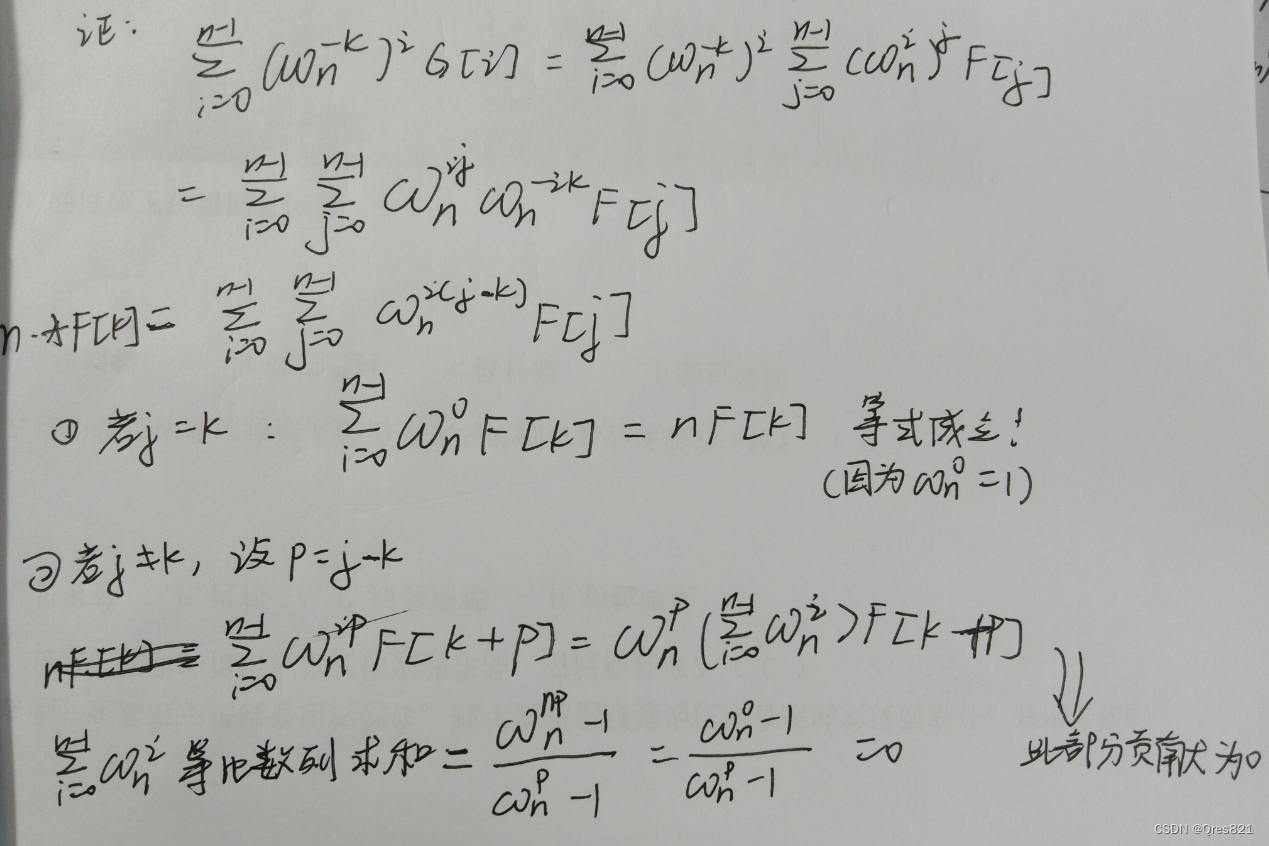全面了解 8.1.0 版本新功能:InnoDB Cluster 只读副本的相关操作。
作者:Miguel Araújo 高级软件工程师 / Kenny Gryp MySQL 产品总监
本文来源:Oracle MySQL 官网博客
* 爱可生开源社区出品。
前言
MySQL 的第一个 Innovation 版本 8.1.0 已经发布,我们将推出 MySQL InnoDB Cluster 只读副本。
在 MySQL InnoDB Cluster 中,副本(Secondray)节点的主要目的是在主(Primary)节点发生故障时做好切换替代(高可用性)。这是由 MySQL 组复制(MGR)插件配合完成的。副本节点的另一个用途是减少主节点的只读工作负载。
现在,可以向数据库拓扑结构中添加异步副本节点这些副本节点可以用于:
- 将读流量从主节点或者其他副本节点转移过来,分担它们的读压力。
- 设置专门用于读取的副本节点。
- 设置专门用于报表等特定目的的副本节点。
- 通过添加多个读取副本节点,实现超出其他副本节点处理能力范围的扩容。

MySQL InnoDB Cluster 会管理这些副本节点的操作,包括:
- MySQL Router 会自动重新导向流量。
- MySQL Shell 负责配置、初次预配(使用 InnoDB Clone 插件)。
- 复制配置和任何想要进行的拓扑结构变更。
只读副本节点也可以与 MySQL InnoDB ClusterSet 配合使用,这个模式下,副本节点可以添加到主集群或副本集群中。
MySQL Router 会识别这些读取副本节点,并根据一些配置选项将读流量重新导向到它们。这些读取副本节点会从主节点或者其他副本节点进行复制,如果复制中断或成员变更(例如新主节点选举),它会自动重新连接到另一个成员。
创建只读副本
将读取副本节点添加到集群中和添加从节点很相似。Admin API 的外观和交互方式保持不变,这可以确保最佳的用户体验。
假设您已经有一个运行中的集群,可以使用新增的这个命令来添加读取副本节点:
<Cluster>.addReplicaInstance(instance[, options])
mysqlsh-js> cluster.addReplicaInstance("rome4:3306")Setting up 'rome4:3306' as a Read Replica of Cluster 'rome'.
Validating instance configuration at rome4:3306...
This instance reports its own address as rome4:3306
Instance configuration is suitable.
* Checking transaction state of the instance...省略……* Waiting for clone to finish...
NOTE: rome4:3306 is being cloned from rome1:3306
** Stage DROP DATA: Completed
** Clone Transfer FILE COPY ############################################################ 100% CompletedPAGE COPY ############################################################ 100% CompletedREDO COPY ############################################################ 100% CompletedNOTE: rome4:3306 is shutting down...* Waiting for server restart... ready
* rome4:3306 has restarted, waiting for clone to finish...
** Stage RESTART: Completed
* Clone process has finished: 4.30 GB transferred in 4 sec (1.08 GB/s)
* Configuring Read-Replica managed replication channel...
** Changing replication source of rome4:3306 to rome1:3306
* Waiting for Read-Replica 'rome4:3306' to synchronize with Cluster...
** Transactions replicated ############################################################ 100% 'rome4:3306' successfully added as a Read-Replica of Cluster 'rome'.如此简单,一个新的副本就添加到集群中了。和普通的集群成员一样,只读副本也支持 Clone 或者增量预配。
和往常一样,可以用 <Cluster>.status() 命令检查集群的状态:
mysqlsh-js> cluster.status()
{"clusterName": "rome", "defaultReplicaSet": {"name": "default", "primary": "rome1:3306", "ssl": "REQUIRED", "status": "OK", "statusText": "Cluster is ONLINE and can tolerate up to ONE failure.", "topology": {"rome1:3306": {"address": "rome1:3306", "memberRole": "PRIMARY", "mode": "R/W", "readReplicas": {"rome4:3306": {"address": "rome4:3306", "role": "READ_REPLICA", "status": "ONLINE", "version": "8.1.0"}}, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.1.0"}, "rome2:3306": {"address": "rome2:3306", "memberRole": "SECONDARY", "mode": "R/O", "readReplicas": {}, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.1.0"}, "rome3:3306": {"address": "rome3:3306", "memberRole": "SECONDARY", "mode": "R/O", "readReplicas": {}, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.1.0"}}, "topologyMode": "Single-Primary"}, "groupInformationSourceMember": "rome1:3306"
}你可能注意到,新增的只读副本运行在 rome4:3306 端口,它被放置在集群主节点 rome1:3306 下面,这表示它会将 rome1:3306 当作源节点进行数据同步,即它会从 rome1:3306 节点复制数据。
从主节点复制数据有一些优点,如可以减少潜在的复制延迟。但是,它也可能增加主节点的负载。为了提供灵活性以及根据不同场景选择,我们改进让这个配置成为可配置项。
运行原理:源节点识别
如上所示,只读副本默认会从主节点进行同步,如果主从切换或故障转移发生,它会自动重新连接到集群新的主节点。换句话说,它总是会跟踪主节点,保持与集群的同步。
这是通过 MySQL 复制技术里的异步复制连接故障转移特性实现的。副本会检查组复制状态,存储一份潜在源服务列表。如果当前源服务下线,它会从列表中选择一个新的源。
这个源列表可以手动或自动维护,后者支持集群复制拓扑。在这种情况下,故障转移机制可以监控成员变更,相应添加或删除候选源。此外,它也能区分主从节点。这与 MySQL InnoDB Cluster 中副本集复制主集群的方式一致。
有了这样灵活的架构,Admin API 可以根据每个用户的需求管理和配置读取副本。
运行原理:配置只读副本
选择故障恢复候选项
从主节点复制有降低延迟的优点,但也可能增加主节点压力。
我们了解自动故障转移机制工作原理,理解不同配置选项:
- 优先从主节点复制
- 优先从副本节点中选择一个复制
- 设置候选列表
可以在添加副本时定义,或随时改变现有副本的配置。下图显示,Rome 地区副本选择从节点作为源,Brussels 副本选择主节点作为源。

作为一个例子,让我们使用指定实例作为源,同时预定义故障恢复候选列表,来向集群添加一个新的副本:
mysqlsh-js> cluster.addReplicaInstance("rome5:3306", {replicationSources: ["rome2:3306", "rome3:3306"]})
Setting up 'rome5:3306' as a Read Replica of Cluster 'rome'.Validating instance configuration at rome5:3306...This instance reports its own address as rome5:3306Instance configuration is suitable.
* Checking transaction state of the instance...
NOTE: A GTID set check of the MySQL instance at 'rome5:3306' determined that it is missing transactions that were purged from all cluster members.
NOTE: The target instance 'rome5:3306' has not been pre-provisioned (GTID set is empty). The Shell is unable to determine whether the instance has pre-existing data that would be overwritten with clone based recovery.
The safest and most convenient way to provision a new instance is through automatic clone provisioning, which will completely overwrite the state of 'rome5:3306' with a physical snapshot from an existing cluster member. To use this method by default, set the 'recoveryMethod' option to 'clone'.Please select a recovery method [C]lone/[A]bort (default Clone): c
* Waiting for the donor to synchronize with PRIMARY...
** Transactions replicated ############################################################ 100% Monitoring Clone based state recovery of the new member. Press ^C to abort the operation.
Clone based state recovery is now in progress.NOTE: A server restart is expected to happen as part of the clone process. If the
server does not support the RESTART command or does not come back after a
while, you may need to manually start it back.* Waiting for clone to finish...
NOTE: rome5:3306 is being cloned from rome2:3306
** Stage DROP DATA: Completed
** Clone Transfer FILE COPY ############################################################ 100% CompletedPAGE COPY ############################################################ 100% CompletedREDO COPY ############################################################ 100% CompletedNOTE: rome5:3306 is shutting down...* Waiting for server restart... ready
* rome5:3306 has restarted, waiting for clone to finish...
** Stage RESTART: Completed
* Clone process has finished: 4.30 GB transferred in 6 sec (717.27 MB/s)* Configuring Read-Replica managed replication channel...
** Changing replication source of rome5:3306 to rome2:3306* Waiting for Read-Replica 'rome5:3306' to synchronize with Cluster...
** Transactions replicated ############################################################ 100% 'rome5:3306' successfully added as a Read-Replica of Cluster 'rome'.此次就是完成向集群添加运行在 rome5:3306 上的新的读取副本。
这个副本使用一个固定的候选失败列表,包含 rome2:3306 和 rome3:3306,其中 rome2:3306 是当前运行中的源服务。列表中的其他成员是潜在的失败转移候选,他们的顺序决定权重,靠前的权重高,靠后的权重低。
让我们查看集群描述,以更直观地了解当前的拓扑结构:
mysqlsh-js> cluster.describe()
{"clusterName": "rome", "defaultReplicaSet": {"name": "default", "topology": [{"address": "rome1:3306", "label": "rome1:3306", "role": "HA"}, {"address": "rome2:3306", "label": "rome2:3306", "role": "HA"}, {"address": "rome3:3306", "label": "rome3:3306", "role": "HA"}, {"address": "rome4:3306", "label": "rome4:3306", "replicationSources": ["PRIMARY"], "role": "READ_REPLICA"}, {"address": "rome5:3306", "label": "rome5:3306", "replicationSources": ["rome2:3306", "rome3:3306"], "role": "READ_REPLICA"}], "topologyMode": "Single-Primary"}
}同样,使用扩展状态,我们可以查看当前拓扑结构的更多信息:
mysqlsh-js> cluster.status({extended:1})
{"clusterName": "rome", "defaultReplicaSet": {"GRProtocolVersion": "8.0.27", "communicationStack": "MYSQL", "groupName": "33cfdab9-3469-11ee-9f3b-d08e7912e4ee", "groupViewChangeUuid": "33cfe2b0-3469-11ee-9f3b-d08e7912e4ee", "groupViewId": "16913336945761559:7", "name": "default", "paxosSingleLeader": "OFF", "primary": "rome1:3306", "ssl": "REQUIRED", "status": "OK", "statusText": "Cluster is ONLINE and can tolerate up to ONE failure.", "topology": {"rome1:3306": {"address": "rome1:3306", "applierWorkerThreads": 4, "fenceSysVars": [], "memberId": "e304af5d-3466-11ee-8d97-d08e7912e4ee", "memberRole": "PRIMARY", "memberState": "ONLINE", "mode": "R/W", "readReplicas": {"rome4:3306": {"address": "rome4:3306", "applierStatus": "APPLIED_ALL", "applierThreadState": "Waiting for an event from Coordinator", "applierWorkerThreads": 4, "receiverStatus": "ON", "receiverThreadState": "Waiting for source to send event", "replicationLag": null, "replicationSources": ["PRIMARY"], "replicationSsl": "TLS_AES_256_GCM_SHA384 TLSv1.3", "role": "READ_REPLICA", "status": "ONLINE", "version": "8.1.0"}}, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.1.0"}, "rome2:3306": {"address": "rome2:3306", "applierWorkerThreads": 4, "fenceSysVars": ["read_only", "super_read_only"], "memberId": "e6eb91c6-3466-11ee-aca6-d08e7912e4ee", "memberRole": "SECONDARY", "memberState": "ONLINE", "mode": "R/O", "readReplicas": {"rome5:3306": {"address": "rome5:3306", "applierStatus": "APPLIED_ALL", "applierThreadState": "Waiting for an event from Coordinator", "applierWorkerThreads": 4, "receiverStatus": "ON", "receiverThreadState": "Waiting for source to send event", "replicationLag": null, "replicationSources": ["rome2:3306", "rome3:3306"], "role": "READ_REPLICA", "status": "ONLINE", "version": "8.1.0"}}, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.1.0"}, "rome3:3306": {"address": "rome3:3306", "applierWorkerThreads": 4, "fenceSysVars": ["read_only", "super_read_only"], "memberId": "ea08833f-3466-11ee-b87c-d08e7912e4ee", "memberRole": "SECONDARY", "memberState": "ONLINE", "mode": "R/O", "readReplicas": {}, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.1.0"}}, "topologyMode": "Single-Primary"}, "groupInformationSourceMember": "rome1:3306", "metadataVersion": "2.2.0"
}改变故障候选项
改变源配置就像改变实例选项一样简单。Cluster.setInstanceOption() 增强了一个新的选项 replicationSources,允许执行这个操作:
让我们修改第一个读取副本的配置,优先从第二实例而不是主实例进行同步。
mysqlsh-js> cluster.setInstanceOption("rome4:3306", "replicationSources", "secondary")
Setting the value of 'replicationSources' to 'secondary' in the instance: 'rome4:3306' ...WARNING: To update the replication channel with the changes the Read-Replica must be reconfigured using Cluster.rejoinInstance().
Successfully set the value of 'replicationSources' to 'secondary' in the cluster member: 'rome4:3306'.为让新的设置立即生效,我们需要使用 Admin API 非常有名的命令 Cluster.rejoinInstance() 强制实例重新加入集群:
mysqlsh-js> cluster.rejoinInstance("rome4:3306")
Rejoining Read-Replica 'rome4:3306' to Cluster 'rome'...* Checking transaction state of the instance...
The safest and most convenient way to provision a new instance is through automatic clone provisioning, which will completely overwrite the state of 'rome4:3306' with a physical snapshot from an existing cluster member. To use this method by default, set the 'recoveryMethod' option to 'clone'.The incremental state recovery may be safely used if you are sure all updates ever executed in the cluster were done with GTIDs enabled, there are no purged transactions and the new instance contains the same GTID set as the cluster or a subset of it. To use this method by default, set the 'recoveryMethod' option to 'incremental'.Incremental state recovery was selected because it seems to be safely usable.NOTE: User 'mysql_innodb_replica_2506922964'@'%' already existed at instance 'rome1:3306'. It will be deleted and created again with a new password.
** Changing replication source of rome4:3306 to rome2:3306* Waiting for Read-Replica 'rome4:3306' to synchronize with Cluster...
** Transactions replicated ############################################################ 100% <strong>Read-Replica 'rome4:3306' successfully rejoined to the Cluster 'rome'.说明:和普通实例一样,使用 Cluster.removeInstance() 可以从集群中删除读取副本。
路由读请求到副本
MySQL Router 在 InnoDB Cluster 中扮演着至关重要的角色,所以现在它完全知晓只读副本的存在。Router 位于应用和集群之间,将客户端流量定向到正确的目标。它可以为只读请求使用只读副本。但是从节点也可以,那么它如何选择?
配置 Router 目标池
默认情况下,Router 的行为不变,即读流量定向到集群的从节点。但是,现在是可配置的。
read_only_targets 模式接受以下可能的行为:
- secondaries:只将目标集群的副本成员用作只读流量(默认)
- read_replicas:只将目标集群的读取副本用于只读流量
- all:将目标集群的所有读取副本以及其他副本成员一起用于只读流量
该模式可以通过另一个常见的命令 .setRoutingOption() 进行配置,该命令可以在 Router、Cluster 或 ClusterSet 级别进行配置。
例如:
mysqlsh-js> cluster.setRoutingOption("read_only_targets", "all")
Routing option 'read_only_targets' successfully updated.mysqlsh-js> cluster.routingOptions()
{"clusterName": "rome", "global": {"read_only_targets": "all", "stats_updates_frequency": null, "tags": {}}, "routers": {"domus::": {}}
}下图显示了更复杂的拓扑,其中 ClusterSet 由主集群(Rome)和部署了多个路由器的副本集群(Brussels)组成。
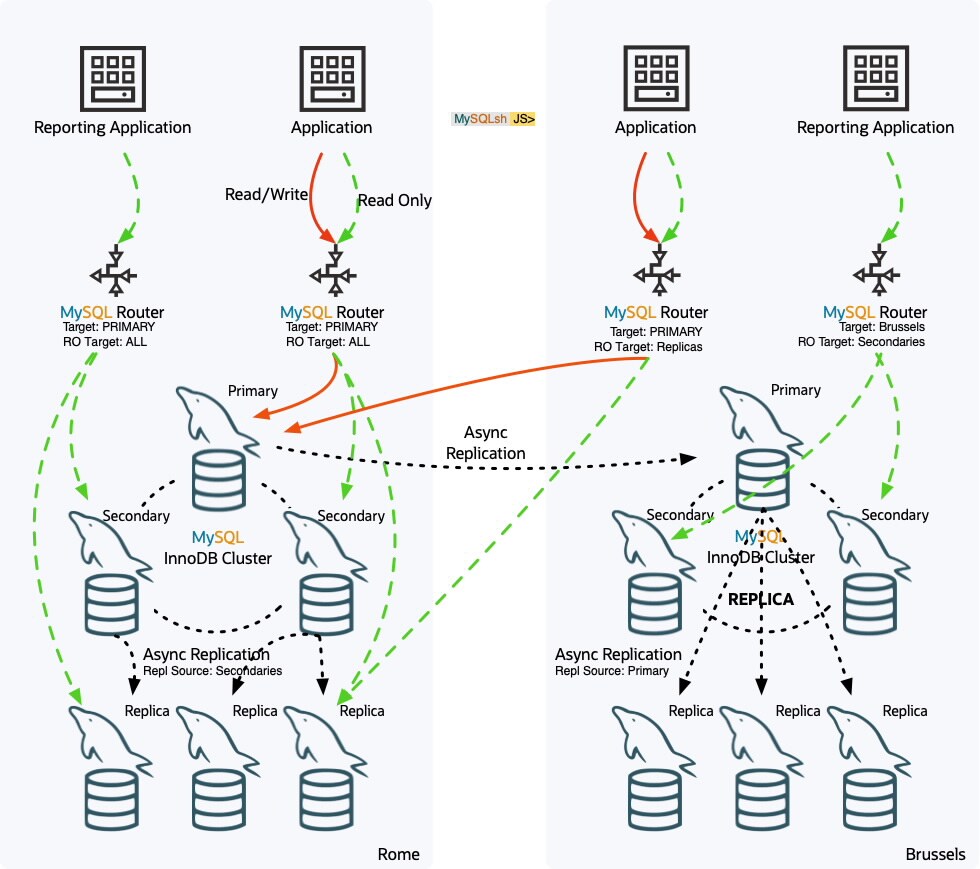
主要集群是包含 3 个主要成员和 3 个只读副本的 3 个成员集群。读取副本使用 sourcesList:"secondary ,因此它们从集群的次要成员进行复制。
部署在该数据中心的两个路由器使用主要集群作为目标集群,并且被配置为使用所有读取目标,即 read_only_targets:all 。
另一个数据中心的副本集群也是一个 3 个成员的集群,包含 3 个只读副本,它们被配置为从主集群主成员进行复制。两个路由器有不同的配置:第一个路由器被配置为使用主要集群作为目标集群,并且只将读取副本用于只读目标,即 read_only_targets: read_replicas。另一个路由器被配置为使用 Brussels 作为目标集群,并且只将次要成员用于只读目标,即 read_only_targets:secondaries。
健康检查和隔离
MySQL Router 作为无状态服务,因此它依赖于 InnoDB Cluster 成员信息进行准确的路由。MGR 基于 Paxos 实现提供集群成员服务,定义哪些服务器在线并参与组。通过利用该信息,Router 避免连接到每个成员检查其状态。
然而,当只读副本也是集群的一部分时,该信息在组成员信息中不可用,Router 无法依赖于该机制。同时,集群成员间看到的可用性不同于 Router 视角,成员信息可能不准确。
为解决这些挑战,Router 实现了内置的隔离机制。
简而言之,当 Router 由于新用户连接尝试连接目标端点失败时,它会将该目标置于隔离状态。但目标不会永远停留在隔离状态,在超时后,Router 会对该服务器执行健康检查,以确定是否可以从隔离池中移除它。
隔离机制在两个方面是可配置的:
- 隔离阈值:接受失败连接尝试的次数,直到服务器被隔离。
- 隔离服务器应该多频繁进行健康检查。
默认情况下,这两个设置的值都是 1,即失败连接会导致目标实例被隔离,每秒对隔离实例进行健康检查,以查看是否可以从隔离池中移除。
复制延迟
同步复制会导致复制延迟是常见问题,需要考虑。如果实例延迟严重,DBA 可能希望隐藏它,等待它恢复同步,然后再将它曝光给应用。
此外,DBA 也可能希望隐藏读取副本:
- 进行不断升级而不影响流入流量
- 进行维护操作或配置更改而无需停止 MySQL
- 在备份或生成报表时排除它以免影响其他查询
- 将其配置为备份服务器,排除任何读流量
与常规集群成员一样,这可以通过指导 Router 不使用其标签来实现。
隐藏副本
要将实例从 Router 流量中隐藏,可以使用内置的 _hidden 标签,通过 .setInstanceOption() 命令很容易设置:
mysqlsh-js> cluster.setInstanceOption("rome5:3306", "tag:_hidden", true)该功能不限于副本,次要实例也可以标记为隐藏。
总结
只读副本可以扩展读密集型工作负载的规模,减轻其他集群成员的压力,并提供更多的数据冗余。
感谢您使用 MySQL!
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
爱可生开源社区的 SQLE 是一款面向数据库使用者和管理者,支持多场景审核,支持标准化上线流程,原生支持 MySQL 审核且数据库类型可扩展的 SQL 审核工具。
SQLE 获取
| 类型 | 地址 |
|---|---|
| 版本库 | https://github.com/actiontech/sqle |
| 文档 | https://actiontech.github.io/sqle-docs/ |
| 发布信息 | https://github.com/actiontech/sqle/releases |
| 数据审核插件开发文档 | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |