GPU到GPU通信选项技术
将讨论使用AMD Instinct™MI250和AMD InstinctTM MI250X GPU的系统中的GPU到GPU通信选项。每个MI250(X)GPU由两个图形计算芯片(GCD)组成。如图4-20所示,显示了具有4个MI250 GPU(8个GCD)的节点的示意图。每个绿色框代表一个MI250 GPU和两个GCD。GCD通过无限结构链路连接。每个Infinity结构链路的峰值带宽为50 GB/s。GCD之间的Infinity结构链接数量不同。例如,同一GPU上的GCD通过4条链路连接,而不同GPU上的GC通过1条或2条链路连接。从该图中可以观察到,GCD之间的跳数不同。例如,GCD 1通过一跳连接到GCD 3,而GCD 0至少通过两跳连接到GC 3。GCD之间可实现的最大带宽取决于GCD之间的无限结构链路的数量以及它们之间的跳数。每个绿色盒子是一个MI250 GPU,带有两个GCD。GCD通过无限结构链路连接。
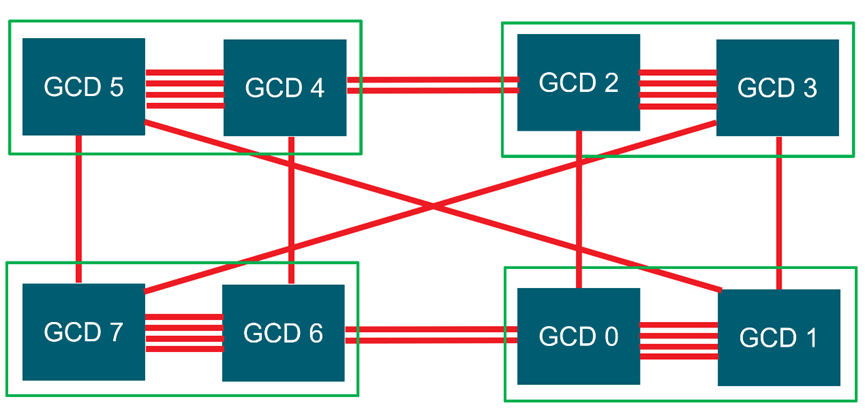
图4-20 具有4个MI250 GPU(8个GCD)的节点图
GPU到GPU通信有两种选择:
1)使用系统直接内存访问(SDMA)引擎
2)启动内核来处理通信。SDMA引擎提供了将通信与计算重叠的机会。然而,它的缺点是它在GCD之间提供了50 GB/s的最大带宽。相比之下,内核提供了更高的通信带宽,但它们需要CU移动数据,因此与内核的计算重叠通信的机会更少。环境变量HSA_ENABLE_SDMA可用于在SDMA引擎和内核之间进行选择。ROCM 5.4及以下版本默认使用SDMA引擎。
以下实验显示了大小为16MB的消息在GCD 0与其对等体之间的通信带宽。将HSA_ENABLE_SDMA设置为0。因此,启动了一个内核来处理通信。设置HIP_VISIBLE_DEMICES为每个实验选择对等GCD。使用-m((16*1024*1024)):((16*1024*11024)),指定感兴趣的消息大小,在本例中为16MiB。
export HSA_ENABLE_SDMA=0
export HIP_VISIBLE_DEVICES=0,1
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 142235.39
export HIP_VISIBLE_DEVICES=0,2
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 38963.65
export HIP_VISIBLE_DEVICES=0,3
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 36903.57
export HIP_VISIBLE_DEVICES=0,4
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 36908.74
export HIP_VISIBLE_DEVICES=0,5
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 34986.54
export HIP_VISIBLE_DEVICES=0,6
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 76276.14
export HIP_VISIBLE_DEVICES=0,7
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 68788.80
上述实验表明,为不同的对等GCD获得了不同的通信带宽。如前所述,这取决于GCD之间的Infinity Fabric链路的数量,以及它们之间的跳数。例如,GCD 0和1之间的通信速度约为142 GB/s,它们通过四个Infinity Fabric链路连接。每个Infinity Fabric链路的峰值理论带宽为50 GB/s。因此,GCD 0和1之间的峰值理论宽度为200 GB/s。假设可实现的带宽约为理论带宽的70%,预计GCD 0与1之间的通信将达到142 GB/s左右。在GCD 0和2的情况下,它们通过一个Infinity Fabric链路连接,得到38 GB/s的带宽。GCD 0与3通过两跳连接,因此获得的带宽略低(约36 GB/s)。可以使用相同的逻辑来推断其他GCD对等体的通信带宽。
如前所述,使用SDMA引擎,可以获得约50 GB/s的最大带宽:
export HSA_ENABLE_SDMA=1
export HIP_VISIBLE_DEVICES=0,1
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM 带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 49396.52
export HIP_VISIBLE_DEVICES=0,2
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试 v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
#大小 带宽 (MB/s)
16777216 41925.10
export HIP_VISIBLE_DEVICES=0,3
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 41019.50
export HIP_VISIBLE_DEVICES=0,4
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 42243.36
export HIP_VISIBLE_DEVICES=0,5
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽 (MB/s)
16777216 41870.39
export HIP_VISIBLE_DEVICES=0,6
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM 带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽 (MB/s)
16777216 49386.80
export HIP_VISIBLE_DEVICES=0,7
mpirun -n 2 $OMB_DIR/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_bw -m $((16*1024*1024)):$((16*1024*1024)) D D
# OSU MPI-ROCM 带宽测试v7.0
# 在设备(D)上发送缓冲区,在设备(D)上接收缓冲区
# 大小 带宽(MB/s)
16777216 49369.06