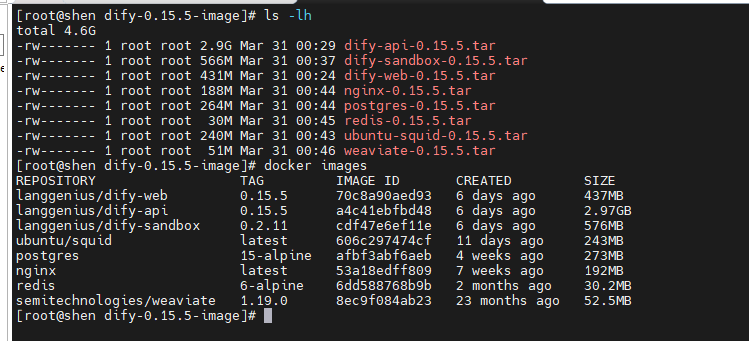
from xmindparser import xmind_to_dict import pandas as pd from openpyxl.workbook import Workbook import os# 可以设想为一个树结构,利用递归函数,获取由根至各叶子节点的路径。 def xm_parse(dic, pre_data=[]):"""输入一个由xmindparser,转换而来的字典形式的数据,将之转换成列表"""title_list = []topic_list = []try:topics = dic.get("topics")title = dic.get("title")# 将前缀追加 title_list.append(title)title_list = pre_data + title_list# 如果到达末尾,就返回if topics is None and title:yield title, title_list# print(title,title_list)return# 如果是列表,就暂存起来(若每个对象为标准的列表,即 topics= topic_list,则可以跳过该步骤)elif isinstance(topics, list) and title:for topic in topics:topic_list.append(topic)except AttributeError as e:print("异常结束")returnif topic_list:for topic in topic_list:yield from xm_parse(topic, title_list)def main():currently_path = os.getcwd()for filename in os.listdir(currently_path):if filename.endswith('.xmind'):xm_path = currently_path + "/" + filenamebreakx_flie = xm_pathnew_filename = filename[:-6] + ".xlsx"out_file = currently_path + "/" + new_filenametemp = []max_cols = 0json_data = xmind_to_dict(x_flie)# 提取数据,并找出最大深度(列数)for i, j in xm_parse(json_data[0]['topic']):temp.append(j)max_cols = max_cols if max_cols > len(j) else len(j)# 对缺失数据采用补全for i in range(len(temp)):temp[i] = temp[i] + (max_cols - len(temp[i])) * [None]result = pd.DataFrame.from_records(temp, columns=["标题-{}".format(i + 1) for i in range(max_cols)])# result.to_excel(out_file,index=False,encoding='utf-8-sig')result.to_excel(out_file, index=False)if __name__ == '__main__':main()

![B3688 [语言月赛202212] 旋转排列](https://img2024.cnblogs.com/blog/3619440/202503/3619440-20250331161851997-1444060053.png)
![B3689 [语言月赛 202212] 宇宙密码](https://img2024.cnblogs.com/blog/3619440/202503/3619440-20250331155752201-1179979371.png)