近年来,人工智能领域在多模态表示学习方面取得了显著进展,这类模型通过统一框架理解并整合不同数据类型间的语义信息,特别是图像与文本之间的关联性。在此领域具有里程碑意义的模型包括OpenAI提出的CLIP(Contrastive Language-Image Pre-training,对比语言-图像预训练)和Google研发的SigLIP(Sigmoid Loss for Language-Image Pre-training,用于语言-图像预训练的Sigmoid损失)。这些模型重新定义了计算机视觉与自然语言处理的交互范式,实现了从图像分类到零样本学习等多种高级应用能力。本文将从技术层面分析CLIP和SigLIP的架构设计、训练方法及其主要差异,并探讨它们在多模态大型语言模型中的应用价值。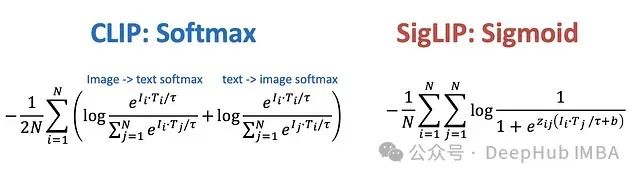
https://avoid.overfit.cn/post/64c63804d691406b830e01bb0a50e931