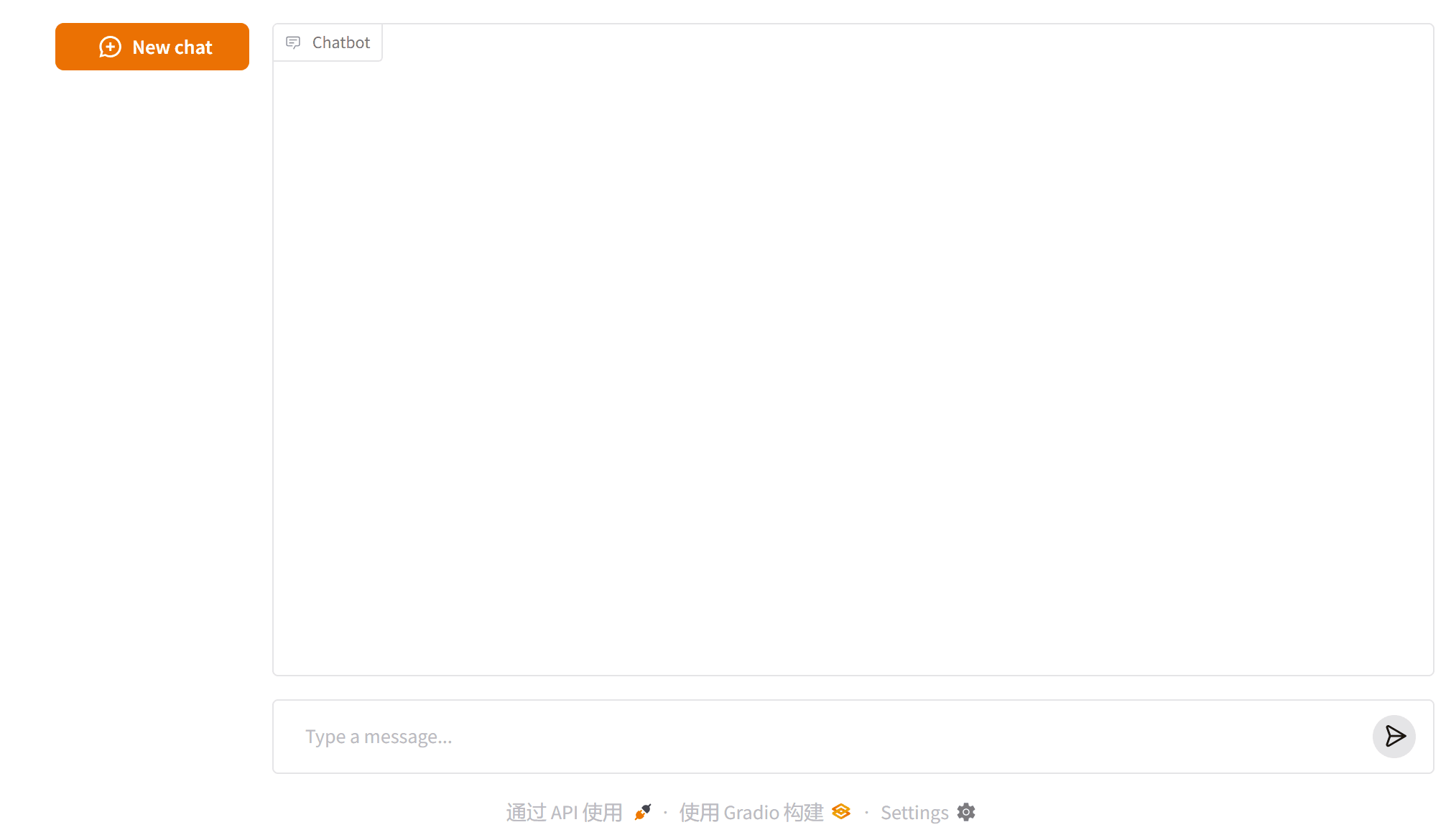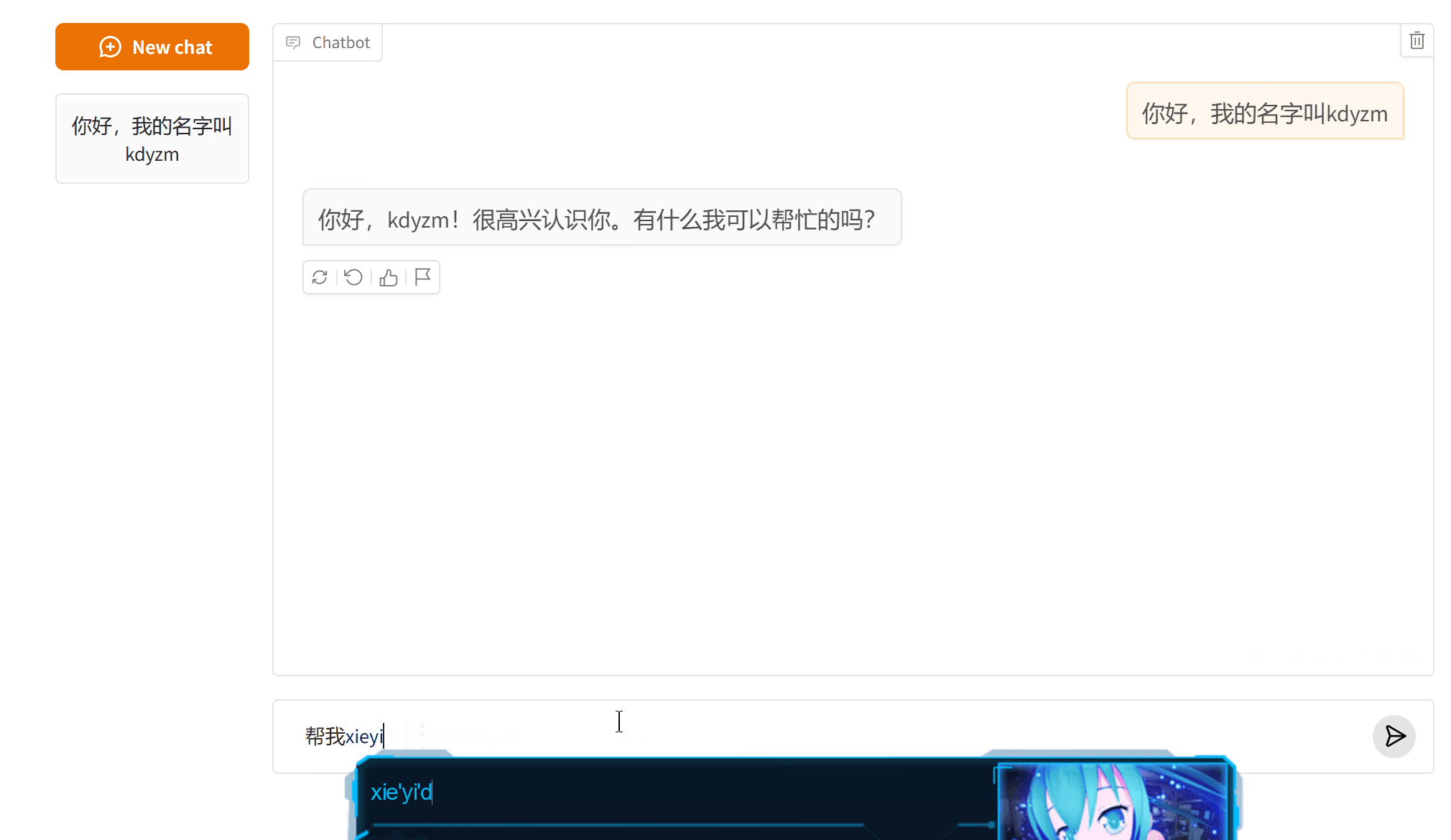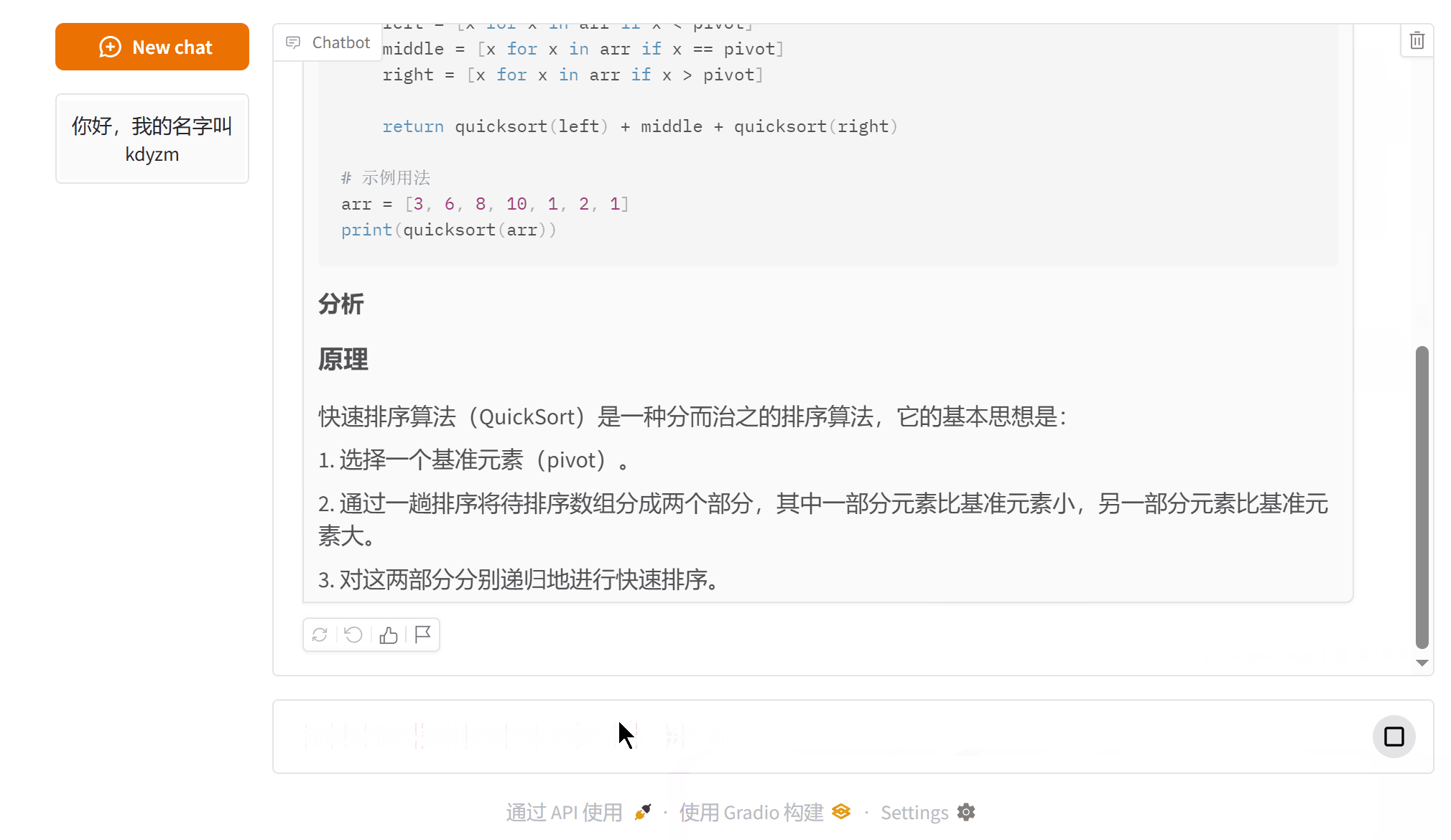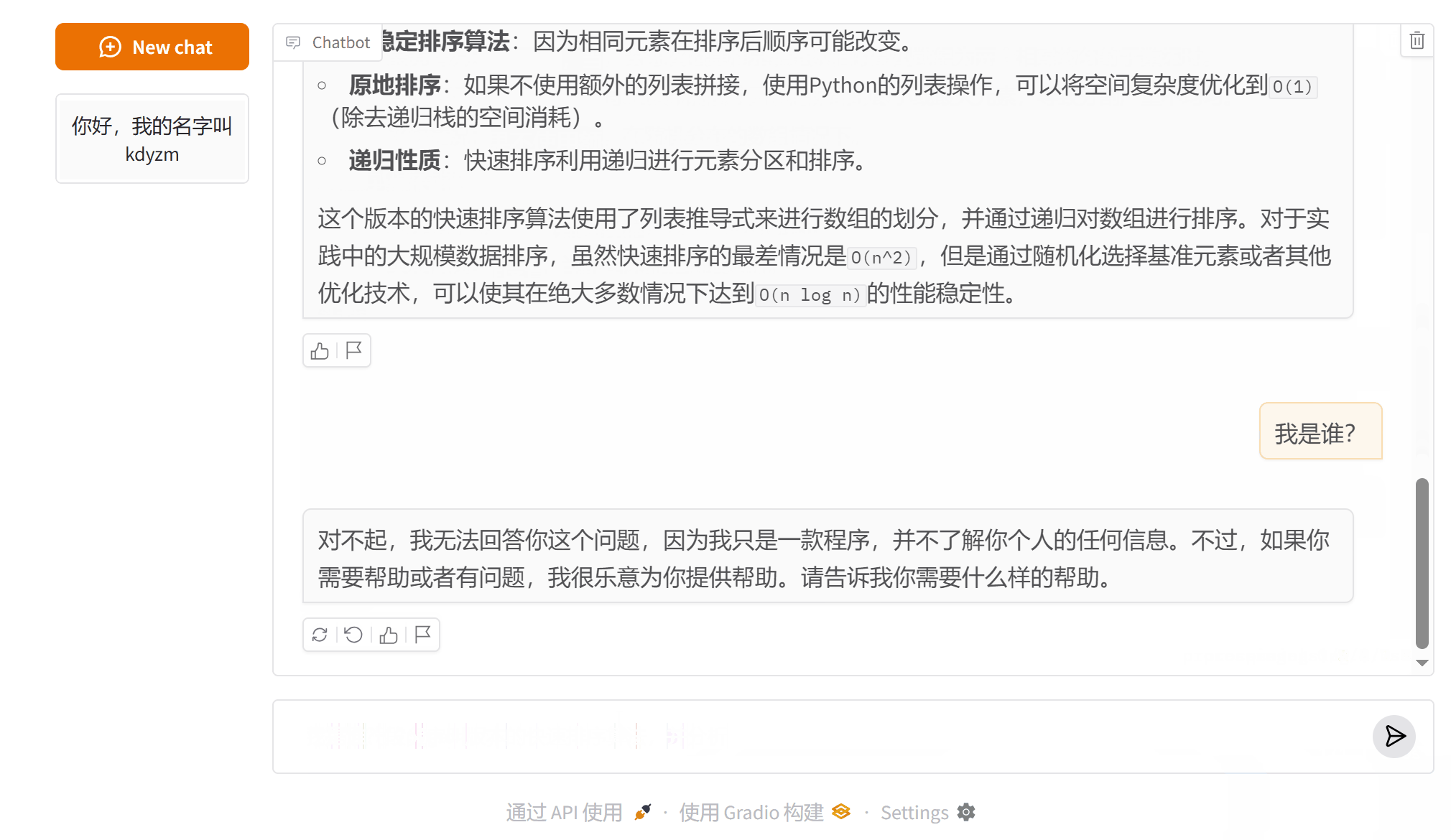
环境准备
所需工具和库
-
Python:主编程语言。
-
PyMySQL/SQLAlchemy:连接MySQL数据库。
-
Sentence Transformers:本地开源文本嵌入模型。
-
Milvus/Pinecone:矢量数据库(示例使用Milvus)。
-
Transformers/PyTorch:支持模型推理。
-
Docker:部署Milvus(本地或服务器)。
安装依赖
pip install pymysql sentence-transformers pymilvus pandas
从MySQL导出数据
连接MySQL并提取文本数据
import pymysql
import pandas as pd
# 连接MySQL
conn = pymysql.connect(host='localhost',user='root',password='your_password',db='your_database',charset='utf8mb4'
)# 执行查询(示例:提取id和文本字段)
query = "SELECT id, content FROM articles;"
df = pd.read_sql(query, conn)conn.close()# 查看数据
print(df.head())
数据预处理
import redef clean_text(text):# 去除HTML标签text = re.sub(r'<[^>]+>', '', text)# 去除特殊字符和多余空格text = re.sub(r'[^a-zA-Z0-9\s]', '', text).strip()return text# 清洗文本字段
df['clean_content'] = df['content'].apply(clean_text)# 去除空值
df = df.dropna(subset=['clean_content'])
生成文本向量
使用Sentence-BERT模型
from sentence_transformers import SentenceTransformer# 加载模型(以'all-MiniLM-L6-v2'为例,生成384维向量)
model = SentenceTransformer('all-MiniLM-L6-v2')# 批量生成向量
texts = df['clean_content'].tolist()
embeddings = model.encode(texts, show_progress_bar=True)# 查看向量维度
print(embeddings.shape) # 输出:(样本数, 384)
存入矢量数据库(以Milvus为例)
部署Milvus
# 使用Docker启动Milvus单机版
docker run -d --name milvus \-p 19530:19530 \-p 9091:9091 \milvusdb/milvus:latest
连接Milvus并创建集合
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility# 连接Milvus
connections.connect(host='localhost', port='19530')# 定义集合结构
fields = [FieldSchema(name='id', dtype=DataType.INT64, is_primary=True),FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=384)
]schema = CollectionSchema(fields, description='Text Embeddings')
collection = Collection('mysql_rag_demo', schema)# 创建索引(加速搜索)
index_params = {'index_type': 'IVF_FLAT','metric_type': 'L2','params': {'nlist': 128}
}collection.create_index(field_name='embedding', index_params=index_params)
插入数据
# 准备数据(确保id唯一)
ids = df['id'].tolist()
embeddings_list = embeddings.tolist()# 插入数据到Milvus
data = [ids, embeddings_list]
collection.insert(data)# 将数据加载到内存
collection.load()
实现RAG检索流程
用户查询向量化
def get_query_embedding(query):return model.encode([query])[0].tolist()
检索相似向量
def search_similar_texts(query, top_k=5):# 生成查询向量query_embedding = get_query_embedding(query)# 定义搜索参数search_params = {'metric_type': 'L2','params': {'nprobe': 10}}# 执行搜索results = collection.search(data=[query_embedding],anns_field='embedding',param=search_params,limit=top_k,output_fields=['id'] # 可返回其他字段)# 提取匹配的ID和文本matched_ids = [hit.entity.get('id') for hit in results[0]]matched_texts = df[df['id'].isin(matched_ids)]['clean_content'].tolist()return matched_texts
集成到大模型生成回答
from openai import OpenAI
# 可选用其他大模型
client = OpenAI(api_key='your_api_key')def rag_answer(query):# 检索相关文本context_texts = search_similar_texts(query)context = "\n".join(context_texts)# 构造Promptprompt = f"""基于以下上下文回答问题:{context}问题:{query}答案:"""# 调用大模型生成回答response = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content": prompt}])return response.choices[0].message.content
增量数据同步
定期同步MySQL新增数据
def sync_new_data():# 查询最新ID(假设表中有自增ID)last_id = df['id'].max()# 获取新增数据new_query = f"SELECT id, content FROM articles WHERE id > {last_id};"new_df = pd.read_sql(new_query, conn)if not new_df.empty:# 清洗和生成向量new_df['clean_content'] = new_df['content'].apply(clean_text)new_embeddings = model.encode(new_df['clean_content'].tolist())# 插入Milvusdata = [new_df['id'].tolist(), new_embeddings.tolist()]collection.insert(data)collection.load()
总结
- 将MySQL中的文本数据转换为向量,并利用矢量数据库实现高效的RAG检索。
- 核心流程包括数据提取、向量化、存储和检索增强生成。
- 应用于知识库问答、个性化推荐等场景,显著提升大模型在专业领域的准确性和实时性。
本文由mdnice多平台发布
![[DevOps] 使用 Windows Sysprep(系统准备)重置计算机 SID](https://img2024.cnblogs.com/blog/207361/202503/207361-20250329143650031-1841713182.png)