文章目录
- 1. Wide&Deep模型的记忆能力和泛化能力
- 2. Wide&Deep模型的结构
- 3. Wide&Deep模型的进化——Deep&Cross模型
- 4. Wide&Deep模型的影响力
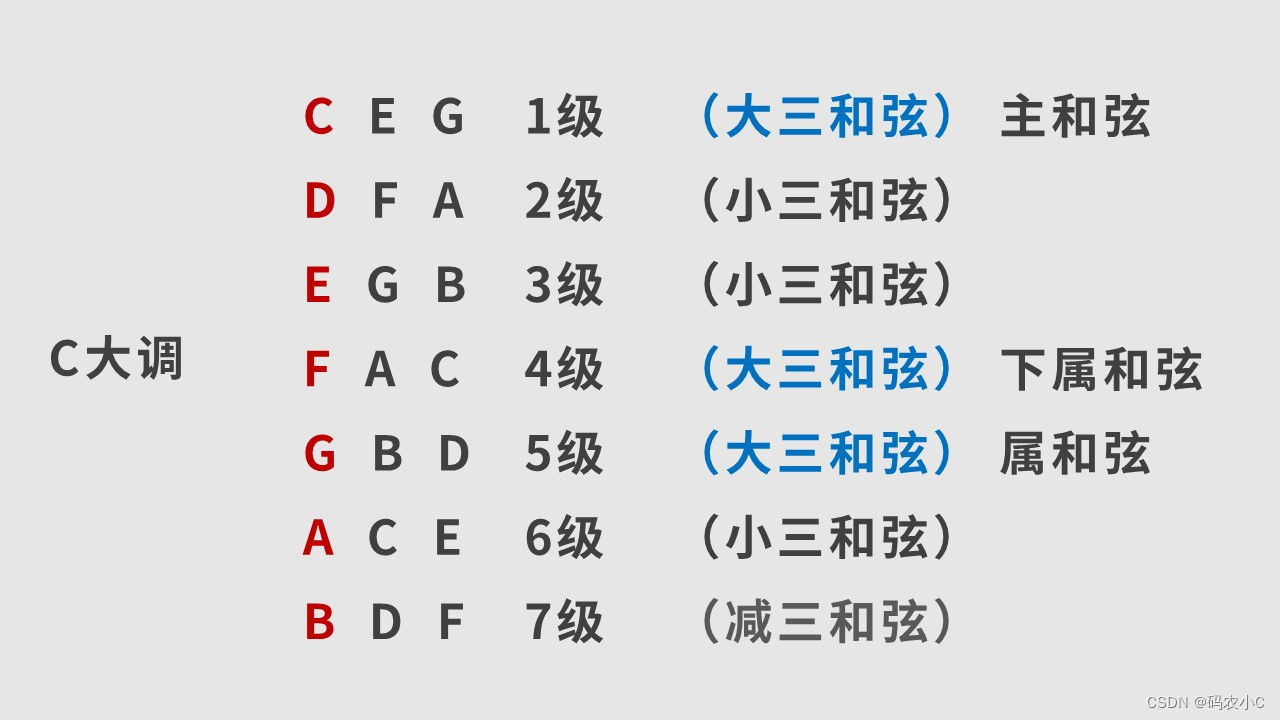
Wide&Deep模型是 记忆能力和 泛化能力的综合,是谷歌在2016年提出的。正如其名,Wide&Deep模型是由 单层的Wide部分和 多层的Deep部分组成的混合模型。
- 其中,Wide部分的主要作用是让模型具有较强的“记忆能力”(memorization);
- Deep部分的主要作用是让模型具有“泛化能力”(generalization)。
这样的结构特点,使模型兼具了逻辑回归和深度神经网络的优点——能够快速处理并记忆大量历史行为特征,并且具有强大的表达能力。
1. Wide&Deep模型的记忆能力和泛化能力
- “记忆能力”可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力。
一般来说,协同过滤、逻辑回归等简单模型具有较强的“记忆能力”。由于这类模型的结构简单,原始数据往往可以直接影响推荐结果,产生类似于“如果点击过A,就推荐B”这类规则式的推荐,这就相当于模型直接记住了历史数据的分布特点,并利用这些记忆进行推荐。
这里以App推荐的场景为例,解释什么是模型的“记忆能力”:
假设在Google Play推荐模型的训练过程中,设置如下组合特征:AND(user_installed_app=netflix, impression_app=pandora)(简称netflix&pandora),它代表用户已经安装了netflix这款应用,而且曾在应用商店中看到过pandora这款应用。如果以“最终是否安装pandora”为数据标签(label),则可以轻而易举地统计处netflix&pandora这个特征和安装pandora这个标签之间的共现频率。假设二者的攻陷频率高达10%(全局的平均应用安装率为1%),这个特征如此志强,以至于在设计模型时,希望模型一发现有这个特征,就推荐pandora这款应用(就像个深刻的记忆点印在脑海里),这就是所谓的模型的“记忆能力”。
像逻辑回归这类简单模型,如果发现这样的“强特征”,则其相应的权重就会在模型训练过程中被调整得非常大,这样就实现了对这个特征的直接记忆。相反,对于多层神经网络来说,特征会被多层处理,不断与其他特征进行交叉,因此模型对这个特征的记忆反而没有简单模型深刻。
- “泛化能力”可以理解为模型传递特征的相关性,以及发掘系数甚至从未出现过的稀有特征与最终标签相关性的能力。
矩阵分解比协同过滤的泛化能力强,因为矩阵分解引入了隐向量这样的结构,使得数据稀少的用户或者物品也能生成隐向量,从而获得有数据支撑的推荐得分,这就是非常典型的将全局数据传递到稀疏物品上,从而提高泛化能力的例子。再比如,深度神经网络通过特征的多次自动组合,可以深度发掘数据中潜在的模式,即使是非常稀疏的特征向量输入,也能得到比较平稳的推荐概率,这就是简单模型所缺乏的“泛化能力”。
2. Wide&Deep模型的结构
Wide&Deep模型的直接动机就是将简单模型的“记忆能力”和深度神经网络的“泛化能力”融合,具体的模型结构如下:

Wide&Deep模型把单输入层的Wide部分与Embedding层和多隐层组成的Deep部分连接起来,一起输入最终的输出层。
- 单层的Wide部分善于处理大量系数的id类特征;
- Deep部分利用神经网络表达能力强的特点,进行深层的特征交叉,挖掘在特征背后的数据模式。
最终,利用逻辑回归模型,输出层将Wide部分和Deep部分组合起来,形成统一的模型。
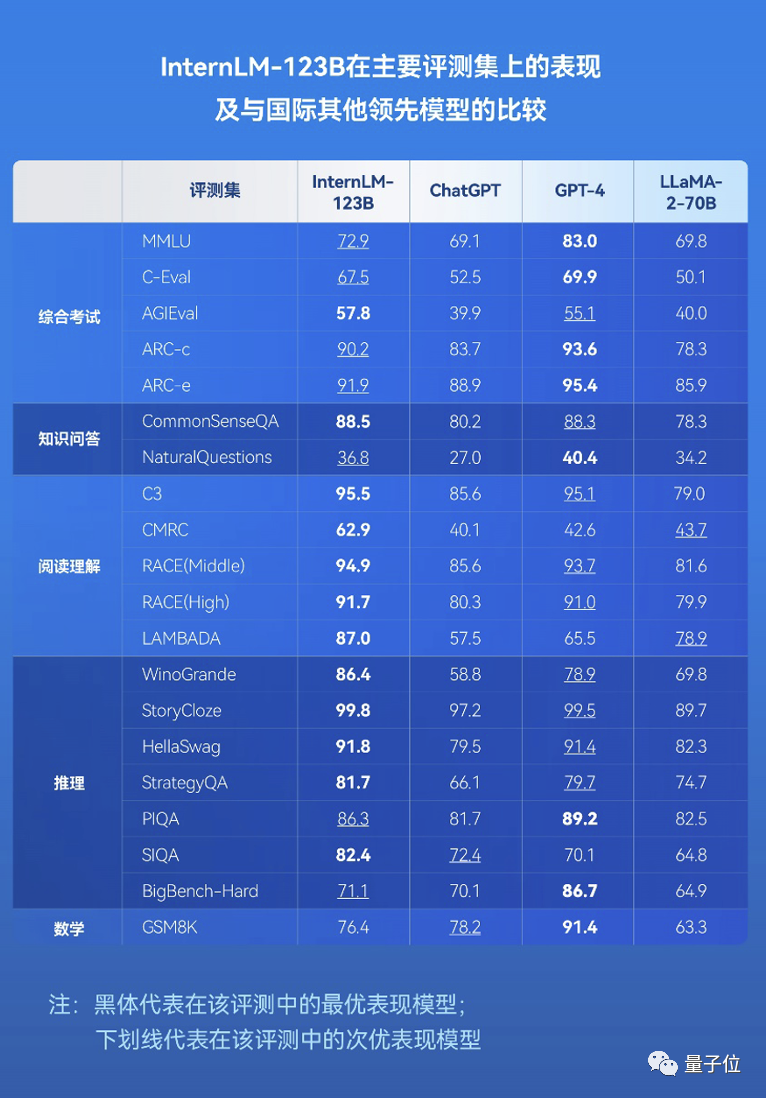
在具体的特征工程和输入层设计中,展现了Google Play的推荐团队对业务场景的深刻理解。从下图中可以详细地了解到Wide&Deep模型到底将哪些特征作为Deep部分的输入,将哪些特征作为Wide部分的输入:

Deep部分的输入是全量的特征向量,包括用户年龄(Age)、已安装应用数量(#App Installs)、设备类型(Device Class)、已安装应用(User Installed App)、曝光应用(Impression App)等特征。已安装应用、曝光引用等类别型特征,需要经过Embedding层输入连接层(Concatenated Embedding),拼接成1200维的Embedding向量,再经过3层ReLU全连接层,最终输入LogLoss输出层。
Wide部分的输入仅仅是已安装应用和曝光应用两类特征,其中已安装引用代表用户的历史行为,而曝光应用代表当前的待推荐应用。选择这两类特征的原因是充分发挥Wide部分“记忆能力”强的优势。
Wide部分组合“已安装应用”和“曝光应用”两个特征的函数被称为交叉积变换(Cross Product Transformation)函数,其形式化定义如下:

-
Cki是一个布尔变量,当第i个特征输入第k个组合特征时,Cki的值就为1,否则为0;
-
xi是第i个特征的值。例如对于“AND(user_installed_app=netflix,impression_app=pandora)”这个特征组合来说,只有当“user_installed_app=netflix”和“impression_app=pandora”这两个特征同时为1时,其对应的交叉积变换层的结果才为1,否则为0.
在通过交叉积变换层操作完成特征组合之后,Wide部分将组合特征输入最终的LogLoss输出层,与Deep部分的输出一同参与最后的目标拟合,完成Wide与Deep部分的融合。
3. Wide&Deep模型的进化——Deep&Cross模型
Deep&Cross模型(DCN)结构图如下:

其主要思路是使用Cross网络替代原来的Wide部分。Deep部分的设计思路并没有本质的改变,下面主要介绍Cross部分的设计思路。
设计Cross网络的目的是增加特征之间的交互力度,使用多层交叉层(Cross layer)对输入向量进行特征交叉。假设第l层交叉层的输出向量为xl,那么l+1层的输出向量形式为:

交叉层的操作如图:

可以看出,交叉层在增加参数方面是比较“克制”的,每一层仅增加一个n维的权重向量wl(n维输入向量维度),并且在每一层均保留了输入向量,因此输出与输入之间的变化不会特别明显。由多层交叉层组成的Cross网络在Wide&Deep模型中的Wide部分的基础上进行了特征的自动化交叉,避免了更多基于业务理解的人工智能特征组合。同Wide&Deep模型一样,Deep&Cross模型的Deep部分相比Cross部分表达能力更强,使模型具备更强的非线性学习能力。
4. Wide&Deep模型的影响力
Wide&Deep模型的影响力无疑是巨大的,不仅其本身成功引用于多家一线互联网公司,而且其后续的改进创新工作也延续至今。事实上,DeepFM、NFM等模型都可以看成Wide&Deep模型的延伸。
Wide&Deep模型能够取得成功的关键在于:
(1)抓住了业务问题的本质特征,能够融合传统模型记忆能力和深度学习模型泛化能力的优势。
(2)模型的结构并不复杂,比较容易在工程上实现、训练和上线,这加速了其在业界的推广应用。
也正是从Wide&Deep模型之后,越来越多的模型结构被加入推荐系统中,深度学习模型的结构开始朝着多样化、复杂化的方向发展。