在团队协作开发的场景中,代码规范的重要性不言而喻。当团队规模逐渐扩大,如何确保每个人提交的代码都符合规范,比如不能 import *、代码嵌套不能超3层,代码包层级依赖结构约定、
不能修改核心文件等,成为了一个亟待解决的问题。今天,咱们就来聊聊如何开发一个代码扫描工具,它能在静态或编译阶段对代码进行检查,还能根据各种条件筛选代码,扫描规则也可以自
定义。我希望本文能带来的是更多的独立思考,即为什么这么实现,而不是拿走即用。
一、确定扫描文件类型:有所取舍
我想到的第一个问题是文件种类太多,怎么办?只能做一些取舍,HTML、JSP、js、sh、txt、xml 等,情况复杂,比如 xml 文件内容灵活自由,获取信息非常困难,Jsp 也麻烦,其嵌入语言
太多样,且属于淘汰技术,未来只会越来越少,其他文件频度低、数量少,人工审阅即可,所以先只将重点放在 Java 文件和 SQL 文件(进一步明确为
mapper.xml)上。
二、技术可行性分析:站在巨人的肩膀上
跟随而来的第二个问题是有无解析上面两类文件的工具?视为事前技术可行性分析,若无,只能手写解析器那估计就不必有下文了,因为本工具的核心在规则上,不能为了开发应用软件还要写
个编译器。还好我们可以站在巨人的肩膀上,对 Java 文件,可使用到 com.github.javaparser 工具,能将 Java 文件解析为关键对象CompilationUnit。对 SQL,来源也多样,特别是大型软件项目
中 SQL 存在的场景比较丰富,我的思路是:对于静态类型一:Java 代码中嵌入的 SQL,从 Java 文件中解析组装出来;对静态类型二:mapper 文件中的 SQL,自然应该想到 mybatis 框架,若
对原理过于陌生,建议先遍观一遍其源码;对动态 SQL:使用 mybatis 插件机制,通过 Interceptor 获取应用运行时执行的 SQL,可使用 jar 嵌入生产项目的方式。留个疑问,为什么动态 SQL 不
能直接在编译时期获取完整的 SQL ?
**项目框架:渐进完善**
开始动手,新建一个 spring+maven 项目,或可使用在 spring 官网提供的 initializr 生成一个 zip 项目包,顺带勾选 test 依赖(各版本信息见文末),粗略划分出几个常规 package,以后需要再
补充,不求一步到位,软件架构演进也同理,初步划分包如下图示(若不知道下图怎样生成,学习 Idea 的 tree 命令):

为什么不使用 gradle?我尝试了,但有版本兼容问题,很不友好,虽然是技术新星,但弃用。
**Java文件解析:com.github.javaparser**
看手基础研究,第 1 点是 javaparser 如何解析 Java 文件,可以先使用 AI 进行辅助探索,给与 Deepseek 提示词:“在使用 maven 构建的 spring 项目中,给出使用 javaparser 解析 Java 文件
的示例。” 再参考回答,先 util 下新建CompilationBuilder 类,做解析转换:
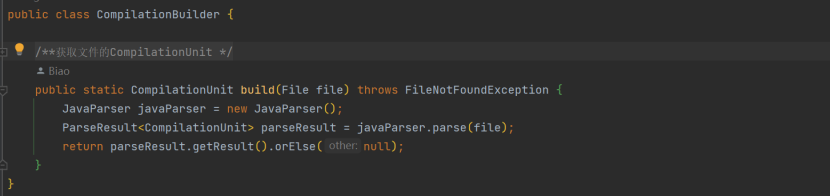
来一个单元测试类,上面类右键直接生成一个 unit test 类,上下文都自动添加了:

这里重点学习下 CompilationUnit,一个 Java 文件在编译器解析后对应一个 CompilationUnit,如果对 AST(全称是Abstract Syntax Tree)抽象语法树有所了解,这里就简单很多了。在 JavaParser
中,AST 对应于 CompilationUnit,代表一个编译单元,CompilationUnit 包含一个或多个类型声明(TypeDeclaration),比如类、接口、枚举等。每个类型声明又可以包含字段、方法、内部类等。
可以 Debug 模式下生成一个 CompilationUnit 看看结构:包含了 package、声明、import 声明、类对象、代码字符范围、类声明、注解声明、方法声明、方法内元素声明。
其中需要注意 Node 节点,代表 AST 的一个节点,Node 是 abstract class,典型的一些子类列举:ImportDeclaration引用声明 、 AnnotationDeclaration 注解声明、BodyDeclaration 具体 class,
interface, enum 实现体声明、ClassOrInterfaceDeclaration 类或接口定义声明、Comment 注释、FieldDeclaration 类变量声明、VariableDeclarator 方法变量声明、MethodDeclaration 方法声明、
ForEachStmt 循环结构、IfStmt 选择结构,并且下图中是 childNodes 中包含了childNodes。用一个 Node 树,可完整表示出了一个 Java 文件的所有信息,留意下图中灰色类型提示如ImportDeclaration。
从此,你想取哪块就取哪块,精确到字符级别。
**mapper文件解析:mybatis**
第 2 点是 mybatis 如何解析 mapper 文件,先复习一下源码,给 deepseek 提示词:MyBatis 如何解析 mapper.xml,并请通过示例代码表明关键类的使用。
完成阅读理解后提取关键信息如下:
- - SqlSessionFactoryBuilder 和 Configuration:负责加载和解析主配置文件 mybatis-config.xml。
- - XMLMapperBuilder:解析 mapper.xml 文件,提取关键信息。
- - MapperRegistry:注册 Mapper 对象,管理 Mapper 接口与 SQL 语句的映射。
- - MappedStatement 和 ResultMap:分别表示 SQL 语句和结果集映射。
- - SqlSource 和 DynamicSqlSource:处理静态和动态 SQL 生成。
- - SqlSession 和 Executor:执行 SQL 语句,处理数据库操作。
- - Cache 和 CacheBuilder:管理缓存,优化性能。
看来重点就是研究源码中 XMLMapperBuilder,核心方法 parse()就是解析 mapper 文件,parse 包含三个子方法,具体都是在解析时执行了configuration.addMappedStatement (statement),即说
明可以在完成后从 Configuration 对象中取出 SQL。
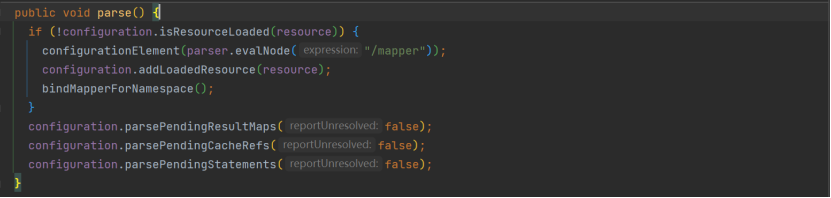
这里有个关键类 MappedStatement,解析后的每个 SQL 语句被封装成一个 MappedStatement 对象,包含 SQL 语句、参数类型、结果类型等信息。动态 SQL 部分(如<if>、<foreach>)被编译成 OGNL
表达式,以便在运行时根据参数动态生成 SQL。那如何构建出 XMLMapperBuilder 运行需要的上下文?我也不知道,那就让 deepseek 生成实例,提示词:“使用 mybatis 框架生成一个解析 mapper.xml 文件
的第三方工具类。”
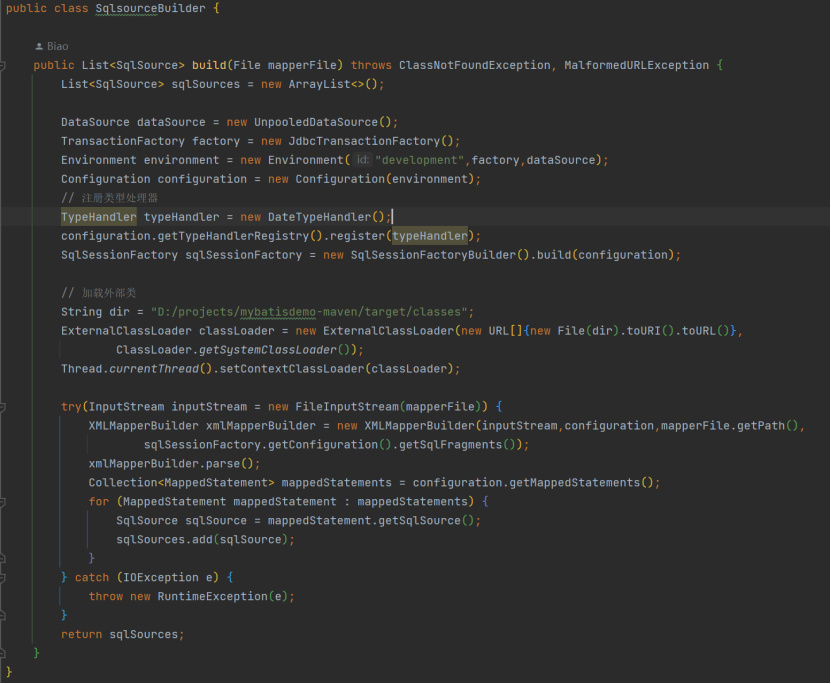
先构建上下文环境,因为没有 mybatis-config.xml,所以以 DataSource、Environment、Configuration、SqlSessionFactory 手工指定,最终构建出 XMLMapperBuilder,这里不要期待 deepseek 实例拿来就
成功运行!这里的问题有:一是为什么一定要有ExternalClassLoader.extClassLoader (...)?二是 TypeHandler 做什么用?三是 mybatis 框架下,不使用 mybatis-config.xml 文件,是否可以构建出 SqlSession
Factory 对象?案例中最终实现的 SqlSourceBuilder,用于获取 SqlSource:
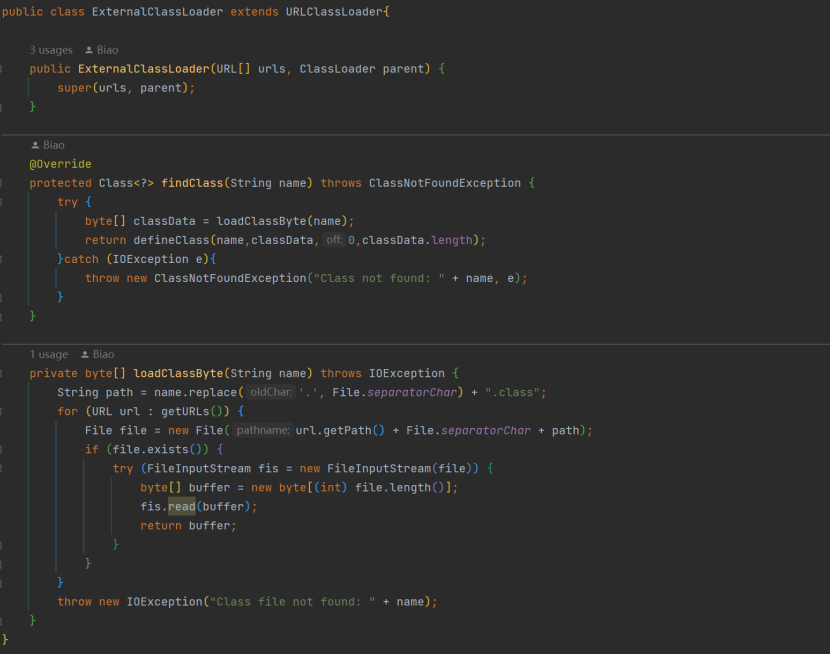
上面的问题解决过程,值得实践:对问题一缺少则运行提示 mapper 文件中的某个 class 不存在,对问题二会提示缺少 Type handler,解决思路如下:1. 既然是缺失外部类,考虑使用 classLoader 进行外部
类加载,创建一个ExternalClassLoader 类专门加载外部类,并特别留意class not found的提示,判断与mapper文件中类的全名称关系:
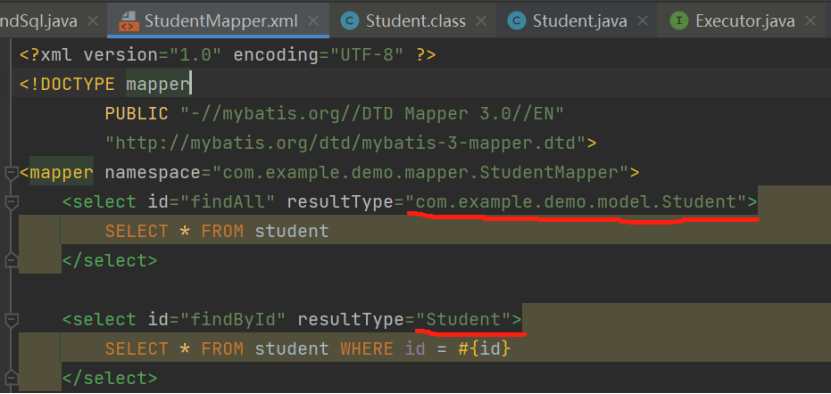
问题 2 中 Type handler 是指在 mapper 中将项目中数据类型转化为 JDBC 类型,比如 collectDate 到 LocalDateTime 的转换,案例中先定义一个 TypeHandler,然后在 Configuration 注册。虽然上面代码可
运行了,但不同的 mapper 文件,有不同的 resultType 和参数类型,就需要不同的类加载和TypeHandler 了。问题三我是直接让 AI 给参考,我再改写出来的。
我们再建一个测试类,这里的外部类加载和SqlSourceBuilder中的有重复,可去掉:

难点在动态 SQL,静态 SQL 暂且不表,这里插播一个知识点,看源码可知,接口 SqlSource 有 4 个实现类DynamicSqlSource 动态 SQL(运行时生成),ProviderSqlSource 是 @SelectProvider 注解生成
SQL(运行时调用),RawSqlSource 静态 SQL(编译时生成),StaticSqlSource 所有 SQL 最终静态结果(执行时形态)。为了看看动态 SQL编译阶段能做点什么,案例中尝试做解析展示,建一个Dynamic
SqlParser 类,专门处理 DynamicSqlSource,因为 SqlNode实现类型有 10 种,以下单独处理了几类动态 SQL 标签 Node:

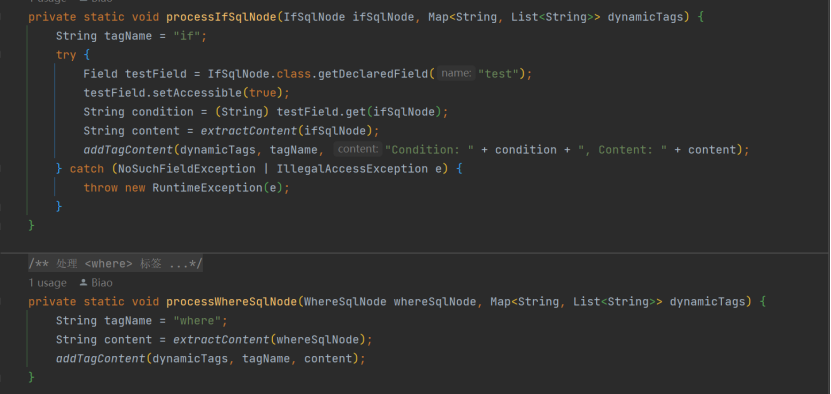
但通过仔细分析发现,场景太多,组装出来的 SQL 也不是正常意义上的 SQL,只是字面上如MixedSqlNode,IfSqlNode,ForEachSqlNode,WhereSqlNode 的动态标签内容,这是条死胡同,放弃(还有个
hard 级别思路,即连接测试数据库,通过模拟出参数输出完整 SQL)!最终做简化处理,只获取动态 SQL 的静态部分内容。
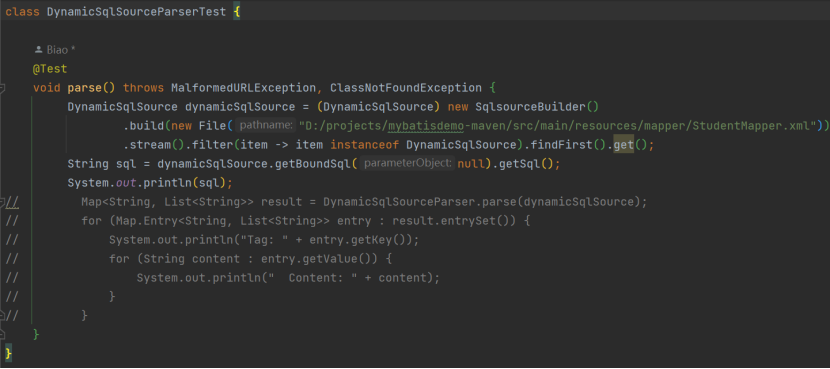
对 RawSqlSource 静态,同上直接可获取完整 SQL,通过 SqlSourceBuilder 获取 SqlSource 后直接输出 SQL。以上尝试过程可使用 AI 进行辅助生成,再次说明不要期待可复制粘贴即运行,提示词:使用
mybatis 框架,实现一个解析DynamicSqlSource 的工具类,要求能解析动态 SQL 的标签内容。
**获取提交信息:BlameResult**
第三个问题是如何获取代码提交信息,比如作者、日期等。答案是可以使用 org.eclipse.jgit 包,可以将 Git 进行管理的项目代码提交信息完整解析出来,这个适用于所有文件类型,包括 mapper.xml。
先预备点知识,便于理解。注意区分好 Git 和 jgit,Git 是工具应用概念,jgit 是技术实现概念。jgit 中 Ref 是一个重要的概念,它代表了对 Git 仓库中特定对象的引用。这些引用可以指向 Git 中的提交(commit)
、标签(tag)、分支(branch)等,如果对这些概念太模糊,建议先了解学习下 “Git 图谱”,所有的提交,在 Git 中会形成一个图结构,即下图中的线状表示:
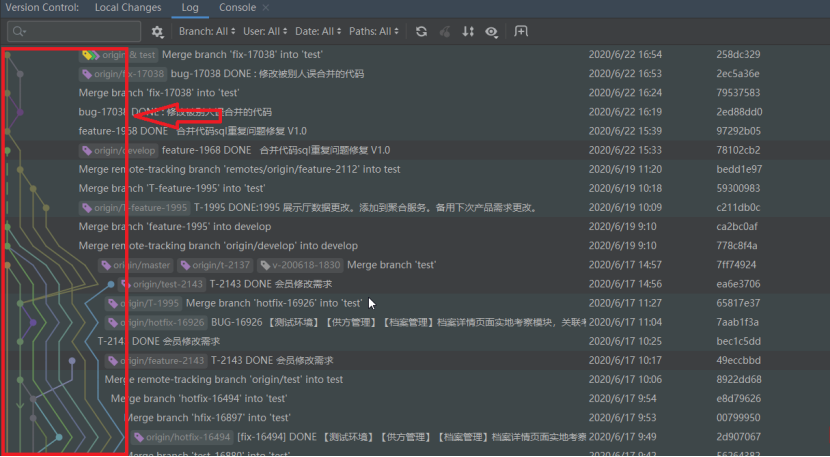
在 jgit 中,HEAD 也是一个重要的概念,它指向当前分支的最新提交(commit)。具体来说,HEAD 是一个指针,它总是指向当前分支的最新一次提交。当你在某个分支上工作时,HEAD 会指向该分支的最新
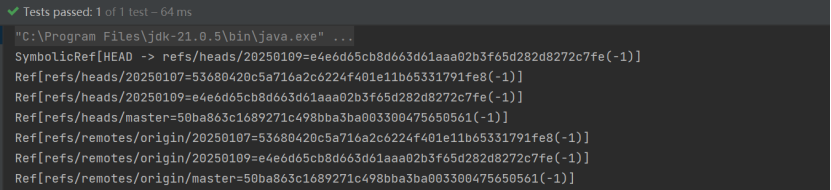
提交。提交(commit)在 jgit 中表示为 RevCommit,指的是下图中,左侧1号位的一次 commit(非push),IDE中右键2号位可以查看本次提交的版本号 RevisionNumber,在 JGit 中可表示为一个ObjectId,右侧
3号位为本次提交的文件清单。
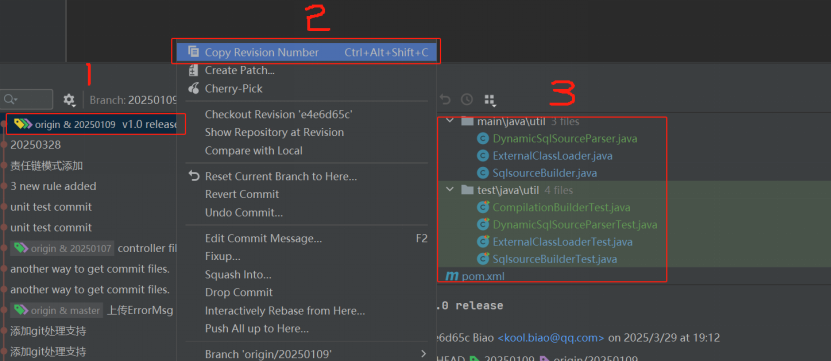
Jgit 中没有分支(branch)概念,思考下为什么?我们可以使用代码直接打印输出,做些值比较,即可充分掌握如 Ref 和分支的关系。另外,ObjectId 则是标识仓库中的对象,比如提交、树、blob 和标签,每个对象
都有一个40 位的 SHA-1 哈希,作为唯一 ID,通过打印输出可发现 RevisionNumber 和Ref 的某个 ObjectId 相等,推理出RevisionNumber 也就是一次提交的 ObjectId。如需要,可通过全局唯一的 ObjectId,可直接
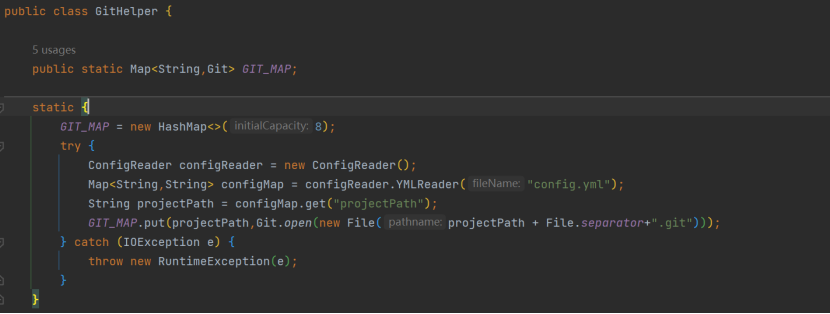
反向获取到某次提交或其他对应的对象。所有Git相关的处理都在一个类,util中新建一个GitHelper,类头做静态读取一些配置信息,其余为下文中1-6的文件筛选方法:
打印出的 ObjectId:
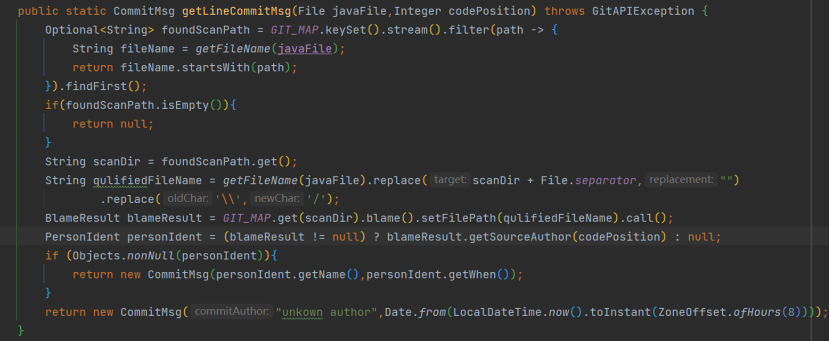
几顿饭的功夫,还只是解决了通过 jgit 找到特定版本下文件的问题,那每行代码的提交人和时间信息怎么办?查阅资料获知凡使用 Git 进行管理的代码,均可通过 jgit.blame 获取每行代码的提交信息,返回一个
CommitMsg {String author;Date commitTime;},PersonIdent 就是作者身份和提交时间的记录类,在GitHelper中的getLineCommitMsg方法:
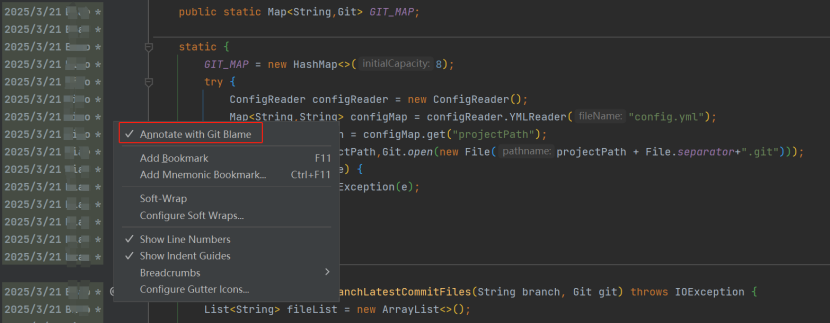
BlameResult 记录了代码行的提交信息,对应于 IDE 中的 Annotate 信息,可找到作者和时间:
**需求场景:条件筛选**
至此,还需要利用以上基础,开发出一些文件筛选方法,都在GitHelper中,包括:1. 获取项目目录下全部文件 2. 获取工作分支下最近一次的 commit 文件清单 getLatestCommitFiles 3. 获取个人本地未提交文件
getUnCommitFiles 4. 获取本地 HEAD 分支指定用户提交的文件 getCommitFilesByUser 5. 获取指定分支下指定用户提交的文件getFilesByBranchByWhenAndUser 6. 获取指定分支下指定用户指定日期之后提交
的文件getFilesByBranchByWhenAndUser。
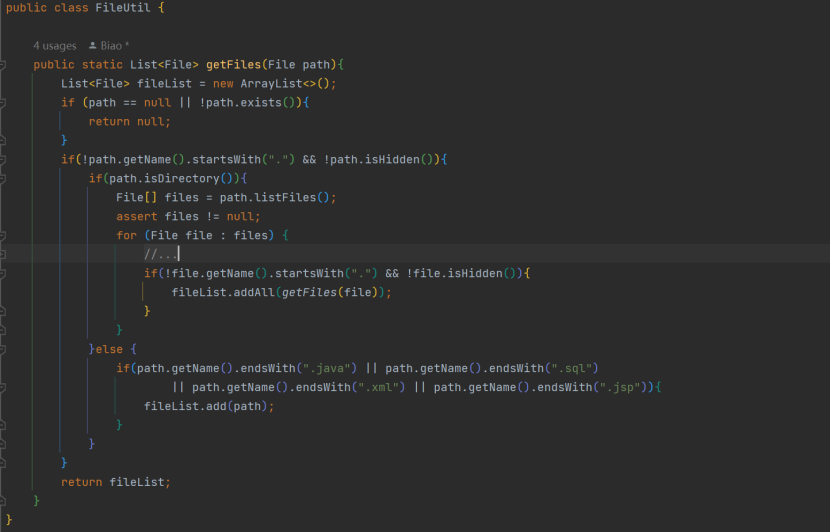
分析并实现如下,第 1 点与 jgit 无关,直接文件遍历可得,在util包下 FileUtil 中的 getAllFiles,可以在这里过滤一些无关的文件:
第 2 点:获取工作分支下最近一次的 commit 文件清单 getLatestCommitFiles,在使用时,传入的 Revision 为当前分支号即可:
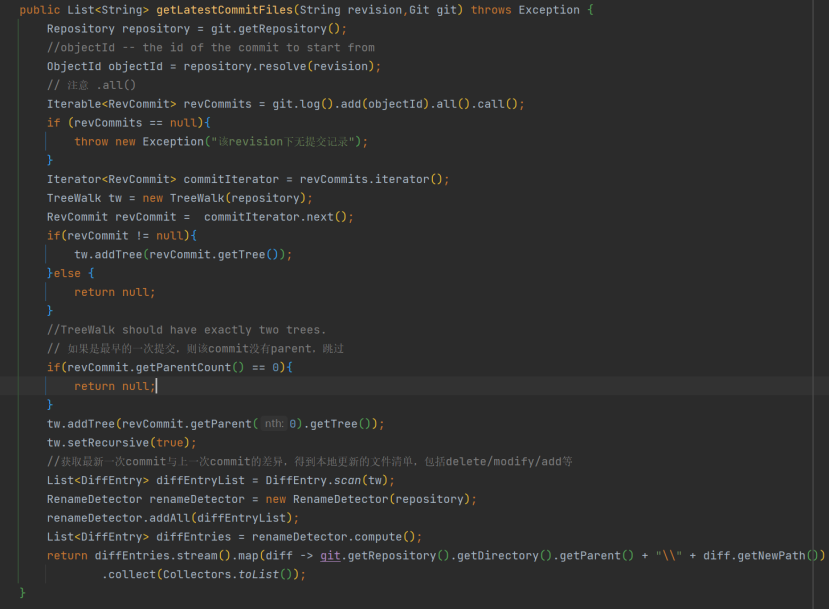
解析一下以上代码,git.log ().call () 为使用 jgit 获取 RevCommit 的公用部分,另外可以加上 add (ObjectId) 表示从图谱中哪一次 commit 开始遍历。使用 iterator 的第一个元素就获取最新一次 RevCommit,再给
TreeWalk 传入上一次提交和本次提交,使用 DiffEntry.scan (tw) 得出差异文件,即提交的文件清单。
第 3 点,获取个人本地未提交文件 getUnCommitFiles:
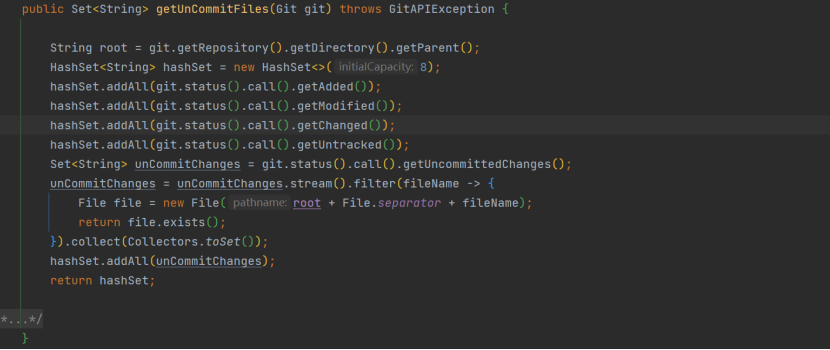
解析一下以上代码,在 Git 中,索引(index)是一个重要的概念,有时也被称作暂存区(staging area),使用 add命令即加入到 index,索引的状态可以通过 git status 命令查看各文件的状态,在 idea 中,用颜色
区分。对方法做单独说明,getAdded (),已添加到 index,但不在 HEAD 中,已 add 未 commit 的,绿色;getModified () ,相对于 index中有修改的,已 add 又修改的,绿色;getChanged (),从 HEAD 中又修改
回到 index 中的,蓝色;getUntracked (),未被追踪的,即未add 操作的,红色;而 getUncommittedChanges () 实际就是简写一步获取未提交清单的,看源码即知不仅包括了以上四种, 并还有 removed、missing
和 conflicting 的文件,建议只需上面单独的 4 个即可。
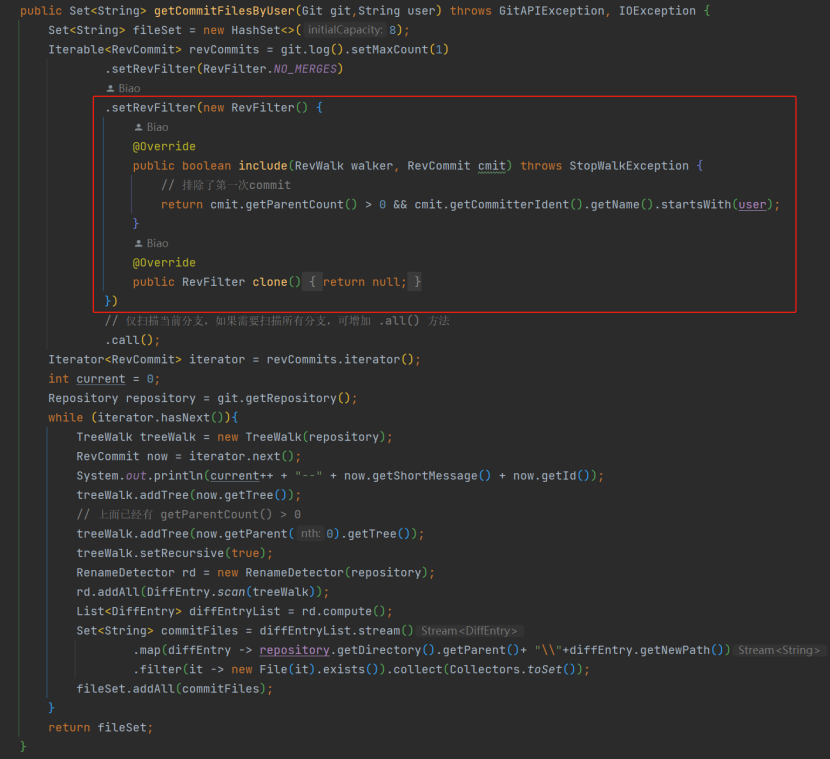
第 4 点,获取本地 HEAD 分支指定用户提交的文件 getCommitFilesByUser,本方法中应留意.setMaxCount (1),指定了输出的 RevCommit 数量为 1,即当前工作分支上,最新一次提交,可以通过 debug 下,对
比 RevisionNumber和案例代码中的 now 变量 ObjectId 进行验证。这里仅增加使用了 RevFilter 对遍历对象过滤。
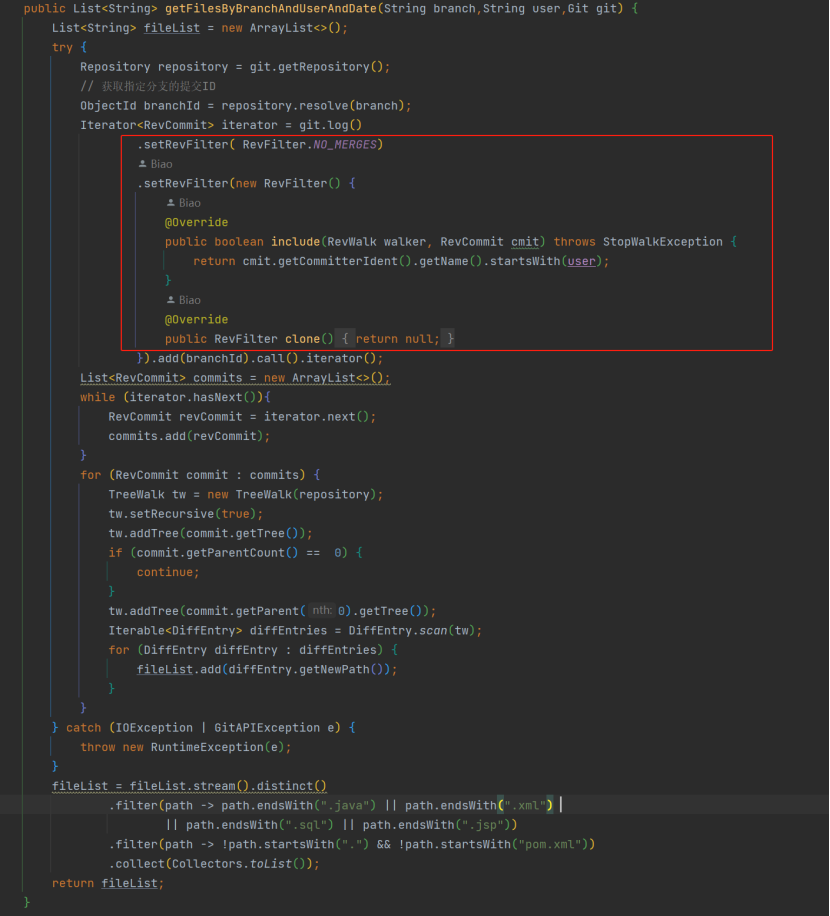
第 5 点获取指定分支下指定用户提交的文件 getFilesByBranchAndUserAndDate,实现代码与前面一样,只是增加分支选择,repository.resolve (branch) 可解析一个代表分支的 Ref,可解析如上面 ObjectId 示例中
的字符串,如“refs/heads/20250210”,add (id) 表示从图谱中哪一次 commit 开始遍历。
如果搜索一些资料,以上 jgit 方法 1-6 还有些不同的实现,各位可尽情尝试,其中有 3 个核心类,我认为需要掌握,RevWalk 是用来遍历提交记录的,也就是 RevCommit 对象,适用于获取提交历史。TreeWalk 则
是用于遍历文件树,也就是 Git 仓库中的文件和目录结构,适用于获取文件信息。DiffEntry 表示一个文件在两次提交之间的变更情况。它包含了文件的路径、变更类型(如添加、删除、修改等)以及变更的具体内容。
另外,这里引出一个设计点,如果对以上 1 到 6 方法做优化,你会想到什么?是不是他们大同小异,可以使用重载实现呢?1 和 3 之外,都可以使用同一个方法名实现,传入参数不同而已,或者可以使用层叠式调用,
多参数的方法调用少参数的。
三、框架设计:合理架构,分层清晰
第四个问题是该工具项目的框架如何设计?目标特征:架构合理、分层清晰、代码规范、抽象丰富、配置化完善。基于以上目标,我先给自己提几个问题,看官可停下来独立思考几分钟。一是规则应该怎么实现,如
何做到规则集可扩展,是否该使用责任链设计模式?二是该工具要支持配置化,所以扫描的条件和规则配置都需要写在配置文件,如 application.yml 中,再通过读取配置文件获取项目地址、分支。三是扫描的结果要呈
现和通知,可以按作者做汇总,并最后发邮件通知到人。其他一些常规的思考:项目架构上 package 的补充设计、统一枚举常量、日志框架、统一异常处理,到处都有资料,太过于普通,忽略不讲。至于设计细节思路,
下文融合来讲。
规则设计
先说规则设计,规则分两大类,一类是 JavaRule,一类是 SQLRule,所有规则实现类显然要结构上一致,很轻易的想到应该都实现一个 Rule 接口,该接口有 Check 扫描方法,为所有实现规则类的共有行为又可以有不
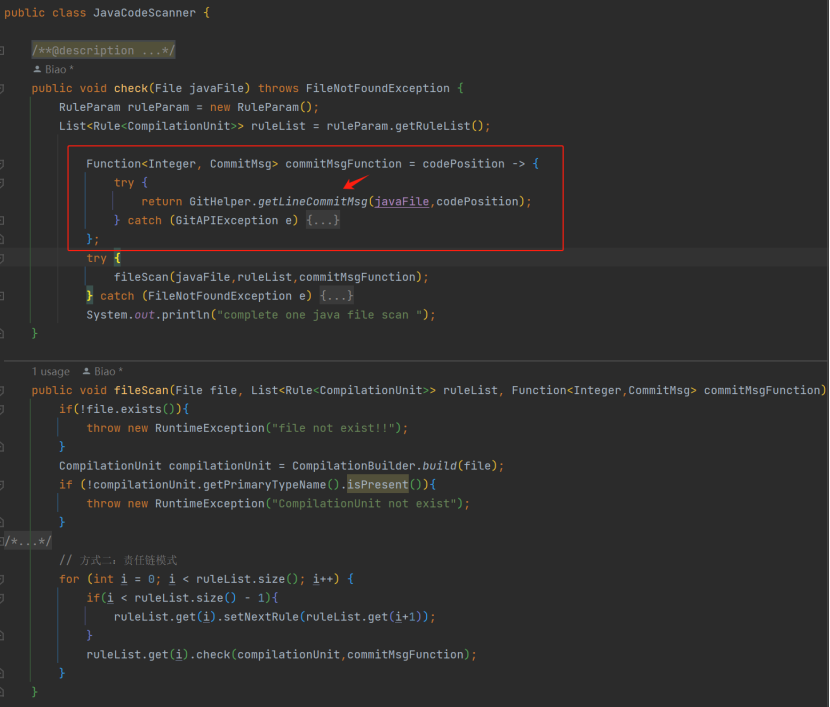
同实现,这就是接口的标准使用场景:抽象同一个行为。那为什么不使用一个 Rule 父类实现?因为在项目代码JavaCodeScanner.fileScan中使用规则集实现逻辑时,必定会使用到 Check 方法,而只有 Rule 接口可以达成。
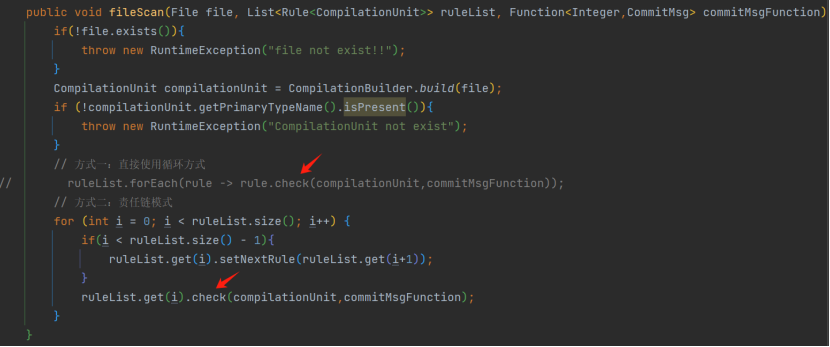
同时,如果想要体现一下责任链模式,就额外需要 Rule 接口中具备 setNext 方法,并且在每个具体的规则实现类中,有一个 Rule 类成员变量,同时重写 setNext 实现该变量的赋值。如果更进一层,可建一个 Handler<T>
接口,有 handle和 setNext 方法,从而分离出与规则无关的逻辑,再由 Rule 接口扩展 Handler。
在每一个具体的规则实体类中,又发现有一些公共的方法,如获取 git 提交信息的 getCommitMsg (),放接口 Rule中似乎不合适,只是一些公共的内容完全相同的属性或方法,于是设计两个抽象基类 JavaBaseRule 和
SQLBaseRule,那有人说我就想放 Rule 接口中行不行?当然可以,使用 default 来实现,但这属于非标准用法。如果考虑规则区分扫描级别,包级、文件级、代码级,可以在两个抽象基类实现,最终的规则相关 UML 类
图如下:

**规则实现:分类继承**
具体的代码扫描典型规则列表如下:
|
Java 代码规则名 |
实现思路 | |
|
1 |
不能 import* |
对 importDeclaration 进行字符串匹配 |
|
2 |
代码注释不得使用 todo,begin - end |
对 Method 方法体,逐行进行字符串匹配 |
|
3 |
Class 类命名不得重复 |
扫描 className,使用 Set 集合运算判断重复 |
|
4 |
禁止直接引用 domain 包下对象 |
判断 import 中的关键字:domain |
|
5 |
Domain 类不得有公共构造方法 |
ConstructorDeclaration 对象属性进行判断 |
|
6 |
不得私自使用 Threadlocal 对象 |
对 Method 方法体,逐行进行字符串匹配 |
|
7 |
不得直接使用指定 table 编码 |
对类变量、Method 方法体,逐行进行字符串匹配 |
|
8 |
代码注释不得使用 todo,begin - end |
对 Method 方法体,逐行进行字符串匹配 |
典型具体规则实现类,ImportRule,对 check () 方法重写,调用 checkAsteriskImport (),checkAsteriskImport 中结合前面对 CompilationUnit 的分析,即可完成对代码 import 部分的解析,通过 try - catch 异常机制收集
规则不符的消息,并在过程中包括了获取 commit 信息的 Function,那请问这个代码有无什么问题?
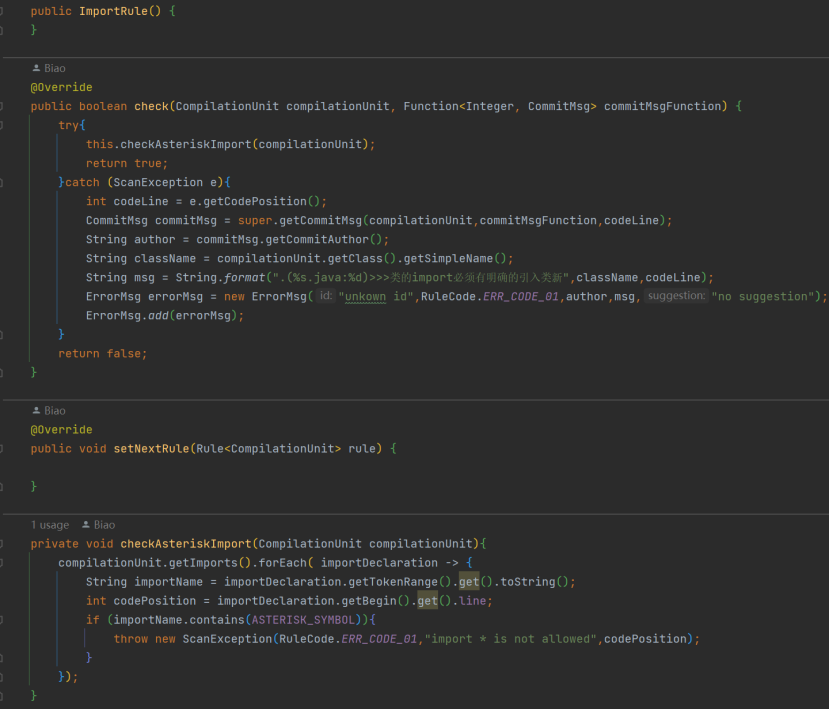
以上代码的问题是,如果有多个 import*,每次扫描只能查到第 1 个不符的,请思考下怎么改进。
另一个规则 “不得直接使用指定 table 编码” 实现类 TableForbidRule,需要先找到 Method,再通过MethodDeclaration 的代码内容进行字符串匹配查找,这里有一个问题,使用什么高效的字符串匹配算法,可以参考如
KMP、BoyerMoore 等,我尝试了 BoyerMoore,结果无法兼容中文字符,最后本案例使用了最素匹配法String.contains (),运行时间无明显感知差异。此处又有一个问题,如果将表名定义为类常量,就扫描不到了!如何
补救呢?
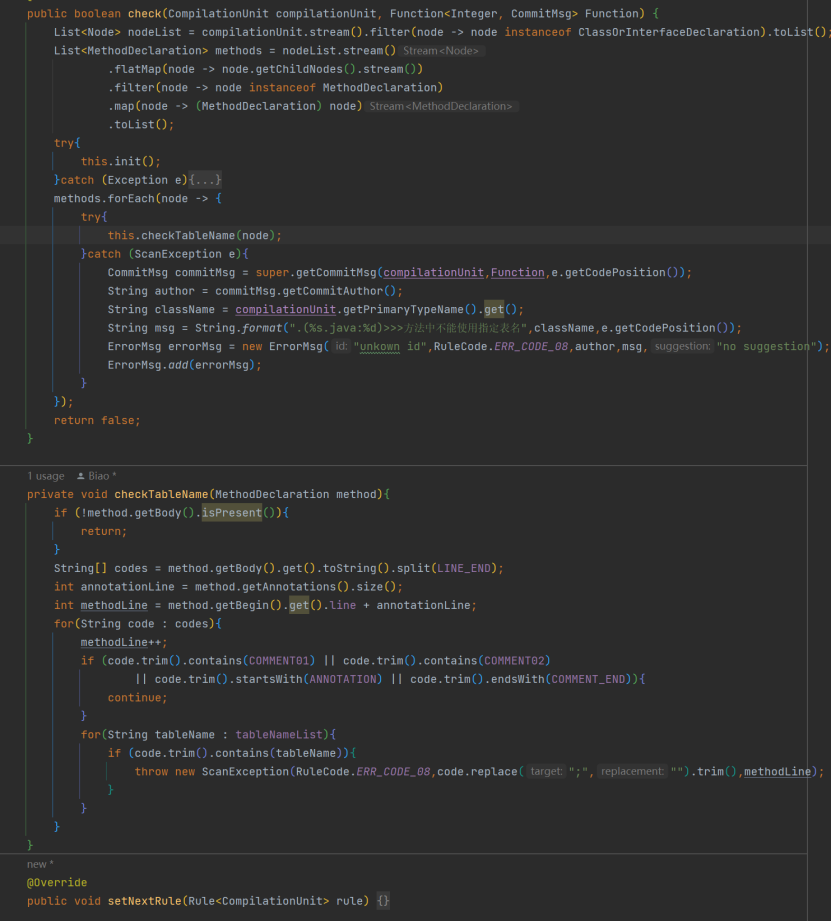
其他规则实现类大同小异,不一一列举说明。针对使用 try..catch 异常的模式,每次只能找出同一个文件中同一规则的第一个不符处的漏洞,思路上可以将 ScanException 替换为一个 Collection 集合,try 部分更换为 for
循环,每次循环中发现不符即收集,catch 更换为判断 Collection 是否为空,非空再加入到总集合 ErrorMessage 中去,此版本代码请大家来尝试。
配置化设计:文件读取
配置化体现,一是,对禁止使用的 table,保存在 resource 目录下的 forbidTable.txt,当然也可以在 DB 进行存表处理。对 txt 文件读取,通过 util.ConfigReader 来实现,然后应用在CustTableForbidRule 的 init () 中,
ConfigReader设计上可以读取 xml、txt、yml,但 xml 格式不统一,节点名无法预测,读取出的内容将不可用,无用而弃。

二是读取 resource 目录下的 config.yml 获取配置项,如项目地址、扫描模式、指定版本、扫描日期、输出地址等。

扫描相关参数放在 ScanningParam 类,里面通过 init () 方法实例化 util.ConfigReader 来实现扫描工具的配置化,init ()方法中使用 checkParam () 对读取参数的组合进行校验,本案例中较为简单,可以进行加强扩
展对字符和格式校验。
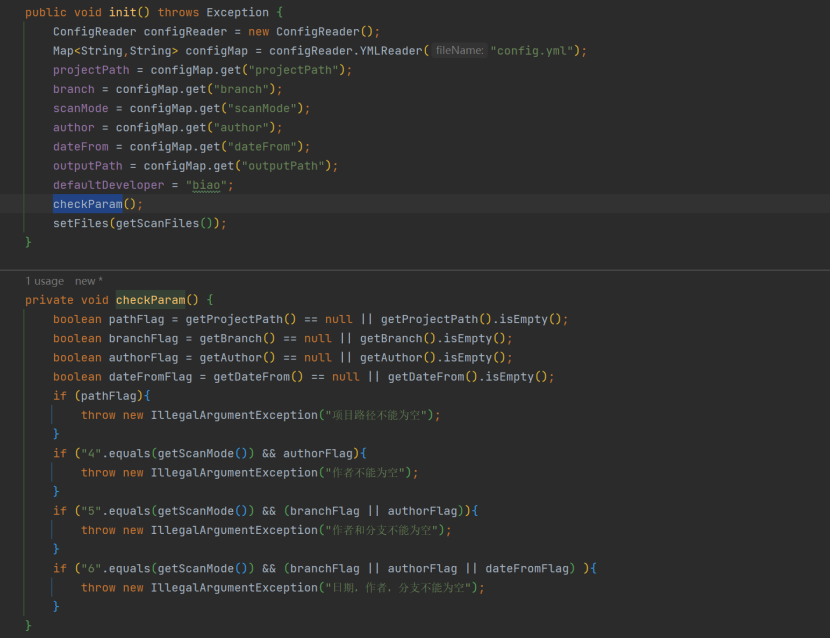
扫描模式的配置化体现在 init () 方法中使用的 getScanFiles () 方法:
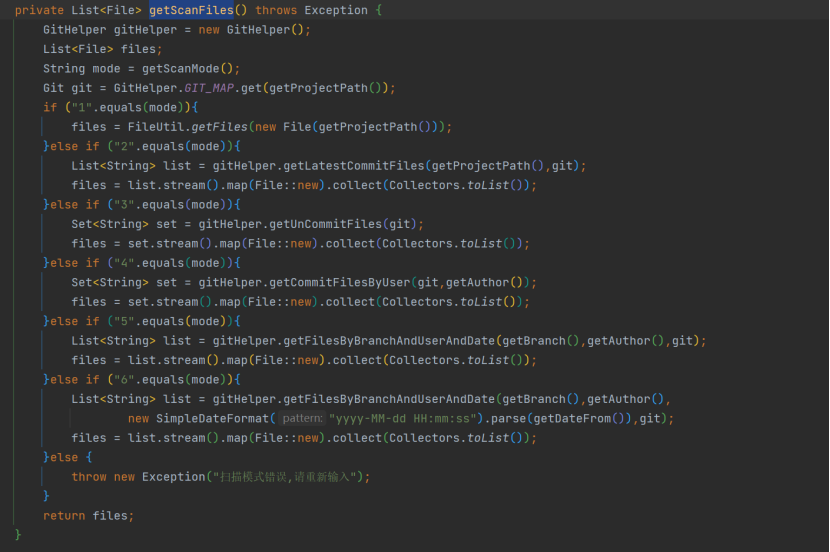
三是 outputPath 作为本地文件的输出位置,与下文中介绍的结果呈现通知相呼应。
扫描的结果呈现和通知:文件和邮件
至于扫描的结果要呈现和通知,设计上考虑既然每个规则都有扫描过程,那么必然是先收集结果,再集中呈现和通知,案例中先定义 exception.ErrorMessage 来组装结果,并在 common.RuleCode 中统一枚
举定义规则编码,做到结构清晰。

在 ErrorMessage 类中又定义了 showAndSaveMessage用于展现扫描信息,并在此方法中包含了附加的将扫描信息写入本地文件的 fileWriter ()。本案例中未实现 email 通知类,比较简单,随便找 AI 都可以帮忙
辅助生成一个,免说。思考下,这个 email 的通知放哪合适?我的推荐位置是在 fileWriter () 前后即可。
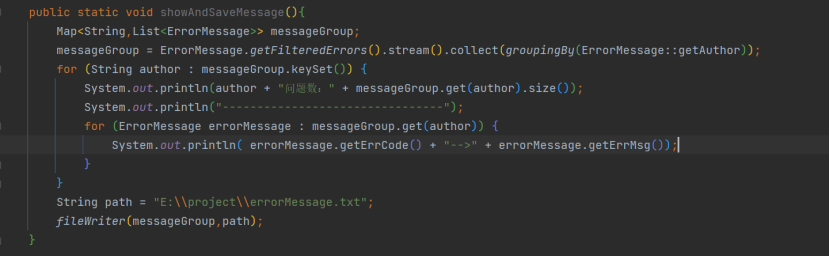
下一步定义两个 Scanner,一个是 JavaScanner,一个是 SQLScanner,JavaScanner 中即处理一个待扫描的 File,然后使用 Rule 集合逐个处理,循环完成全部的扫描过程。需要注意一下 commitMsgFunction是一
个函数式接口 Function 的实现,作为 fileScan () 的实参,后续各种 Function 的形参,其实就是这个来实现了。
**mapper文件解析实现**
Java 代码扫描的基本上已经成型,现在只剩下添加 mapper 文件的处理规则实现了,列出一些常见的 SQL 规则如下表:
|
规则名称 |
实现方式 | |
|
2 |
sql 语句中禁止存在1=1 |
SQL 语句字符串匹配 |
|
3 |
sql 语句不能使用 replace into |
SQL 语句字符串匹配 |
|
4 |
sql 语句不能使用 now () 函数 |
SQL 语句字符串匹配 |
|
5 |
Delete 语句必须有 where 条件 |
Tag+SQL 语句字符串匹配 |
|
6 |
Insert 语句不能使用 insert into t values (),必须明确列出需要写入的字段名 |
SQL 语句字符串匹配 |
|
7 |
Update 语句缺少 where 条件 |
Tag+SQL 语句字符串匹配 |
|
8 |
Select 语句缺少 where 条件 |
Tag+SQL 语句字符串匹配 |
|
13 |
createTs/updateTs 的类型必须为 Date 类型 |
SQL 语句字符串匹配 |
|
14 |
检查记录是否存在时,严禁使用 select count (*) 的逻辑 |
SQL 语句字符串匹配 |
|
15 |
CURDATE () 、CURRENT_DATE () 、NOW () 和 SYSDATE 这 4 个关键字不能直接使用 + 和 - 运算符 |
SQL 语句字符串匹配 |
前面已经探索出了使用 mybatis 获取静态和动态 SQL,虽获取了语句,但上述过程无法取得代码所在行号,难以找出提交人信息,再想想通用的 xml 的解析工具是否有什么帮助,先找 AI 来出场,提示词:请在 java
环境中,使用第三方组件解析 xml 文件,并输出节点内容和行号。结论是有 DOM 和 SAX 两种,DOM 是直接加载整个 xml 到内存,大型 xml 文件容易 OOM,且没有行号信息,需手动获取,过程复杂,SAX 是逐行
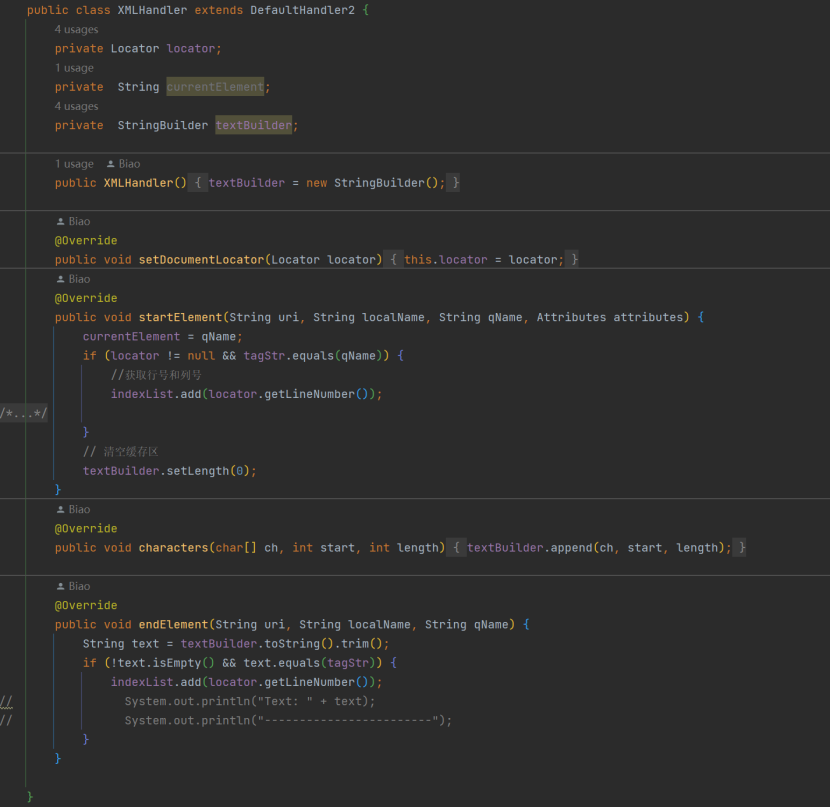
读取,还可以直接输出行号,本案例中选用 Java SAX 处理,新建 XMLLocator 类,返回所有匹配待查找字符的行号 List:
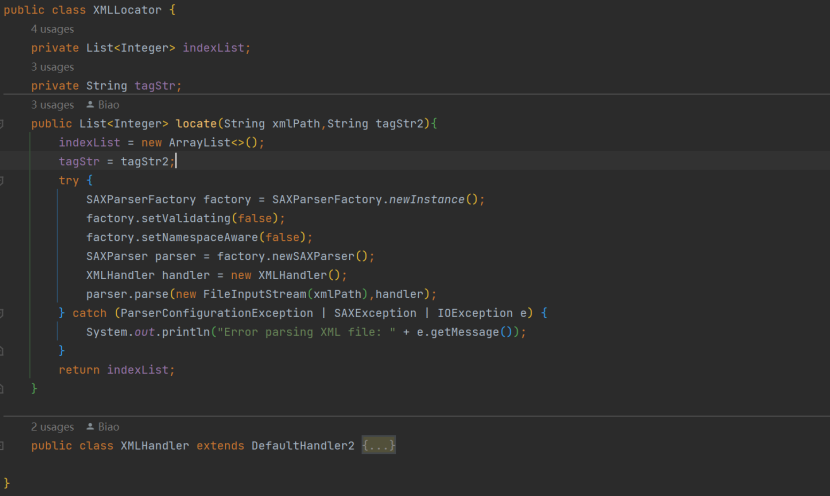
其中定义了一个内部类,继承自 DefaultHandler2,改写了 startElement 和 endElement 方法,标签或内容匹配时都记录下行号。问题又来了,要吃北京烤鸭何必上北京呢,我使用 inputStream 逐行读 xml 记录行号还
不是一样效果,当然可以!我只是体现了一种思路和探索实践。
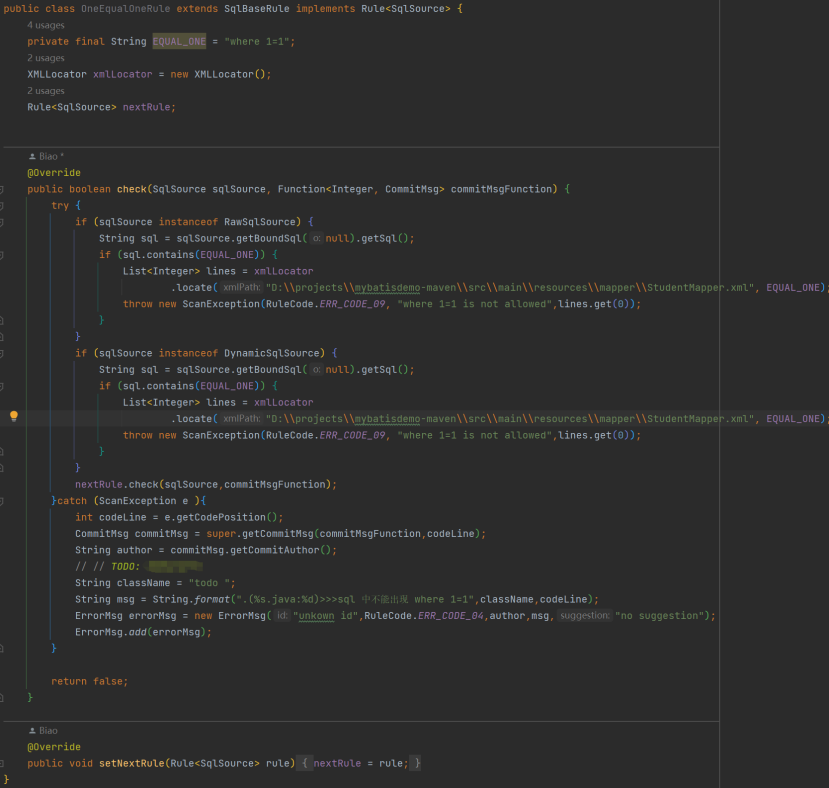
有了以上 xml 行号定位实现,参考 java,实现一个 OneEqualOneRule 规则类,重写 check 方法,处理对象换为 SqlSource:
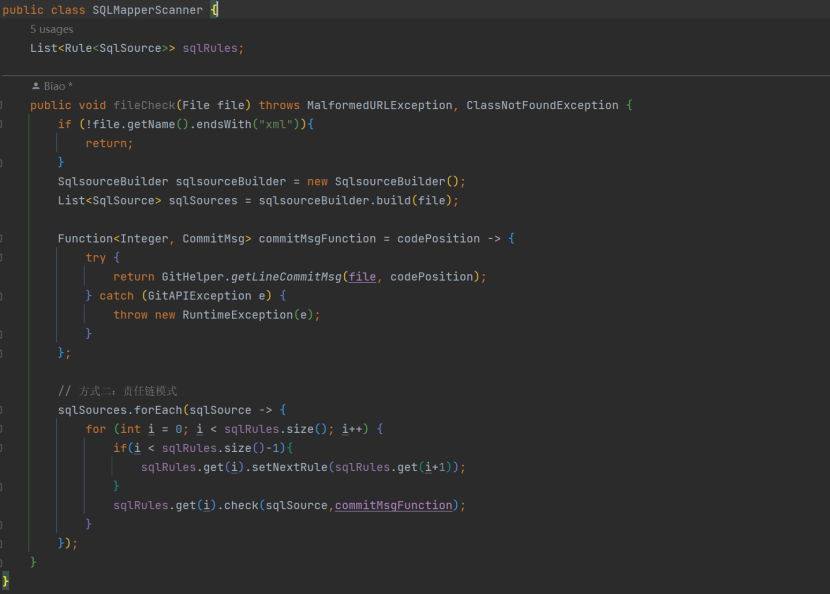
同样的模式,参考 java 写一个 SQL 的 SQLScanner 类,对一个文件进行规则的链式扫描:
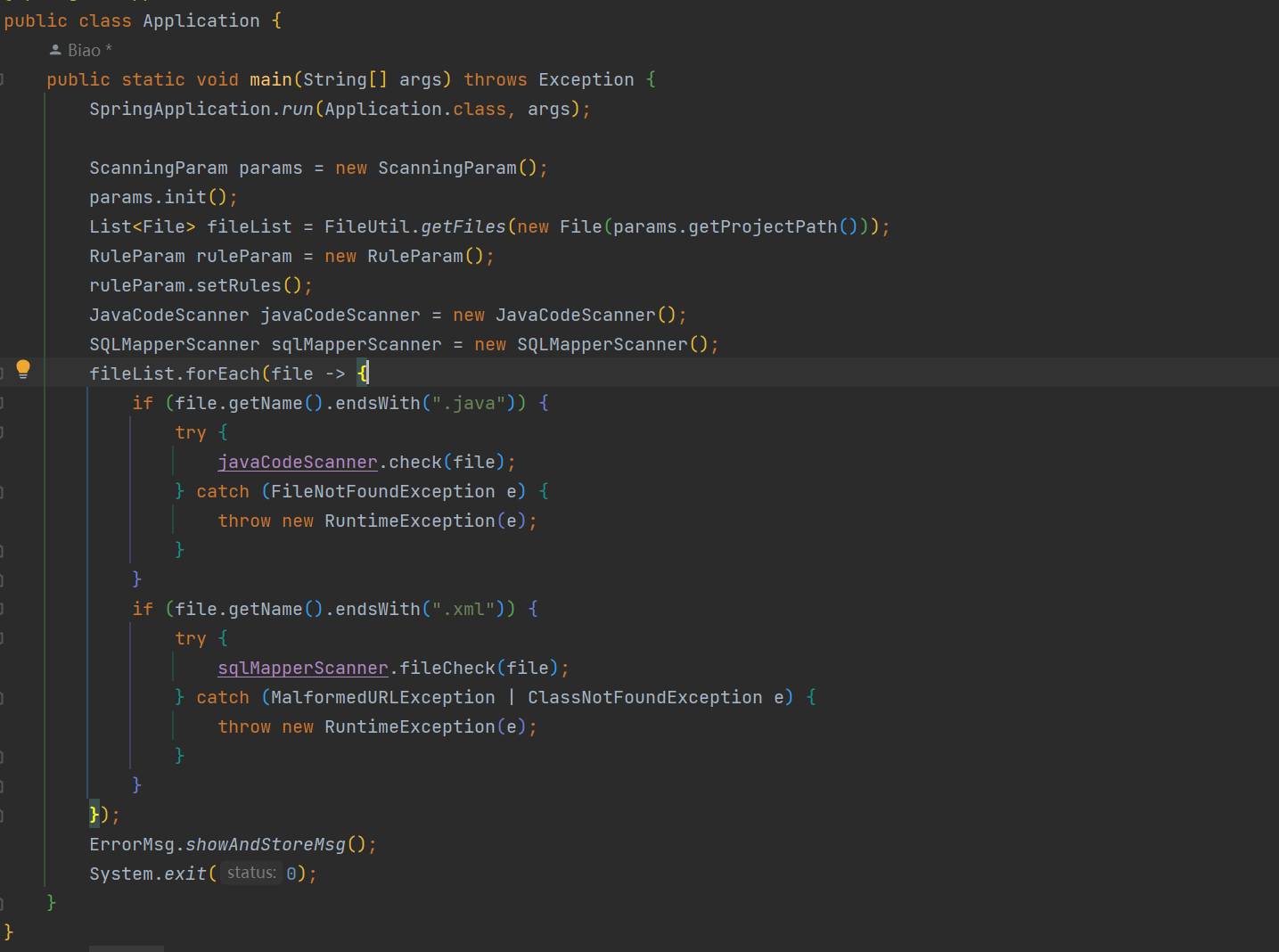
有了以上,就可以将逻辑添加到应用的入口了,AppBooter 中对 ScanningParam 取得各配置参数和文件列表,然后 RuleConfig 初始化规则,依据文件类型做分流,扫描完成后即输出结果,项目结束!
**全文小结:**
1.遗留问题与拓展方向。虽然这个代码扫描工具已经有了基本框架,但还有一些遗留问题。比如 java 中嵌套 sql 的识别与组装、Jsp 文件的扫描、对.sql/.txt 数据库脚本的扫描、生产应用中 jar 插件制作,以及工具性
能的改进等。大家可以根据项目特点,对这些功能进行扩展。对于新手来说,建议自己动手实践,遇到问题多思考、多调试。另外,文中多次借助 AI 工具获取知识和思路,但记住,AI 只是辅助,代码还是得自己看
懂、能调试通过才行。
2.思路整理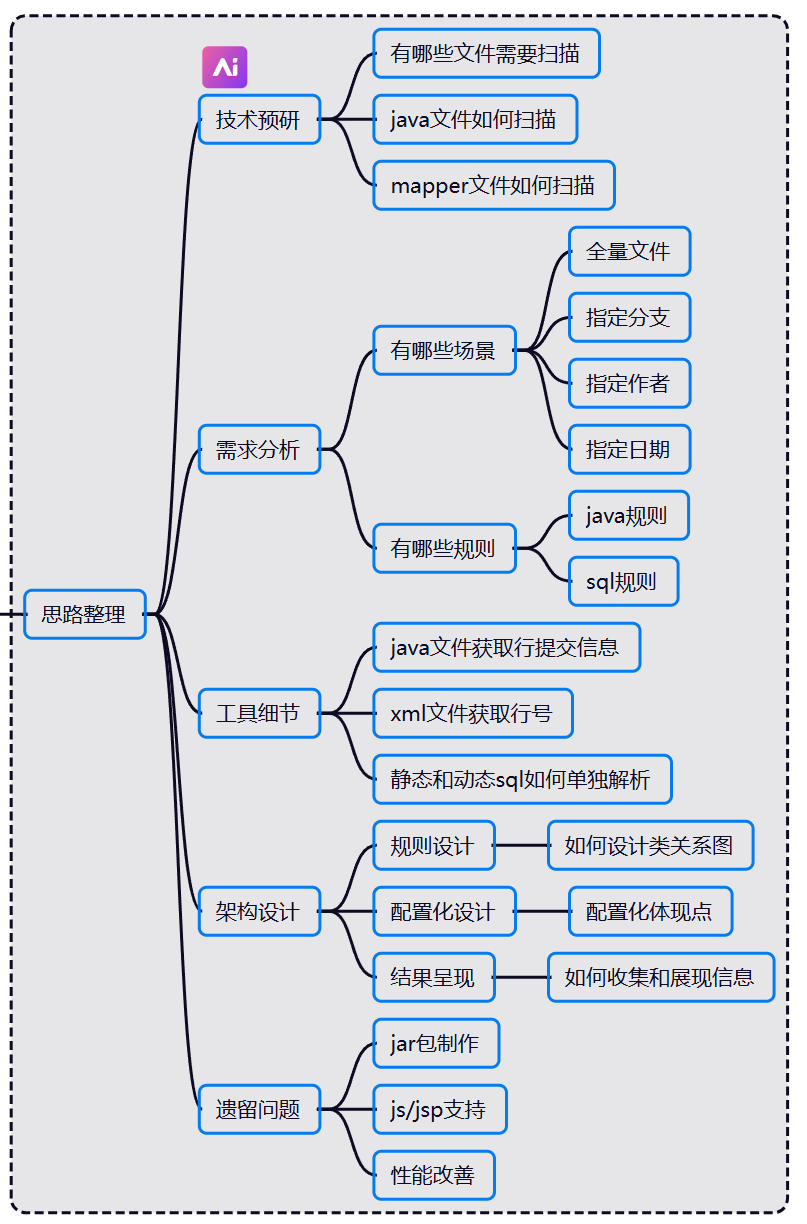
3.版本说明:案例代码基于springboot3.5+JDK21+maven3.8.8运行通过,相关依赖版本如下:
|
groupId |
Version |
|
org.eclipse.jgit |
5.13.3.202401111512-r |
|
com.github.javaparser |
3.26.2 |
|
org.mybatis |
3.5.16 |
|
com.github.jsqlparser |
5.0 |
|
org.reflections |
0.10.2 |
|
org.jdom |
2.0.6 |
希望这篇文章能帮助大家对代码扫描工具的开发有更深入的理解。如果在实践过程中有任何问题,或需要源码,欢迎留言交流!
原创不易,禁止转载