上次我们讨论了如何将自己的开源项目发布到 Maven 中央仓库,确保其能够方便地被其他开发者使用和集成。而我们的项目 spring-ai-hunyuan 已经具备了正常的聊天对话功能,包括文本聊天和图片理解等基础功能。今天,我们进一步优化和扩展了该项目,新增了一个向量化功能。如图所示:
好的,首先就是对接API接口。我们开始。
向量功能
接口调用
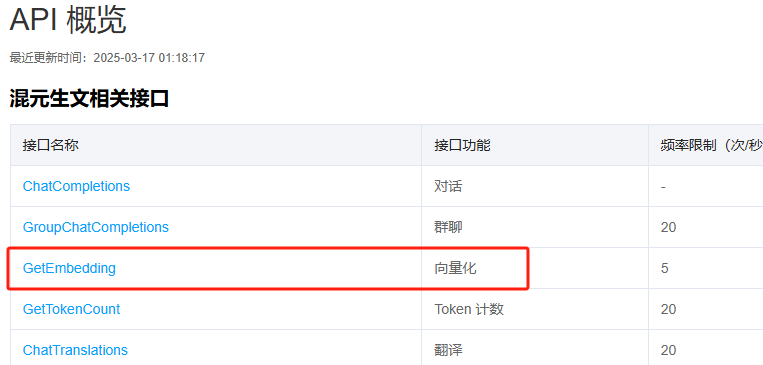
腾讯的所有接口共享同一个域名,并且接口之间并没有按照请求路径进行细分。主要依赖请求头中的action字段来区分不同的接口调用。通过这种方式,接口能够在同一个域名下通过不同的请求头信息进行区分和处理,如下图所示:

所以,我们以前写的HunYuanAPI类就需要改一下,否则他默认走的全是聊天接口。修改如下:
ResponseEntity<EmbeddingResponse> embeddingResponseResponseEntity = this.restClient.post().uri("/").header("X-TC-Action", HunYuanConstants.DEFAULT_EMBED_ACTION).body(embeddingRequest).retrieve().toEntity(EmbeddingResponse.class);
在正常调用过程中,header字段用于区分不同的接口请求。这是因为在我使用的restClient加密方式中,采用了拦截器的形式。通过这种方式,每次请求发起时,拦截器都会被触发,从而使我能够轻松地读取到请求头中的相关信息。
这样一来,我可以在请求的整个生命周期内获取和处理这些信息。具体实现细节如下所示:
@Override
public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException {String action = request.getHeaders().getFirst("X-TC-Action");MultiValueMap<String, String> httpHeadersConsumer = hunYuanAuthApi.getHttpHeadersConsumer(action, body);.......
}
通过这种方式,我们不再依赖于写死的固定值来传递参数,而是能够动态地处理每次请求时的不同值。完成接口调用的处理后,接下来需要关注的是输入参数的管理与传递。
输入参数
这里的输入参数有两个可选值,如图所示:

为了简化对接过程,我们选择直接使用数组类型的输入形式。这种方式不仅使得数据传递更加直观和高效,而且与Spring AI的内部处理机制高度契合。Spring AI在处理数据时,本身也会将输入数据自动转化为数组形式进行处理,具体的实现方式如下所示:
default float[] embed(String text) {Assert.notNull(text, "Text must not be null");List<float[]> response = this.embed(List.of(text));return response.iterator().next();
}
输出参数
处理完了输入参数,那么紧接着就是输出参数了。如图所示:
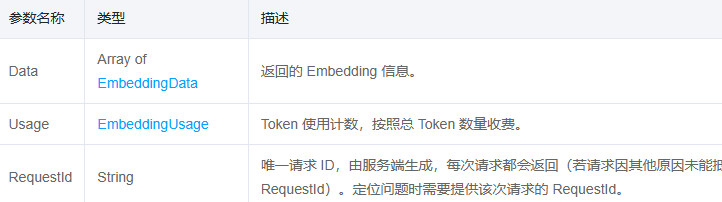
但是,腾讯接口有一个共同特点,就是所有输出参数都被Response字段包围着。所以我们还需要单独处理一下,如下所示:
ResponseEntity<EmbeddingResponse> embeddingResponseResponseEntity = this.restClient.post().uri("/").header("X-TC-Action", HunYuanConstants.DEFAULT_EMBED_ACTION).body(embeddingRequest).retrieve().toEntity(EmbeddingResponse.class);return embeddingResponseResponseEntity.getBody().response();
EmbeddingResponse的结构如下:
@JsonInclude(Include.NON_NULL)
public record EmbeddingResponse(// @formatter:off@JsonProperty("Response") EmbeddingList response
) {// @formatter:on
}
@JsonInclude(Include.NON_NULL)
public record EmbeddingList(// @formatter:off@JsonProperty("RequestId") String object,@JsonProperty("Data") List<Embedding> data,@JsonProperty("Usage") Usage usage) { // @formatter:on
}
自动配置
在正常完成接口调用的编写之后,接下来我们需要着手进行Spring Boot的自动配置编写。
HunYuanEmbeddingProperties
首先一个配置类解析,将配置文件中的配置信息读取到类中,如下所示:
@ConfigurationProperties(HunYuanEmbeddingProperties.CONFIG_PREFIX)
public class HunYuanEmbeddingProperties extends HunYuanParentProperties {public static final String CONFIG_PREFIX = "spring.ai.hunyuan.embedding";public static final String DEFAULT_EMBEDDING_MODEL = "hunyuan-embedding";.......
}
HunYuanAutoConfiguration
这里就是单独配置一下我们需要的embedding模型的接口配置了。如图所示,先将配置类添加到注解中。

然后我们需要注入一下HunYuanEmbeddingModel模型。代码如下:
@Bean
@ConditionalOnMissingBean
@ConditionalOnProperty(prefix = HunYuanEmbeddingProperties.CONFIG_PREFIX, name = "enabled", havingValue = "true",matchIfMissing = true)
public HunYuanEmbeddingModel hunYuanEmbeddingModel(HunYuanCommonProperties commonProperties,HunYuanEmbeddingProperties embeddingProperties, ObjectProvider<RestClient.Builder> restClientBuilderProvider,ObjectProvider<WebClient.Builder> webClientBuilderProvider, RetryTemplate retryTemplate,ResponseErrorHandler responseErrorHandler, ObjectProvider<ObservationRegistry> observationRegistry,ObjectProvider<EmbeddingModelObservationConvention> observationConvention) {var hunyuanApi = hunyuanApi(embeddingProperties.getSecretId(), commonProperties.getSecretId(),embeddingProperties.getSecretKey(), commonProperties.getSecretKey(), embeddingProperties.getBaseUrl(),commonProperties.getBaseUrl(),restClientBuilderProvider.getIfAvailable(RestClient::builder),responseErrorHandler);var embeddingModel = new HunYuanEmbeddingModel(embeddingProperties.getOptions(), retryTemplate,hunyuanApi, embeddingProperties.getMetadataMode(),observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP));observationConvention.ifAvailable(embeddingModel::setObservationConvention);return embeddingModel;
}
这样一来,我们基本上已经完成了Spring-AI-Hunyuan中向量化功能的集成和配置工作,确保了系统能够顺利进行向量化处理,并与其他模块良好协作。接下来的步骤便是编写单元测试,由于单元测试的编写较为标准且常见,这部分内容就不再详细赘述。
小结
在本次更新中,我们进一步优化了spring-ai-hunyuan项目,新增了向量化功能。首先,我们对接了腾讯API,通过修改HunYuanAPI类来支持不同接口的调用,确保请求头能够正确区分接口类型。接着,我们处理了输入输出参数的管理,将数据以数组形式传递,并适应Spring AI的处理机制。同时,完成了Spring Boot自动配置,确保向量化功能能够顺利运行并与其他模块协同工作。
我是努力的小雨,一个正经的 Java 东北服务端开发,整天琢磨着 AI 技术这块儿的奥秘。特爱跟人交流技术,喜欢把自己的心得和大家分享。还当上了腾讯云创作之星,阿里云专家博主,华为云云享专家,掘金优秀作者。各种征文、开源比赛的牌子也拿了。
💡 想把我在技术路上走过的弯路和经验全都分享出来,给你们的学习和成长带来点启发,帮一把。
🌟 欢迎关注努力的小雨,咱一块儿进步!🌟