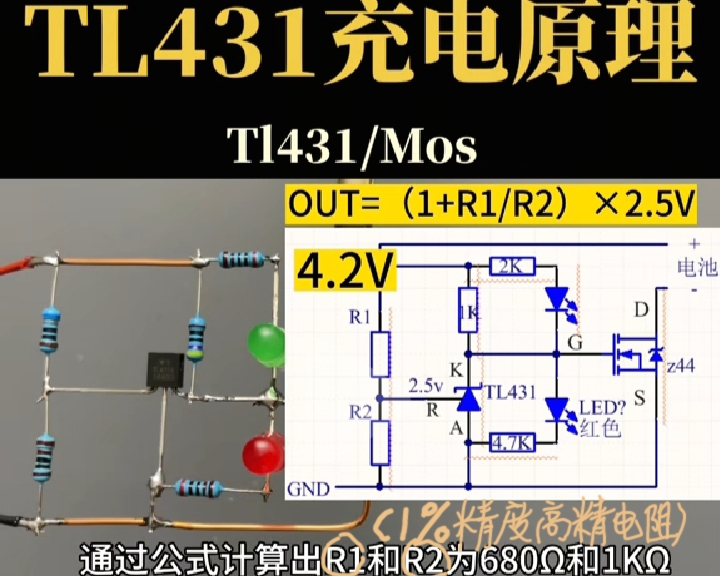
一、文件编码:计算机的 "语言翻译官"
在计算机世界中,所有数据最终都以0和1的二进制形式存储。但人类需要更直观的表示方式,文件编码就是连接二者的桥梁。
常见编码格式
- ASCII:最早的单字节编码,仅支持英文和符号(128 个字符)
- UTF-8:Unicode 的可变长编码,兼容 ASCII,支持全球语言(Python3 默认编码)
- GBK:中文常用编码,双字节存储中文字符
Python 中的编码处理
当使用open()函数时,通过encoding参数指定编码:
# 读取UTF-8编码的文本
with open("data.txt", "r", encoding="utf-8") as f:content = f.read()# 写入GBK编码的文件
with open("output.txt", "w", encoding="gbk") as f:f.write("你好,世界!")
二、文件读取:从磁盘到内存的桥梁
基础操作模式
| 模式 | 说明 | 示例 |
|---|---|---|
r |
只读(默认) | open("file.txt", "r") |
rb |
二进制只读 | open("image.png", "rb") |
r+ |
读写(指针从头开始) | open("data.txt", "r+") |
读取方法对比
1. 一次性读取全部内容
with open("log.txt", "r") as f:all_text = f.read() # 适合小文件
2. 逐行读取(推荐大文件)
with open("large_file.txt", "r") as f:for line in f: # 内存友好型方式print(line.strip())
3. 按字节读取二进制文件
with open("video.mp4", "rb") as f:chunk = f.read(1024) # 每次读取1KBwhile chunk:process(chunk)chunk = f.read(1024)
三、文件写入:从内存到磁盘的持久化
写入模式详解
| 模式 | 说明 | 注意事项 |
|---|---|---|
w |
覆盖写入(文件不存在则创建) | 会清空原有内容 |
wb |
二进制写入 | 用于图片、音频等非文本文件 |
w+ |
读写模式(覆盖写入) | 慎用,避免数据丢失 |
文本写入示例
# 写入多行文本
lines = ["第一行\n", "第二行\n", "第三行\n"]
with open("output.txt", "w") as f:f.writelines(lines) # 比多次f.write更高效
二进制写入示例
# 保存图片数据
with open("download.jpg", "wb") as f:f.write(requests.get("https://example.com/image.jpg").content)
四、追加写入:数据的增量存储
追加模式a
使用a模式时,文件指针会指向末尾,新内容将添加到文件尾部:
# 追加日志信息
with open("app.log", "a") as f:f.write(f"[{datetime.now()}] 用户登录\n")
二进制追加模式ab
# 合并视频片段
with open("movie.mp4", "ab") as f:f.write(new_video_chunk)
五、最佳实践与注意事项
-
始终使用
with语句:自动管理文件关闭,避免资源泄漏 -
明确指定编码:防止出现
UnicodeDecodeError或乱码 -
模式组合技巧:
r+:读写模式(需手动控制指针位置)a+:追加并读取(常用于日志分析)
-
异常处理
try:with open("test.txt", "r") as f:content = f.read() except FileNotFoundError:print("文件不存在") except UnicodeDecodeError:print("编码错误,请检查文件格式")
细节决定成败!
个人愚见,如有不对,恳请斧正!