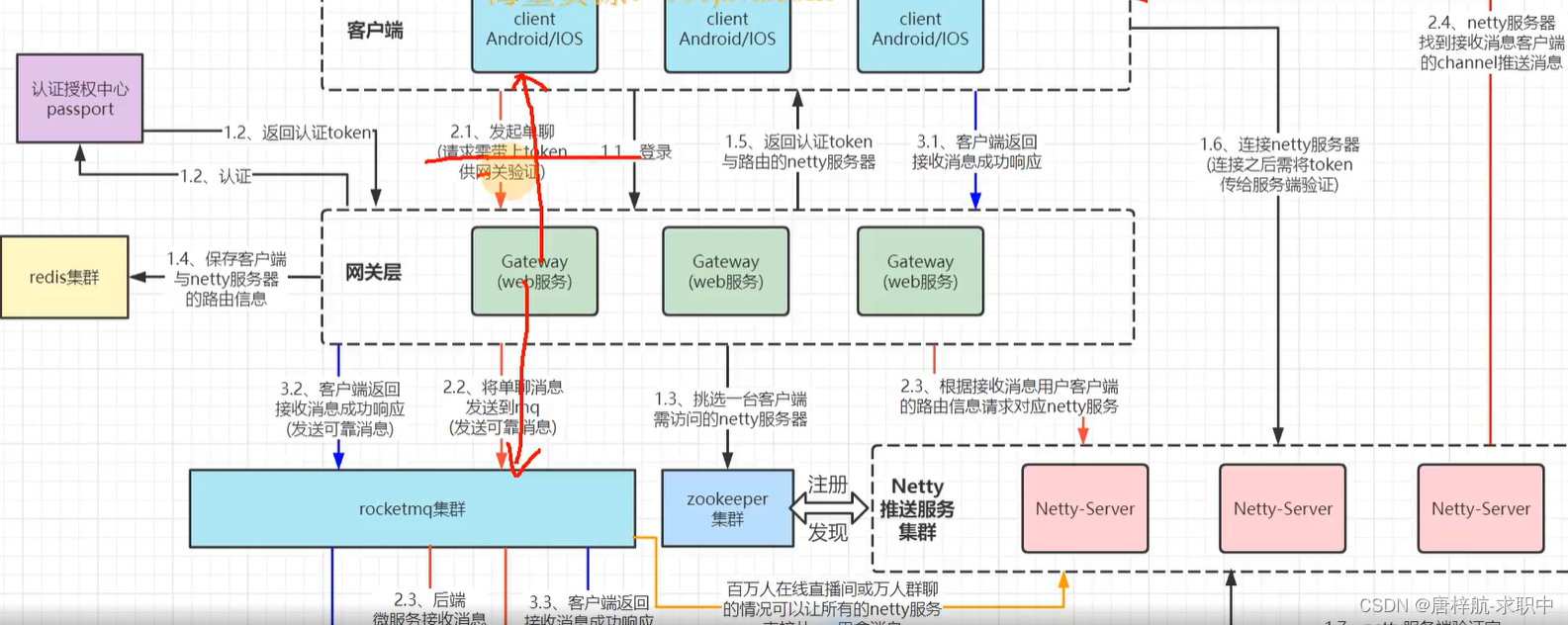
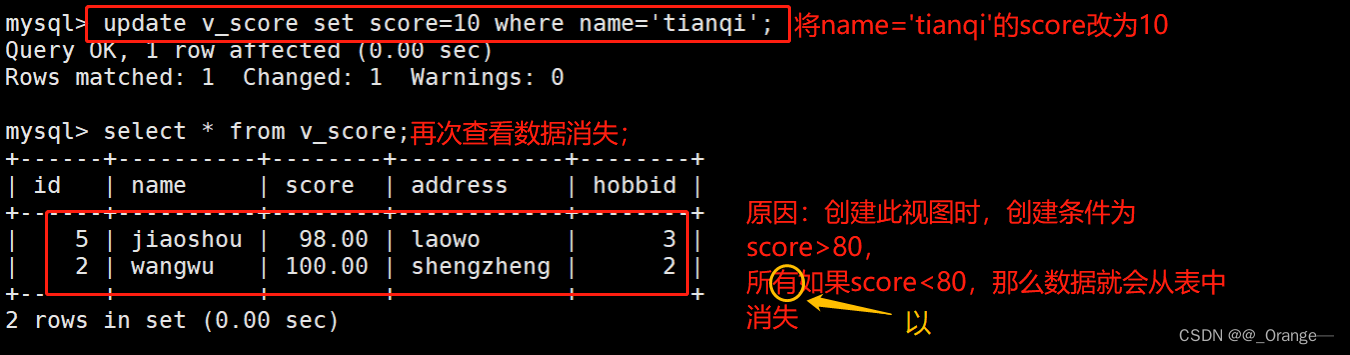
编者按
本文系东北大学李俊虎所著,也是「 OceanBase 学术加油站」系列第 11 篇内容。
「李俊虎:东北大学计算机科学与工程学院在读硕士生,课题方向为数据库查询优化,致力于应用 AI 技术改进传统基数估计器,令数据库选择最优查询计划。」
今天分享的主题是“学习型基数器”,为大家贡献了一种新的基准测试方法,并从多方面综合评价了各种技术模型。希望阅读完本文,你可以对学习型基数估计器有新的收获,当然也可以有不同看法,欢迎在底部留言探讨。

* 论文标题"Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation", 点击文末“阅读原文”即可下载学习。
查询优化器非常依赖准确的基数估计来选择代价最低的查询计划。事实上,由于传统的基数估计器在高偏度,高相关的数据集中表现很差,因此目前人们正寻求建立学习型基数估计器改善其性能。
然而,目前的学习型基数估计器在生产环境下能有多好的表现?本文提出了之前相关研究的一些不足:
-
目前用于评估的数据和查询负载并不能很好地代表生产环境的真实数据。
-
现有的评估方式并没有直接体现出基数估计方法对优化器的端到端提升。目前的指标只聚焦于准确性,但事实上,估计精度并不完全等价于查询计划的质量。
针对于上述研究动机,本文有以下贡献:
第一,为基数估计工作建立了一个新的基准测试,它可以代表生产环境下的设置。本文的基准测试包括了一个真实数据集 STATS 和一个人工筛选的 STATS-CEB。STATS 包含了复杂的属性,STATS-CEB 包含了许多不同的多表连接查询。
第二,为基数提供了一个端到端的评估平台,并选择了各类具有代表性的方法进行评估,各种方法被集成到开源的 PostgreSQL (下文简称 PG ) 数据库内置的优化器内。
第三,本文从推理延迟,模型大小,训练时间,更新效率等方面综合评价了已有的各种基数估计模型。
第四,受最近的研究启发[1,2],本文提出了一个新的度量方式:P-Error。相较于 Q-Error 而言,它更能体现出端到端的查询性能。
第五,本文还认为,学习型基数估计方法应当尝试支持更多类型的查询。此外,最好能够通过调整模型或方法的参数或配置,以应对不同场合下的基数估计任务,比如 OLTP 和 OLAP。
从设计原则上考虑,本文应当以端到端的性能去优化学习模型,同时将研究重点放到多表查询中。

数据库的基数估计通常被定义成一个统计问题。比如一个表 T 有 k 个属性。假定每一个属性的域是 Di。此后,T 的任何查询都可以用标准的 Q = { A1 ∈ R1, A2 ∈ R2, ... } 来表示,其中 Ri 指该查询中对属性 Ai 的约束域。假设查询 Q 不对 Ai 有约束,则可认为 Ri = Di。
基数估计期望在不对 T 表物理执行 Q 的条件下估计出基数 Card(T, Q) 的值。本文重点评估数值型和分类型 (如性别只分为男,女) 属性。同时,文献中存在许多基数估计方法,可以分为以下三类:
-
传统的基数估计方法,比如直方图和采样方法[3,4,5],它们被广泛用于 DBMS 中,通常基于简化的独立性假设,均匀分布假设或者均匀分布假设。
-
学习型查询驱动方法,通过尝试学习一个模型,将每一个特征化查询 Q 直接映射为 Card(T, Q)。这类方法试图使用更复杂的网络模型来提高基数估计方法的性能。
-
学习型数据驱动方法,这类方法强调直接从数据中求得联合分布概率,然后采用 Card(T, Q) = P(Q)·|T| 的公式去估计基数。因此,可以将基数估计问题简化为求表 T 的概率模型。其中最具备代表性的是深度自回归模型,以及基于 SPN 的模型。
除此之外,本文提出了更加接近生产环境的 STATS 作为基准测试集,它具有更大的数据规模,更复杂的数据分布,更大的查询空间,且表之间包含了 PK-FK,FK-FK 的更加丰富的连接关系,见图 1,而 STATS-CEB 则是相应的工作负载,这意味着对其进行基数估计要更有挑战性。
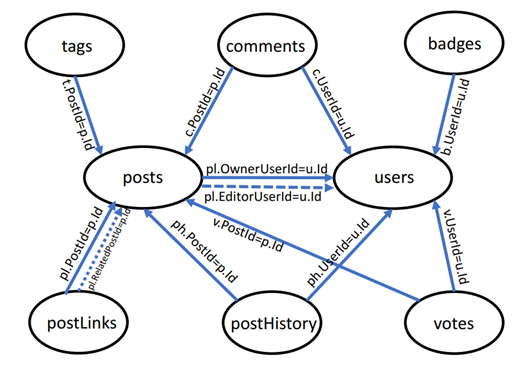
图 1 STATS 数据集 Join 关系
本文的目标是评估基数估计算法在真实 DBMS 中的行为,包括在本文的新基准测试上对优化查询计划和其他实用性方面的端到端改进。

本文上述三类方法中选了 13 个代表性的详细方案,首先是 5 个非学习 (本文称传统) 型估计方法:
-
PG[6]采取基于直方图的估计,它假设所有属性都是相互独立的。
-
MultiHist[7]则识别相关属性的子集,并将它们建模为多维直方图。
-
UniSample[5,8] 不做任何假设,而是根据PT (A)随机从T中即时获取记录来估计概率PT (Q),它也被广泛应用于MySQL和MariaDB等DBMS中。
-
WJSample[9]设计了一个基于随机游走的方法从多个表中采样元组。它已经被集成到DBMS中。
-
PessEst[10] 利用随机散列和数据草图来缩小多连接查询的界限,它的性能已经在真实的 DBMS环境中被证实是优秀的。
一、学习型基数估计算法
在本文的评估中,本文选择了四种查询驱动模型 MSCN, LW-XGB, LW-NN 和 UAE-Q 和四种数据驱动模型 NeuroCard, BayesCard, DeepDB 和 FLAT。它们各自应用不同的统计模型,并使用每种模型展示了最先进的性能。清单如下:
-
MSCN[11] 是一种基于多集卷积网络模型的深度学习方法。假设有一个作用于 T 表的查询 Q,模型将表的属性特征、查询的连接关系和谓词送入三个独立的模块,然后将这些模块的输出池化后再输入到最终的神经网络进行估计。
-
LW-XGB[12] 和LW-NN[12] 将基数估计作为回归问题,分别应用梯度增强树和神经网络进行回归。
-
UAE-Q[13] 采用深度自回归模型学习映射函数。它通过Gumbel-Sotfmax技巧提出可微渐进抽样,使深度自回归模型能够从查询中学习。
-
NeuroCard[14] 是 Naru 的多表扩展,建立在一个深度自回归模型上,核心思想是构建一个条件联合分布。
-
BayesCard[15] 将所有属性之间的依赖关系建模为一个有向无环图,是 BN 模型的有效改进。
-
DeepDB[16],基于和积网络(SPN) 递归地将 PT (A) 分解为局部独立的“直方图”。
-
FLAT[17] 则是对 SPN 模型的改进版本,新增了一个 factorize 节点分解强,弱关联的属性集合,整体建模过程和 SPN 类似。
对于 DeepDB 和 FLAT,本文分别将 RDC 阈值设置为 0.3 和 0.7,用于过滤独立和高度相关的属性。
UAE 扩展了 UAE- q 方法,使用自回归模型将查询信息和数据信息统一起来。它是一项旨在整合数据驱动和查询驱动的模型。
二、系统设置
本文将每个 CardEst 算法集成到 PG 的查询优化器中,这是一个开源 DBMS。然后,每个 CardEst 方法的质量可以通过注入基数估计的端到端查询运行时直接反映出来。
在介绍集成策略的细节之前,本文提出了一个重要的概念,称为子计划查询。对于每个 SQL 查询 Q,每个子计划查询都是一个只涉及 Q 中表的子集的查询,所有这些查询的集合称为子计划查询空间。对于示例查询 A⋈B⋈C,它的子计划查询空间包含了对 A⋈B,A⋈C,B⋈C、A、B 和 C 的查询以及相应的过滤谓词。DBMS 中的内置计划器将生成子计划查询空间,估计它们的基数,并确定最佳执行计划。
事实上,基数估计还可能会影响连接顺序,连接方法等物理计划的选择。因此,基数估计对最终查询执行计划的提升完全取决于它如何影响计划的选择。
三、评价指标
本文的评估主要集中在从不同方面直接反映 CardEst 算法性能的量化指标上。本文将它们列举如下:
-
查询工作负载的端到端时间,包括查询计划生成时间和物理计划执行时间。它是基数估计算法的“黄金标准”,因为提高端到端时间是在查询优化器中优化基数估计的最终目标。
-
推理延迟反映了基数估计的时间成本,与查询计划生成时间直接相关。理论上说,越准确的基数估计可能越耗时,这甚至大大超过了最后的执行延时,导致端到端的总体性能下降。
-
模型存储成本,轻量级的模型更容易存储和运输。
-
训练成本,这里指模型的离线训练时间。
-
更新速度,反映了基数估计模型为了重新适应新数据而带来的更新成本。这对于 OLTP 业务非常重要,因为数据总是在更新。
本文以基于真实基数的 TrueCard 代价估计器作为测试基准,因为理论上它应当总能 ( 98% 的概率 ) 指出最优的查询计划。
除了这些指标之外,本文还提出了一些与 CardEst 算法的稳定性、使用和部署相关的定性指标,并进行了综合分析,使用 O1,O2,... 等标识出了实验结论。

本文研究了以上基数估计方法在提高查询计划方面上的有效性。本文的评估侧重于静态环境,其中系统中的数据是只读的,这种环境常见于 OLAP 业务中。
一、端到端性能评估
本文评估了所有的基数估计方法在 JOB-Light 和 STATS-CEB 基准上的端到端性能,如下表所示。本文将依据这些方法相对于 PG 和 TrueCard 的提升作为端到端性能指标。
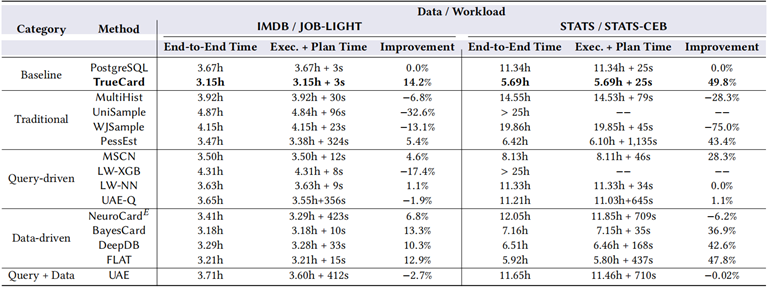
表 1 各方法在 IMDB 及 STATS 下的性能表现
O1:大部分数据驱动的基数估计方法都可以显著提升性能。本文认为,数据驱动的基数估计方法可以准确表征数据分布,以及对连接的表之间做一些合理的独立性假设。
传统的直方图和基于采样的方法的性能比 PG 差,而其它新提出的方法效果明显更好。基于查询驱动的基数方法的性能不稳定,因为它们依赖大量已经执行的查询作为训练数据。
O2:在具备更复杂数据分布和连接模式的数据集上,基数估计方法的性能有巨大差异。
在 JOB-Light 上,诸如 PessEst,NeuroCard,BayesCard,DeepDB 和 FLAT 的基数估计方法的执行时间都差不多是 3.2h,已经非常接近 TrueCard 的最小执行时间。原因是:IMDB 大部分数据都是主键连接的,因此联合分布相对容易计算。
但是 STATS 数据集有各种复杂的属性相关和连接类型,因此它们在 STATS 上的性能差异非常大,而 STATS-CEB 揭示了这些方法的优缺点。
传统基数估计方法分析:直方图以及采样的方法在两个基准上的性能都不如 PG,因为它们均采取了过于理想的假设。MultiHist 和 UniSample 使用连接一致性假设去估计连接查询,每当查询连接越多的表时,带来的级联误差也将迅速增大。
WJSample 通过随机游走的方式从多表连接中进行取样。但连接的表变多时,基数也将随之增加,再使用小样本抽样获得的信息量相对减少,因此误差也会增大。
总的来说,查询驱动方法面临复杂度和准确性的取舍:如果模型不够复杂,那么模型就无法完全理解分布。但另一方面,负载转移问题 ( workload shift issue ) 表明,复杂的查询驱动方法很难将一个工作负载上的模型迁移到其它的工作负载中去。
学习型数据驱动的基数估计性能稳定优于 PG 约 7-13%。除了 NeuroCard 之外,其它三者甚至将 PG 的查询性能提高了 37-48%。这些都表明,基于数据驱动的方法可以作为 PG 基数估计组件的潜在替补。还有以下观察结果:
O3:首先,统计数据集包含的属性明显更多,域空间也越大,这对于 NeuroCard 的深度自回归模型不利。其次,STATS 的全外连接大小明显多于简化的 IMDB,这使得 NeuroCard 的采样效率变低了。一旦数据变得偏斜,那么 NeuroCard 就很难捕捉到正确的数据分布,尤其是基数较小的连接表。
其它三种数据驱动的基数估计方法 BayesCard,DeepDB 和 FLAT 都显著优于 PG,因为它们的模型不是在所有表的全外连接上构建的。通过这种方式,它们可以通过构建 BN,SPN 等方式捕获表的每个子集内的丰富相关性。
二、对不同查询类型的分析
本文进一步研究基数估计方法在不同查询类型,不同表连接数量,以及不同的基数量级上,相较于 PG 的改进程度。由于 JOB-Light 工作负载没有体现出查询多样性,因此学习型数据驱动方法没有在此体现出明显差异性,因此,本节只研究基于 STATS-CEB 上的查询,同时仅比较性能提升明显的方法:MSCN,BayesCard,DeepDB 和 FLAT。

表 2 在不同连接表数量时的性能对比
连接表的数量:表2 显示了不同学习型方法在不同 Join 表数量时的相对性能改进,本文得出以下观察结果:
O4:这些方法相对于 TrueCard 的性能改进随着连接表的数量而增加。但是,对于连接大量表的查询,此估计误差可能会累积,从而导致次优查询计划,此时估计质量反而会下降。
O5:具有大基数的查询的准确估计优势比小基数查询更加重要。当 Q57 执行计划的根节点选择连接方法时,BayesCard 低估了最终连接的大小,并选择了 merge join 物理操作。而 FLAT 更准确的估计了最终连接的大小,并选择了哈希连接操作,导致时延是其它方法的两倍。
O6:选择正确的物理算子有时候要比选择更优的 Join-Order 更加重要。
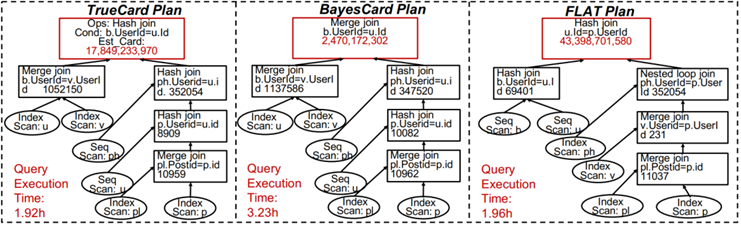
图 2 STATS Q57 查询计划
如图 2 所示,BayesCard 可以生成 Q57 的最优连接顺序,因为它对除根节点处的查询之外的所有子计划查询进行了近乎完美的估计,而 FLAT 选择的连接顺序与最优连接顺序非常不同。结果是 FLAT 因为选择了“正确的”物理算子产生了相对更低的查询时延。

本节还将讨论基数估计方法对其他方面的影响,包括推理时延,模型尺寸和训练时间,以及模型更新速度和正确率。
一、推理延时方面
首先是推理时延,为了显示其重要性,本文把 STATS-CEB 的查询分为 OLTP 和 LOAP 两种工作负载,实验数据见表 3:
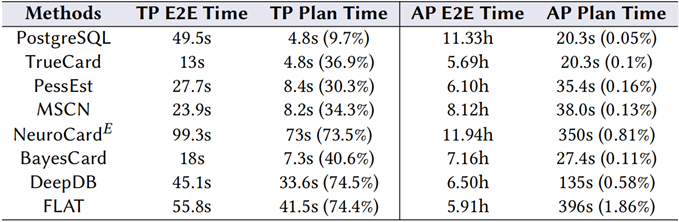
表 3 各方法在 OLTP / OLAP 下的性能
O7:OLTP 工作负载中推理时延的影响很大,但 OLAP 很小。在 OLTP 负载中,计划时间占据了总端到端时间的大部分。
特别是 NeuroCard , DeepDB 和 FLAT 的推理速度相对较慢,尽管它们的执行时间比 PostgreSQL 快,但由于较长的计划时间导致了最糟的端到端时间。
而在 OLAP 负载中,因为包含了特别长时间运行的查询,基数估计方法的计划时间比执行时间短的多,这种情况下生成查询计划的质量掩盖了缓慢的推理时延。对于 OLTP 的工作负载,一个适合的方法应该有快速的推理速度,而 OLAP 可以忍受高推理时延,它只要能提供高质量的查询计划即可。图 3 显示了在工作负载中每种方法的平均推理时延。
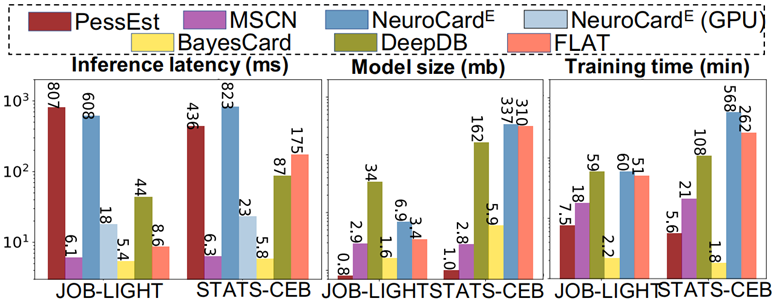
图 3 各方法在时延,模型大小,训练时间的对比
BayesCard 在两个基准测试上都有快速稳定的推理速度,但 FLAT 和 DeepDB 不够稳定,因为它们在更复杂的数据库会因为更多的计算回路形成更大的模型。NeuroCard 推理过程需要大量的渐进采样,因此在 GPU 上运行会比在 CPU 上运行有很大的提升。
二、模型部署方面
在图 3 中还有上述方法的模型尺寸和训练时间的比较。
O8:基于贝叶斯的基数估计方法是对系统开发友好的。首先基于贝叶斯的方法通常是可解释可预测的,因此在 DBMS 进行 debug 时很简单。更重要的是,一个对于系统开发友好的基数估计方法应该有较快的训练速度和轻量的模型大小,贝叶斯方法在这两项都有所胜出。
三、模型更新方面
模型更新是开发一个 OLTP 数据库的基数估计方法的一个重要的方面,这些数据库中频繁的数据更新要求这些基数估计方法能更新自己并准确的适应新数据。
O9:现有的查询驱动方法不适用于动态的 DB。这些方法面临冷启动问题,更重要的是它们在数据集或查询负载发生变化时需要重新收集并执行查询。
O10:数据驱动方法有潜力去处理快速的数据更新,可以用于动态 DB。其中 BayesCard 的效率最好并且其端到端性能不受大量更新的影响,因此适用于动态 DB,原因在于它保留了模型的结构只是更新了模型参数。而 DeepDB 和 FLAT 也保存了原有结构但因为它们模型过大,更新其参数需要大量时间。
而更新后的正确率是 BayesCard > DeepDB > FLAT > NeuroCard,原因在于 BayesCard 的底层模型计算的是数据的内在关系,当数据发生变化时也不会改变,而 DeepDB 和 FLAT 适应了更新前的数据但不能很好的泛化到新插入的数据,因此只更新参数会导致建模的不准确。

大多数现有方法使用 Q-Error 来评估模型的质量。然而,基数估计的最终目标是生成执行时间更快的查询计划,这也是本文主张使用 P-error 来代替 Q-error 的原因。
一、Q-error 的问题
Q-Error 是目前为止公认的衡量不同基数估计方法质量的指标。它测量估计基数与实际基数的相对误差,可计算为 Q-error = max{est(Q),true(Q)} / min{est(Q),true(Q)}。
具有较小 Q-Errors 的基数估计方法是否肯定会生成执行时间较短的查询计划?为了回答这个问题,本文重新审视实验结果。
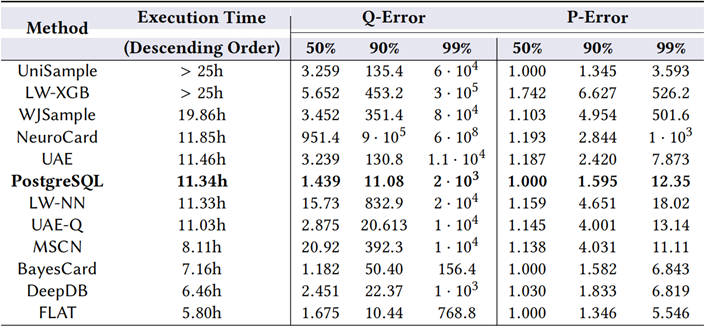
表 4 各方法的 Q-Error 与 P-Error 对比
表 4 报告了在 JOBLIGHT 和 STATS-CEB 上,由不同基数估计方法生成的所有子计划查询的 Q-Error 的分布(50%、90% 和 99% 百分位数)。
O11:Q-Error 指标不能作为查询执行性能的良好指标。这一观察源于表 4 中实验数据的支持。本文在 STATS-CEB 上列出了三个典型示例,如下所示:
-
NeuroCard 在所有方法中具有最差的 Q-Errors,但它的执行时间堪比PG,并比基于直方图及基于采样的方法好得多。
-
BayesCard 具有最好的 Q-Errors,但执行时间比 FLAT 慢 1.4 小时。
-
MSCN 的 Q-Errors 明显比 PG 差,但 MSCN 的执行时间大大优于它。
O12:Q-Error 不区分具有相同 Q-Error 值但具有不同大小的基数的查询。对于 Q-Error,真实基数为10与估计基数为1的Q-Error与真实基数为1012 与估计基数为 1011 的Q-Error是相同的。前一种情况可能几乎不会影响整个查询计划,而后一种情况可能是灾难性的,因为具有大基数的查询决定了查询计划的整体有效性。
O13:Q-Error 无法区分具有相同 Q-Error 值但对查询计划有不同影响的查询低估和高估。对于 Q-Error,对真实基数 1010 的低估值 109 与对 1011 的高估值相同。这两种估计很可能导致执行时间截然不同的不同计划。
二、P-error
显然,评估基数估计质量的最佳方法是直接在一些基准数据集和查询工作负载上记录其查询执行时间,本文因此提出了 P-Error 度量来实现这一目标。
给定一个查询 Q ,使用 CT 和 CE 表示 Q 的所有子计划查询的真实和估计基数的集合。当 CE 输入查询优化器时,它将生成一个对应的查询计划 P(CE)。
根据之前的工作,本文选择 PG 来计算这个估计成本,记为 PPC (PostgreSQL Plan Cost)。理想情况下,如果成本模型准确,则由真实基数 CT 找到的查询计划 P(CT) 应该是最优的,即:
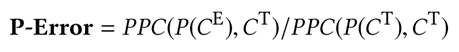
公式 1 P-Error 计算公式
因此,本文定义 P-Error 作为基数估计的指标。只要本文预先计算并存储所有子计划查询的真实基数,就可以借助插件 pg_hint_plan 即时计算现有查询工作负载的 P-Error。
在表 7 中,本文报告了所有基数估计方法的 STATS-CEB 工作负载的 P-Error 分布(50%、90%、99% 百分位数),并得出以下观察结果:
O14:P-Error 与查询执行时间的相关性高于 Q-Error。本文可以粗略观察到,具有更好运行时的方法往往具有更小的 P-Error。此外,P-Error 更方便,因为它在计划成本的层次上输出单个值,而 Q-Error 需要为查询 Q 的每个子计划查询输出一个值。

基于以上,本文总结了以下关键信息和未来的研究机会:
整体性能:学习型数据驱动的基数估计方法可以实现接近最佳的性能,而其他方法几乎没有比 PG 有任何改进。诚然,查询驱动的方法更通用,因为它们可以处理复杂的字符串“LIKE”查询。
不同查询的重要性:对大基数查询的准确估计比小查询重要得多。因此,研究人员应该开发基数估计方法,并专注于为大基数的查询生成准确的估计。
多表连接查询的估计:学习型的方法对于连接表数量增加的查询表现出性能下降。由于在所有表的 (样本) 全外连接上学习一个大型数据驱动模型具有较差的可扩展性,本文认为有效的基数估计方法应该做出适当的独立假设,并倡导研究人员遵循和改进 DeepDB 首次提出的扇出方法。
实用性方面:基数估计方法的推理延迟对端到端查询时间有重要影响。现有的学习型查询驱动方法对于具有频繁数据更新的动态数据库本质上是不切实际的。因此,设计具有快速推理速度和有效更新算法的基数估计方法也非常重要。
Q-Error:公认的 Q-Error 指标并不能反映基数估计方法的端到端查询性能。比如,新提出的 P-Error 度量与查询性能有更好的对应关系,可以作为未来研究的更好的优化目标。
*参考文献:
[1] Parimarjan Negi, Ryan Marcus, Andreas Kipf, Hongzi Mao, Nesime Tatbul, Tim Kraska, and Mohammad Alizadeh. 2021. Flow-Loss: Learning Cardinality Estimates That Matter. arXiv preprint arXiv:2101.04964 (2021).
[2] Parimarjan Negi, Ryan Marcus, Hongzi Mao, Nesime Tatbul, Tim Kraska, and Mohammad Alizadeh. 2020. Cost-guided cardinality estimation: Focus where it matters. In 2020 IEEE 36th International Conference on Data Engineering Workshops (ICDEW). IEEE, 154–157.
[3] Max Heimel, Martin Kiefer, and Volker Markl. 2015. Self-tuning, gpu-accelerated kernel density models for multidimensional selectivity estimation. In SIGMOD. 1477–1492.
[4] Martin Kiefer, Max Heimel, Sebastian Breß, and Volker Markl. 2017. Estimating join selectivities using bandwidth-optimized kernel density models. PVLDB 10, 13 (2017), 2085–2096.
[5] Viktor Leis, Bernhard Radke, Andrey Gubichev, Alfons Kemper, and Thomas Neumann. 2017. Cardinality Estimation Done Right: Index-Based Join Sampling. In CIDR.
[6] Postgresql Documentation 12. 2020. Chapter 70.1. Row Estimation Examples. https://www.postgresql.org/docs/current/row-estimation-examples.html (2020).
[7] Viswanath Poosala and Yannis E Ioannidis. 1997. Selectivity estimation without the attribute value independence assumption. In VLDB, Vol. 97. 486–495.
[8] Zhuoyue Zhao, Robert Christensen, Feifei Li, Xiao Hu, and Ke Yi. 2018. Random sampling over joins revisited. In SIGMOD. 1525–1539.
[9] Feifei Li, Bin Wu, Ke Yi, and Zhuoyue Zhao. 2016. Wander join: Online aggregation via random walks. In SIGMOD. 615–629.
[10] Walter Cai, Magdalena Balazinska, and Dan Suciu. 2019. Pessimistic cardinality estimation: Tighter upper bounds for intermediate join cardinalities. In SIGMOD. 18–35.
[11] Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter Boncz, and Alfons Kemper. 2019. Learned cardinalities: Estimating correlated joins with deep learning. In CIDR.
[12] Anshuman Dutt, Chi Wang, Azade Nazi, Srikanth Kandula, Vivek Narasayya, and Surajit Chaudhuri. 2019. Selectivity estimation for range predicates using lightweight models. PVLDB 12, 9 (2019), 1044–1057.
[13] Ziniu Wu, Peilun Yang, Pei Yu, Rong Zhu, Yuxing Han, Yaliang Li, Defu Lian, Kai Zeng, and Jingren Zhou. 2021. A Unifed Transferable Model for ML-Enhanced DBMS. arXiv preprint arXiv:2105.02418 (2021).
[14] Zongheng Yang, Amog Kamsetty, Sifei Luan, Eric Liang, Yan Duan, Xi Chen, and Ion Stoica. 2021. NeuroCard: One Cardinality Estimator for All Tables. PVLDB 14, 1 (2021), 61–73.
[15] Ziniu Wu and Amir Shaikhha. 2020. BayesCard: A Unifed Bayesian Framework for Cardinality Estimation. arXiv preprint arXiv:2012.14743 (2020).
[16] Benjamin Hilprecht, Andreas Schmidt, Moritz Kulessa, Alejandro Molina, Kristian Kersting, and Carsten Binnig. 2019. DeepDB: learn from data, not from queries!. In PVLDB.
[17] Rong Zhu, Ziniu Wu, Yuxing Han, Kai Zeng, Andreas Pfadler, Zhengping Qian, Jingren Zhou, and Bin Cui. 2021. FLAT: Fast, Lightweight and Accurate Method for Cardinality Estimation. VLDB 14, 9 (2021), 1489–1502.