目录
1、正排索引和倒排索引
2、什么是Elasticsearch
3、es核心概念
索引:
文档:
域:
4、安装es和可视化工具Kibana
5、原生操作es
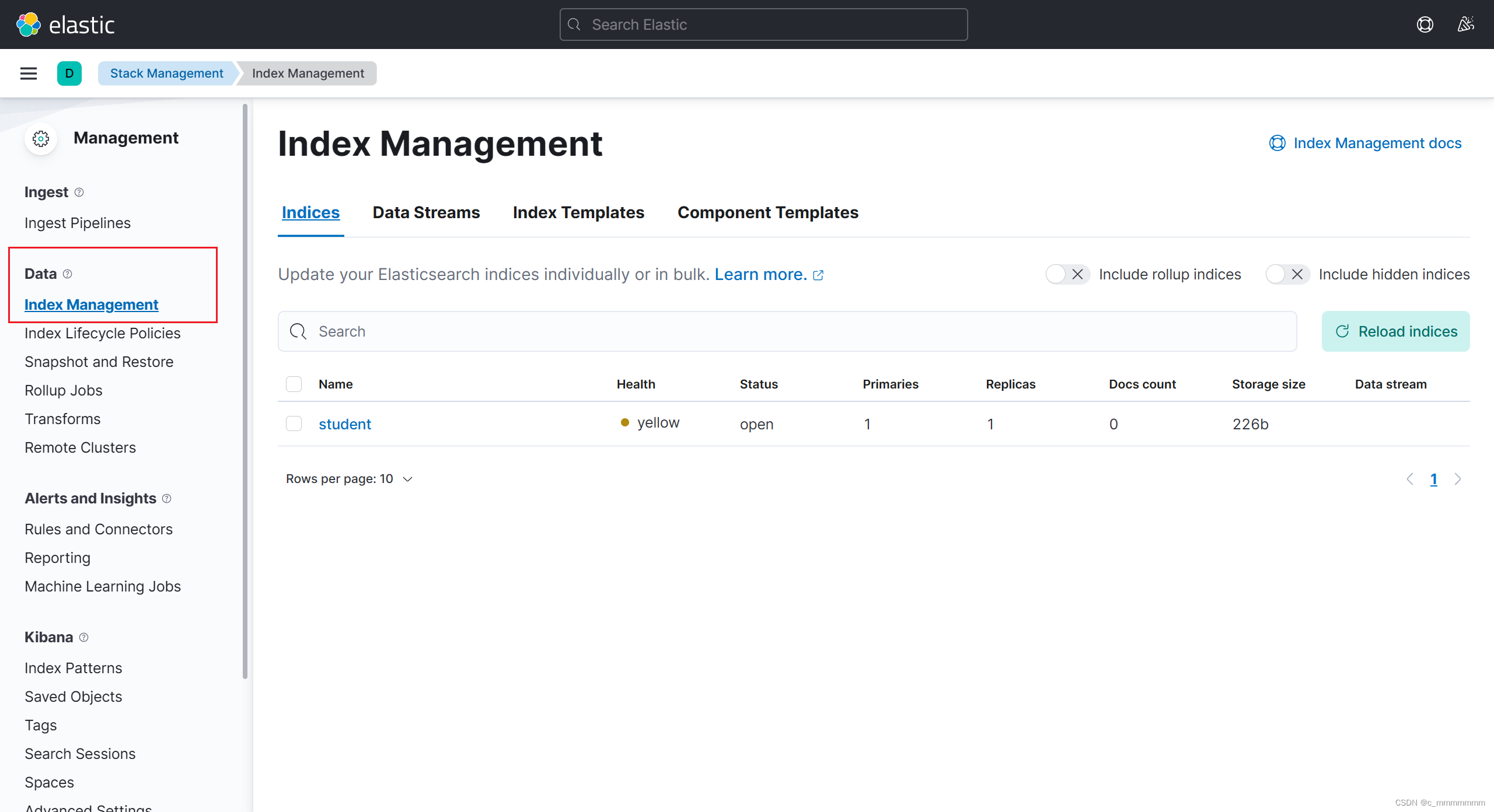
索引操作
新增索引
删除索引
文档操作
新增文档
修改文档
删除文档
查询文档
查询所有文档
分词器
默认分词器
IK分词器
IK拼音分词器
自定义分词器
复杂查询
条件查询
排序查询
分页查询
复合搜索
高亮显示
自动补全
6、SpringDataEs操作es
项目搭建
创建实体类
Repository接口方法
DSL查询文档
按照规则命名查询
分页查询
结果排序
template操作:
操作索引
创建索引
删除文档
增删改文档
查询文档
复杂查询
分页排序
结果排序
7、实战案例
实现功能
项目搭建
编写Repository层
编写Service层
编写Controller层
编写前端页面
部分图片来自百战程序员
1、正排索引和倒排索引
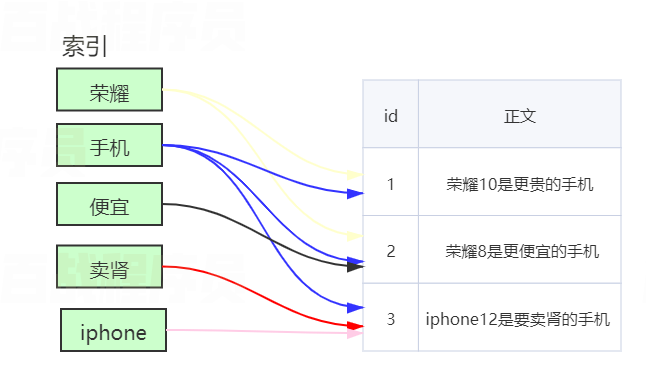
索引:索引是将数据中的一部分信息提取出来,重新组织成一定的数据结构,我们可以根据该结构进行快速搜索,这样的就够称之为索引。索引即目录,例如词典会将字的拼音提取出来做目录,通过目录可以快速找到字的位置,索引分为正排索引和倒排索引
正排索引:将文档id建立为索引,通过id快速查找数据,就像数据库中的主键就会建立正排索引

倒排索引:倒排索引就不是通过id建立索引了,而是通过提取数据中的关键字,然后将关键字建立为索引,通过匹配的关键字去查询数据
2、什么是Elasticsearch
- Elasticsearch 是一个免费且开放的分布式搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。
- Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 RESTFUL 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;
- Elastic Stack 是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据
3、es核心概念
索引:
索引对应的就是数据库中的表
文档:
文档对应的就是表中的一条数据
域:
域名对应的就是字段
4、安装es和可视化工具Kibana
es下载路径:
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.8.2-linux-x86_64.tar.gz
kibana下载路径:
https://artifacts.elastic.co/downloads/kibana/kibana-8.8.2-linux-x86_64.tar.gz
大家自行下载上传到虚拟机中或者直接使用wget拉取(这里要提醒的是es和kibana的版本必须一致否则会有错误)
Elasticsearch启动:
1、关闭防火墙
systemctl stop firewalld.service
2、配置最大可创建文件数大小
#打开系统文件:
vim /etc/sysctl.conf
#添加以下配置:
vm.max_map_count=655360
#配置生效:
sysctl -p
3、由于es不能以root运行,我们需要创建一个非root用户
#创建es用户
useradd es
4、解压es
#解压es
tar -zxvf 文件目录名
#修改文件属主
chown -R es:es 文件目录路径
5、启动es
#切换用户
su es
#启动elasticsearch,进入到elasticsearch的bin目录下
./elasticsearch
Kibana启动:
1、解压文件
tar -zxvf 文件目录名
2、配置kibana.yml
#进入kibana的config目录的kibana.yml文件,添加如下配置
#es的默认端口号是9200
server.host=虚拟机ip
elasticsearch.hosts=["http://运行es的虚拟机ip:端口号"]
3、运行kibana
#因为kibana不能以root用户运行,所以需要使用非root用户,我之前创建了一个es用户,
#所以我们直接使用es用户
#将文件所属改为es
chown -R es:es 文件目录路径
#切换用户
su es
#切换到kibana的bin目录,运行kibana
./kibana
4、运行之后访问http://kibana虚拟机ip:端口号
#kibana的默认端口是5601
5、访问 http://虚拟机ip:5601
访问成功过后我们就可以对es进行操作了
这个页面是通过restful风格api对es进行操作的
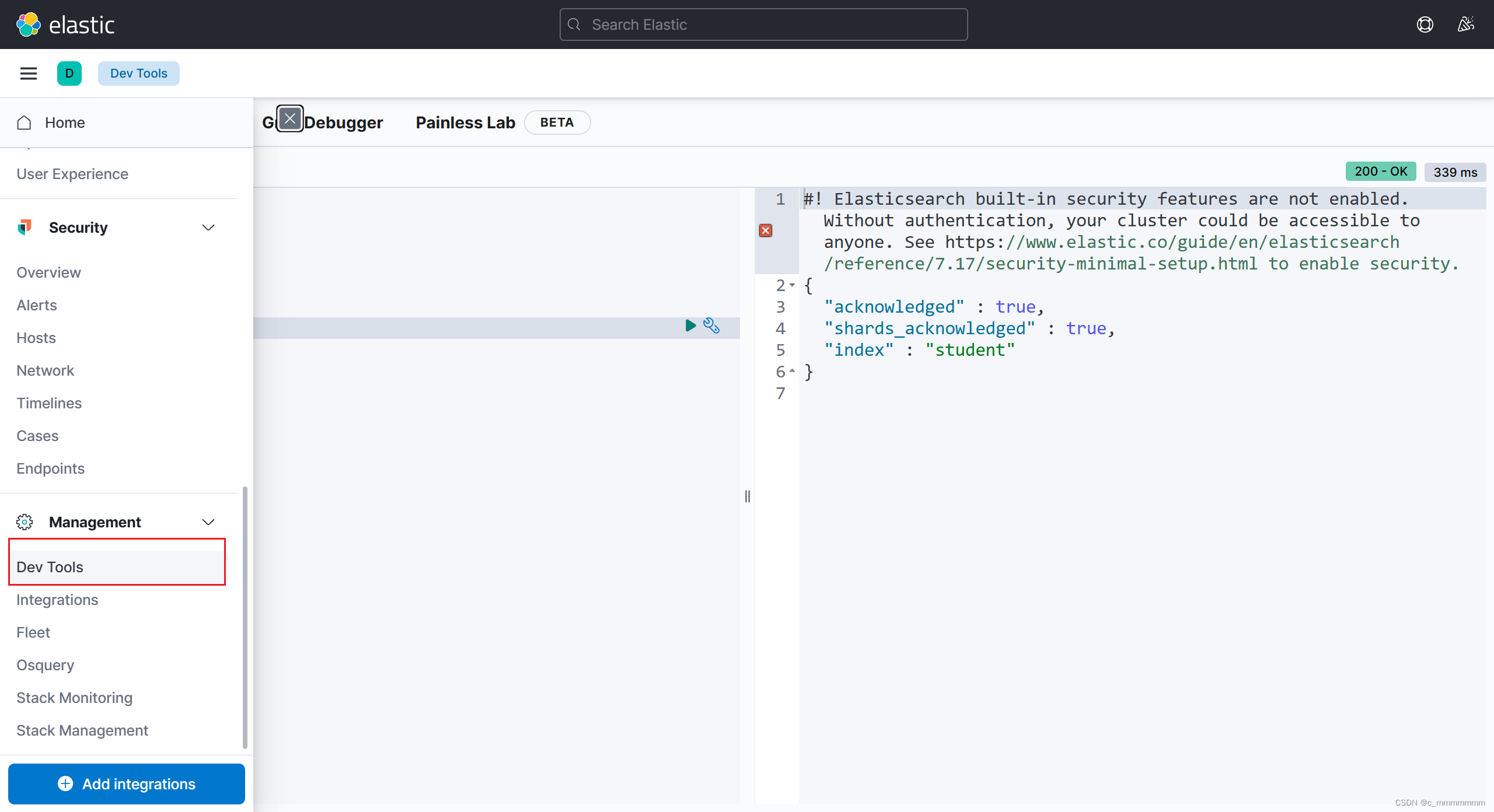 这个页面里的Index Management可以查看索引
这个页面里的Index Management可以查看索引
5、原生操作es
索引操作
新增索引
1、建立没有结构的索引
PUT /索引名
示例:
PUT /student
2、建立有结构的索引
PUT /索引名
{
"mappings":{
"properties":{
"域名":{
"type":"字段类型",
"index":"是否创建索引",
"store":"是否存储",
"analyzer":"分词器"
},
"域名":{
......
}
}
}
}
示例:
PUT /student1
{
"mappings": {
"properties": {
"id":{
"type": "integer"
},
"name":{
"type":"text"
}
}
}
}
删除索引
DELETE /索引名
示例:
DELETE /student
文档操作
文档存储数据类似于set集合,其存储的id不可重复,
如果id重复则直接覆盖id里面所对应的数据,如果不写id则自动生成
新增文档
POST /索引名/_doc/[id]
示例:
POST /student1/_doc/1
{
"id":"1",
"name":"zhangsan"
}
修改文档
POST /索引名/_update/id值
示例:
POST /student1/_update/1
{
"doc":{
"name":"lisi"
}
}
删除文档
DELETE /索引名/_doc/id值
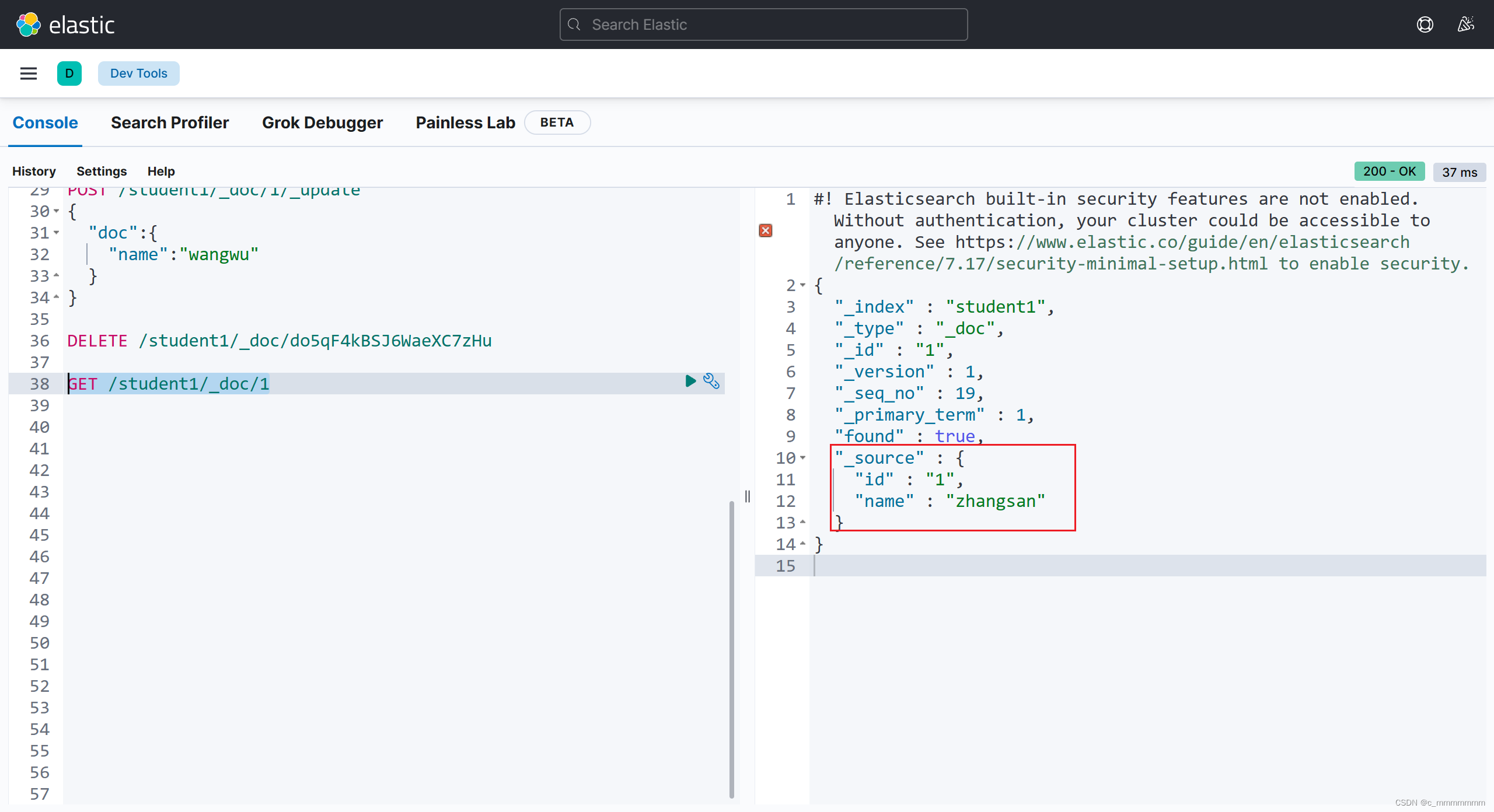
查询文档
GET /索引名/_doc/id值
示例:
GET /student1/_doc/1
查询所有文档
GET /索引名/_search
{
"query":{
"match_all":{}
}
}
分词器
默认分词器
ES文档的数据拆分成一个个有完整含义的关键词,并将关键词与文档对应,这样就可以通过关键词查询文档。要想正确的分词,需要选择合适的分词器。
standard analyzer:Elasticsearch默认分词器,根据空格和标点符号对英文进行分词,会进行单词的大小写转换。
默认分词器是英文分词器,对中文的分词是一字一词。
GET /_analyze
{
"text":测试语句,
"analyzer":分词器
}
IK分词器
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。提供了两种分词算法:
- ik_smart:最少切分
- ik_max_word:最细粒度划分
安装IK分词器
关闭es服务
使用rz命令将ik分词器上传至虚拟机
注:ik分词器的版本要和es版本保持一致。解压ik分词器到elasticsearch的plugins目录下
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis-ik#切换用户es
su es
#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/
#启动ES服务:
./elasticsearch -d
GET /_analyze
{
"text":"测试语句",
"analyzer":"ik_smart/ik_max_word"
}
IK分词器词典
IK分词器根据词典进行分词,词典文件在IK分词器的config目录中。
- main.dic:IK中内置的词典。记录了IK统计的所有中文单词。
- IKAnalyzer.cfg.xml:用于配置自定义词库。
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext_dict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">ext_stopwords.dic</entry>
</properties>
1、编辑ext_dict.dic文件(只需要在里面添加想要的关键词就好了)
2、编辑ext_stopwords.dic文件(只需要在里面添加不想要的关键词就好了)

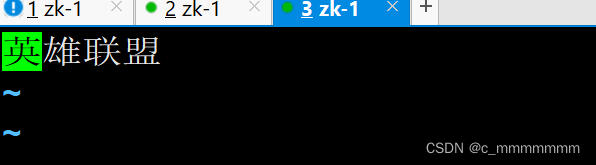
3、测试分词效果
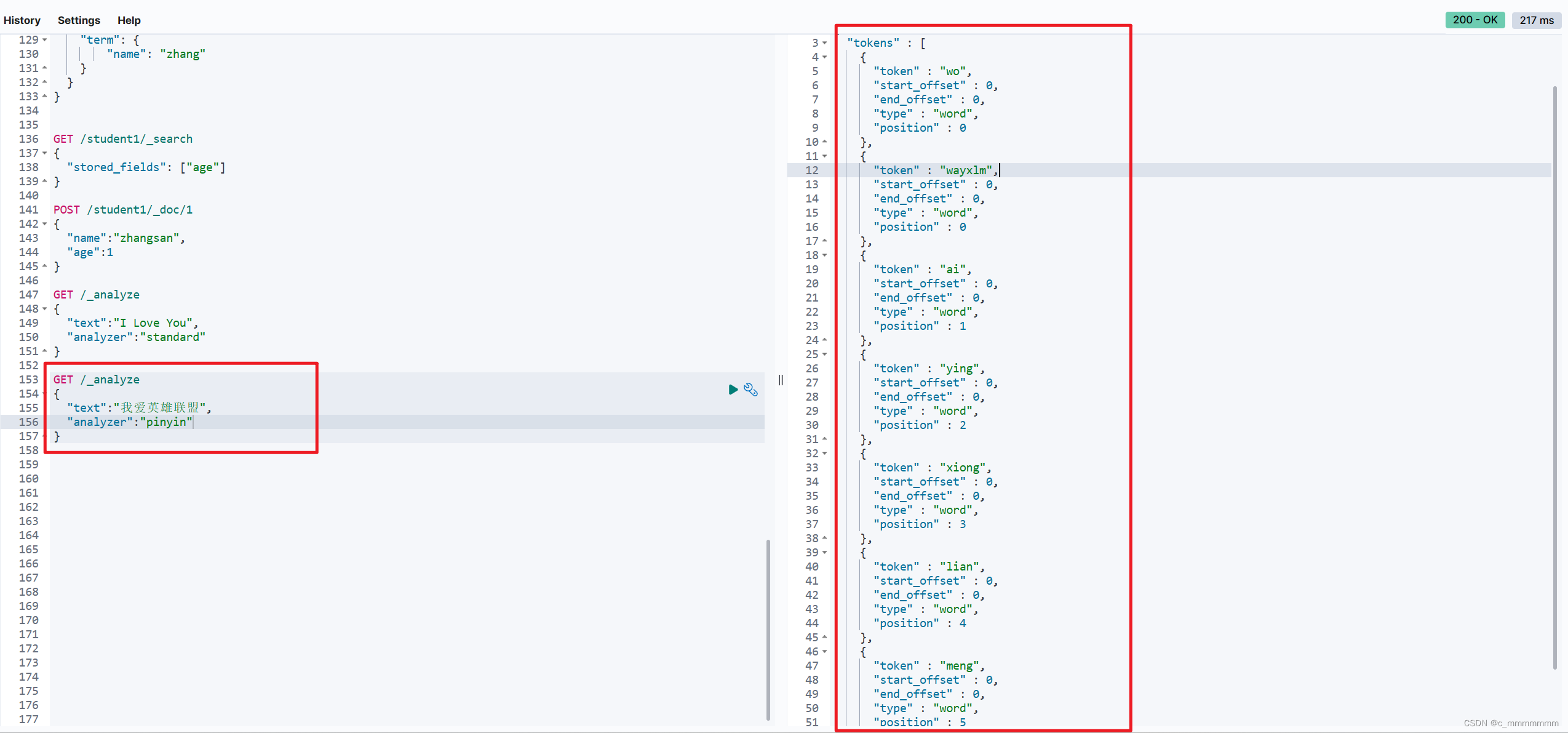
GET /_analyze
{
"text":"我爱英雄联盟",
"analyzer":"ik_max_word"
}
没有自定义词典的分词效果:

添加了自定义词典的分词效果:

IK拼音分词器

拼音分词器可以将中文分成对应的全拼,全拼首字母等。
安装拼音分词器
关闭es服务使用rz命令将拼音分词器上传至虚拟机
注:拼音分词器的版本要和es版本保持一致。
解压ik分词器到elasticsearch的plugins目录下
unzip elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis-pinyin
启动ES服务
su es
#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/
#启动ES服务:
./elasticsearch
GET /_analyze
{
"text":测试语句,
"analyzer":pinyin
}
自定义分词器
真实开发中我们往往需要对一段内容既进行文字分词,又进行拼音分词,此时我们需要自定义ik+pinyin分词器。
注意:两个分词器不是叠加的,而是各干各的,也就是说先对文档进行ik分词,然后再对文档进行pinyin分词。而不是对文档先ik分词,然后再对已经被ik分词的文档进行pinyin分词,也就是说倒排索引中会有两种不同的关键词,一种是通过ik分词器分词的,一种是通过pinyin分词器分词的
PUT /索引名
{
"settings" : {
"analysis" : {
"analyzer" : {
"ik_pinyin" : { //自定义分词器名
"tokenizer":"ik_max_word", // 基本分词器
"filter":"pinyin_filter" // 配置分词器过滤
}
},
"filter" : { // 分词器过滤时配置另一个分词器,相当于同时使用两个分词器
"pinyin_filter" : {
"type" : "pinyin", // 另一个分词器
// 拼音分词器的配置
"keep_separate_first_letter" : false, // 是否分词每个字的首字母
"keep_full_pinyin" : true, // 是否分词全拼
"keep_original" : true, // 是否保留原始输入
"remove_duplicated_term" : true // 是否删除重复项
}
}
}
},
"mappings":{
"properties":{
"域名1":{
"type":域的类型,
"store":是否单独存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
...
}
}
}
}
示例:
PUT /product2
{
"settings": {
"analysis": {
"analyzer": {
"ik_pinyin":{
"tokenizer":"ik_max_word",
"filter":"pinyin_filter"
}
},
"filter": {
"pinyin_filter":{
"type":"pinyin",
"keep_separate_first_letter" : false,
"keep_full_pinyin" : true,
"keep_original" : true,
"remove_duplicated_term" : true
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "integer",
"store": true
},
"name":{
"type": "text",
"store": true,
"index": true,
"analyzer": "ik_pinyin"
}
}
}
}测试自定义分词器
GET /索引名/_analyze
{
"text": "你好百战程序员",
"analyzer": "ik_pinyin"
}
复杂查询
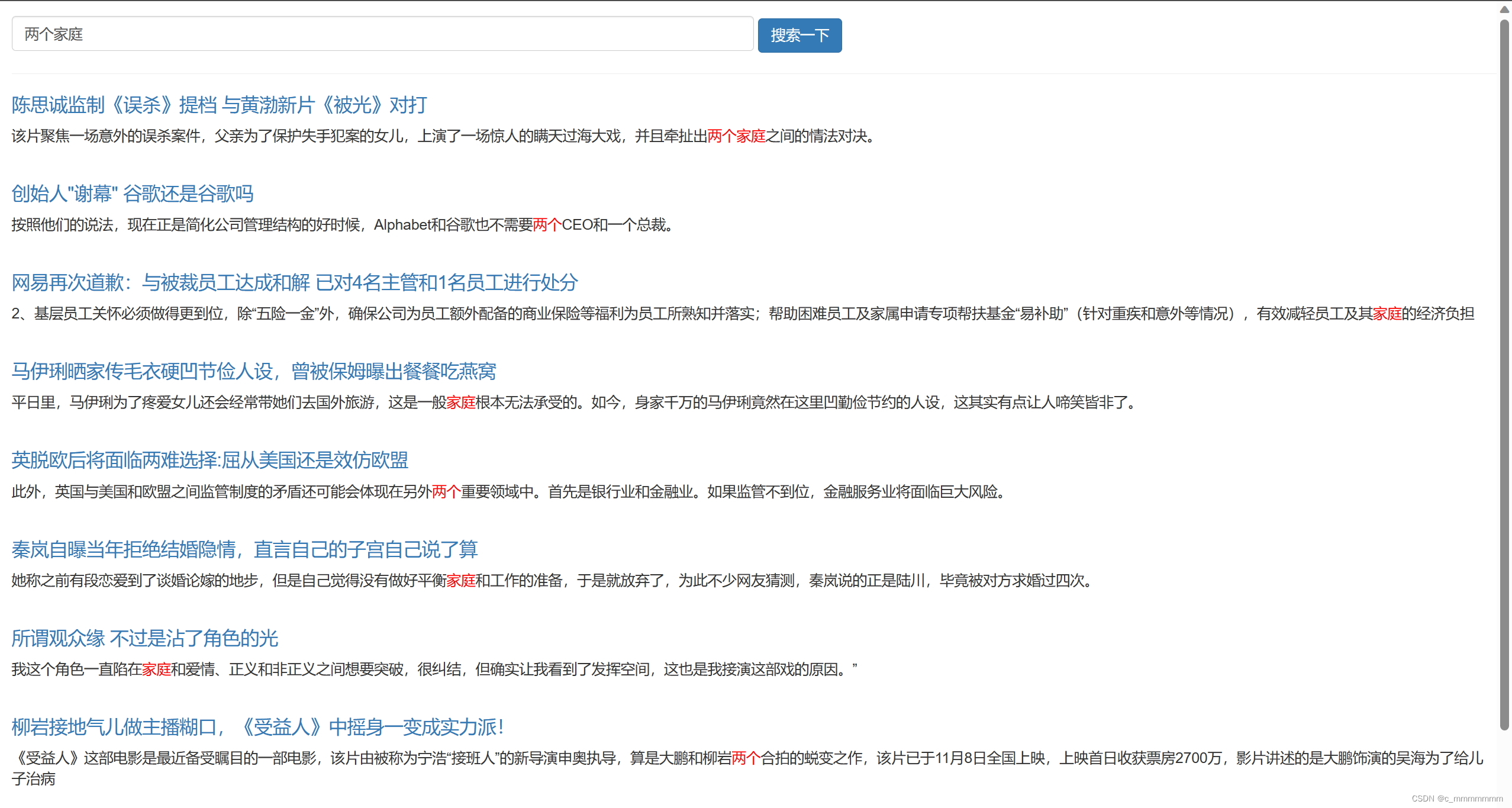
通过前面的操作我们学会了基本的es操作,但是在查询的时候我们的查询操作不可能会这么简单,我们肯定需要对于查询添加一些条件,所以我们这里就来学一下复杂查询
条件查询
1、match_all查询所有文档
GET /索引名/_search
{
"query":{
"match_all":{}
}
}
2、match全文检索(想要全文检索需要再创建索引的时候域的index设置为true)
这里需要注意的是如果使用match方式查询的话会先对关键字进行分词,然后最用分词后的数据进行查询
GET /索引名/_search
{
"query":{
"match":{
"域名":"关键字"
}
}
}
示例:
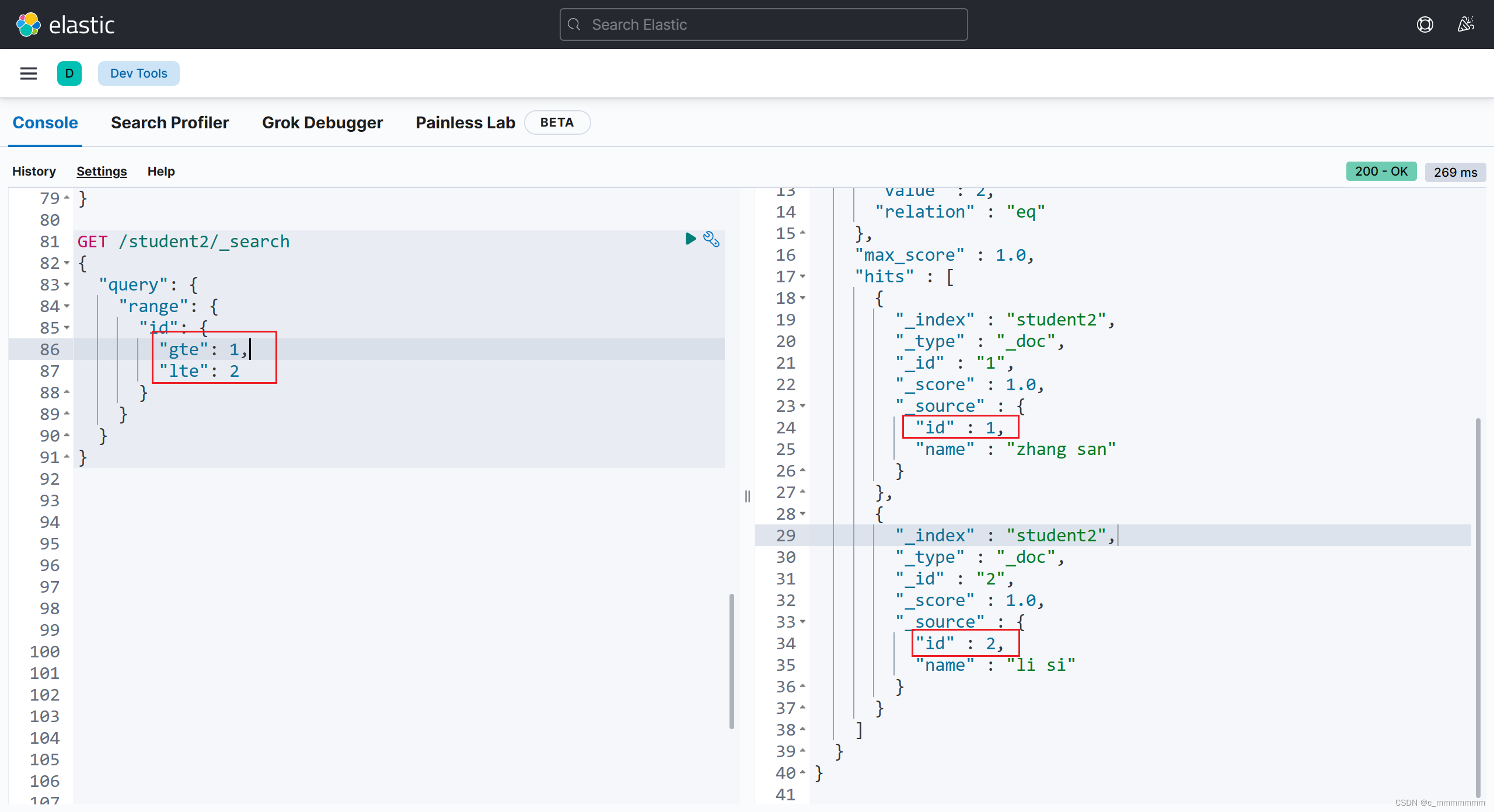
3、range范围查询
GET /索引名/_search
{
"query":{
"range":{
"域名":{
//大于等于1,小于等于2
"gte":1,
"lte":2
}
}
}
}
GET /索引名/_search
{
"query":{
"range":{
"域名":{
//大于1,小于3
"gt":1,
"lt":3
}
}
}
}
示例:
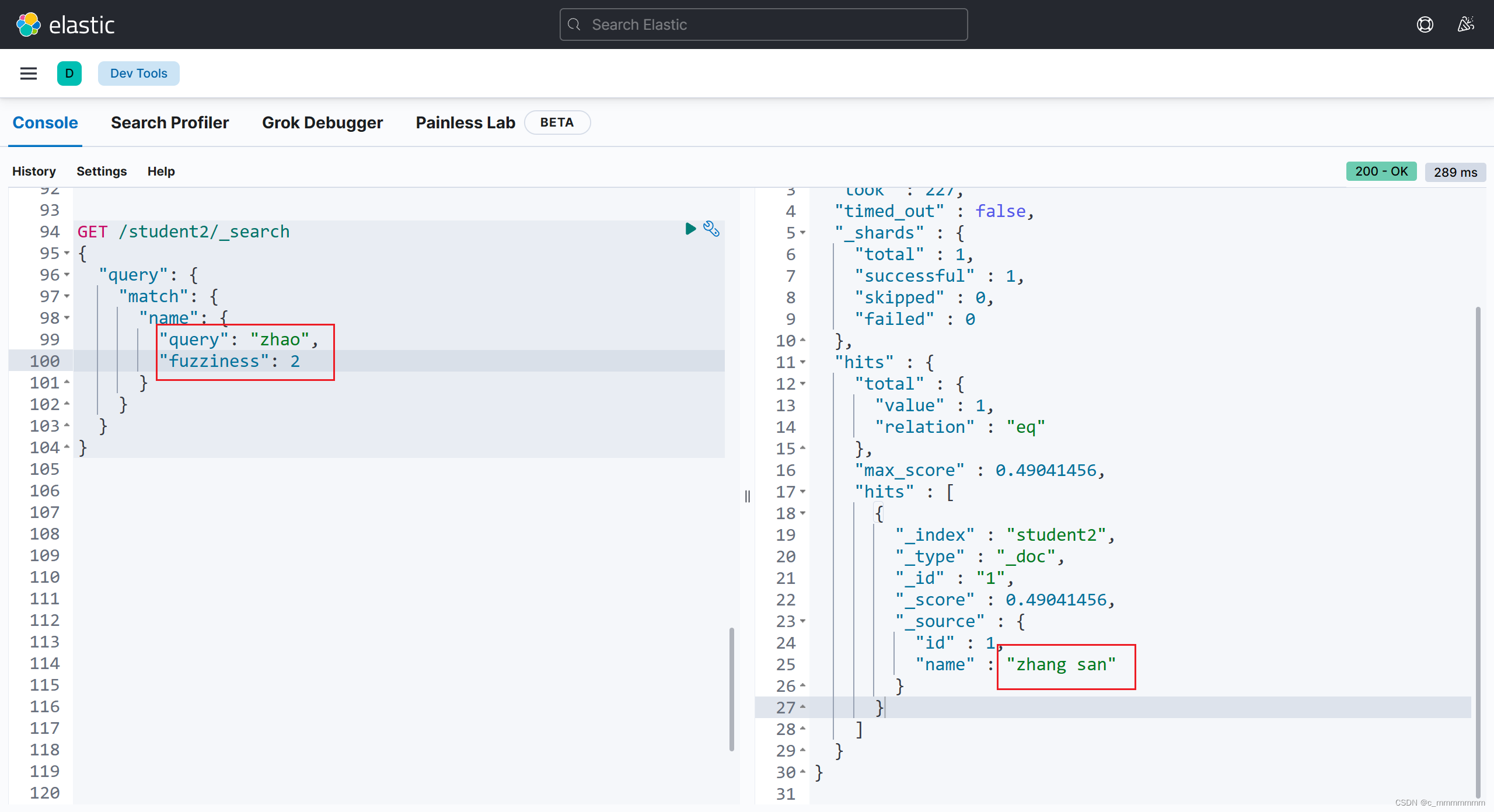
4、fuzziness纠错(最多只能纠错2位)
GET /索引名/_search
{
"query":{
"match":{
"域名":{
"query":"关键词",
"fuzziness":纠错个数
}
}
}
}
示例:
5、match_phrase短语检索,关键字不做任何分词,在搜索字段对应的倒排索引中精准匹配
GET /索引名/_search
{
"query":{
"match_phrase":{
"域名":"关键词"
}
}
}
示例:
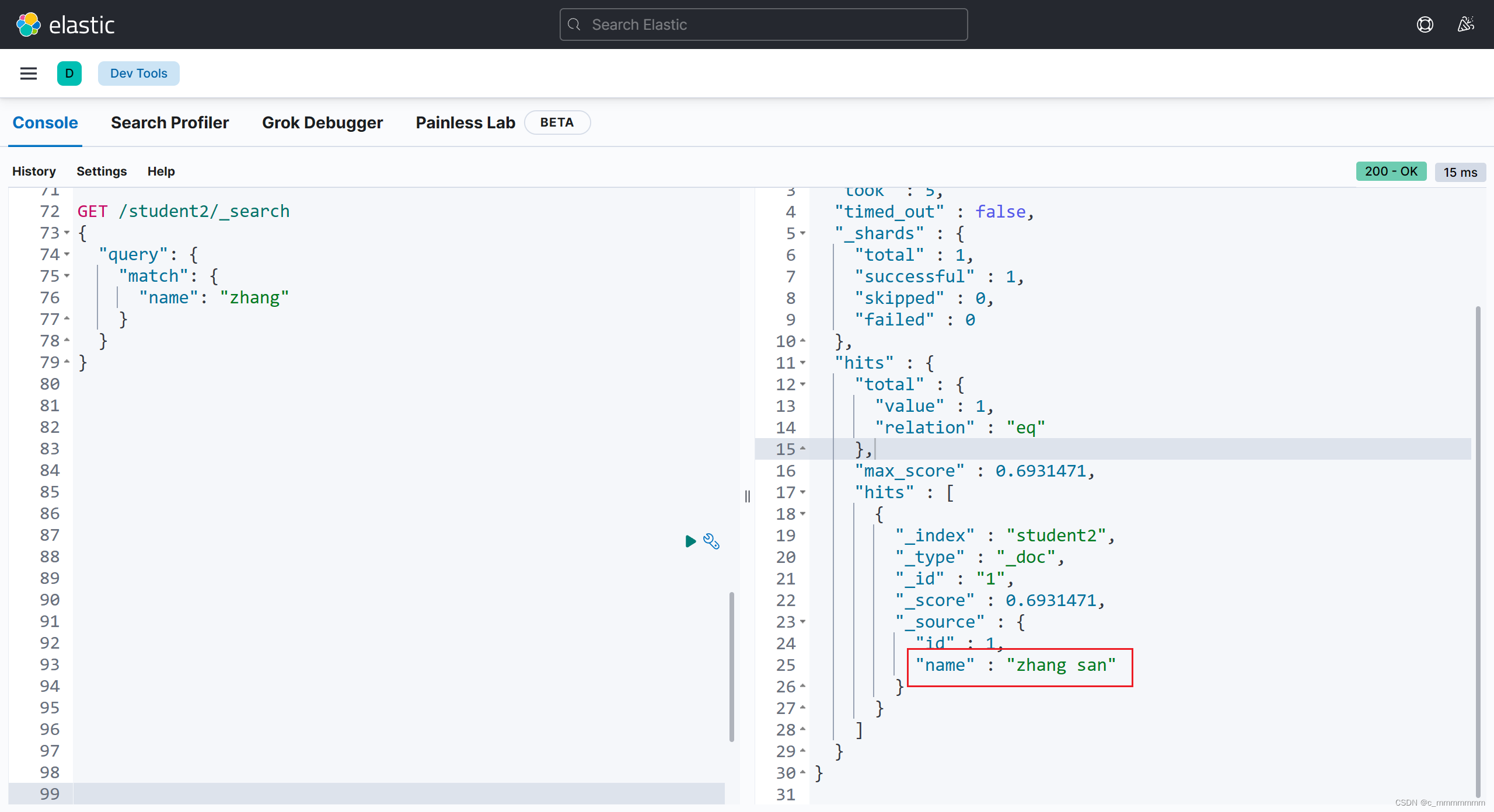
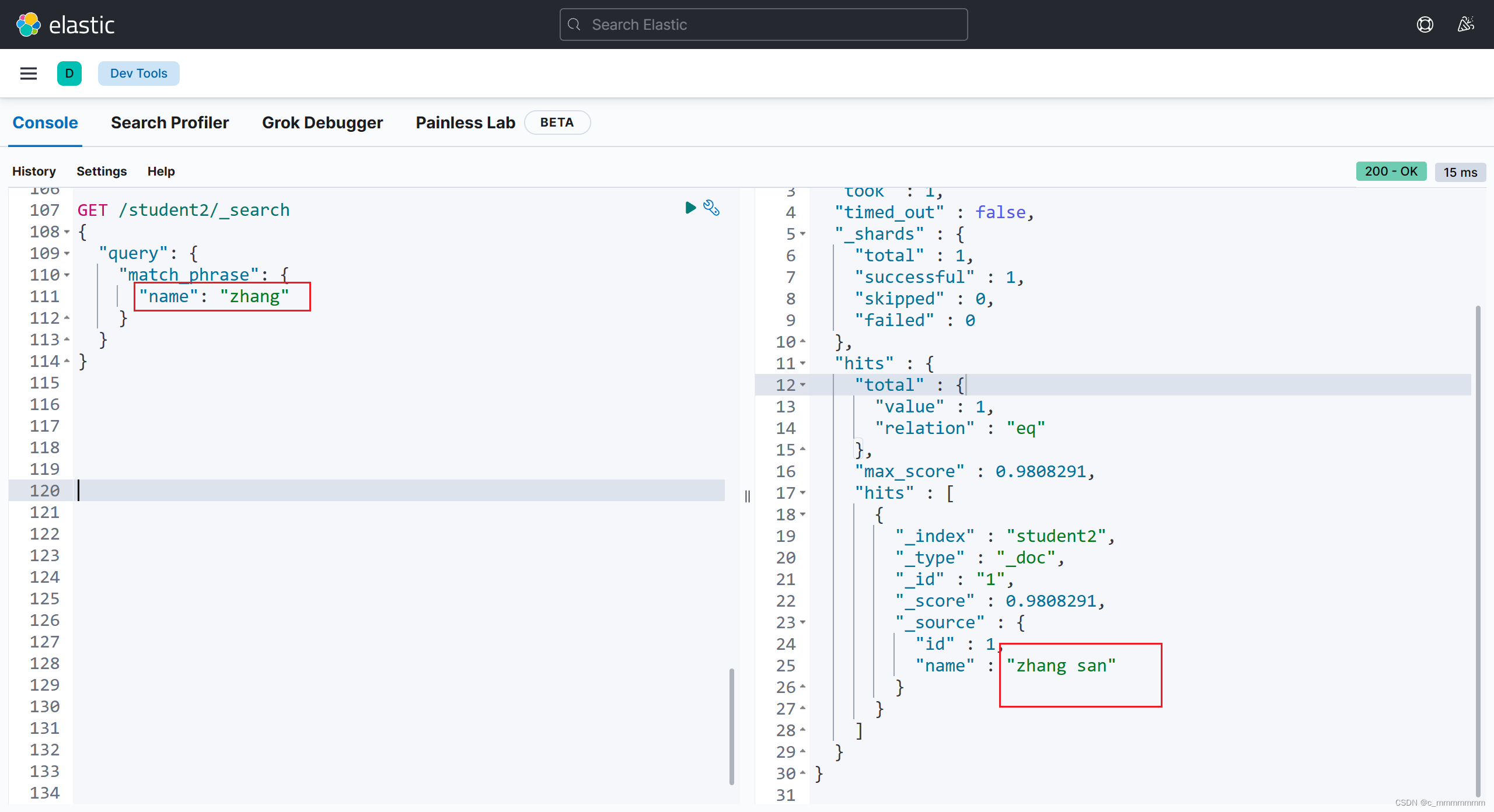
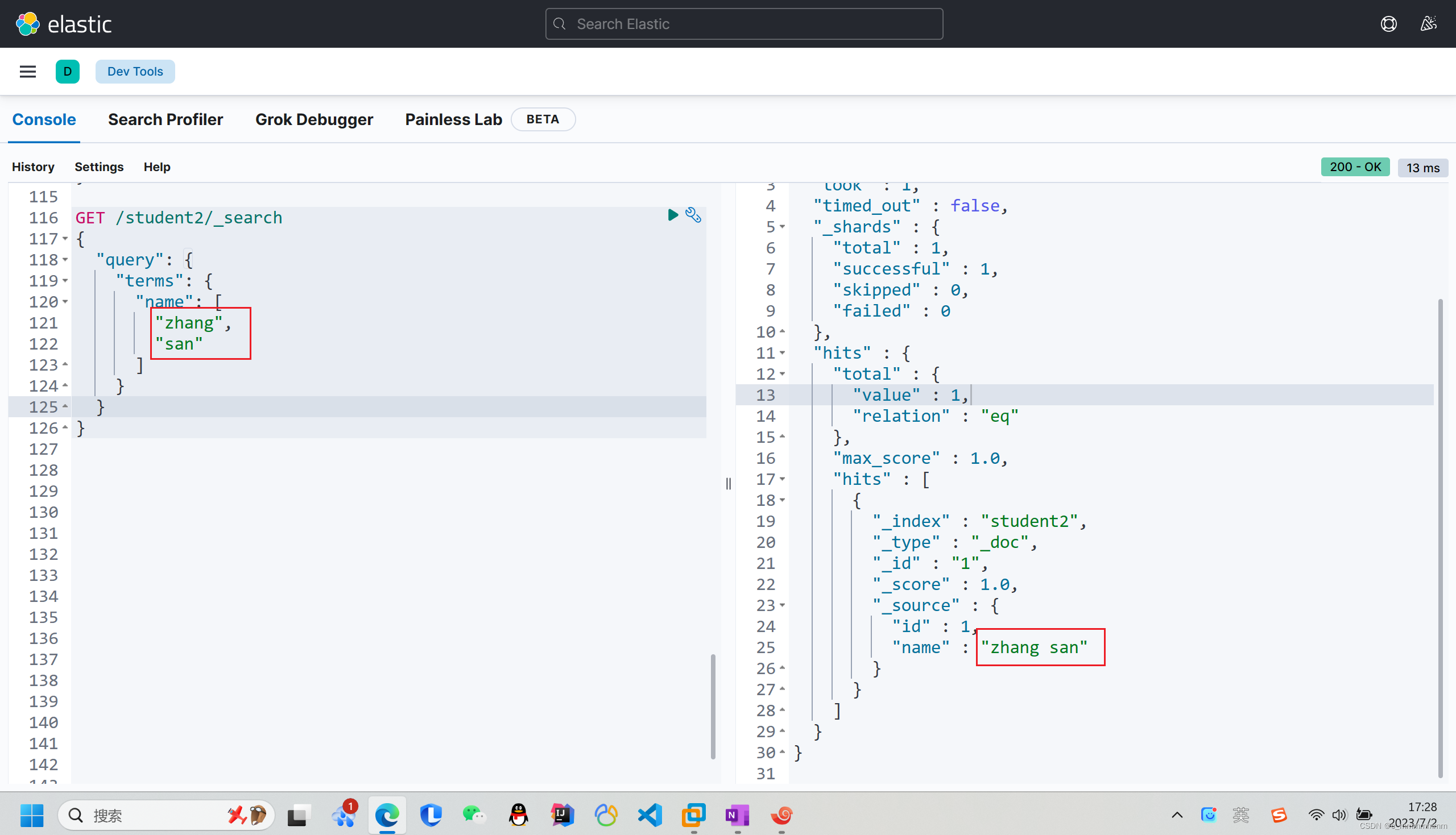
6、terms词组检索,关键词不做任何分词,在搜索字段对应的倒排索引中精准匹配
GET /索引名/_search
{"query":{
"terms":{
"域名":[
"关键词",
"关键词",
...
]
}
}
}
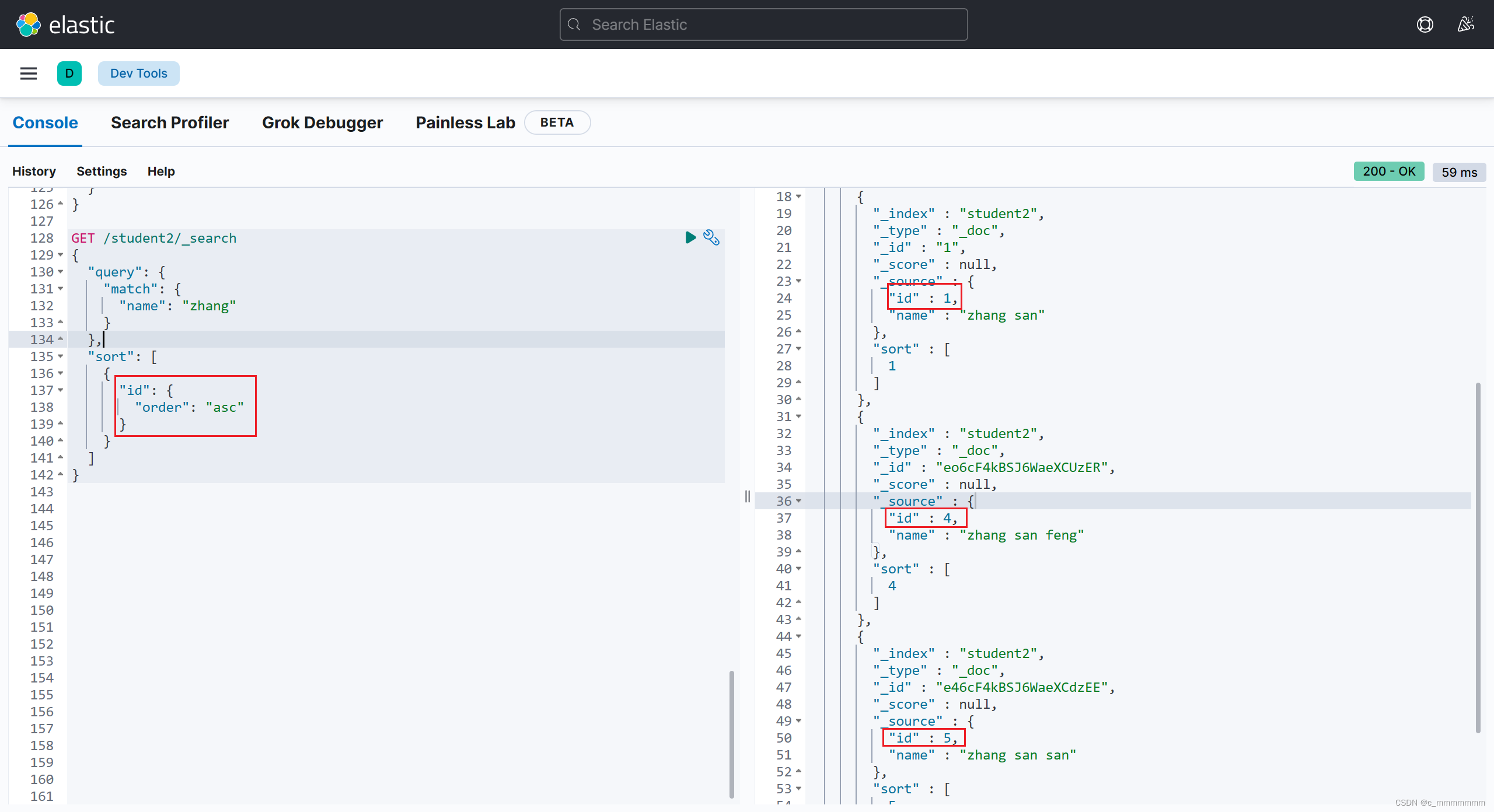
排序查询
GET /索引名/_search
{
"query":{
"match":{
"域名":"关键词"
}
},
"sort":[
"域名":{
"order":"排序方式"
}
]
}
示例:
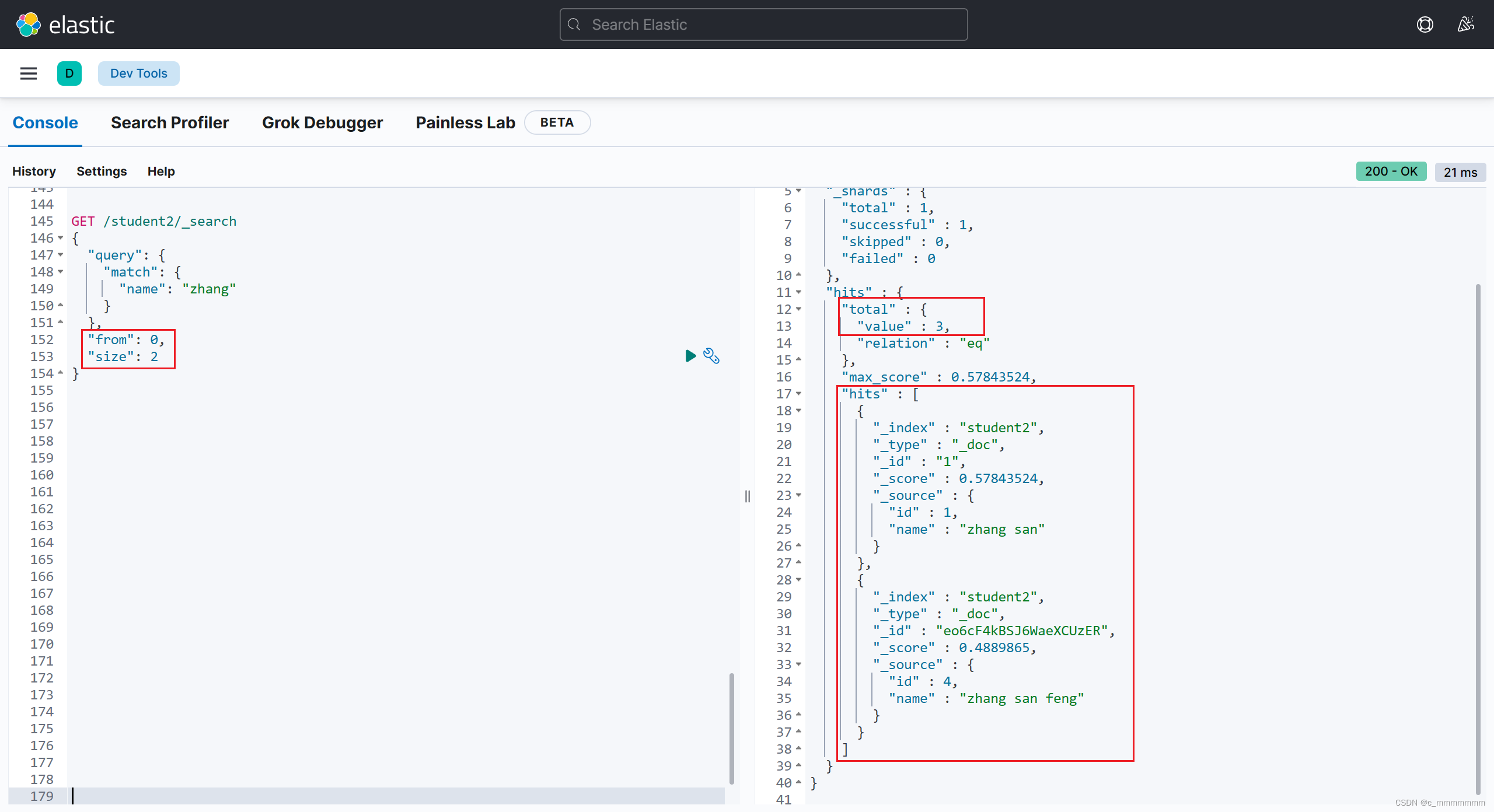
分页查询
GET /索引名/_search
{
"query":{
"match":{
"域名":"关键词"
}
},
"from":起始下标,
"size":每页个数
}
示例:
复合搜索
GET /索引名/_search
{
"query":{
"bool":{
// 必须满足的条件
"must":{
{
"搜索方式":{
"域名":"关键字"
}
},
{...}
},
//任意一个条件满足即可
"should":{
{
"搜索方式":{
"域名":"关键字"
}
},
{...}
},
//必须不满足的条件
"must_not":{
{
"搜索方式":{
"域名":"关键字"
}
},
{...}
}
}
}
}
示例: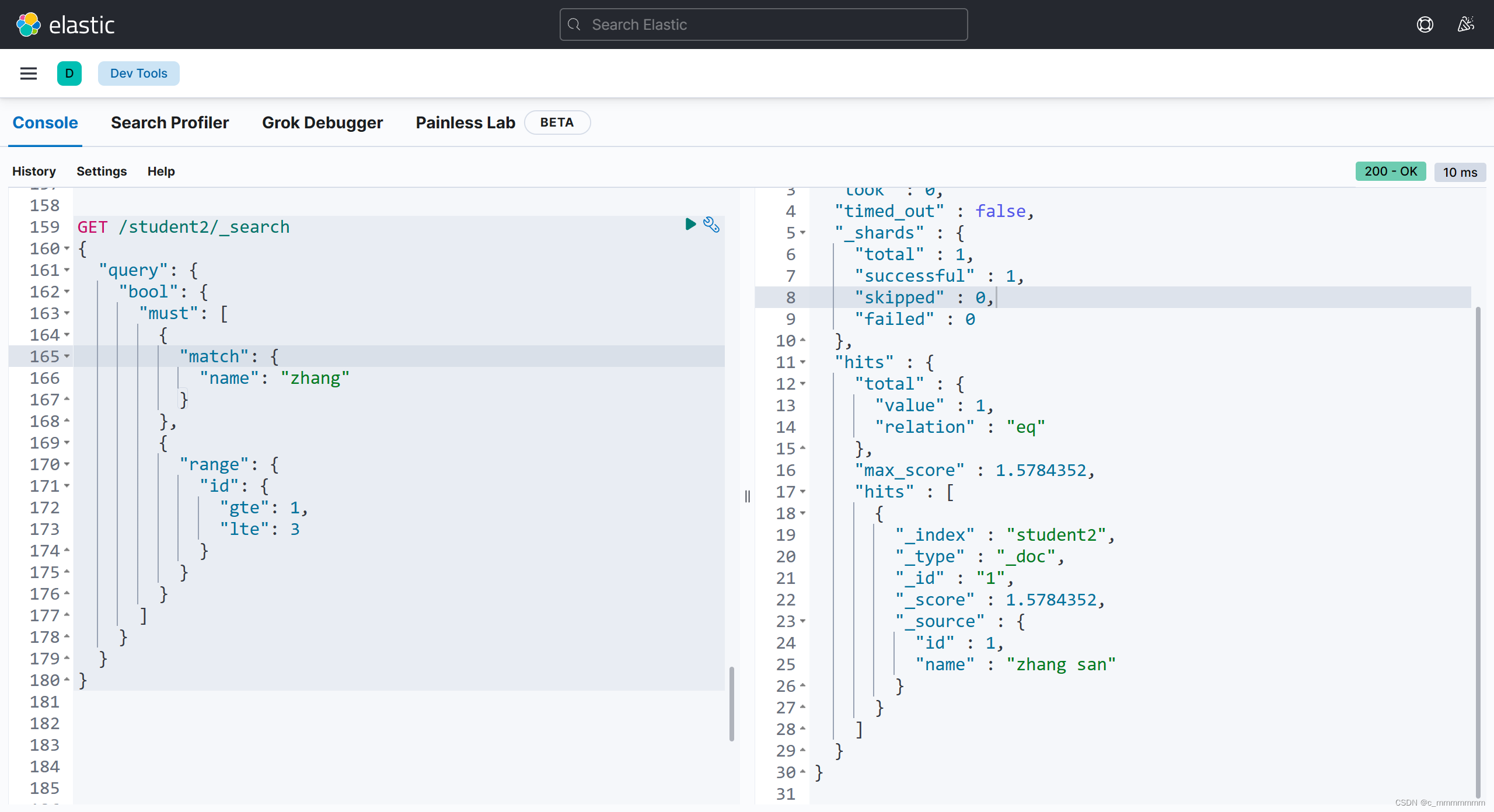
高亮显示
GET /索引名/_search
{
"query":{
"match":{
"域名":"关键词"
}
},
"highlight":{
"fields":{
"高亮字段名":{
// 返回高亮数据的最大长度
"fragment_size":100,
// 返回结果最多可以包含几段不连续的文字
"number_of_fragments":5
}
},
"pre_tags":["前缀"],
"post_tags":["后缀"]
}
}
示例: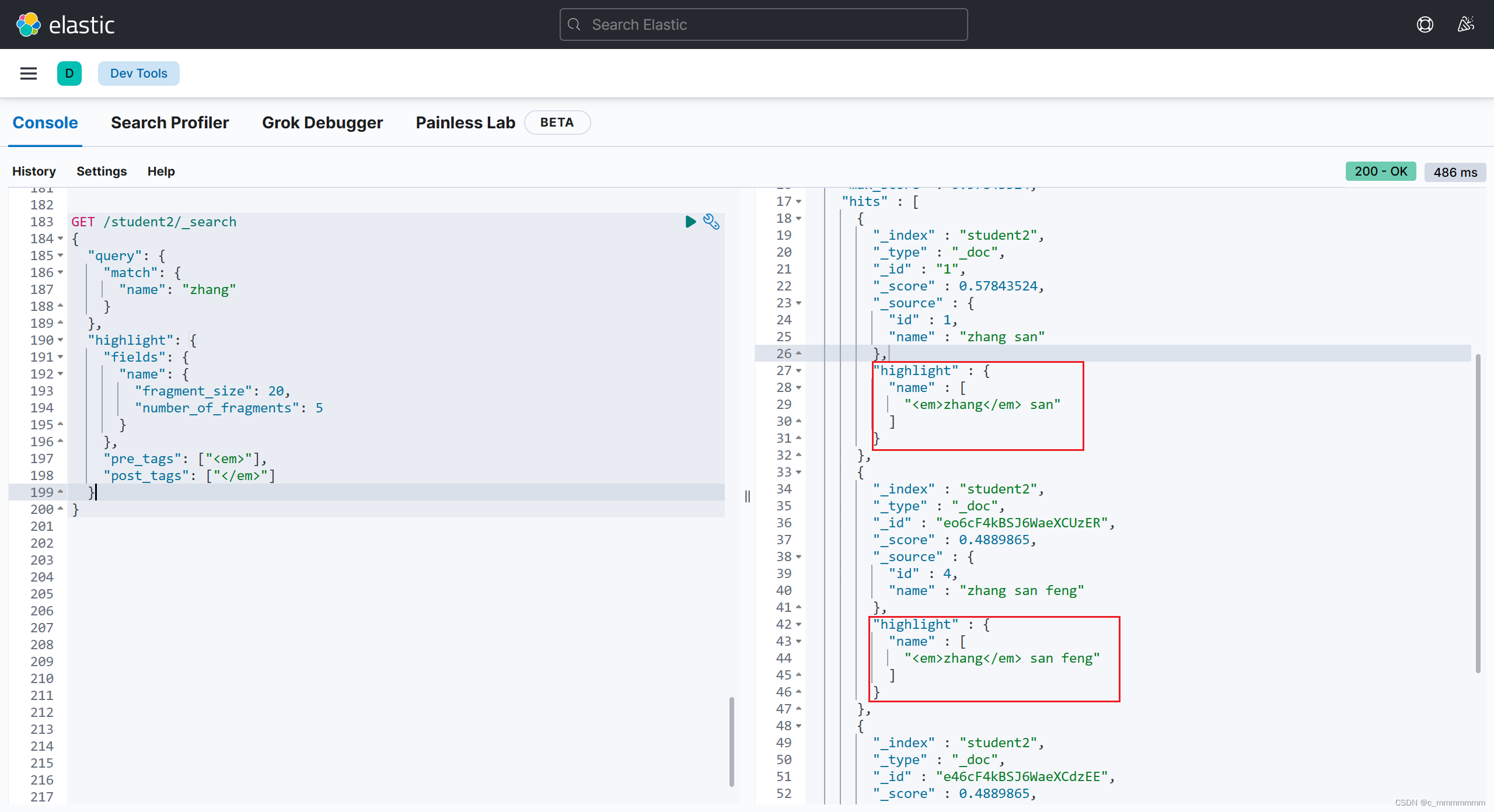
自动补全
自动补全的字段的类型必须是completion,所以我们需要新建一个索引,将对应的域的类型设置为completion
PUT /product
{
"mappings": {
"properties": {
"id":{
"type": "integer",
"index": true,
"store": true
},
"productName":{
"type": "completion"
},
"productDesc":{
"type": "text",
"index": true,
"store": true
}
}
}
}然后我们需要新增几条数据
POST /product/_doc
{
"id":1,
"productName":"elasticsearch1",
"productDesc":"elasticsearch1 is a good search engine"
}
POST /product/_doc
{
"id":2,
"productName":"elasticsearch2",
"productDesc":"elasticsearch2 is a good search engine"
}
POST /product/_doc
{
"id":3,
"productName":"elasticsearch3",
"productDesc":"elasticsearch3 is a good search engine"
}
自动补全
GET /索引名/_search
{
"suggest":{
"自定义名字":{
"prefix":"被补全的关键字",
"completion":{
"fields":"补全字段",
"skip_duplicates": true, // 忽略重复结果
"size": 10 //最多查询到的结果数
}
}
}
}
6、SpringDataEs操作es
项目搭建
创建SpringBoot项目,引入SpringDataEs依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>配置yml文件
spring:elasticsearch:uris: http://运行es的虚拟机IP:9200
创建实体类
一个实体类的所有对象都会存入ES的一个索引中,所以我们在创建实体类时关联ES索引。
//索引名叫product,启动SpringBoot的时候是否自动创建索引
@Document(indexName = "product",createIndex = true)@Datapublic class Product {@Id @Field(type = FieldType.Integer,store = true,index = true)private Integer id;@Field(type = FieldType.Text,store = true,index = true,analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")private String productName;@Field(type = FieldType.Text,store = true,index = true,analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")private String productDesc;}@Document:标记在类上,标记实体类为文档对象,一般有如下属性:
indexName:对应索引的名称
createIndex:是否自动创建索引
@Id:标记在成员变量上,标记一个字段为主键,该字段的值会同步到ES该文档的id值。
@Field:标记在成员变量上x`标记为文档中的域,一般有如下属性:
type:域的类型
index:是否创建索引,默认是 true
store:是否单独存储,默认是 false
analyzer:分词器
searchAnalyzer:搜索时的分词器
Repository接口方法
创建Repository接口继承ElasticsearchRepository,接口提供了增删改查方法
(该接口有两个泛型,第一个泛型是实体类类型,第二个泛型是实体类的主键的类型)
import com.itbaizhan.esblog.pojo.Product;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;public interface ProductRepository extends ElasticsearchRepository<Product,Integer> {
}
测试接口:
import com.itbaizhan.esblog.pojo.Product;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.Optional;@SpringBootTest
public class ProductRepositoryTest {@Autowiredprivate ProductRepository repository;@Testpublic void t1(){//新增Product product = new Product(1,"HUAWEI MATE 30","照亮你的美");repository.save(product);}@Testpublic void t2(){//修改Product product = new Product(1,"OPPO RENO 6 PRO","充电两分钟通话两小时");repository.save(product);//因为id相同所以是修改,就像map集合一样}@Testpublic void t3(){//根据id获取文档Optional<Product> optional = repository.findById(1);Product product = optional.get();System.out.println(product);}@Testpublic void t4(){//查询所有Iterable<Product> products = repository.findAll();products.forEach(System.out::println);}@Testpublic void t5(){//删除Product product = new Product(1);repository.delete(product);}}
DSL查询文档
接下来我们讲解SpringDataES支持的查询方式,首先准备一些文档数据:
// 添加一些数据
repository.save(new Product(2, "三体1", "三体1是优秀的科幻小说"));
repository.save(new Product(3, "三体2", "三体2是优秀的科幻小说"));
repository.save(new Product(4, "三体3", "三体3是优秀的科幻小说"));
repository.save(new Product(5, "elasticsearch", "elasticsearch是基于lucene开发的优秀的搜索引擎"));
使用Repository继承的方法查询文档
该方式我们之前已经讲解过了
使用DSL语句查询文档
ES通过json类型的请求体查询文档,方法如下:
GET /索引/_search
{
"query":{
搜索方式:搜索参数
}
}
query后的json对象称为DSL语句,我们可以在接口方法上使用@Query注解自定义DSL语句查询。
(?0代表占位符,一个?0匹配一个方法形式参数)
@Query("{" +
" \"match\": {" +
" \"productDesc\": \"?0\"" +
" }" +
" }")
List<Product> findByProductDescMatch(String keyword);
示例:
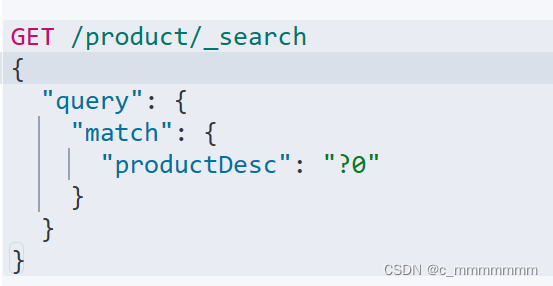
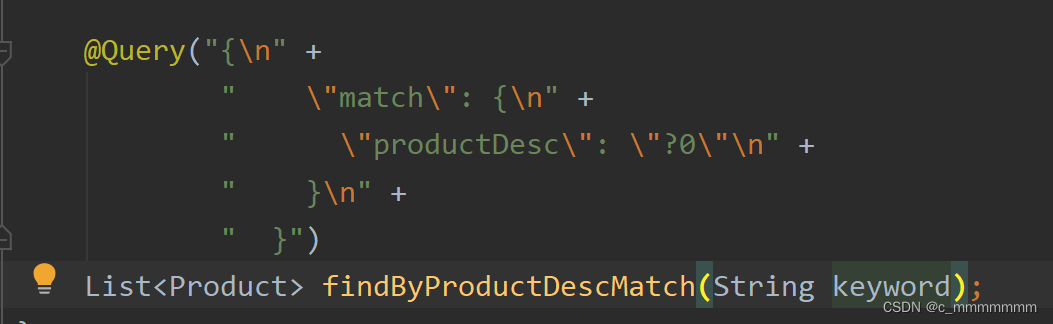
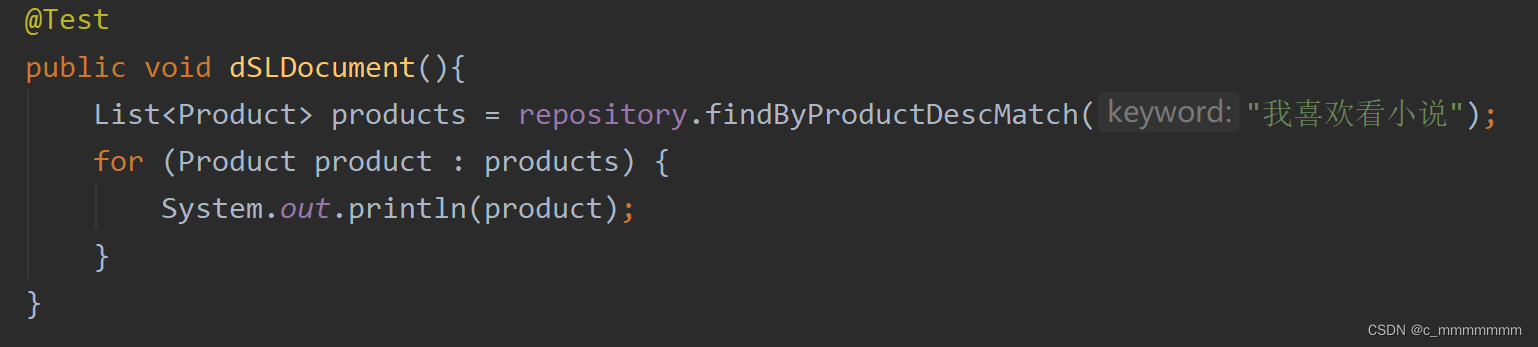

@Query("{" +
" \"match\": {" +
" \"productDesc\": {" +
" \"query\": \"?0\"," +
" \"fuzziness\": 1" +
" }" +
" }" +
"}")
List<Product> findByProductDescFuzzy(String keyword);
按照规则命名查询
按照规则命名方法进行查询
| 关键字 | 命名规则 | 解释 | 示例 |
| and | FindByField1AndField2 | 根据Field1和Field2 获得数据 | FindByTitleAndContent |
| or | FindByField1OrField2 | 根据Field1或Field2 获得数据 | FindByTitleOrContent |
| is | FindByField | 根据Field获得数据 | FindByTitle |
| not | FindByFieldNot | 根据Field获得补集数据 | FindByTitleNot |
| between | FindByFieldBetween | 获得指定范围的数据 | FindByPriceBetween |
List<Product> findByProductName(String productName);
List<Product> findByProductNameOrProductDesc(String productName,String productDesc);
List<Product> findByIdBetween(Integer startId,Integer endId);
- 只需在Repository接口中按照SpringDataES的规则命名方法,该方法就能完成相应的查询。
- 规则:查询方法以findBy开头,涉及查询条件时,条件的属性用条件关键字连接。
分页查询
使用继承或自定义的方法时,在方法中添加Pageable类型的参数,
返回值为Page类型即可进行分页查询。
// 测试继承的方法:@Testpublic void testFindPage(){// 参数1:页数,// 参数2:每页条数Pageable pageable = PageRequest.of(1, 3);Page<Product> page = repository.findAll(pageable);System.out.println("总条数"+page.getTotalElements());System.out.println("总页数"+page.getTotalPages());System.out.println("数据"+page.getContent());}// 自定义方法Page<Product> findByProductDesc(String productDesc, Pageable pageable);// 测试自定义方法@Testpublic void testFindPage2(){Pageable pageable = PageRequest.of(1, 2);Page<Product> page = repository.findByProductDescMatch("我喜欢三体", pageable);System.out.println("总条数"+page.getTotalElements());System.out.println("总页数"+page.getTotalPages());System.out.println("数据"+page.getContent());}结果排序
使用继承或自定义的方法时,在方法中添加Sort类型的参数即可进行结果排序
// 结果排序@Testpublic void testFindSort(){//第一个参数:排序的类型 第二个参数:根据哪个字段进行排序Sort sort = Sort.by(Sort.Direction.DESC, "id");Iterable<Product> all = repository.findAll(sort);for (Product product : all) {System.out.println(product);}}// 测试分页加排序@Testpublic void testFindPage2(){Sort sort = Sort.by(Sort.Direction.DESC,"id");Pageable pageable = PageRequest.of(0, 2,sort);Page<Product> page = repository.findByProductDescMatch("我喜欢三体", pageable);System.out.println("总条数"+page.getTotalElements());System.out.println("总页数"+page.getTotalPages());System.out.println("数据"+page.getContent());}template操作:
通过继承ElasticsearchRepository类我们可以很方便的进行增删改查,但是使用这种方式查询文档,无法复杂查询,也就是说只能通过id查询或者查询所有,无法通过关键字匹配查询,这就使得查询收到了很大的局限性,而使用SpringDataEs提供的工具类ElasticsearchRestTemplate操作es则可以解决该问题
操作索引
创建索引
ElasticsearchRestTemplate创建索引无法设置索引结构,所以并不推荐使用该方法创建索引
使用template操作索引,首先我们需要获取到该索引的操作对象,然后通过该操作对象进行索引操作
@SpringBootTest
public class TestTemplate {@Autowiredprivate ElasticsearchRestTemplate template;@Testpublic void addIndex(){IndexOperations ops = template.indexOps(Product.class);ops.create();}
}
删除文档
删除文档也是一样的只是调用的方法不同
@SpringBootTest
public class TestTemplate {@Autowiredprivate ElasticsearchRestTemplate template;@Testpublic void delete(){IndexOperations ops = template.indexOps(Product.class);ops.delete();}}增删改文档
template增删改文档和ElasticsearchRepository差不多,只是引用不同
@SpringBootTest
public class TestTemplate {@Autowiredprivate ElasticsearchRestTemplate template;@Testpublic void addIndex(){//新增索引IndexOperations ops = template.indexOps(Product.class);ops.create();}@Testpublic void delete(){//删除索引IndexOperations ops = template.indexOps(Product.class);ops.delete();}@Testpublic void save(){//新增文档Product product = new Product(1,"HUAWEI MATE 30","照亮你的美");template.save(product);}@Testpublic void update(){//修改文档Product product = new Product(1,"OPPO RENO 6 PRO","充电五分钟,通话两小时");template.save(product);}@Testpublic void testDelete(){//删除文档template.delete("1",Product.class);}}查询文档
使用template查询文档主要分为四步:
- 确定查询方式
- 构建查询条件
- 查询
- 处理查询结果
@Testpublic void searchDocument(){//查询文档//1、确定查询方式MatchAllQueryBuilder builder = QueryBuilders.matchAllQuery();//2、构建查询条件NativeSearchQuery request = new NativeSearchQueryBuilder().withQuery(builder).build();//3、查询//参数一:查询条件//参数二:索引对应的类对象SearchHits<Product> hits = template.search(request, Product.class);//4、处理查询结果for (SearchHit<Product> hit : hits) {System.out.println(hit.getContent());}}复杂查询
通过template复杂条件查询可以实现动态的查询,根据是否传递某个参数动态修改dsl语句,查询数据
@Testpublic void boolSearch(){String productName = null;String productDesc = null;//1、确定查询方式BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();if (productName == null && productDesc == null){//参数一:匹配的字段//参数二:关键字MatchAllQueryBuilder queryBuilder = QueryBuilders.matchAllQuery();boolQueryBuilder.must(queryBuilder);//必须匹配}else if (productDesc != null && productDesc.length() > 0){//参数一:匹配的字段//参数二:关键字MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("productDesc", productDesc);boolQueryBuilder.must(queryBuilder);//必须匹配}else if (productName != null && productName.length() > 0){//参数一:匹配的字段//参数二:关键字MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("productName", productName);boolQueryBuilder.must(queryBuilder);//必须匹配}//2、构建查询条件NativeSearchQuery request = new NativeSearchQueryBuilder().withQuery(boolQueryBuilder).build();//3、查询SearchHits<Product> searchHits = template.search(request, Product.class);//4、处理查询结果for (SearchHit<Product> hit : searchHits) {System.out.println(hit.getContent());}}分页排序
template分页排序通过构建分页对象Pageable,设置第几页以及每页条数,然后将分页条件放入查询条件中,查询完成之后需要自己手动构造分页条件PageImpl,然后通过返回的Page对象就可以使用分页数据了
@Testpublic void limit(){//查询文档//1、确定查询方式MatchAllQueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
// MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("productName", "oppo");//2、构建查询条件//构建分页条件Pageable pageable = PageRequest.of(0, 1);NativeSearchQuery request = new NativeSearchQueryBuilder().withQuery(queryBuilder).withPageable(pageable).build();//3、查询SearchHits<Product> hits = template.search(request, Product.class);//4、处理查询结果//将结果封装为Page对象List<Product> list = new ArrayList<>();for (SearchHit<Product> hit : hits) {Product product = hit.getContent();list.add(product);}//参数一:具体数据//参数二:分页条件//参数三:总条数Page<Product> page = new PageImpl<>(list, pageable, hits.getTotalHits());System.out.println("每页条数:"+page.getTotalElements());System.out.println("总页数:"+page.getTotalPages());System.out.println("数据:"+page.getContent());}结果排序
template结果排序是通过构建结果排序对象,指定排序字段和排序方式,然后再构建查询条件的时候传入
@Testpublic void sort(){//查询文档//1、确定查询方式MatchAllQueryBuilder builder = QueryBuilders.matchAllQuery();
// MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("productName", "oppo");//2、构建查询条件//构建结果排序对象FieldSortBuilder sortBuilder = SortBuilders.fieldSort("id").order(SortOrder.DESC);NativeSearchQuery request = new NativeSearchQueryBuilder().withQuery(builder).withSorts(sortBuilder).build();//3、查询SearchHits<Product> hits = template.search(request, Product.class);//4、处理查询结果for (SearchHit<Product> hit : hits) {System.out.println(hit.getContent());}}7、实战案例
实现功能
本次案例我们要实现的是高亮字段以及自动补全的功能
项目搭建
创建索引
这一段DSL语句的意思是:创建一个分词器,既有pinyin分词器的作用又有ik分词器的作用。为索引添加结构,创建域以及指定各个域的类型,并且给tags域的类型设置为completion,因为后面我们要给该字段进行自动补全功能的实现
PUT /news
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"ik_pinyin": {
"tokenizer": "ik_smart",
"filter": "pinyin_filter"
},
"tag_pinyin": {
"tokenizer": "keyword",
"filter": "pinyin_filter"
}
},
"filter": {
"pinyin_filter": {
"type": "pinyin",
"keep_joined_full_pinyin": true,
"keep_original": true,
"remove_duplicated_term": true
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "integer",
"index": true
},
"title": {
"type": "text",
"index": true,
"analyzer": "ik_pinyin",
"search_analyzer": "ik_smart"
},
"content": {
"type": "text",
"index": true,
"analyzer": "ik_pinyin",
"search_analyzer": "ik_smart"
},
"url": {
"type": "keyword",
"index": true
},
"tags": {
"type": "completion",
"analyzer": "tag_pinyin",
"search_analyzer": "tag_pinyin"
}
}
}
}
将mysql的数据同步到es中
先在mysql中添加news表的数据:
百度网盘链接
提取码:7bqy自行下载logstash文件,该文件可以将mysql中的数据同步到es中
1、解压logstash-7.17.0-windows-x86_64.zip
logstash要和elastisearch版本一致
2、在解压路径下的/config中创建mysql.conf文件,文件写入以下脚本内容:
input {
jdbc {
jdbc_driver_library => "E:\新课\Elasticsearch\软件\案例\mysql-connector-java-5.1.37-bin.jar" //找到jdbc驱动包
jdbc_driver_class => "com.mysql.jdbc.Driver" //找到驱动类
"jdbc:mysql:///news?useUnicode=true&characterEncoding=utf-8&useSSL=false" //找到指定的数据库,这后面的参数是一定要加的,不加会报错
jdbc_user => "root" //数据库用户名
jdbc_password => "root" //数据库密码
schedule => "* * * * *" //多长时间同步一次(这里是每分钟同步一次,如果logstash一直运行则每分钟一直同步)
jdbc_default_timezone => "Asia/Shanghai" //时区
statement => "SELECT * FROM news;" //执行的sql
}
}
filter { //查到数据库后的操作
mutate {
split => {"tags" => ","} //针对tags字段进行操作,通过逗号分割字段内容转为一个数组
}
}
output {
elasticsearch {
hosts => ["192.168.0.187:9200","192.168.0.187:9201","192.168.0.187:9202"] //es集群
index => "news" //索引名字
document_id => "%{id}" //从数据库查询到的id列作为索引里的文档id
}
}
3、在解压路径下打开cmd黑窗口,运行命令:
bin\logstash -f config\mysql.conf
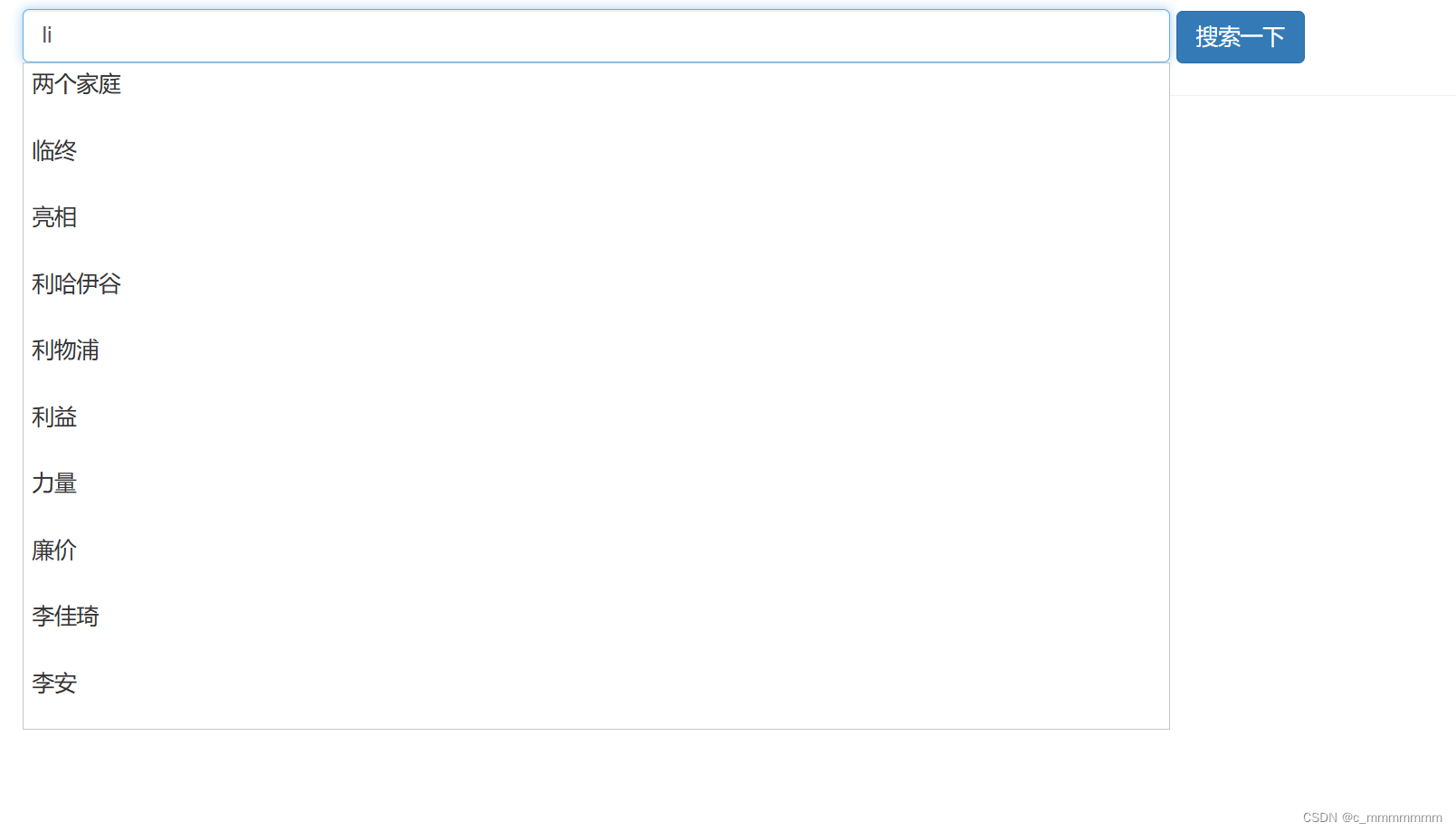
4、测试自动补齐
GET /news/_search
{
"suggest": {
"my_suggest": {
"prefix": "li",
"completion": {
"field": "tags",
"skip_duplicates": true,
"size": 10
}
}
}
}
一张表对应的就是一个对象,一个索引就是一张表,那么一个索引就对应了一个对象,所以我们需要创建News对象,属性对应的就是索引中的各个域
@Document(indexName = "news",createIndex = false) @Data @NoArgsConstructor @AllArgsConstructor public class News {@Id@Fieldprivate Integer id;@Fieldprivate String title;@Fieldprivate String content;@Fieldprivate String keyword;@CompletionField //Completion属性比较特殊需要使用@CompletionField修饰@Transientprivate Completion tags;}
编写Repository层
@Repository
public interface NewsRepository extends ElasticsearchRepository<News,Integer> {
}编写Service层
实现自动补全功能
1、创建补全请求
2、创建补全条件并且添加补全条件
3、查询
4、处理查询结果
@Service public class NewsService {@Autowiredprivate ElasticsearchRestTemplate template;public List<String> suggestion(String keyword){//1、创建补全请求SuggestBuilder suggestBuilder = new SuggestBuilder();//2、创建补全条件SuggestionBuilder suggestionBuilder = SuggestBuilders.completionSuggestion("tags") //补全字段.prefix(keyword) //补全前缀.skipDuplicates(true) //去除重复.size(10); //最大补全大小//添加补全条件suggestBuilder.addSuggestion("my_suggestion",suggestionBuilder);//3、查询SearchResponse response = template.suggest(suggestBuilder, IndexCoordinates.of("news"));//4、处理查询结果List<String> collect = response.getSuggest().getSuggestion("my_suggestion").getEntries().get(0).getOptions().stream().map(Suggest.Suggestion.Entry.Option::getText).map(Text::toString).collect(Collectors.toList());return collect;} }实现高亮字段功能
1、添加高亮查询方法
2、高亮查询
3、处理查询结果,将高亮字段设置到原始数据中
实现这个高亮字段功能需要先在repository接口中添加以findBy规则命名的方法,并且添加@HighLight注解
//该注解的作用就是设置需要高亮查询的字段
//该方法是按照SpringDataES规则命名,该方法可以通过对上传的title和Content参数进行match查询
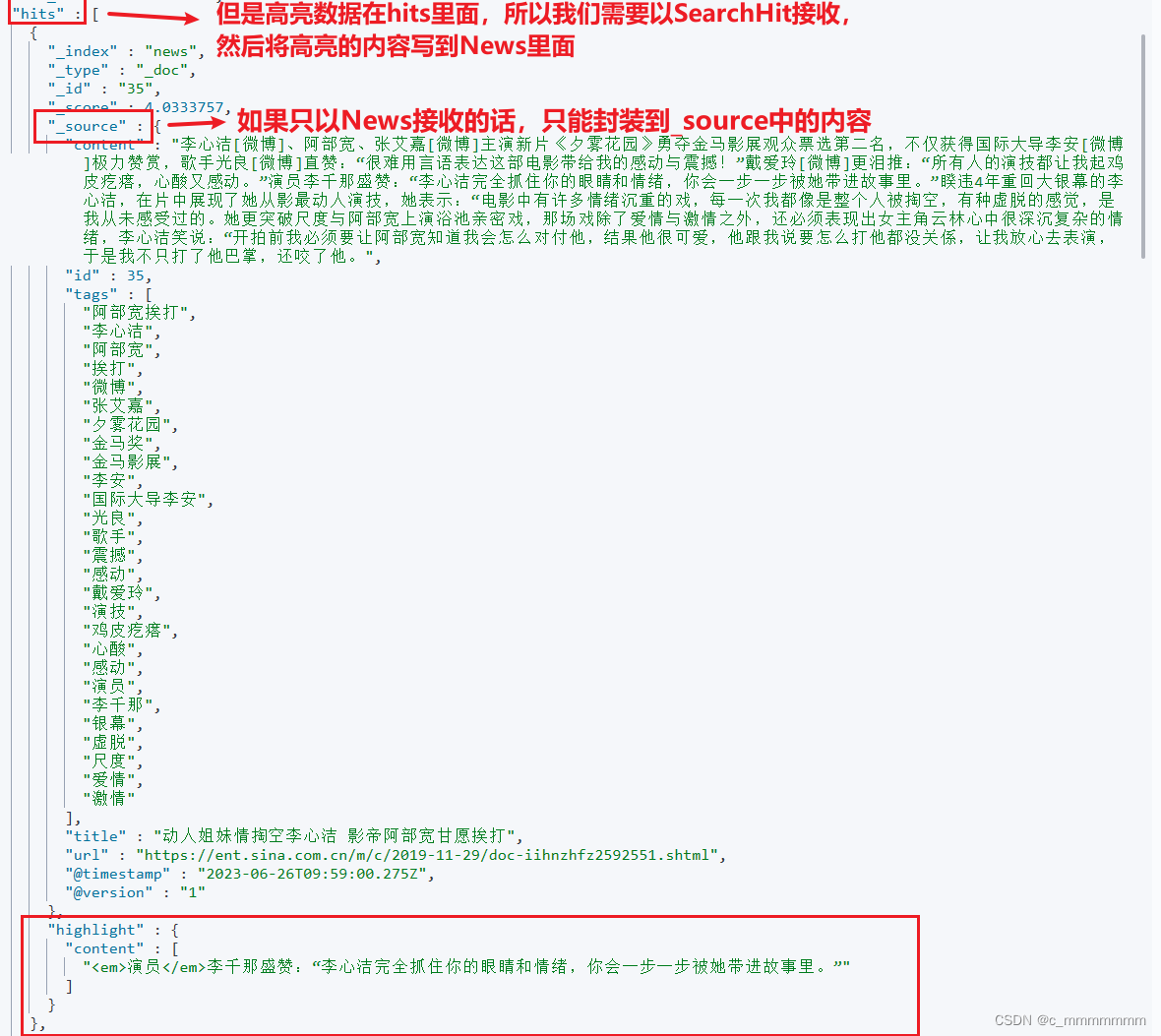
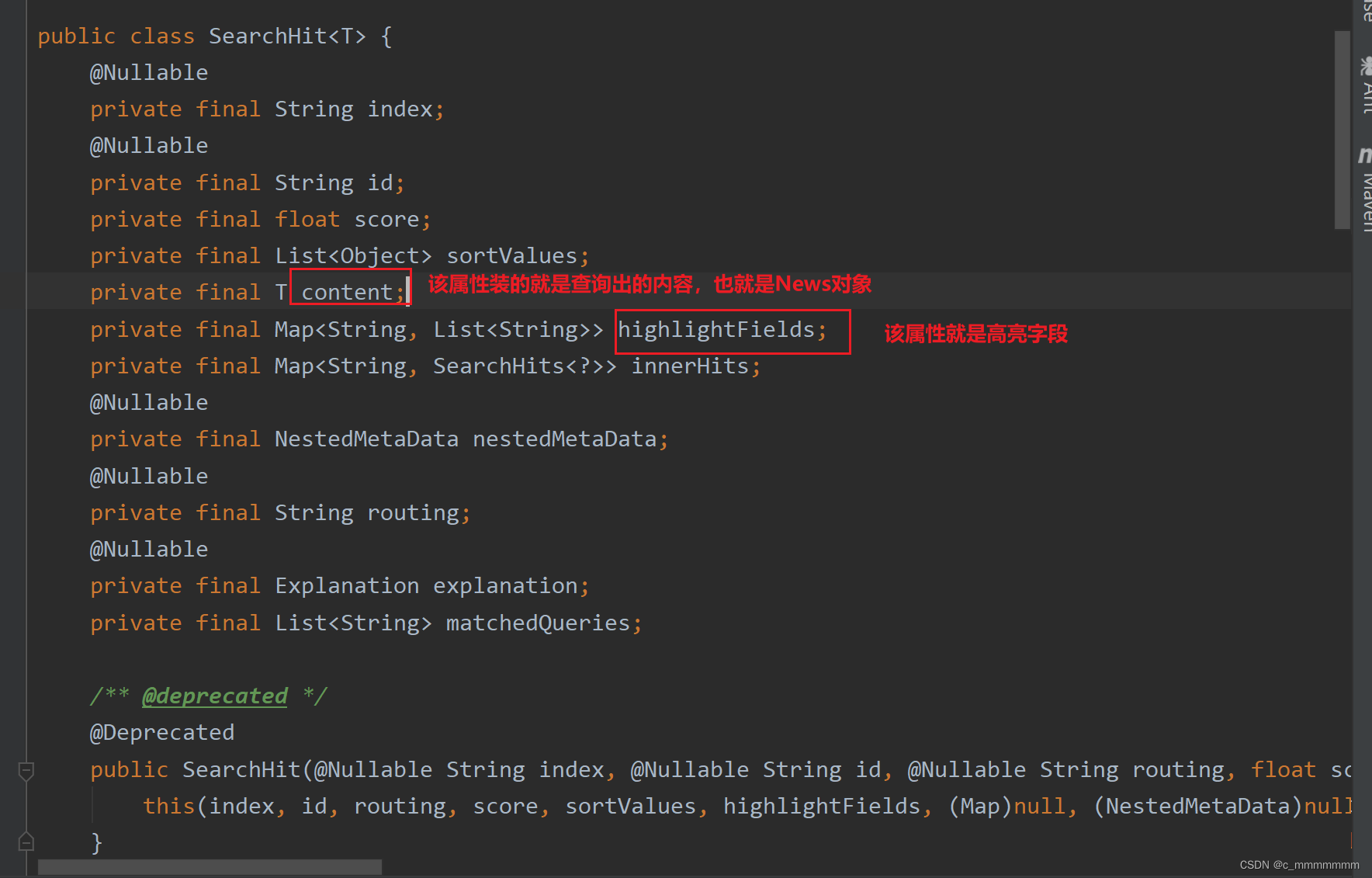
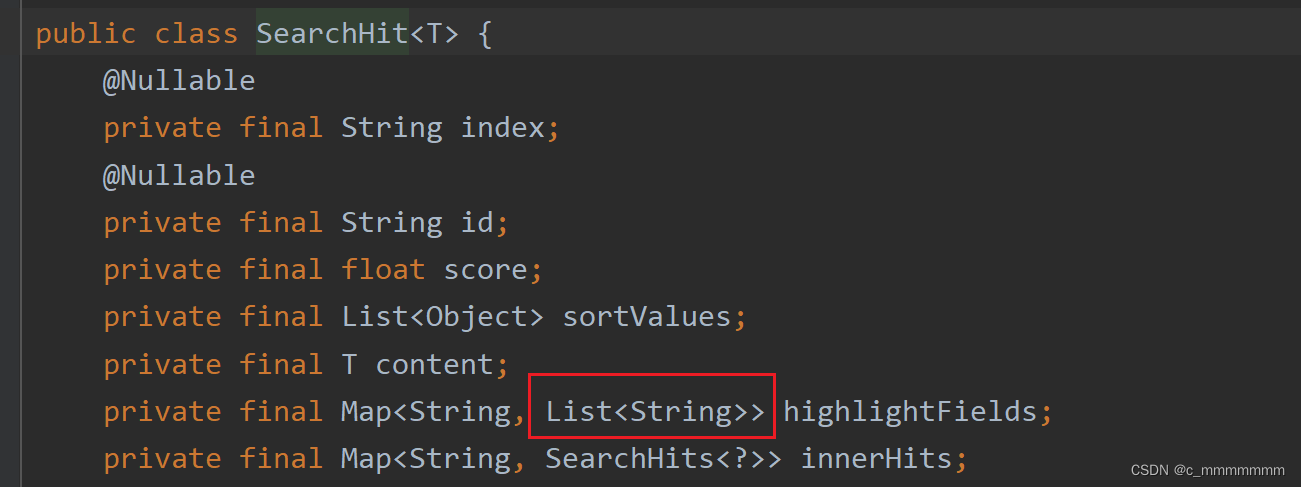
//该方法的返回值是SearchHit的容器,具体看图
//SearchHit里的结构,如下图
@Repository public interface NewsRepository extends ElasticsearchRepository<News,Integer> {@Highlight(fields = {@HighlightField(name = "title"),@HighlightField(name = "content")})public List<SearchHit<News>> findByTitleMatchesOrContentMatches(String title, String content); }实现功能
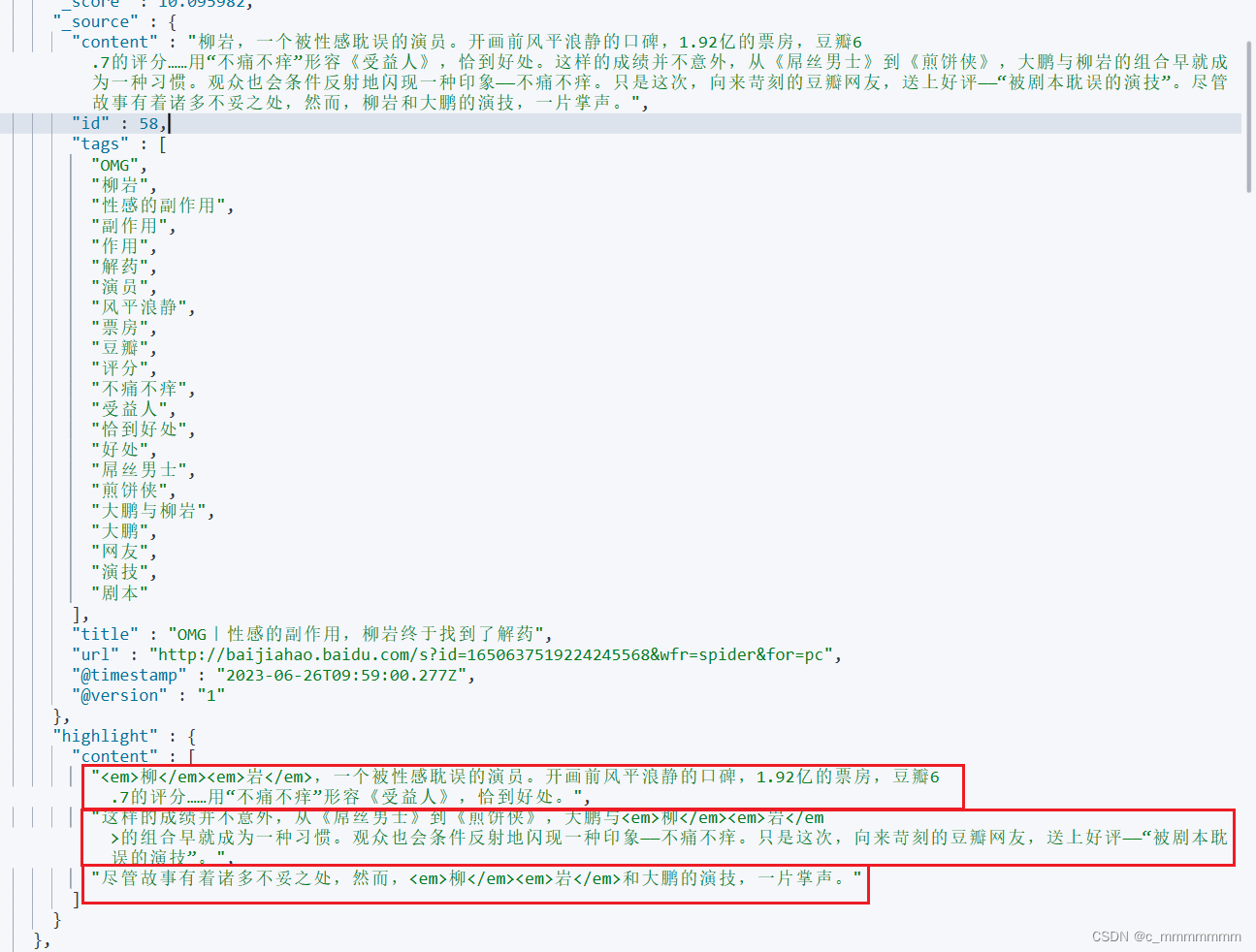
public List<News> highLight(String keyword){//构建新的news集合,该集合是有高亮字段的List<News> news = new ArrayList<>();//高亮查询List<SearchHit<News>> hits = repository.findByTitleMatchesOrContentMatches(keyword, keyword);//处理查询结果for (SearchHit<News> hit : hits) {News content = hit.getContent();//返回的是没有高亮字段的News//获取高亮字段Map<String, List<String>> highlightFields = hit.getHighlightFields();//如果有高亮字段匹配则将高亮字段设置进去if (highlightFields.get("title") != null){content.setTitle(highlightFields.get("title").get(0));}//如果有高亮字段匹配则将高亮字段设置进去if (highlightFields.get("content") != null){content.setContent(highlightFields.get("content").get(0));}news.add(content);}return news;}//这里的get(0)只是为了方便测试,但是如果一条文档的域的值有多个高亮字段匹配的话,则会分开存入集合中
//这是因为es在进行高亮搜索的时候,如果一条文档啊的域的值有多个高亮字段匹配,会以数组的方式分开存放,所以在使用
//SpringDataEs操作es的时候就会以集合的方式存入
编写Controller层
@RequestMapping所写的路径和方法参数名必须与我的匹配,因为后面提供的前端页面需要使用到
@RestController
public class NewsController {@Autowiredprivate NewsService newsService;@RequestMapping("/autoSuggest")public List<String> suggest(String term){return newsService.suggestion(term);}@RequestMapping("/highLightSearch")public List<News> highlight(String term){return newsService.highLight(term);}}编写前端页面
通过该链接获取前端资源,获取之后将该资源放到static目录中
百度网盘链接:https://pan.baidu.com/s/1SgcdqzdWC_530nWjJReLFA?pwd=tt5r
提取码:tt5r
启动项目访问localhost:8080/news.html
测试自动补全:
 测试高亮字段:
测试高亮字段: