images.append(preprocess(image))
# 调整布局以防止重叠
plt.tight_layout()
# 显示图
plt.show()
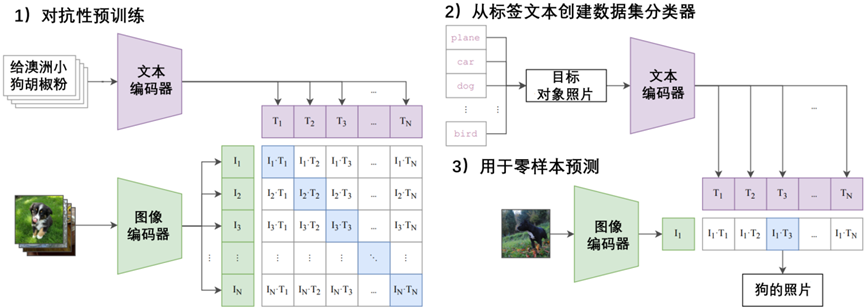
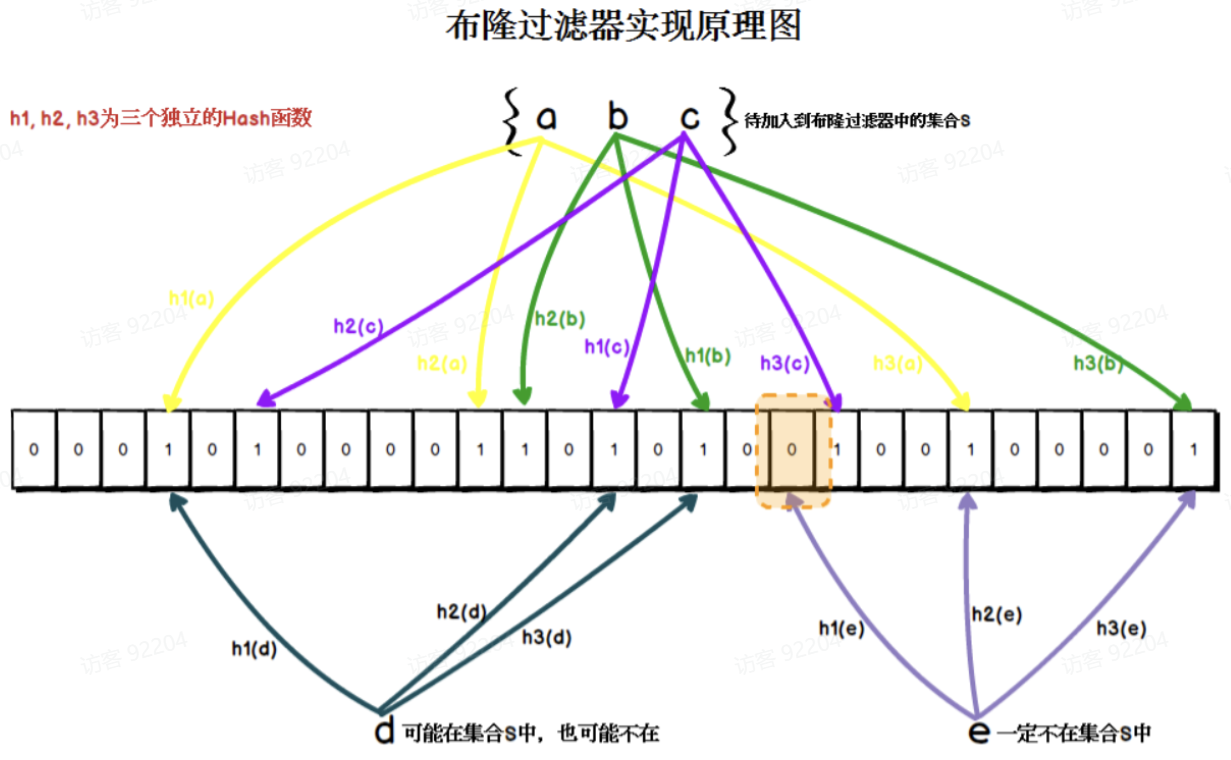
将COCO数据集中的8幅样本图像及其文本,特征显示,如图3-2所示。

图3-2 将COCO数据集中的8幅样本图像及其文本,特征显示
4. 步骤4:生成特征
接下来,准备图像和文本输入,并继续执行模型的前向传递。此步骤的结果是提取相应的图像和文本特征。
image_inputs = torch.tensor(np.stack(images)).cuda()
text_tokens = clip.tokenize(["It is " + text_descriptions中的文本]).cuda()
with torch.no_grad():
image_features = model.encode_image(image_inputs).float()
text_features = model.encode_text(text_tokens).float()
5. 步骤5:计算文本和图像之间的相似性得分
对特征进行归一化,并计算每对的点积。
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity_score = text_features.cpu().numpy() @ image_features.cpu().numpy().T
6. 步骤6:可视化文本和图像之间的相似性
def plot_similarity(text_descriptions, similarity_score, images_for_display):
count = len(text_descriptions)
fig, ax = plt.subplots(figsize=(18, 15))
im = ax.imshow(similarity_score, cmap=plt.cm.YlOrRd)
plt.colorbar(im, ax=ax)
# y轴刻度:文本描述
ax.set_yticks(np.arange(count))
ax.set_yticklabels(text_descriptions, fontsize=12)
ax.set_xticklabels([])
ax.xaxis.set_visible(False)
for i, image in enumerate(images_for_display):
ax.imshow(image, extent=(i - 0.5, i + 0.5, -1.6, -0.6), origin="lower")
for x in range(similarity_score.shape[1]):
for y in range(similarity_score.shape[0]):
ax.text(x, y, f"{similarity_score[y, x]:.2f}", ha="center", va="center", size=10)
ax.spines[["left", "top", "right", "bottom"]].set_visible(False)
# 设置x和y轴的限制
ax.set_xlim([-0.5, count - 0.5])
ax.set_ylim([count + 0.5, -2])
# 为布局添加标题
ax.set_title("用CLIP计算文本和图像相似性得分", size=14)
plt.show()
plot_similarity(text_descriptions, similarity_score, images_for_display)
使用CLIP计算文本和图像相似性得分,如图3-3所示。
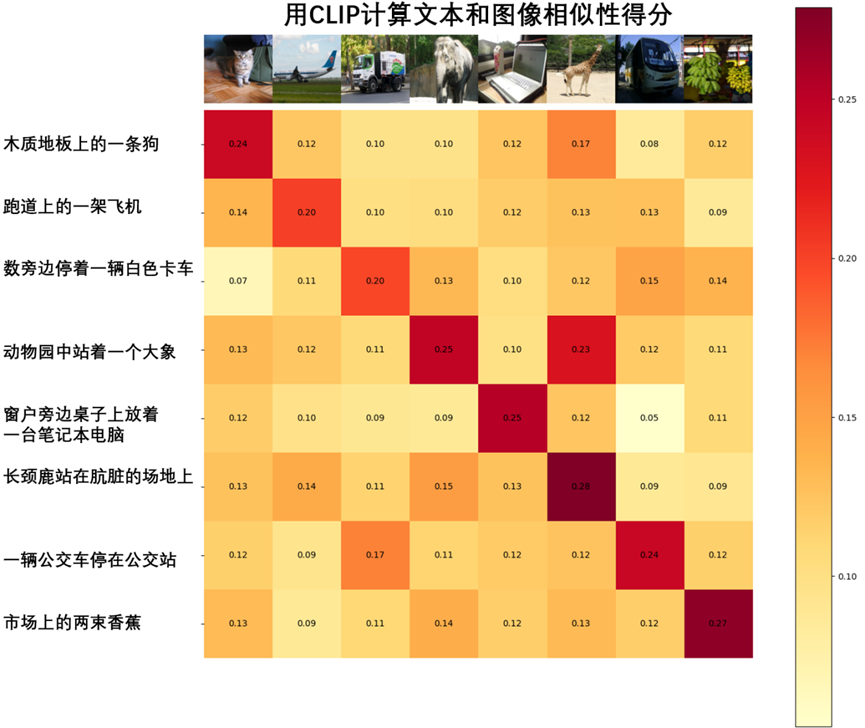
图3-3 使用CLIP计算文本和图像相似性得分