个人网站:https://tianfeng.space
一、前言
OpenAI的CLIP项目自从推出以来,CLIP引起了广泛的关注。它的方法看似简单,但效果非常出色,许多结果令人惊叹。例如,预训练模型可以在任何视觉分类数据集上实现出色的效果,而且最重要的是,它具有零样本学习的能力,这意味着它无需在这些数据集上进行额外的训练,就能够表现出色。
作者进行了大量实验,涵盖了30多个数据集,包括OCR、视频动作检测、坐标定位和许多细粒度分类任务。其中最引人注目的结果之一是在ImageNet上的,CLIP在没有使用ImageNet的128万张训练图像的情况下,通过零样本学习,达到了与监督的ResNet-50模型相媲美的性能,这在该工作之前被认为是不可能的。
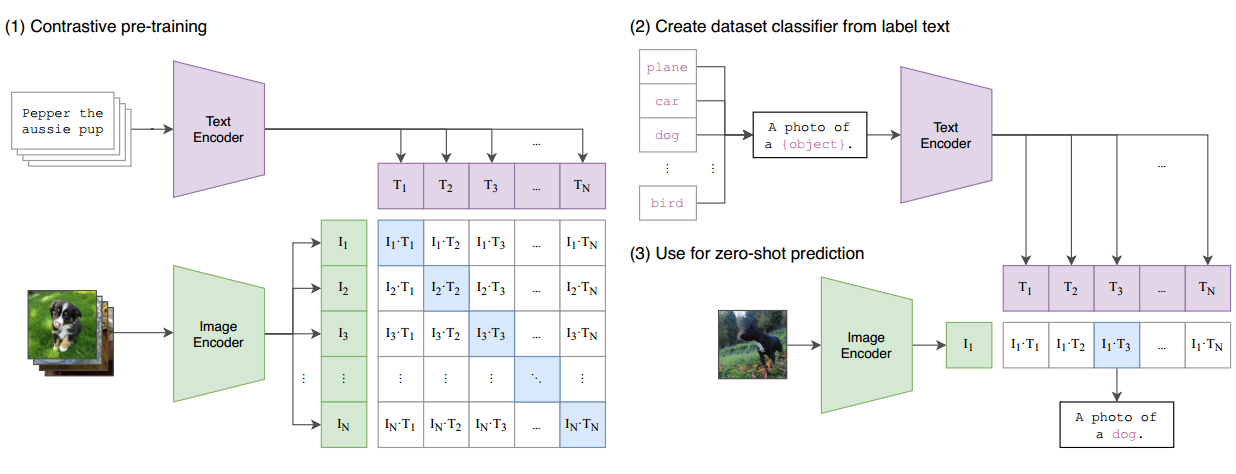
现在,让我们简要讨论一下CLIP的工作原理以及如何实现零样本推理。CLIP的模型概览如论文的第1图所示。在预训练阶段,该模型以图像和文本配对作为输入。例如,一张狗的图像与文本"Pepper是一只小狗"配对。图像通过图像编码器(例如ResNet或Vision Transformer)进行处理以获得特征,而文本通过文本编码器进行处理以获得文本特征。
假设每个训练批次包含n个图像文本对,我们将获得n个图像特征和n个文本特征。然后,CLIP对这些特征执行对比学习。特征矩阵中的对角线元素是正样本(例如,I1 T1,I2 T2),而非对角线元素是负样本。通过n个正样本和n^2 - n个负样本,模型可以进行对比学习,无需手动注释。
然而,像对比学习这样的无监督预训练方法需要大量的数据。OpenAI收集了包含4亿个高质量注释的图像文本对的数据集,这是CLIP成功的主要原因之一。
为了进行零样本推理,CLIP使用了巧妙的自然语言方法,称为"提示模板prompt template"。以ImageNet为例,1,000个类别被转化为1,000个句子(例如,“这是一张飞机的图片”)。然后,在推理过程中,模型计算输入图像的特征与1,000个文本特征之间的相似性,并将具有最高相似性的类别分配为预测标签。这样,CLIP可以在不需要额外的训练或特定分类任务微调的情况下执行零样本推理。这是CLIP如何工作以及如何实现其卓越的零样本能力的简要概述。 CLIP之所以如此强大,是因为它不受分类标签的限制,可以识别新的物体,并且具有出色的迁移效果。
主要参考资料:
- 论文 https://arxiv.org/abs/2212.07143
- 视频 https://www.bilibili.com/video/BV1SL4y1s7LQ/?spm_id_from=333.999.0.0&vd_source=69a72fa3fe0bf11ff1588ccaeb91737a
- 其他等等
词汇解释:
One-shot learning(一样本学习):在这种情况下,模型只能使用一个示例来学习每个类别,以进行分类。
Few-shot learning with N examples(N样本学习):模型可以使用每个类别的N个示例,其中N通常是一个小的整数,来学习分类任务。
Zero-shot learning(零样本学习):虽然零样本学习通常被视为一种独立的概念,但它也可以看作是一种极端的少样本学习,其中每个类别都没有任何训练示例。
Pretrained Model:首先,针对特定任务(例如,语言理解或图像分类),在大型数据集上对 BERT 或 CNN 等神经网络模型进行预训练。在预训练过程中,模型学习从输入数据中捕获有用的特征或表示。
Feature Extraction:训练预训练模型后,您可以删除最终的分类层(例如,语言模型中的 softmax 层)并使用早期层的输出作为特征嵌入。这些嵌入通常是输入数据的低维表示。
Linear Probe:是一种用于评估预训练模型学到的特征质量和泛化性能的技术,而不是在特定任务上进行微调。在Linear probe中,预训练的模型的骨干网络(通常是一个全连接层之前的部分)被冻结,不再更新。然后,一个浅层的分类头被添加,通常是一个线性分类器。这个头被用于在新的任务上进行分类。Linear probe的目标是检查预训练模型的特征表示是否具有足够的质量来进行有效的分类。Linear probe通常用于模型评估和特征分析,而不是部署在实际任务中。例如,通过在ImageNet上预训练的模型,在不同的图像分类任务上添加线性分类头,以评估模型的泛化性能。
Fine-Tuning:是一种将预训练模型适应特定任务的技术。它的主要目标是在新的任务上提高模型的性能。在Fine-tuning中,预训练的模型(例如,CLIP)通过在任务特定的数据集上进行进一步的训练来适应新的任务。这通常涉及到在任务特定数据上调整模型的权重,以最小化任务特定的损失函数。常用于迁移学习,以便将一个在大规模数据上预训练的模型转移到小规模任务上,例如图像分类、目标检测、文本生成等。
二、总结
样例
论文:https://arxiv.org/abs/2103.17249
代码:https://github.com/orpatashnik/StyleCLIP

这里,我们暂时不讨论分类,而是探讨一些有趣的基于CLIP的应用。首先,一个非常有趣的工作是"Style CLIP"。从名称就可以看出,这是一个结合了CLIP和Style GAN的项目。这项工作旨在通过文本描述的方式来引导图像生成,例如,在下面的演示视频中,通过改变不同的文本输入,可以调整右侧生成的图像的各种属性。

接下来,让我们看一些示例,以更好地理解这个概念。例如,原始图像可能是奥巴马的照片,然后通过添加文本指示,可以改变他的发型。还有一个例子,原始图像是Taylor Swift的照片,然后通过文本指示去掉化妆,就可以实现一键卸妆。还有一个例子是一只猫的图像,原始图像中猫的眼睛是闭合的,但通过写入"cute cat"这样的文本,猫的眼睛变得更大,使它看起来更可爱。这项工作的效果非常出色,因此被收录在ICCV 21的口头报告论文中。
colab代码:https://colab.research.google.com/github/kvfrans/clipdraw/blob/main/clipdraw.ipynb#scrollTo=5dyyH781qzIC
论文:https://arxiv.org/pdf/2106.14843.pdf

另外还有一篇名为"CLIP Draw"的论文,也是利用预训练的CLIP模型来指导图像生成。这项工作的思路非常简单,甚至不需要进行模型训练,只需进行几步梯度下降,就可以生成简笔画风格的图像。根据论文中的描述,这种生成过程通常在普通的GPU上不到一分钟就能完成。下面展示了一些生成的有趣图像,例如一匹马正在吃杯子蛋糕的动画、一个3D寺庙的简笔画、一家人在迪士尼乐园玩耍的图像以及一个自拍照,其中相机拍摄了多张脸部照片并呈现出一种抽象主义的风格。

当然,除了图像生成任务,CLIP还可以用于执行更多任务,如物体检测和分割。不久之后,CLIP发布后,Google就发表了一篇利用CLIP进行物体检测的工作。这篇工作的具体细节我不会详细讨论,但我们可以看一下其效果如何。论文中指出,如果使用传统的目标检测方法,可能只能识别这些物体属于基本类别,例如他们所说的“玩具”,即蓝色基本类别。但是,通过结合自然语言,您可以摆脱这种基本类别的限制,实现更自由的目标检测,也就是所谓的“开放词汇检测器”。因此,他们训练的模型可以检测出新的类别,如红色的物体,同时还能理解这些物体的具体类别,例如检测出这是一个玩具大象、玩具鳄鱼或玩具鸭子等。这种方法可以大大丰富输出信息。
文章架构
CLIP论文总共有48页,包括正文和附录。为了简洁起见,我将讨论主要部分。下面是论文的结构和要点:
\1. 摘要:介绍了CLIP的核心思想,即利用自然语言监督信号来学习高效的视觉特征,使模型能够在各种数据集和任务上进行迁移学习。
\2. 引言:提出了传统视觉系统的问题,这些系统通常需要事先定义的固定物体类别集合。作者讨论了利用自然语言监督信号来解决这一问题的潜力,并提出了CLIP的目标。
\3. 方法:介绍了CLIP的训练方法,包括爬取了一个包含4亿个图像文本配对的数据集,然后使用多模态对比学习进行自监督预训练。这个预训练模型的任务是判断给定图像和文本描述是否匹配。
\4. 实验:这一部分详细探讨了CLIP的实验结果,包括如何进行零样本推理以及Prompt Engineering Prompt Ensemble等方法。作者还说明了CLIP在多个视觉任务和数据集上的性能。
\5. 局限性:讨论了CLIP的一些局限性,包括模型偏见和监控视频中的应用。
\6. 影响:作者讨论了CLIP可能带来的重大影响,包括解决模型偏见问题以及在各种领域的应用。
\7. 未来工作:作者展望了CLIP的未来研究方向。
\8. 相关工作:简要概述了与CLIP相关的先前工作。
\9. 结论:总结了论文的主要发现和贡献。
在摘要中,作者强调了CLIP模型的迁移学习效果,特别是在不使用任何监督数据集的情况下,CLIP可以与以传统有监督方式训练的模型相媲美,这一点在ImageNet上的实验结果尤为引人注目。作者提供了CLIP预训练模型的链接,尽管代码不是完全开源,但模型可供使用。
总之,CLIP的核心贡献在于利用自然语言监督信号进行训练,使模型能够在多种任务和数据集上进行零样本推理,这一思想引发了许多后续研究。
三、详解
摘要

这段文字讨论了CLIP论文的主要思想和贡献:
- 传统的视觉系统通常需要一个预定义的固定物体类别集合来进行训练,如ImageNet的1,000个类别、CIFAR-10的10个类别等。这种方法的好处是简化了训练,但限制了泛化性,尤其是对于识别新物体类别。
- CLIP采用了一种创新方法,利用自然语言监督信号来训练模型。作者构建了一个包含4亿个图像文本配对的大型数据集,并使用多模态对比学习进行自监督预训练。模型的任务是判断给定图像和文本描述是否匹配。
- 预训练后,CLIP可以用于零样本分类,即模型能够在不需要特定监督数据集的情况下执行分类任务。这扩展了模型的应用领域,并提供了强大的泛化能力。
- 作者进行了30多个不同的视觉任务和数据集上的测试,发现CLIP的迁移学习效果非常好。在许多任务上,CLIP甚至能够与完全使用有监督方法训练的模型媲美,有时甚至更好。
- CLIP的出色性能吸引了大量关注,作者提供了预训练模型的链接,虽然源代码没有完全开源,但模型可供使用,这激发了一系列相关工作。
总之,CLIP通过自然语言监督信号的创新使用,实现了出色的迁移学习性能,使模型能够在多样的任务和数据集上进行零样本推理。这一成就在当时引起了广泛的关注和研究。
引言

- 在NLP领域,使用自监督的预训练方法(如BERT、GPT、T5等)已经取得了巨大的成功。这些方法的目标函数与下游任务无关,主要是为了学习泛化能力强的特征表示。
- 随着计算资源的增加、模型规模的扩大以及可用数据的增多,这些方法的性能不断提升。
- 这些NLP模型的架构与下游任务无关,因此在应用于不同的任务时,无需特定任务的输出头或数据集特定的处理。
- 其中,GPT-3是一个著名的模型,可以进行分类、翻译,甚至可以生成文本,具有广泛的应用领域,而且在大多数任务上只需要微调而不需要领域特定的数据。
- 文中认为,这些令人鼓舞的结果表明,利用自监督信号进行大规模无标注数据的训练,在某些情况下可能比手工标注的高质量数据集更有效。
- 然而,作者提出一个问题,即在视觉领域,通常的做法是在像ImageNet这样的数据集上进行训练,这可能会导致模型的一些限制。作者认为,根据以往的研究,将NLP中的自监督框架应用到视觉领域是可行的。
CLIP,即"Contrastive Language-Image Pre-training",可以被视为ConVIRT(Contrastive Vision-Text Pre-training)的简化版本,但其效果卓越。在模型方面,作者在视觉领域尝试了8个不同的模型,从ResNet到Vision Transformer,这些模型的计算量相差悬殊,最小和最大模型之间的计算量差异达到了约100倍(也就是所谓的"two orders of magnitude")。作者最终得出结论,模型大小与迁移学习效果之间存在明显的正相关关系。这意味着较大的模型通常具有更好的迁移学习效果,这种关系呈现出平滑的趋势。因此,根据模型的大小,可以估计其在实际应用中的迁移学习效果。
在引言部分的最后,作者强调了CLIP论文的多样性和出色的效果。作者列举了一些关键点:
首先,由于CLIP模型旨在进行迁移学习并优化泛化性能,因此可以通过在多个任务上进行迁移来展示其实用性。作者在30个不同的数据集上测试了CLIP,并发现它通常能够与之前精心设计的监督训练模型媲美甚至胜过它们的性能。
为了进一步验证CLIP模型学到的特征的有效性,作者采用了线性探测器(linear probe)的方法,而不是立即进行零样本学习。这种方法包括冻结预训练模型的参数,然后在其基础上训练最后一层分类头以执行分类任务。结果显示,CLIP的性能不仅在分类任务上优于以ImageNet为基础的模型,而且在计算上更加高效。
最后,作者发现CLIP的零样本性能非常稳健。当CLIP的性能与监督训练的ImageNet模型相当时,其泛化性能要好得多。这表明CLIP在处理素描图像或对抗性样本时表现出色,而监督训练的模型则表现不佳。
方法

\1. 使用自然语言监督信号训练视觉模型的方法: 作者提到了一种方法,其核心思想是利用自然语言作为监督信号,以培训高质量的视觉模型。这种方法的目标是将文本与图像相关联,以改善多模态学习。
\2. 方法不是全新的但有改进: 作者指出,尽管这种方法并不是全新的,但之前的方法存在一些混淆和相似的思想。作者试图总结并扩展这些方法,以使其规模更大,并展示其效果。
\3. 不同监督信号的方法: 这四种工作将监督信号描述为无监督、自监督、弱监督和有监督,尽管它们的目标都是使用文本作为训练信号,但它们在监督程度和方法上存在差异。
\4. 自然语言监督信号的优势: 作者提到了使用自然语言监督信号的两个优点。首先,无需手动标记大量数据,只需在线下载图像和文本对即可。这简化了数据集准备流程并增加了数据规模。其次,将图像和文本绑定在一起,使得学到的特征成为多模态特征,这有助于进行零样本学习和迁移学习。
\5. 数据集规模的挑战: 作者提到要实施这种文本与图像的训练,需要足够大规模的数据集,其中包含许多图像文本对。作者列举了一些常见的数据集,但指出它们的标注质量或数据规模不足以满足现代标准。
\6. 数据集的问题: 在提到YFCC 100Million数据集时,作者指出该数据集的标注质量较差,其中许多图像文本对不匹配。即使经过清理,数据集的规模也显著减小,导致训练模型的数据量有限。

因此,作者决定亲手创建一个大型数据集。这个决定实际上带来了双重价值,不仅催生了像CLIP这样的工作,还催生了OpenAI的另一项工作,即DALL·E,用于图像生成。最终,OpenAI创建了一个包含4亿个图像文本对的数据集,这意味着比之前最大的图像数据集,即Google的JFT 300Million数据集,多了一个亿的训练样本。从NLP的角度来看,根据单词数量来衡量,这个新收集的数据集与用于训练GPT-2的WebText数据集相当接近,因此应该足够大且足够充分。
他们将这个最终的数据集称为"WIT",即Web Image Text数据集。有了如此庞大的数据集,作者在第2.3节详细介绍了预训练方法以及如何选择这些方法。作者指出,当前视觉模型通常非常庞大且昂贵进行训练。例如,之前的工作在Instagram数据集上进行预训练,使用了ResNet 101网络,需要19年的GPU时间。另一项工作,即"Noisy Student",也在ImageNet数据集上取得了卓越成绩,但需要33年的TPUv3时间。这表明即使是OpenAI这样一个计算资源丰富的公司,也认为训练这些系统非常耗费资源。

作者补充指出,这些系统都是用来预测1,000个类别,已经消耗了如此多的资源。而现在,数据集更大,任务更加复杂,他们需要从自然语言处理领域中直接学习开放世界中的视觉概念。即使对于OpenAI这样的公司,他们也认为训练这个系统令人望而却步。因此,作者通过一系列努力,发现了训练效率对于多模态预训练的成功至关重要。
作者介绍了他们的尝试,首先尝试了一种与VirTex工作非常相似的方法。该方法涉及使用卷积神经网络处理图像和使用Transformer处理文本,然后从头开始进行训练。任务是给定一张图片,预测与之对应的文本,即图片的描述。这是一项预测型任务,但它相对容易理解,因为OpenAI一直是以GPT为基础的公司,从GPT、GPT-2、GPT-3,到最近的DALL·E、Image GPT和OpenAI Codex,所有这些著名的大型项目都是基于GPT进行的。但是,由于训练效率的原因,CLIP选择了对比学习方法。
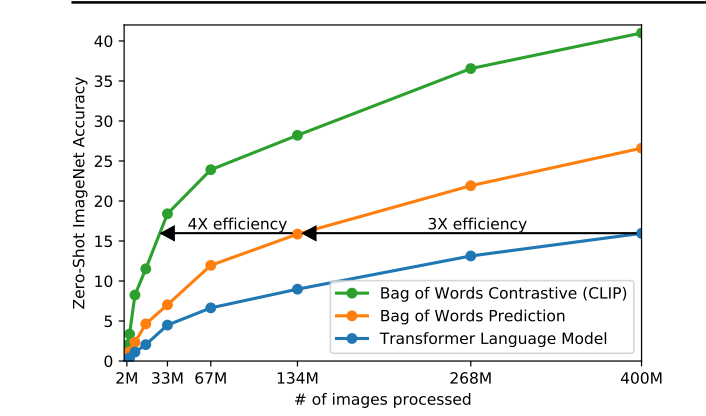
接下来,作者解释了为什么选择对比学习。他指出,如果任务是给定一张图片,然后逐字逐句地预测文本,那么这个任务将非常困难,因为对于一张图片,可以有无数不同的描述。不同的人可能会为同一张图片提供不同的字幕。这导致了任务的巨大多样性。因此,将训练任务转化为对比任务的方法变得更加合理,因为此时只需判断图像和文本是否匹配,而不再需要逐字逐句地预测文本。这种方法简化了任务,减少了多样性,使监督信号更加合理。作者展示了这种方法的好处,发现将预测型目标函数替换为对比型目标函数后,训练效率提高了4倍。最终,基于对比学习的方法被证明是非常高效的。
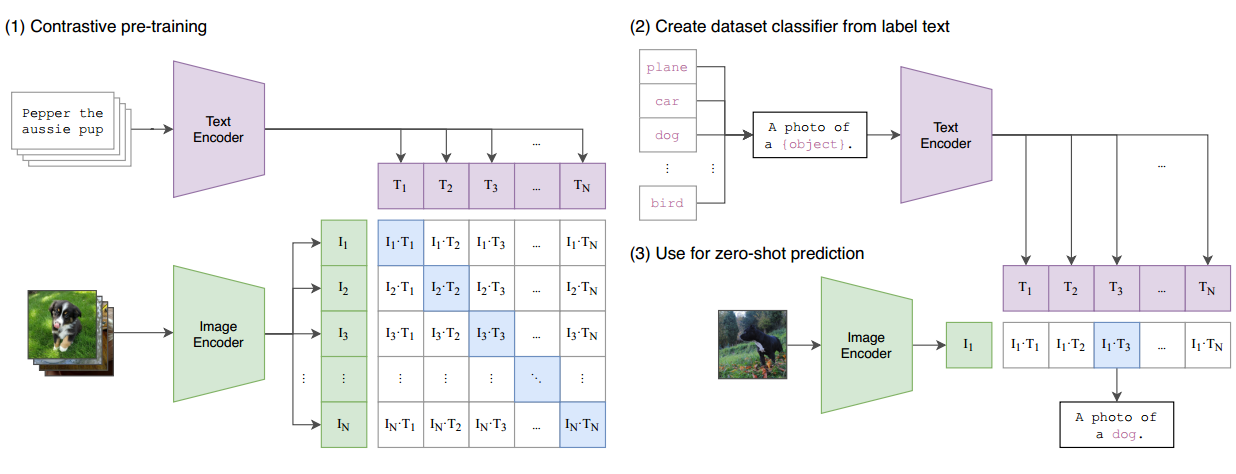
接下来,作者详细介绍了CLIP所使用的方法。在前言中,我们已经大致讲解了图1中CLIP模型的总体概述。在这里,让我们直接查看伪代码,以更直观地了解CLIP方法。

首先,有两个输入,一个是图像输入,一个是文本输入。图像输入的维度是n(批次大小),以及hwc(高度、宽度、通道数),例如224x224x3。文本输入t也具有批次大小n和序列长度l。一旦有了这两个输入,您将需要通过编码器来获得相应的特征。这里的编码器可以是ResNet或Vision Transformer,视具体情况而定。对于文本,编码器可以是CBOW(Continuous Bag-Of-Words)或文本Transformer。在获得图像特征和文本特征之后,通常会进行一次正规化操作,这涉及到一个投射层。投射层的目的主要是学习如何从单模态特征转变为多模态特征。作者指出,这是多模态特征的融合。一旦完成投射,再次进行L2正规化,您将获得最终用于比较的特征,分别是I_e(图像特征)和T_e(文本特征)。
一旦您有了这两个特征,也就是说,您有了n个图像特征和n个文本特征,接下来要做的是计算它们之间的余弦相似度。这个计算得到的相似度实际上就是用于分类的logits。一旦您有了要预测的logits,当然接下来您需要一个ground truth。然后,您的logits将与ground truth进行交叉熵损失的计算,从而获得最终的损失。这里我们可以看到,它使用arrange函数来创建ground truth,该函数的输出是从1开始的序列1,2,3,…,n。这与我们之前讨论的MOCO方法创建ground truth的方式不同,因为对于MOCO,正样本始终在第一位,因此在MOCO的实现中,ground truth始终是0。
接下来是非常标准的步骤,计算两个损失,一个是图像损失,一个是文本损失,这是对称的损失,最后将两个损失相加并求平均值。在对比学习中,这种操作非常常见,从SimCLR、BYOL一直到最新的MOCO v3和DINO等工作,都使用了这种对称的目标函数。因此,当我们查看了这份伪代码后,会发现CLIP实际上非常简单,与以前的对比学习方法没有太大区别。它的关键之处在于将单模态的正样本替换为多模态的正样本。
接下来,作者提到了一些有趣的细节。由于他们收集的数据集非常庞大,所以模型的训练不太容易出现过拟合问题。因此,他们的实现相对于之前的工作来说要简单得多。例如,在训练CLIP模型时,文本编码器和图像编码器都不需要预先进行预训练。
另一个有趣的点是,在他们最后进行投射时,他们没有使用非线性的投射层,而是使用了线性的投射层。在之前的对比学习工作中,特别是SimCLR和MOCO等一系列论文中,我们曾经讨论过使用非线性的投射层可以带来近10个百分点的性能提升,这是非常显著的。但是作者在这里表示,在他们的多模态预训练过程中,他们发现线性和非线性投射层没有太大的差异。他们怀疑非线性投射层可能只是用来适应纯图片的单模态学习,而且由于OpenAI的数据集非常大,所以他们不需要进行太多的数据增强。作者提到,他们唯一使用的数据增强是随机裁剪,其他所有复杂的数据增强方法都没有使用。
最后,由于模型非常庞大,数据集也非常大,训练非常耗时,所以调参工作相对较难。在计算对比学习的目标函数时,温度(temperature)这个超参数在之前的对比学习工作中被认为是非常重要的参数,微调一下温度会显著影响最终性能。但作者在这里表示,他们不太想调整这个参数,因此将其设置为一个可学习的标量,这个参数会在模型训练过程中进行优化,而不需要将其作为超参数最后再进行调整。

在文章的2.4节中,作者详细介绍了模型的选择。对于视觉部分,他们选择了ResNet和Vision Transformer,而对于文本部分,他们使用了Transformer。这些模型的选择非常标准,只进行了一些小的改动,这些改动旨在提高训练的效率,而不会影响整个文章的主要故事线。因此,这里直接跳过了详细介绍。

接下来,在文章的2.5节,作者解释了如何训练这些模型。作者表示,在视觉部分,他们总共训练了8个模型,其中包括5个ResNet和3个Vision Transformer。在这5个ResNet中,有ResNet-50和ResNet-101以及三个根据EfficientNet方式调整了通道宽度、深度和输入大小的残差网络变体。这些变体分别命名为ResNet-504、ResNet-5016和ResNet-50*64,分别对应原始ResNet-50的4倍、16倍和64倍计算量。对于Vision Transformer,作者选择了ViTBase/32、ViTBase/16和ViTLarge/14,其中的32、16和14是指patch的大小。由于ViTLarge已经非常大,因此没有进一步增加其大小,如果需要更大的模型,作者提到了ViT Huge和ViT G作为备选。
所有这些模型都进行了32个epochs的训练,使用了Adam优化器,并对所有超参数进行了一些网格搜索和随机搜索的手动调整,以加快调参速度。对于更大的模型,作者并没有进一步调整超参数。在训练期间,作者选择了非常大的批量大小,超过3万个,这表明模型明显是在多台机器上进行分布式训练的。混合精度训练也得以应用,这不仅可以加速训练,还可以节省内存。作者还采用了许多其他技术来进一步减少内存占用。
最大的ResNet网络ResNet-50*64在592台V100 GPU上训练了18天,而最大的Vision Transformer模型ViTLarge/14在256台V100 GPU上只花了12天。这再次证明了Vision Transformer在训练效率上的优势,正如ViT论文中所述。作者还提到,最后对性能进行Fine-Tune时,使用了更大尺寸的图像(336x336),这种Fine-Tune可以提高性能,这个技巧来自于先前的研究。
在接下来的文章中,如果没有特别说明,提到CLIP时都指的是这个最大、最好的模型。至此,我们完成了文章第二章的内容。
实验

在实验部分的开头,作者首先介绍了什么是"zero-shot transfer",因为这个概念是CLIP文章的核心和精华所在。作者不得不再次强调他们为什么要研究这个问题,这是因为之前的自监督或无监督方法主要关注特征学习的能力,他们的目标是学习到具有很好泛化性能的特征,例如之前提到的MOCO、SimCLR和DINO等方法。然而,即使你学习到了高质量的特征,当你尝试将其应用于下游任务时,通常仍然需要标注数据进行微调。这就引发了一系列问题,比如难以收集下游任务所需的数据,以及可能存在的数据分布偏移等问题。因此,作者的动机在于,如何能够训练一个模型,使其在经过预训练后,不再需要进一步微调,尤其是在应对各种下游任务时,如分类等,这个问题尤为关键。而一旦你借助文本信息,训练好了一个大型而高性能的模型,你就可以利用文本信息作为引导,以实现高度灵活的"zero-shot transfer"学习。至少在分类任务上,CLIP展现出了非常出色的效果。这一动机和方法的创新,是CLIP文章的重要亮点。
当使用CLIP进行zero-shot迁移时,让我们回到图1来详细了解这个过程,以更直观地理解。在CLIP进行预训练之后,它会拥有两个编码器,一个用于图像,一个用于文本。这两个编码器都已经在预训练中得到了训练。
假设我们有一张狗的照片作为输入。通过图像编码器,它将生成一个图像特征向量。然后,在文本输入的一侧,我们需要提供感兴趣的标签,比如“飞机”、“汽车”、“狗”和“鸟”。这些标签会经过一种叫做"prompt engineering"的处理,将它们转化为相应的句子。例如,“飞机”会转化为句子"这是一张飞机的照片"。同样,其他标签也会被转化成相应的句子。
现在,我们有了四个句子,它们分别描述了四个标签。通过文本编码器,每个句子都会生成一个文本特征向量。接下来,我们将这四个文本特征向量与图像特征向量计算余弦相似度。这将产生四个相似度分数。然后,通过Softmax函数,将这些相似度分数转化为概率分布。最终,哪个句子对应的概率最高,哪个标签就是最可能出现在这张照片中的物体。
如果我们想对ImageNet中的所有图像执行此过程以测试模型性能,那么我们需要生成多少个句子呢?答案是1,000个句子,因为ImageNet有1,000个类别。所以,对于每张图像,我们可以认为我们用1,000个句子分别询问它是否是飞机、汽车、狗、人等。然后,它会与这1,000个句子进行比较,并选择与之最接近的句子,从而确定图像属于哪个类别。
需要注意的是,在计算文本特征时,并不是按照这种顺序逐一计算的,而是可以批量处理的。因此,CLIP的zero-shot推理过程非常高效。

讲完了如何进行Zero Shot的推理,接下来我们就可以看看CLIP在不同任务上的表现了。在3.1.3节中,作者将CLIP的性能与之前的工作Visual N grams进行了对比。作者在表1中展示了令人惊讶的结果,即Visual N grams在ImageNet上的准确率仅为11.5%,而CLIP的准确率已达到76.2%。这个76.2%的性能几乎与之前的原版ResNet-50相媲美,而且现在完全不需要使用任何训练图像,只需进行Zero Shot迁移即可达到76.2%。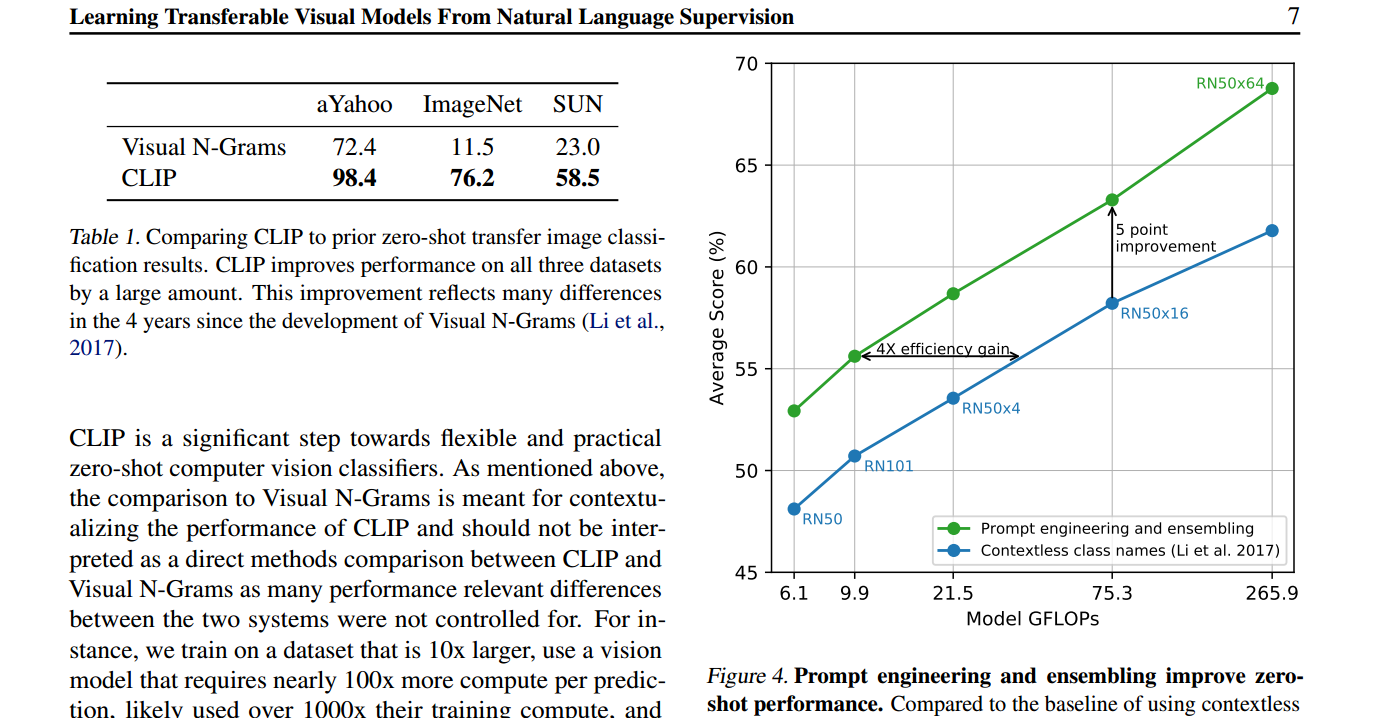
如果我们看一下表1,CLIP和Visual N grams的直接比较,可以看到CLIP在各个数据集上都明显优于Visual N grams。然而,作者指出这并不是一个公平的比较,因为许多方面都不同。CLIP的数据集比以前的方法大了10倍,视觉模型的计算量也多了100倍。这意味着在训练方面,他们使用了超过1,000倍的资源来训练这个模型。此外,在模型架构方面,CLIP使用了Transformer,而在Visual N grams的论文发表时,Transformer还不存在。因此,作者的目的是强调这不是一个公平的比较,并对以前的工作表示尊重。

在3.1.4节中,作者介绍了prompt engineering和ensemble这两个技术。Prompt engineering是一种近期在NLP和计算机视觉领域非常流行的方法,用于微调或进行推理,而不是在预训练阶段。这个方法的好处在于它不需要大量的计算资源,但仍然能够取得良好的效果。
Prompt的含义有很多,但在这里,它起到提示的作用,也就是文本的引导。为什么需要进行prompt engineering和ensemble呢?作者提出了两个常见的问题。
首先,多义性问题。有些单词可能有多个含义,如果每次只使用一个单词作为prompt,就可能会出现歧义。例如,在ImageNet数据集中,包含了两个类别,一个是construction crane,另一个是crane。在不同语境下,这两个单词的含义是不同的。通过使用一个提示模板,将标签转化为句子,可以减少多义性问题。
其次,分布差异问题。在预训练时,匹配的文本通常是一个句子,但在推理时,每次输入的是一个单词,这可能导致分布差异。通过使用提示模板,可以将prompt转化为句子,减少分布差异问题。
作者提出了一个简单而有效的提示模板,将标签放在模板中,变成句子的形式,例如,“这是一张飞机的图片”。这种提示模板在准确度上提高了1.3%。此外,作者还指出,如果您提前知道一些信息,例如您正在处理oxford-IIIT Pets数据集,那么您可以在提示中加入更多上下文信息,以提高zero-shot推理的准确性。

作者还介绍了prompt ensembling的概念,即多次使用不同的提示模板进行推理,然后综合结果,通常会获得更好的性能。在论文中,作者使用了80个提示模板进行ensemble。
最后,作者列举了一些示例提示模板,这些模板在不同情境下有助于更好地匹配物体。这种提示模板的目的是尽量描述物体可能所处的环境,以减少歧义和分布差异问题。
最后就是实验数据的对比了:所以接起来在3.1.5节, 作者就大范围的在27个数据集上, 去衡量了一下, CLIP 做这种 zero shot的迁移的效果,
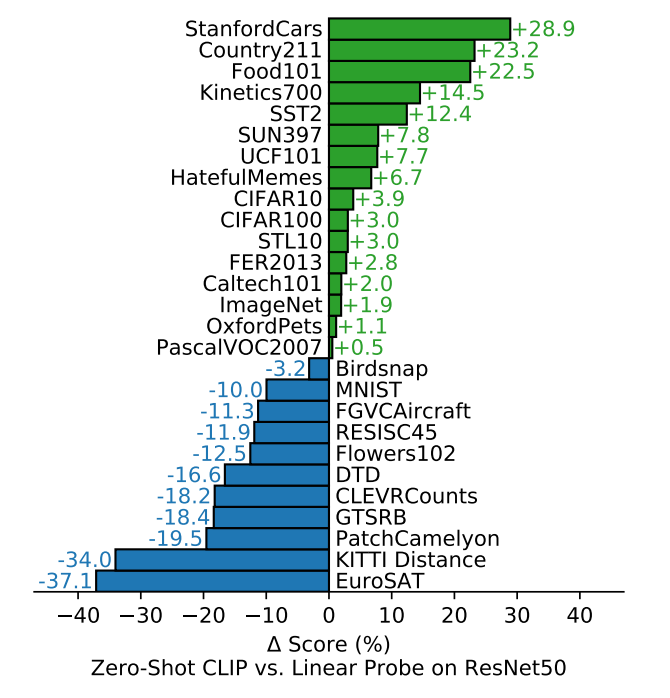
一个重要的实验是将CLIP与传统的在ImageNet上有监督训练的ResNet-50模型进行比较,使用"linear probe"这种微调方式。在这个实验中,CLIP的性能表现是关键。作者将这种方法作为基线,然后比较CLIP模型的性能相对于这个基线的提升或降低。
绿色的加号表示CLIP相对于基线提升的性能,蓝色表示CLIP相对于基线降低的性能。结果显示,在大多数数据集上,Zero Shot的CLIP模型都超越了有监督预训练的ResNet-50模型。这个结果非常惊人,因为它证明了Zero Shot的迁移在多个数据集上都是有效的,而不仅仅局限于ImageNet或某些特定的数据集上。
但是在一些非常抽象和难以分类的任务上,如对纹理进行分类或给图片中的物体计数,CLIP模型可能会面临很大的挑战。这是因为对于这种极具挑战性的任务,仅凭零样本迁移可能不够合理,因为没有提供足够的标签信息和领域知识。
在这方面,作者提出了一种合理的观点,即在这些难以处理的任务上,进行少样本学习(Few Shot Learning)可能会更合适。即使对于人类来说,如果没有特定领域的先验知识,也很难正确分类这些任务。因此,作者认为不应该过于强调CLIP在零样本迁移时的性能,而应该更加注重在少样本学习(Few Shot Learning)情况下的性能。
为了确保这一观点的合理性,作者也进行了相关的Few Shot学习实验,以评估CLIP在更具挑战性的任务上的性能。这种方法更加符合实际,因为它允许模型在有限的示例和领域知识下学习,并在挑战性任务上表现更好。作者通过这种方式强调了CLIP的应用场景和局限性,以便更好地理解何时以及如何使用该模型。所以在图6里呢, 作者就做了一下 zero shot CLIP 和 Few Shot CLIP, 以及和之前, Few Shot 的那些方法的一些比较,

这一部分详细说明了CLIP模型在不同Few Shot学习情景下的性能比较,并与基线方法进行了对比。
首先,图6横坐标表示数据集中每个类别的训练样本数量,0表示Zero Shot。而图6纵坐标表示平均分类准确度,这个平均准确度是在27个数据集上取得的平均值。
以下是关于图6的一些关键观察和结论:
\1. Zero Shot CLIP vs. Bit模型: 蓝色曲线代表Bit模型,Bit模型是Google的BigTransfer工作的一部分,专门为迁移学习而设计。Bit模型在ImageNet21k上进行了预训练,数据集规模较大。令人印象深刻的是,Zero Shot CLIP(不使用任何训练样本)直接与Bit模型(使用大量训练样本)的性能持平。这表明CLIP模型在多模态学习中的自然语言引导能力的强大。
\2. Few Shot CLIP vs. Zero Shot CLIP: 紫色曲线表示CLIP模型的Few Shot学习,其中对CLIP的图像编码器进行Few Shot的线性探测。有趣的是,当训练样本数量仅为1、2或4时,使用Few Shot的方式不如直接使用Zero Shot的CLIP性能好。这再次强调了使用文本引导的多模态学习的强大。
\3. Few Shot CLIP随样本增多的性能提升: 随着训练样本数量的增加,Few Shot学习的CLIP模型的性能逐渐提高。在训练样本数量增加时,Few Shot学习的CLIP不仅超越了以前的方法,还超越了Zero Shot的CLIP。这进一步验证了在面对困难数据集时,一些训练样本仍然是非常有必要的。
总之,这些结果表明CLIP模型在多模态学习中的表现出色,尤其在Zero Shot和Few Shot学习方面,它显示出了强大的性能。这也强调了在处理难以分类的任务时,增加一些训练样本可以提高模型的性能。

作者在第3.2节进行了相关实验。他将这一节称为"特征学习",因为在以前的方法中,无论是无监督还是自监督的情况下,通常都需要首先预训练一个模型,然后在下游任务上使用全部数据进行微调。因此,如果使用全部数据,可以将其与以前的特征学习方法进行公平比较。
在下游任务中使用全部数据有多种衡量方式,其中最常见的两种是线性探测(linear probe)和微调(fine-tune)。线性探测是指将预训练好的模型冻结,然后在其上再训练一个分类头。而微调则是指放开整个网络,进行端到端的学习。微调通常更灵活,并且在下游数据集较大时,微调的效果往往比线性探测要好得多。
然而,在CLIP这篇论文中,作者选择使用线性探测,而不是微调,有几个原因。首先,CLIP的目标是研究与数据集无关的预训练方法。如果在足够大的下游数据集上进行微调,可能会掩盖掉预训练模型的质量差异。线性探测不太灵活,因为大部分网络被冻结,只有最后一层分类头可以训练。这意味着如果预训练模型不够好,即使在下游任务上训练很长时间,也难以优化得到好的结果,因此可以更准确地反映出预训练模型的质量。
另一个使用线性探测的原因是因为它不需要太多的超参数调整。CLIP论文进行了大量实验,涵盖了多个数据集,如果采用微调,就需要调整许多超参数和设计方案。例如,如果下游数据集很大且标注质量很高,可能需要使用较大的学习率来拟合数据集。但如果下游任务的数据集很小,可能需要使用较小的学习率以防止过拟合。线性探测只需要调整很少的参数,并且对于任何数据集和任务,测试流程都是一样的,不需要改变,因此简化了方法之间的比较过程。
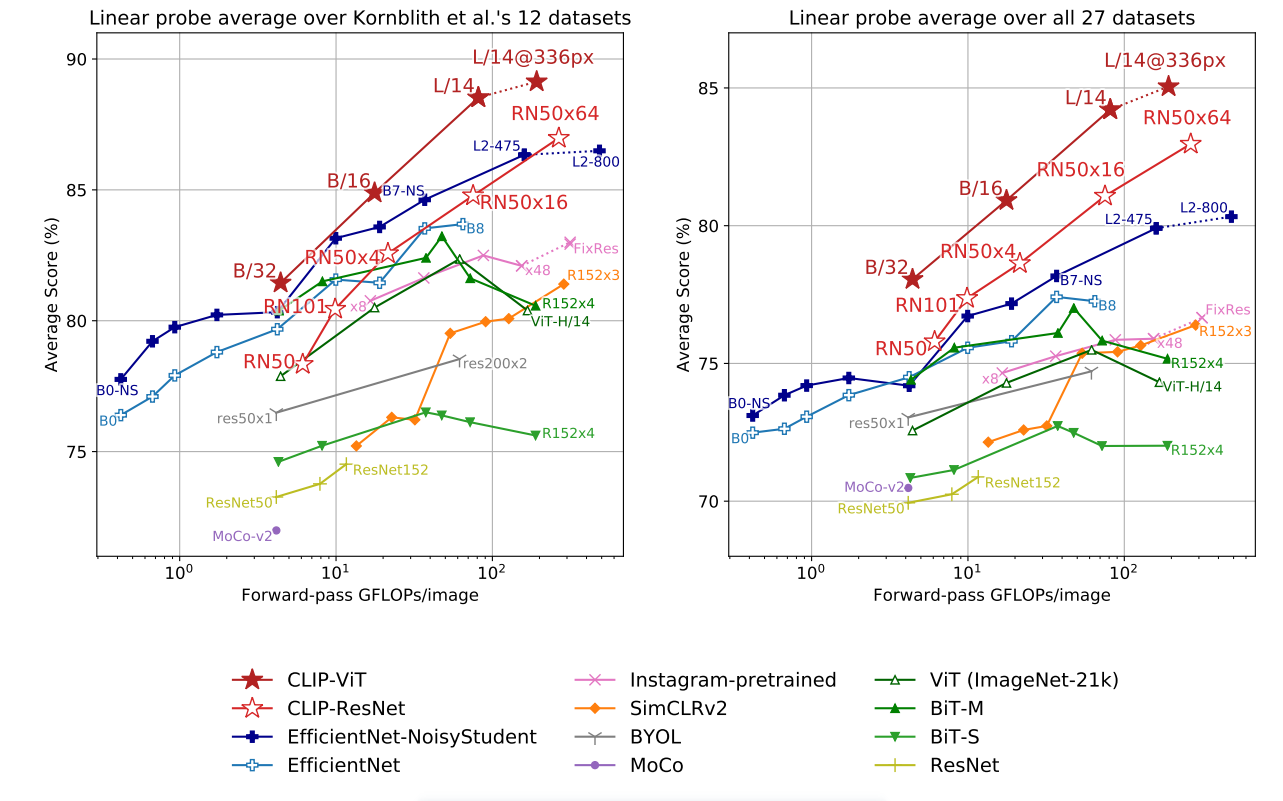
作者在图10中展示了CLIP模型与其他方法的比较结果。作者比较了多种方法,从CLIP自身到有监督的EfficientNet,使用伪标签的EfficientNet,以及弱监督方法在Instagram上训练的模型,还包括最近流行的自监督学习方法,以及一些经典的有监督学习基线模型。
图10包括两张图,它们传达了相同的信息。横坐标表示对于单张图片执行前向计算所需的计算量,纵坐标表示在多个数据集上的平均准确率。换句话说,准确率越高,所需时间越短,效果越好。因此,这两张图中靠左上角的点代表模型在精度和速度方面达到了更好的平衡。
首先看右图,作者平均了27个数据集上的结果。在这里,CLIP的效果用红色的五角星和红色的空心五角星表示,它在所有其他模型上表现最好,这再次证明了CLIP模型的强大。CLIP在zero-shot和few-shot任务上都表现出色,并且即使在使用全部数据进行训练时,CLIP仍然优于其他模型。
左边的图是为了与以前的工作进行公平比较,因为之前有一个工作使用了包含12个数据集的集合,人们通常使用这12个数据集来比较平均效果。在这张图中,可以看到使用更大的模型(如Vision Transformer)的CLIP效果良好,但使用残差网络的CLIP效果略逊于其他一些方法。然而,作者指出,这12个数据集与ImageNet之间存在较大的关联性,因此如果模型在ImageNet上进行了有监督的预训练,那么它在这些数据集上的效果很可能会更好。
最后,作者为了再次证明CLIP模型的强大,选择了在ImageNet上表现最佳的模型,即使用最大的EfficientNet和伪标签的方式进行训练的模型。作者将CLIP模型和这个模型都冻结,然后从中提取特征,最后进行逻辑回归。结果显示,在27个数据集中,CLIP在21个数据集上超过了EfficientNet,并且在很多数据集上领先幅度较大。即使在表现较差的数据集上,CLIP也只略逊于EfficientNet,差距不大。
总之,CLIP模型在多个方面表现出色,包括zero-shot、few-shot任务以及使用全部数据进行训练的任务。作者还探讨了CLIP模型的泛化性和稳健性,发现它在面对数据分布变化时表现出色。这篇论文提供了对CLIP模型的全面分析和讨论,以及与其他方法的比较。
局限
作者在论文中提出了关于CLIP模型的几个关键观点和总结:
\1. CLIP与传统机械模型平手: 作者指出,CLIP在许多数据集上的表现平均下来与简单的ImageNet上训练的ResNet-50模型相当。但需要注意的是,ResNet-50并不代表最新的state-of-the-art模型,因此CLIP并不一定是在所有任务上都领先的。
\2. CLIP的局限性: CLIP在分类任务方面表现出色,但它对于异常和安全性的理解非常有限。作者认为,在某些情况下,CLIP可能无法胜任,因此它并不是一种适用于所有领域的通用方法。
\3. Zero Shot性能的局限性: 作者强调了CLIP在zero-shot分类任务中的局限性,特别是当数据与训练数据差距较大时out of distribution。作者以MNIST数据集为例,指出CLIP在这个数据集上的准确率相对较低,与其他简单模型相比不占优势。
\4. 数据效率问题: CLIP需要大量的数据来进行训练,但这在计算资源方面非常昂贵。作者提出了减少数据用量的方法,包括数据增强、自监督学习和伪标签等。
\5. 对比学习与生成式方法的结合: 作者认为,结合对比学习和生成式方法可能是未来的研究方向,可以综合两者的优势,提高模型的性能和灵活性。
\6. 偏见问题: 作者提到,CLIP模型的数据集可能存在偏见,因为它们爬取来自于互联网上未经审查的数据。这可能导致模型带有社会偏见。
\7. 局限性与复杂性: CLIP在处理复杂任务和概念时可能会受到限制,因为某些任务需要更多的训练样本以进行泛化。然而,CLIP并不是为Few-shot学习而设计的,因此在提供额外训练样本时,其性能可能不如在zero-shot情况下表现得好。
综上所述,CLIP模型在许多方面表现出色,但仍然具有一些局限性和挑战,特别是在处理复杂任务和不同分布的数据时。作者提出了一些可能的改进方法和研究方向,以进一步提高CLIP的性能和应用范围。
四、简单试试
from PIL import Image
import requestsfrom transformers import CLIPProcessor, CLIPModel # 挂不挂梯子都试试,看看怎么能下载model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32") # openai/clip-vit-base-patch32
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# url = "http://images.cocodataset.org/val2017/000000039769.jpg"
# image = Image.open(requests.get(url, stream=True).raw)
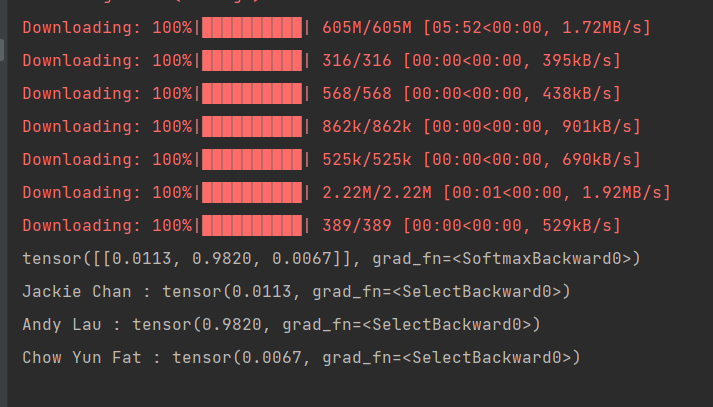
image = Image.open('liudehua.jpg')text = ["Jackie Chan", "Andy Lau", 'Chow Yun Fat']inputs = processor(text=text, images=image, return_tensors="pt", padding=True)outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
print(probs)
for i in range(len(text)):print(text[i], ':', probs[0][i])
运行自动下载huggingface权重文件,输入一张刘德华照片,给出华哥的英文名称(中文或拼音没用),从结果可以看出,华哥0.98的概率,其实这也涉及之前所说道德法律等等,擅自爬取个人图片,肯定没有得到别人准许。就到这里┏(^0^)┛




![[SWPUCTF 2022]——Web方向 详细Writeup](https://img-blog.csdnimg.cn/img_convert/54be7975c5048b4987a110731d16fab9.png)