目录
- 什么是Hadoop?
- 一、Hadoop依赖环境配置
- 1.1 设置静态IP地址
- 1.2 重启网络
- 1.3 再克隆两台服务器
- 1.4 修改主机名
- 1.5 安装JDK
- 1.6 配置环境变量
- 1.7 关闭防火墙
- 1.8 服务器之间互传资料
- 1.9 做一个host印射
- 1.10 免密传输
- 二、Hadoop安装部署
- 2.1 解压hadoop的tar包
- 2.2 切换到配置文件目录
- 2.3 修改配置文件
- 2.4 分发到其他节点
- 2.5 初始化Hadoop集群
- 2.6 强制使用root启动hadoop集群
- 2.7 启动集群
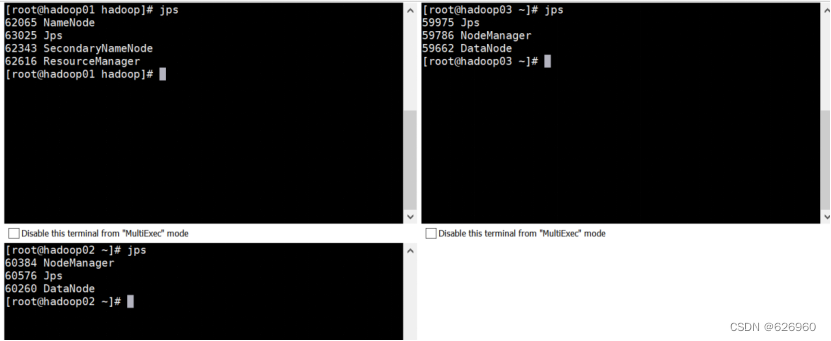
- 2.8 输入命令jps,完成Hadoop的搭建
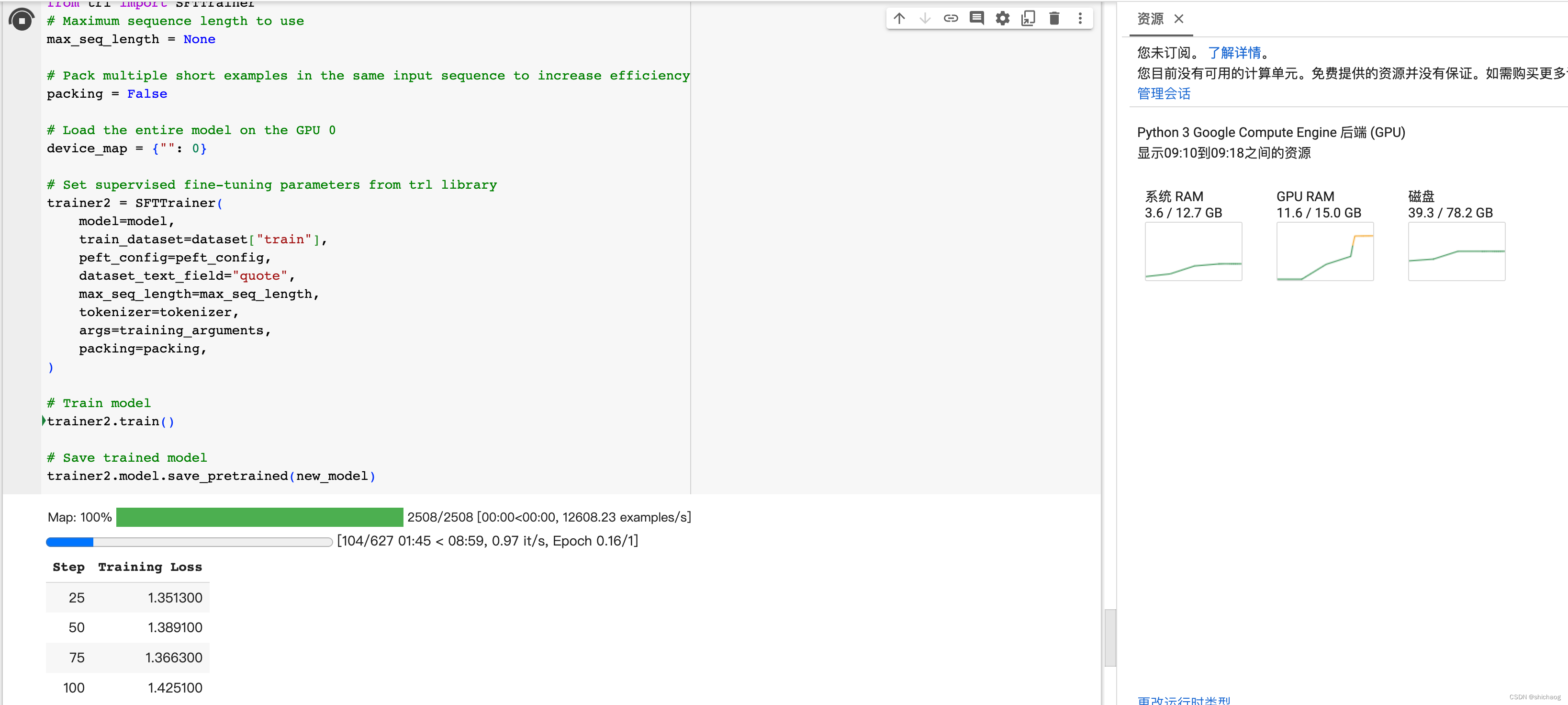
什么是Hadoop?
Hadoop是一个分布式系统基础架构, 是一个存储系统+计算框架的软件框架。主要解决海量数据存储与计算的问题,是大数据技术中的基石。Hadoop以一种可靠、高效、可伸缩的方式进行数据处理,用户可以在不了解分布式底层细节的情况下,开发分布式程序,用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。
一、Hadoop依赖环境配置
1.1 设置静态IP地址
之所以设置静态IP是因为当我们连上不同的网络时,ip总是会发生变化,因为dhcp服务会为我们分配一个空闲的ip地址,所以静态ip解决的问题就是为了把ip地址固定下来。
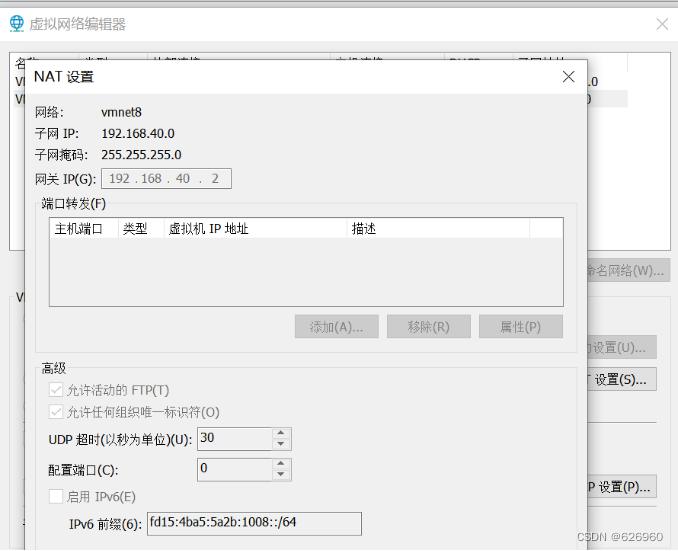
- 首先查看网关,打开VMware,编辑>>虚拟网络编辑器。
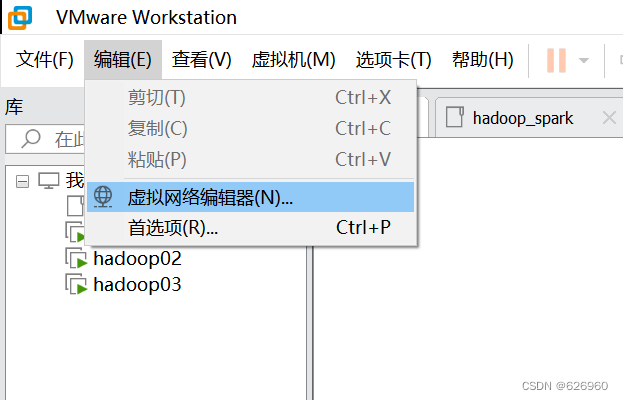
- 打开NAT设置。
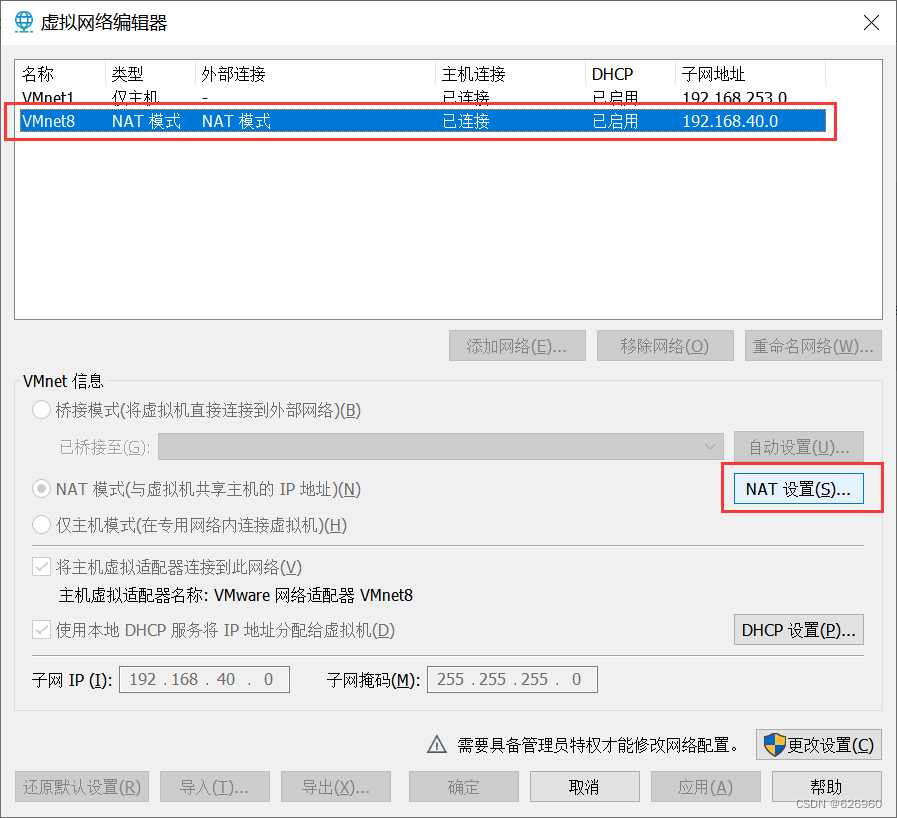
- 截图保存该页面,方便后面设置。
- 修改IP的配置文件
cd /etc/sysconfig/network-scripts/ //进入到如下目录
vim ifcfg-ens33 //编辑该文件
进入以后修改为如下内容:
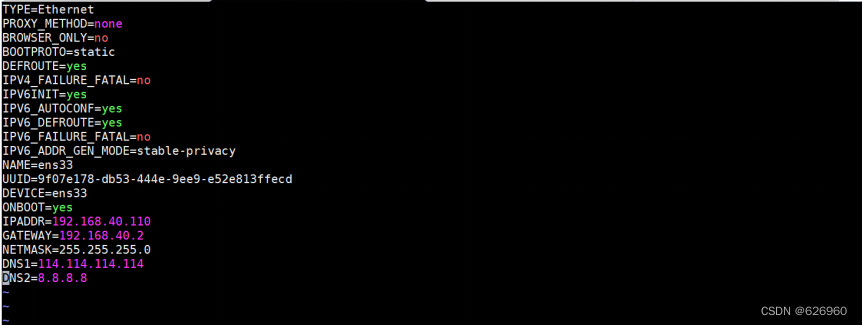
修改内容如下:
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.xx.110 //xx查看自己之前的截图内容
GATEWAY=192.168.xx.2
NETMASK=255.255.255.0
DNS1=114.114.114.114
DNS2=8.8.8.8
1.2 重启网络
重启网络的命令:service network restart
1.3 再克隆两台服务器
-
步骤如下图
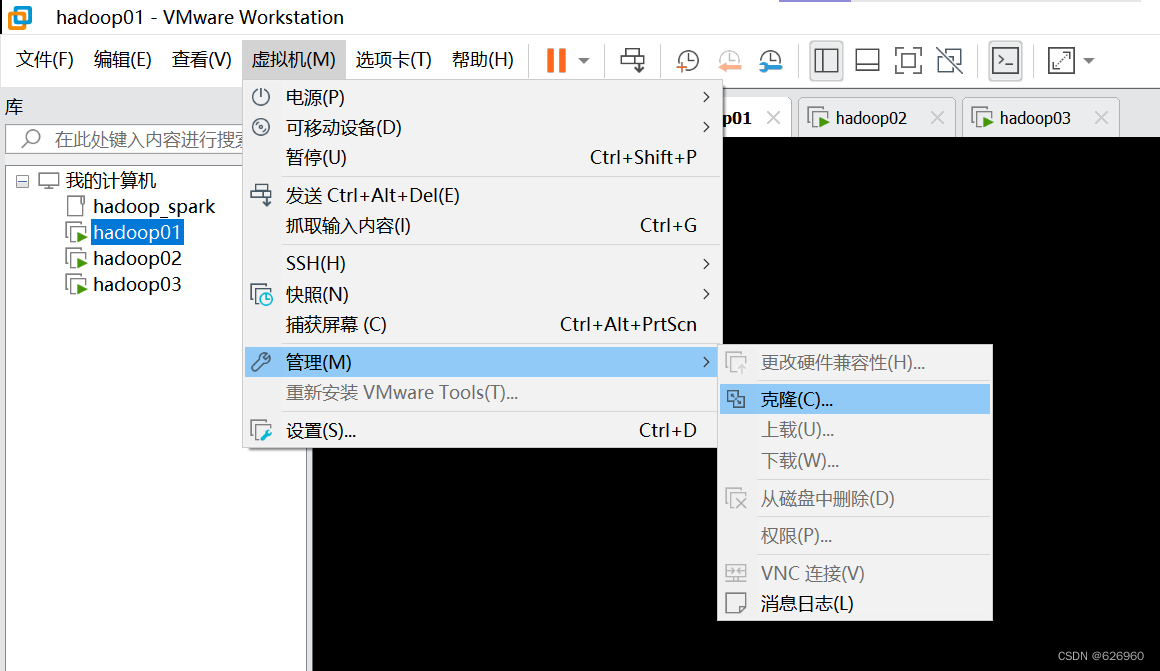
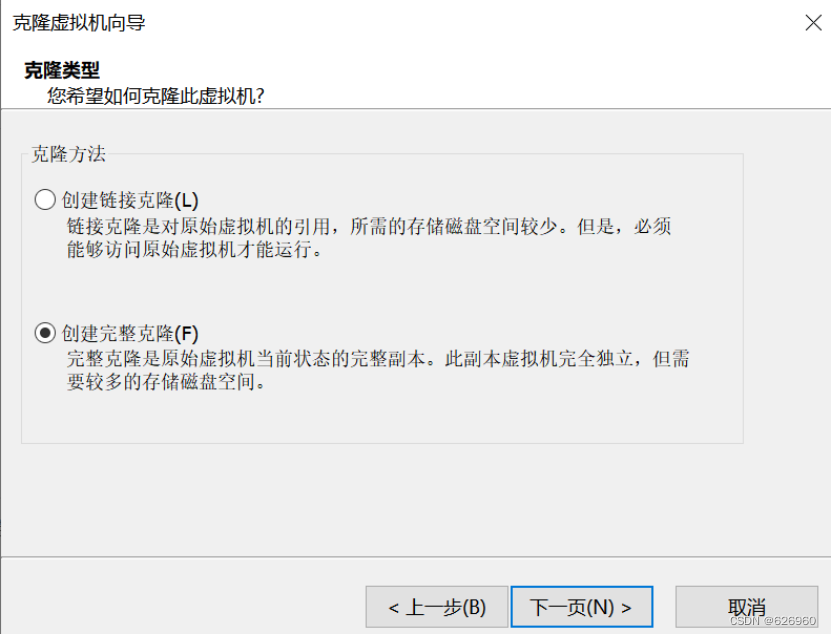
-
再克隆一台
1.4 修改主机名
克隆完虚拟机后,在MobaXterm中分布修改三台虚拟机的名称。分别输入如下命令:
hostnamectl set-hostname 'hadoop01'
hostnamectl set-hostname 'hadoop02'
hostnamectl set-hostname 'hadoop03'
1.5 安装JDK
输入命令:rpm tar.gz rpm -ivh XXX.rpm
1.6 配置环境变量
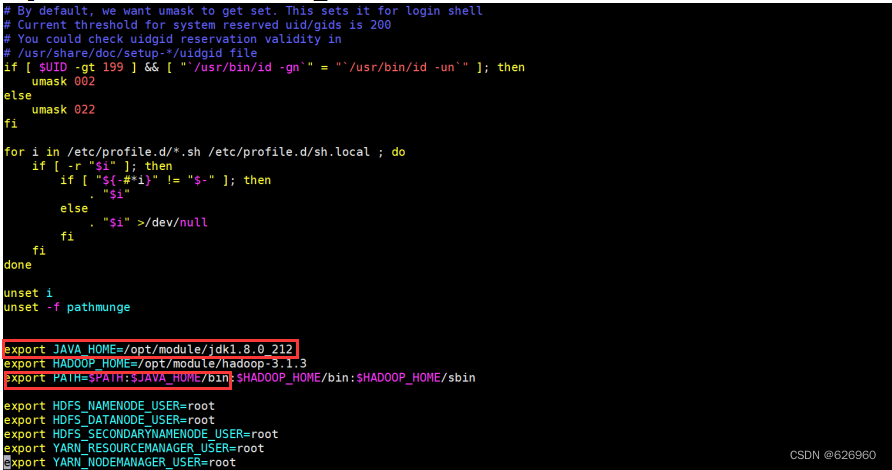
输入命令:vim /etc/profile,进入以后添加如下内容:
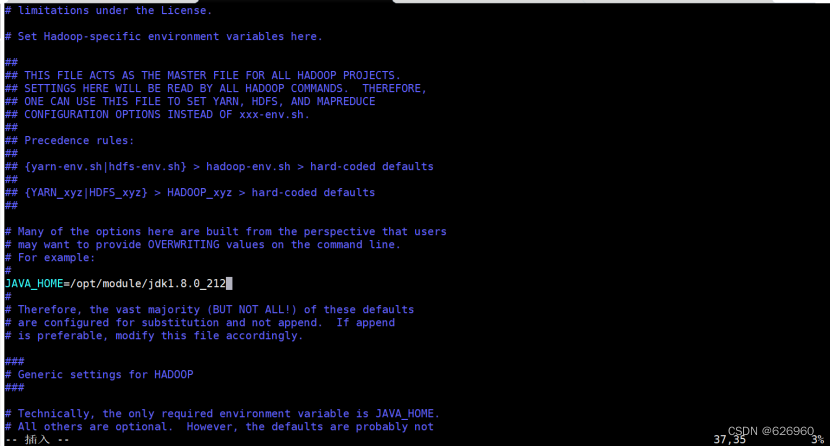
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
1.7 关闭防火墙
首先临时关闭防火墙,输入命令:systemctl stop firewalld
然后永久关闭防火墙( 只能先临时关闭,才能永久关闭),输入命令:systemctl disable firewalld

可以查看防火墙是否关闭:systemctl status firewalld
1.8 服务器之间互传资料
scp -r /opt/module/xxx 192.168.70.120:/opt/module
scp -r /opt/module/xxx hadoop03:/opt/module
1.9 做一个host印射
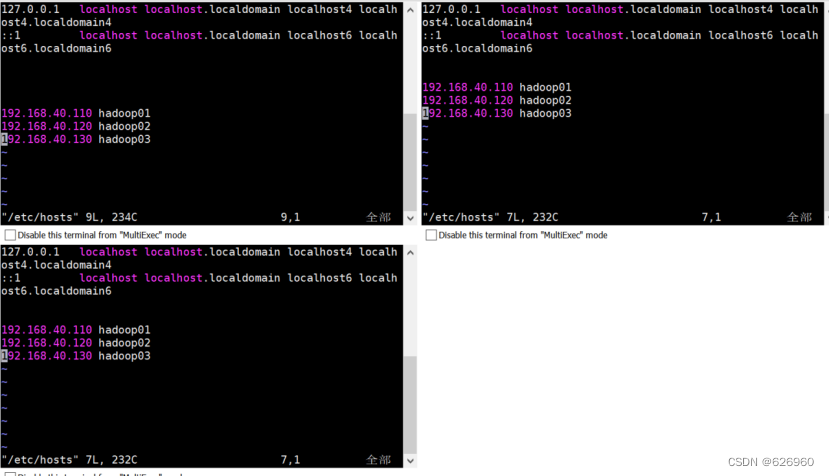
输入命令进入hosts映射文件:vim /etc/hosts
修改内容如下(三台虚拟机一样):
1.10 免密传输
生成各自的私钥与公钥:ssh-keygen
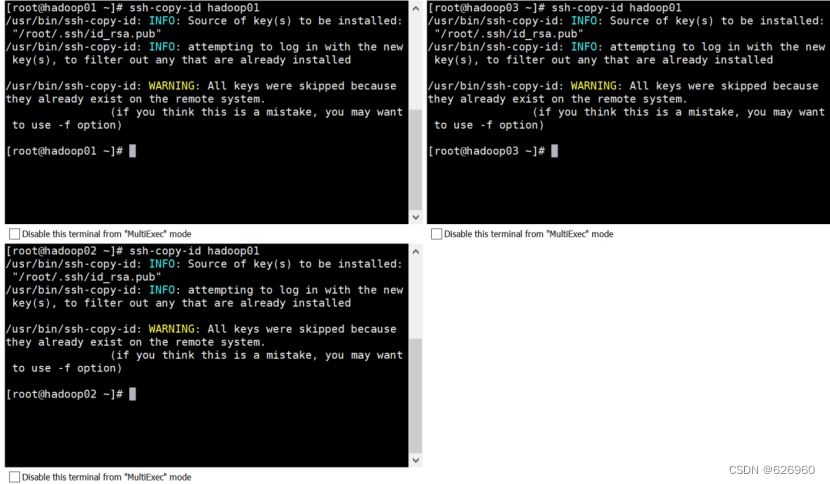
把生成的公钥给别人:ssh-copy-id hadoop01ssh-copy-id hadoop02ssh-copy-id hadoop03
三台虚拟机同时输入:
二、Hadoop安装部署
2.1 解压hadoop的tar包
输入如下命令:tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
2.2 切换到配置文件目录
输入如下命令:cd /opt/module/hadoop-3.1.3/etc/hadoop
2.3 修改配置文件
-
第一个配置文件,修改hadoop-env.sh,修改hadoop的环境依赖JDK:
vim hadoop-env.sh,添加jdk的环境变量。
修改内容如下:
-
第二个配置文件,输入命令:
vim core-site.xml,在<configuration></configuration>中添加如下内容:
<!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop01:9000</value>
</property>
<!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value>
</property><!-- 配置HDFS网页登录使用的静态用户为root --><property><name>hadoop.http.staticuser.user</name><value>root</value>
</property><!-- 配置该root(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
- 第三个配置文件,输入命令:
vim hdfs-site.xml,在<configuration></configuration>中添加如下内容:
<!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop01:50070</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop01:50090</value>
</property>
<!--副本数的配置--><property><name>dfs.replication</name><value>2</value>
</property>
- 第四个配置文件,输入命令:
vim yarn-site.xml,在<configuration></configuration>中添加如下内容:
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value>
</property>
<!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value>
</property>
<!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
- 第五个配置文件,输入命令:
vim mapred-site.xml,在<configuration></configuration>中添加如下内容:
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
- 第六个配置文件,输入命令:
vim workers,添加如下内容:

2.4 分发到其他节点
scp -r /opt/module/hadoop-3.1.3 hadoop02:/opt/module/
scp -r /opt/module/hadoop-3.1.3 hadoop03:/opt/module/
2.5 初始化Hadoop集群
hadoop namenode -format
2.6 强制使用root启动hadoop集群
vim /etc/profile
2.7 启动集群
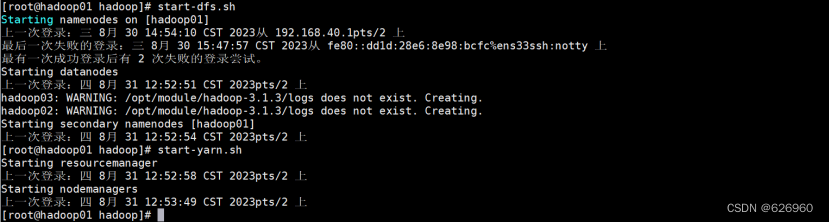
start-dfs.sh
start-yarn.sh
2.8 输入命令jps,完成Hadoop的搭建