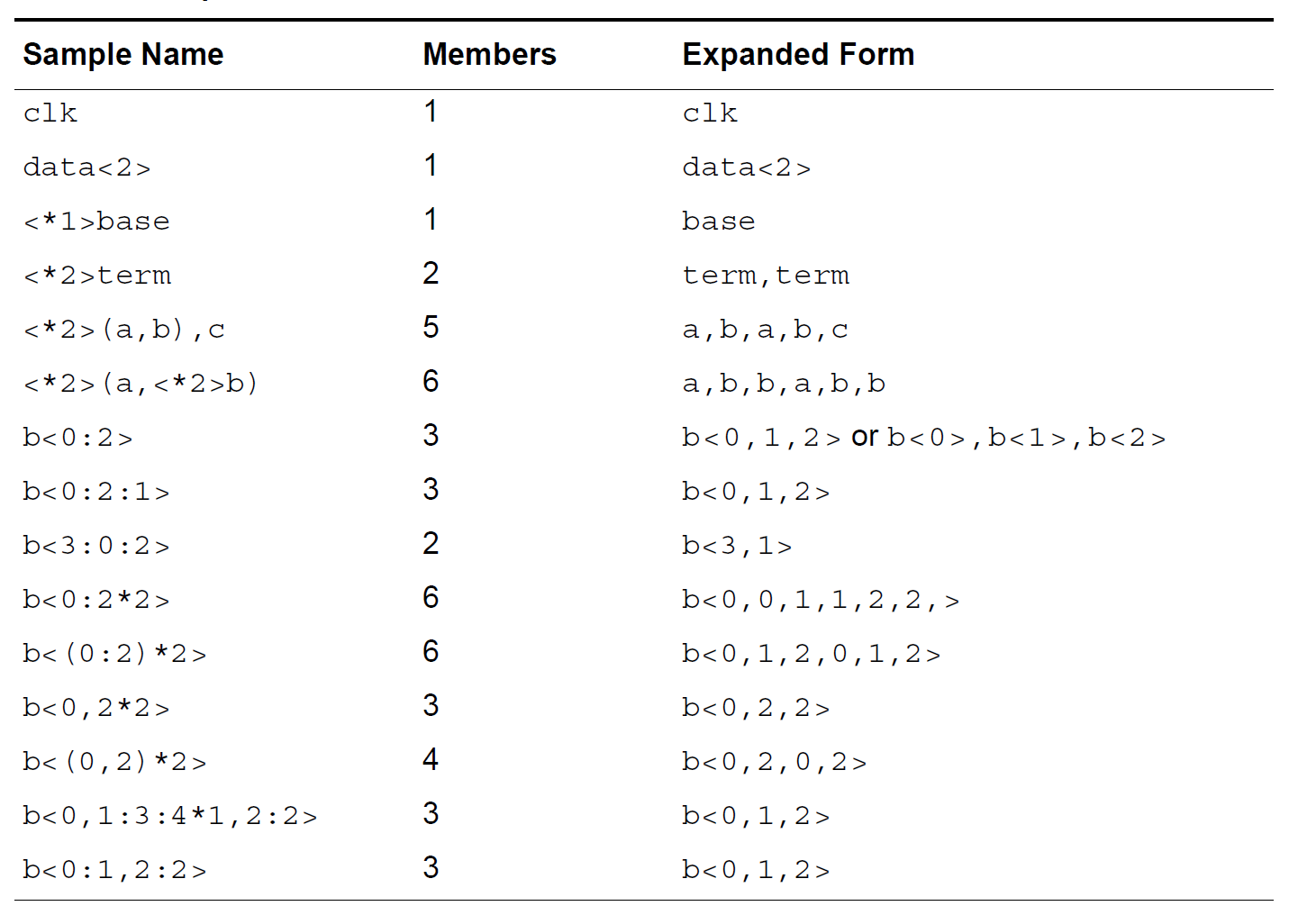
作者:执少
引言
在亿级日志分析中,你是否遇到过结果不精确导致误判的困扰?多次查询,仍然结果不精确,怎么办? 别担心,阿里云 SLS 全新推出「SQL 完全精确」模式,如何在超大规模数据下确保分析结果零误差?3 分钟解锁关键能力!
SQL 查询为何不精准
在 SLS(日志服务)中,超大规模日志数据分析时可能出现“结果不精确”的提示。原因在于部分数据未能完全加载,导致这些数据未参与 SQL 计算。

数据加载中断的常见原因包括时间片耗尽、数据量/数据行数/IO 操作次数超过阈值等情况,这些情况可能导致部分数据未能完全加载,从而影响结果的精确性,具体限制请参见查询与分析限制说明【1】。
这是糟糕的设计吗?
并非如此。SLS 基于云上多租户在线实时分析场景的特点,采取了权衡策略。这种设计旨在应对以下挑战:
- 恶意攻击: 防止系统资源被大量恶意请求占用,避免全线崩溃,影响全量用户。
- 用户误用: 避免某条复杂 SQL 耗尽租户的资源配额,影响其他业务请求。
- 用户体验: 在包含多图表的仪表盘分析场景中,部分不精确结果优于全盘失败。
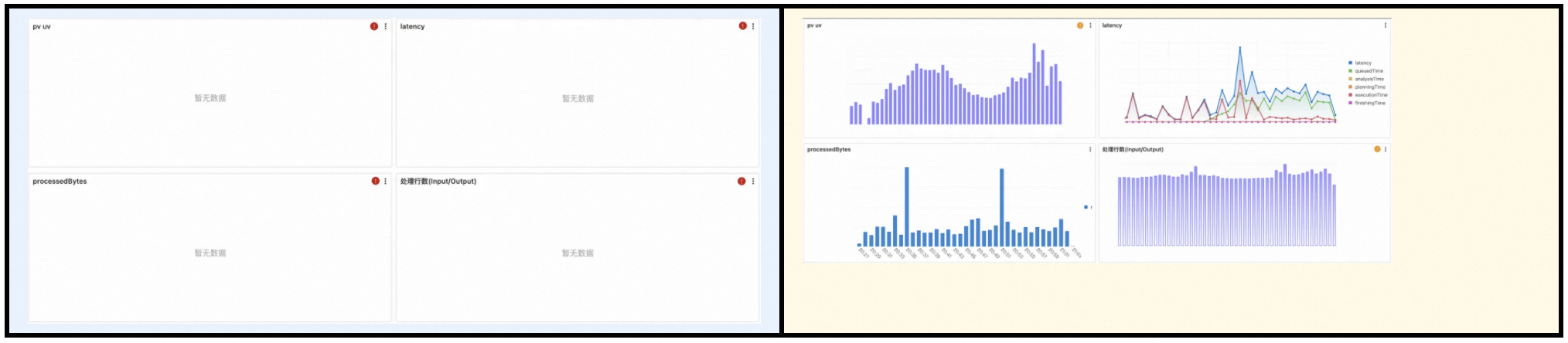
通过设置系统级和用户级资源上限,以“不精确”为代价,SLS 实现了资源保护与用户体验的平衡。
SQL 完全精确仍是刚需
尽管不精确模式适用于快速分析,但在严肃业务场景中,完全精确的 SQL 查询不可或缺。典型场景包括:
-
业务监控告警: 不精确可能导致的漏报或误报,影响系统应急响应。例如安全监控因部分日志未加载,攻击行为漏报引发资损。
-
业务运营分析: 营收、财账、留存、转化等关键指标分析需严肃准确,否则影响运营策略和决策。例如:某电商大促期间日志量激增,普通 SQL 漏算 3% 订单数据,导致 GMV 统计误差。
-
在线数据服务: 对外提供数据服务时,分析结果的准确性需严格保证,提供在线联机数据分析能力(OLTP/OLAP)。例如:财务对账要求 100% 精确,普通模式无法满足审计需求。
全新的 SQL 完全精确模式
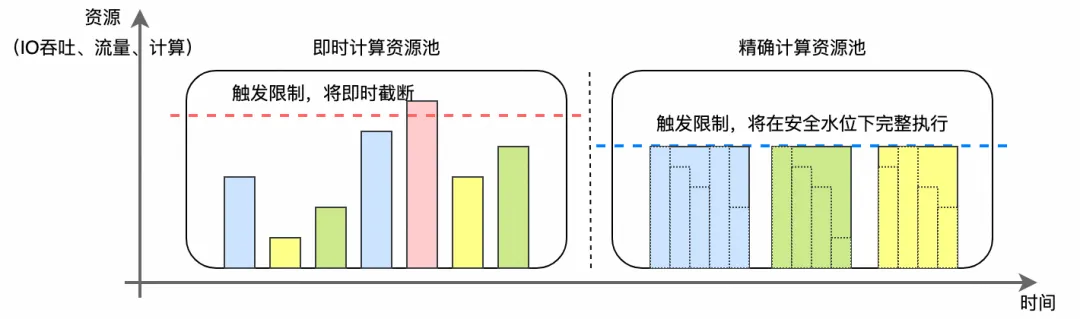
为满足精确需求,SLS 推出了「SQL 完全精确」模式,通过时间换资源的方式确保结果精确完整。通俗来讲普通模式为保障多租户资源公平,采取超限时“牺牲精度保速度”,类似高速公路流量大时临时关闭入口。而完全模式采取独享资源池 + 时间换精度,就像为 VIP 用户开辟专用车道,允许延长通行时间。
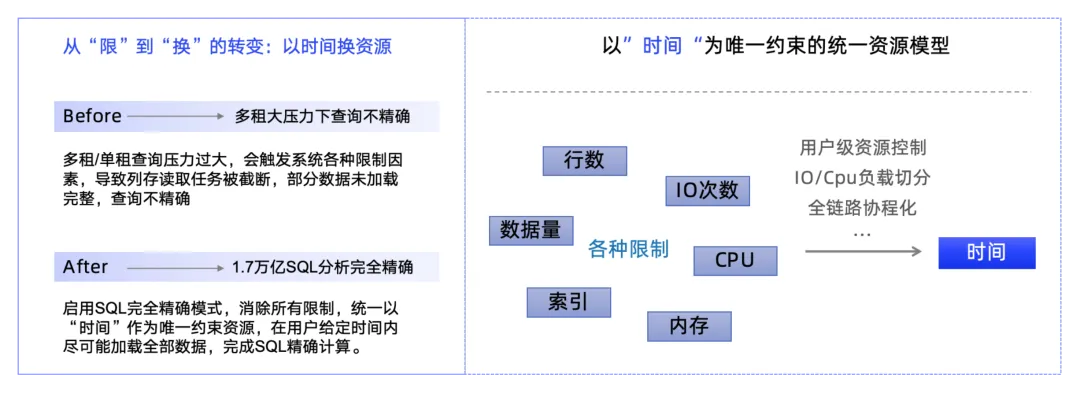
实现原理
-
资源隔离: 将即时计算与精确计算分离,分别运行于不同资源池。
-
时间换资源: 在用户指定时间内,Query 稳定运行直至完成精确计算或超时。
-
负载切分: 针对计算密集型和 IO 密集型任务进行负载切分,优化资源分配。
-
细粒度流控: 实现用户级 Qos 管控能力,针对不同用户、不同任务类型、不同工作负载实现精细化控制,确保即使在系统瞬时高压力下也能保证多租用户的正常服务能力。
适用场景
该模式适用于超大规模数据集的分析场景,尤其是对计算结果有严格精确需求的场景,比如:
-
关键业务指标分析: 在涉及企业核心运营数据(如收入、成本、利润率、转化率、留存率等)的分析场景中,任何微小的误差都可能导致决策失误。此时,SQL 完全精确模式是不可或缺的选择。
-
长周期趋势分析: 对于需要跨越较长时间周期(如季度或年度)的日志数据分析任务(例如年度运营报表),数据完整性至关重要。结果不精确将导致趋势分析结果失真,影响对业务变化的洞察。
-
复杂多列聚合: 当查询涉及多个维度的复杂聚合时,默认模式可能因加载多列数据而很容易触发系统限制,造成部分数据加载不全,结果不精确。而完全精确模式能够确保所有维度的数据均被纳入计算,保证最终结果精确。
-
大宽列分析: 当日志中包含无结构或半结构的超长文本数据时,比如超长字符串,超大 JSON 等(SQL 默认支持最大 64KB),业务需要从这些大宽列中提取和分析有效数据,一旦日志数据规模过大,默认模式可能会加载不全,结果不精确,SQL 完全精确模式可以有效解决此类问题。
-
超大规模数据分析: 单条 Query 需要分析百 GB 或 TB 级数据量、千亿或万亿级数据行,对于这种超大规模的数据分析,SQL 完全精确模式可以有效解决。
同时,注意该模式并不适用于:高并发的快速分析场景,尤其是对分析延时极为敏感、有毫秒级响应需求的场景。
优化建议
尽管 SQL 完全精确模式解决了结果精确的问题,但其资源消耗和执行时间与数据规模成正相关,相较于默认模式可能会有显著增加,查询的响应行为也可能有所差异。因此,在实际应用中,建议用户根据业务自身特点合理选择使用场景,并结合资源优化策略以提升效率。
-
合理设置查询时间窗口: 完全精确模式的执行时间与数据量成正比。在满足业务需求的前提下,尽量缩小查询的时间范围,减少不必要的数据扫描量,从而缩短执行时间。
-
利用索引加速查询: SLS 支持多种索引类型(如全文索引、数值索引、JSON 类型等)。为关键字段创建高效索引,可以大幅降低无效数据扫描,显著提升查询性能,尤其是在完全精确模式下,索引的作用更加突出。
-
预处理数据以降低复杂度: 对于高频使用的复杂查询,可考虑通过 ScheduledSQL 定时任务提前对原始日志数据进行清洗、转换和预聚合,生成中间表或视图,以简化后续查询逻辑。
-
先小规模验证再大规模执行: 在首次启用完全精确模式时,建议先对小规模数据集(如选取小段时间)进行测试,验证查询逻辑的正确性和性能表现。待确认无误后,再扩展至更大范围和规模的数据分析任务。
-
合理设置最大执行时间: 在启用完全精确模式时,时间是唯一的约束资源,合理设置 Query 的最大执行时间(下文详述),将有助于用户合理分配资源使用,避免超大 Query 影响其他正常查询,同时也能有效控制业务查询的响应延时。
能力限制
该模式在数据处理和计算能力的上限方面有显著增强,但同时也具有相关的约束限制。

SQL完全精确模式有其自身的能力边界,其核心能力:在给定的时间资源下,确保整个计算过程的完整稳定运行。但其并不覆盖以下能力范畴:
-
内存超限: 在计算过程中,当数据在单节点上的驻留内存超过上限(10GB)时将查询失败。
-
执行超时:同步查询(控制台或 API/SDK 调用)执行时间上限为55秒,异步查询(下载或 ScheduledSQL)执行时间上限为 10min,超过执行时间上限将查询超时。
-
并发超限:该模式可能会使用更多的 IO 和计算资源,因此单 Project 的并发上限为 5,超过将排队,排队长度为 100,排队超限将查询失败。
-
内部错误:某些非预期的内部错误(如列存编码错误等)仍然可能会标记不精确。
与此同时,选择独享 SQL 时,如果数据规模超过了系统最大处理能力,增强 SQL 和完全精确 SQL 在行为表现上存在一定的差异:增强 SQL 可能在有限时间内返回不精确的结果;而完全精确 SQL 要么返回精确结果,要么将查询失败(在给定时间资源耗尽后返回超时失败)。
请用户结合自身业务情况和分析场景合理选择不同 SQL 模式,当然也可以通过 query_max_run_time 设置 Query 最大执行时间,控制资源使用上限,避免超大 Query 影响其他正常查询。
如何使用
支持控制台、仪表盘、API 及 SDK 等多种方式启用:
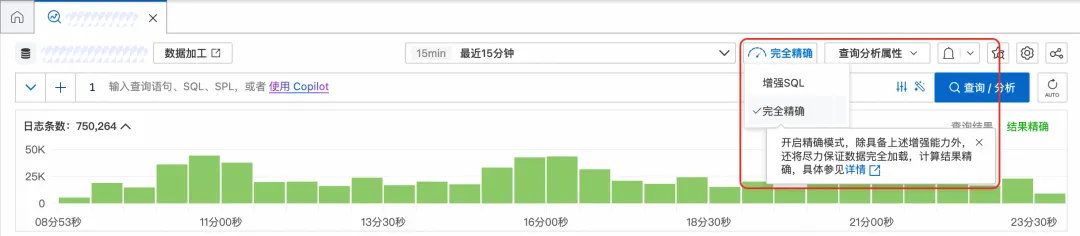
- 控制台: 在查询选项中开启“完全精确”。
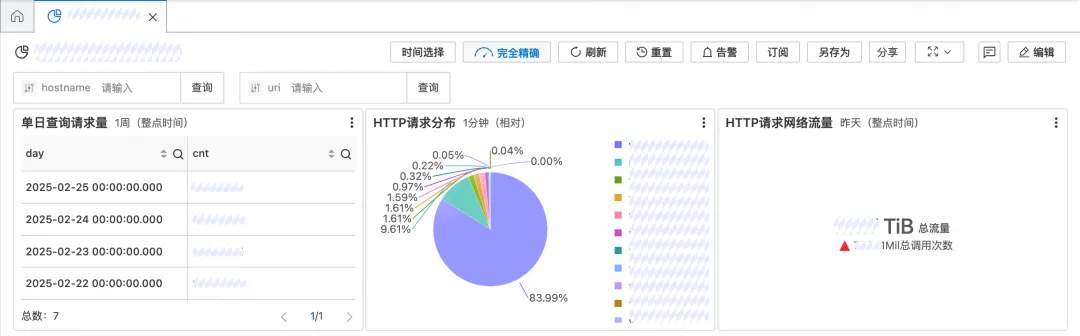
- 仪表盘: 在查询选项中开启“完全精确”。
- API/SDK: 以 Java SDK 为例,通过参数设置启用。
// 引入Maven依赖
// <dependency>
// <groupId>com.aliyun.openservices</groupId>
// <artifactId>aliyun-log</artifactId>
// </dependency>public void demo() throws LogException {final String PROJECT = "...";final String LOGSTORE = "...";final String Query = "* | SELECT ..."final int FROM = (int)(System.currentTimeMillis()/1000) - 60;final int TO = (int)(System.currentTimeMillis()/1000);GetLogsRequest request = new GetLogsRequest(PROJECT, LOGSTORE, FROM, TO, "", QUERY);request.SetSession("allow_incomplete=false");GetLogsResponse response = client.GetLogs(request);System.out.println("Complete:" + response.IsCompleted());
}
- 如何控制 Query 最大执行时间
SQL 完全精确模式将保持 Query 稳定运行,直至完成精确计算或执行超时。用户在使用该模式时,需结合业务特性和延时需求,对于有响应延时上限要求的查询,可以指定最大执行时间,以控制资源使用上限。
通过设置参数 query_max_run_time 控制 Query 最大执行时间
方式一:在SQL中设置Session
示例: | set session query_max_run_time=100ms; SELECT ...*
方式二:在SDK中设置Session(以Java SDK为例)
示例:GetLogsRequest.SetSession("query_max_run_time=100ms");
参数说明:
1、query_max_run_time表示本次Query允许执行的最大时间
2、时间单位支持可读性,如100ms, 1s, 5s等等
3、预期返回:抛出LogException,httpCode=400, message='Query exceeded maximum time limit: <..>'
性能对比
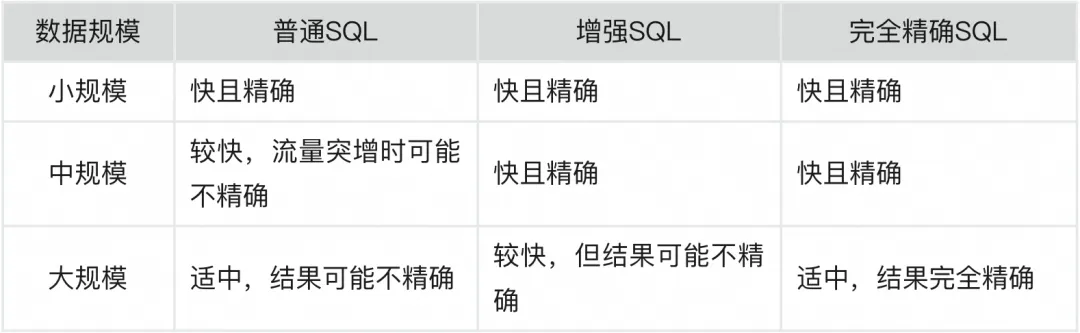
SQL 完全精确模式并非普通或增强模式的“限流阉割”版本,在绝大多数情况下,性能与增强模式相当;而在处理超大规模数据时,其与增强模式行为表现略有异同,下表针对不同数据规模和模式,进行了性能的定性比较。
SLS SQL 模式全景
SLS 为用户提供了覆盖全场景的多种 SQL 分析模式,不同模式适用于不同的业务需求与分析场景,能够满足从探索性分析到精细化运营的多层次需求。
下图展示了一个能力象限模型,描绘了在不同的业务阶段和规模下,如何通过选择适当的SQL模式来最大化业务的数据分析效能。

- 初创探索期:敏捷洞察与快速迭代
在业务初期,产品通常快速发布和迭代,日志数据高效汇集到 SLS,使用普通 SQL 不断进行业务探索和分析,可以快速发现产品缺陷、性能瓶颈和服务异常等,从而不断提升产品和服务能力。
- 稳定期:系统化数据处理与高效赋能
进入稳定期后,业务的关注点逐渐从“发现问题”转向“保障稳定”。此时,使用普通 SQL 构建持续的服务监控体系、智能化告警机制以及全链路可观测能力;使用 ScheduledSQL 实现数据的定时周期清洗、加工与转换;面对高并发和高性能查询场景,使用增强 SQL 快速高效且低成本地实现业务的实时在线数据服务能力。
- 精细化运营:精准分析与业务决策
最后,SQL完全精确则为数据驱动的决策提供强有力的支持。面对超大规模数据时,针对业务运营、财账、转化及留存等关键指标和严肃业务场景提供可靠的数据分析能力,辅助业务精准决策。
结语
SLS 全新推出的「SQL 完全精确」模式,通过“限”与“换”的策略切换,在快速分析与精确计算之间实现平衡,满足用户对于超大数据规模分析结果精确的刚性需求。标志着其在超大规模日志数据分析领域再次迈出了重要的一步。这一功能不仅填补了默认快速分析模式在查询结果精度上的不足,还为 SLS 在面对严肃分析场景时提供了可靠的数据分析能力。SLS 将持续致力于为客户提供不断增强的可观测和分析能力,支持客户在关键业务场景上的不断演进、拓展与创新。
相关链接:
【1】查询与分析限制说明
https://help.aliyun.com/zh/sls/product-overview/query-and-analysis
【2】Shard
https://help.aliyun.com/zh/sls/product-overview/shard
【3】OCU
https://help.aliyun.com/zh/sls/product-overview/billable-items#e21cbfc5b016s
点击此处 ,了解更多产品详情!