目录
- 1 简介
- 2 思路分解与说明
- 3 完整代码
1 简介
最近完成一个工作,就基于一些表格化的数据进行机器学习分类。
由于分类是研究中的关键步骤,所以首先要选择到底哪个模型适合我们的分类任务。
比较传统且经典的选择方法就是用交叉验证。
交叉验证是什么可以看以下这幅图,来自这篇论文,这里不过多赘述。
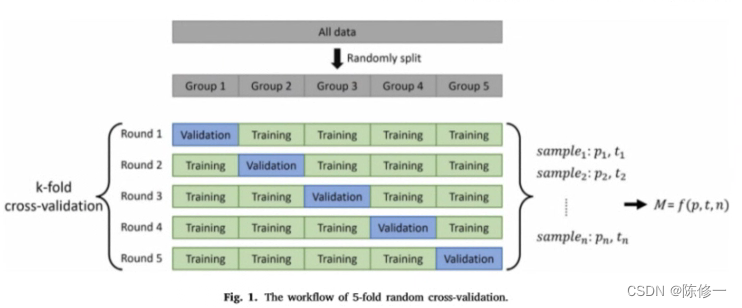
那么,具体实验中,有了数据之后,要怎么用自动化高效地方法完成交叉验证并选择合适的模型呢?这篇博文就是为了解决这个问题。
本文要实现的东西很简单,在于:
对多个模型进行k折交叉验证,并且对输出每一fold和每个模型的总体评价指标。
因此,本文的思路是:
1,读取数据;
2,拆分数据,并且对每一个fold进行质量指标计算;
3,汇总结果,对一个模型的总体结果的质量指标进行计算。
2 思路分解与说明
我们首先需要从本地文件中读取用于建模的样本数据,一般是用excel存取的,示例如下。
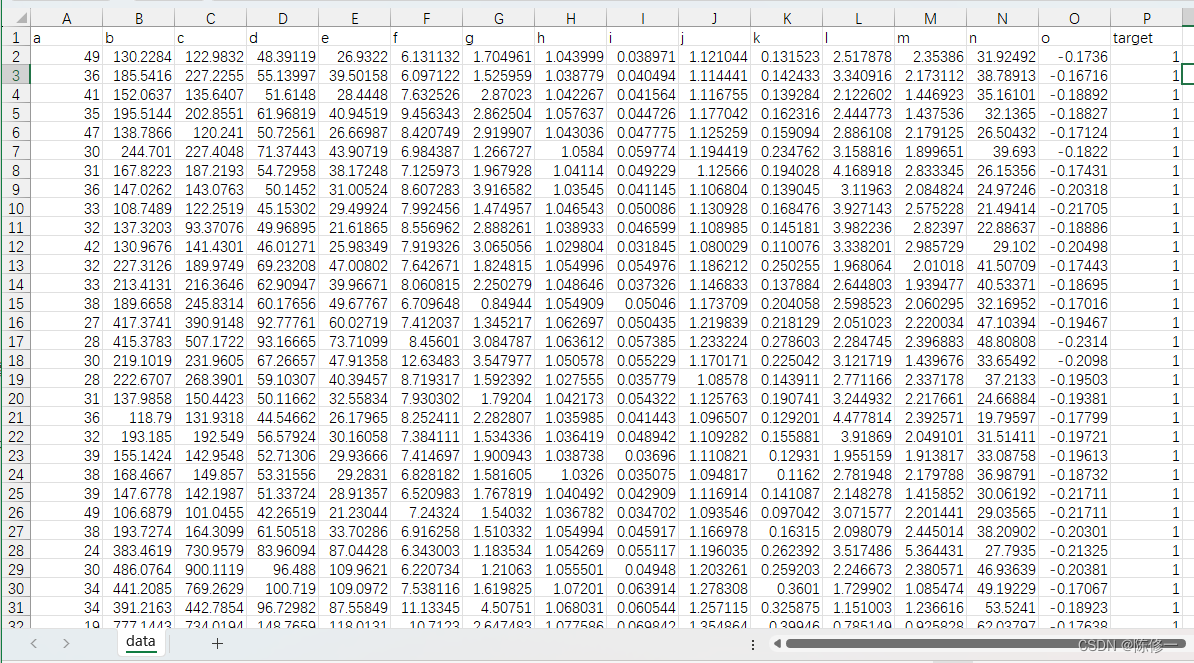
共有16列数据。其中前15列是特征(自变量),最后一列是目标(因变量)。
因为这个是分类任务,所以我的目标(因变量)只有两个值,即0和1。
首先,需要写个函数读取excel数据,如下。
def read_data(data_path, data_sheet):"""读取excel表格中的数据输入excel文件路径,输出dataframe格式的数据data_path: excel文件(xlsx或xls)的路径data_sheet: excel文件的sheet名称"""from pandas import read_excelfile = data_path # 读取数据路径data = read_excel(open(file, "rb"), sheet_name=data_sheet) # 读取数据return data
我们用这个函数读取了样本,并且用这两句代码
data = read_data("data.xlsx", "data") # 读取数据
print(data) # 样本数据
进行读取和打印,结果如下。

接下来就是实现交叉验证及其模型质量参数的计算。
这里用比较常用的一些参数,比如kappa系数,总体精度(OA),精确度(precision),召回率(recall),F1-score这些,基本覆盖了分类任务中常用的所有评价指标。
好在关于这个分折(k-fold)和这些指标的计算都有比较方便的接口,接下来的任务就是整合以上需求,以分折交叉验证和这些指标的计算为导向写一个函数。函数如下。
def KFold_Classificaton(data, KNumber, classification_model, shuffle=False, random_state=None):"""K折交叉验证输入数据和K折交叉验证所需参数,打印各次模型的精度指标data: dataframe格式数据KNumber: 折数classification_model: 实例化后的分类模型shuffle: 是否打乱样本,默认不打乱random_state: 随机种子target_names: 目标类名输出所有折验证的结果"""from sklearn.model_selection import KFoldfrom sklearn.metrics import classification_reportfrom sklearn.metrics import accuracy_score, precision_score, f1_score, recall_score, cohen_kappa_scorekf_model = KFold(n_splits=KNumber, shuffle=shuffle, random_state=random_state) # KFold规则,KNumber为折数results_list = [] # 存放所有结果dataframe的list# 每折的计算fold_counter = 1 # 折数计数器model_copy = classification_modelfor train_index, test_index in kf_model.split(data):results = DataFrame()print("=======================================================================")# 分割训练集和验证集的特征和目标x_train = data.iloc[train_index, 0:-1]y_train = data.iloc[train_index, -1]x_test = data.iloc[test_index, 0:-1]y_test = data.iloc[test_index, -1]model_copy.fit(x_train, y_train) # 训练模型y_predict = model_copy.predict(x_test) # 模型预测kappa = cohen_kappa_score(y_test, y_predict) # kappa系数model_report = classification_report(y_test, y_predict, digits=6) # 分类精度报告# 存放结果results["true"] = y_testresults["pred"] = y_predictresults["fold"] = fold_counterresults_list.append(results)# 显示结果print(f"第 {fold_counter} 次精度验证:\n模型: {model_copy}\nkappa = {kappa}\n", model_report)fold_counter += 1print("=======================================================================\n")# 整合结果tot_results = pd.concat(results_list, axis=0) # 合并所有结果tot_results = tot_results.reset_index(drop=True) # 重置索引y_test = tot_results["true"]y_predict = tot_results["pred"]kappa = cohen_kappa_score(y_test, y_predict) # kappa系数model_report = classification_report(y_test, y_predict, digits=6) # 分类精度报告print(f"总体结果精度验证:\n模型: {model_copy}\nkappa = {kappa}\n", model_report)print("=====================================================================================\n")return tot_results
这个函数调用了sklearn里的kfold接口,它能自动按照填入的折数分割样本;然后遍历每一折并且划分特征和目标以进行建模和相关精度指标的计算,精度指标计算也用了sklearn.metrics里自带的一些接口,可根据需要自行调节;最后把一个模型的所有折的结果汇总起来,以进行总体的精度评估。
由于上述函数的参数需要输入一个实例化的模型,我就在主函数写了一些以供选取。
# 1.决策树分类
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
# 2.SVM分类
from sklearn.svm import SVC
svm = SVC()
# 3.KNN分类
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
# 4.随机森林分类
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100)
# 5.Adaboost分类
from sklearn.ensemble import AdaBoostClassifier
adb = AdaBoostClassifier(n_estimators=100)
# 6.GBDT分类
from sklearn.ensemble import GradientBoostingClassifier
gbdt = GradientBoostingClassifier(n_estimators=100)
# 7.Bagging分类
from sklearn.ensemble import BaggingClassifier
bag = BaggingClassifier(n_estimators=100)
# 8.极端数分类
from sklearn.tree import ExtraTreeClassifier
et = ExtraTreeClassifier()
# 9.朴素贝叶斯分类
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
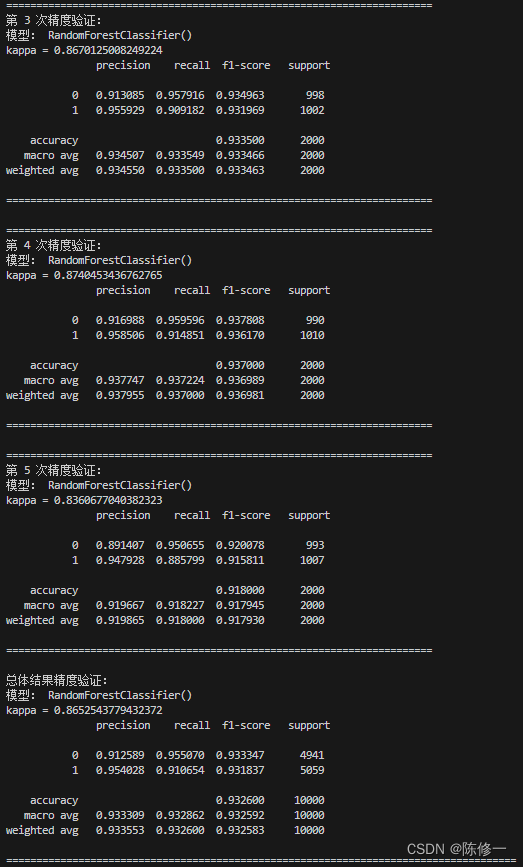
好的,接下来演示一下该函数的工作。比如我要用5折交叉验证测试随机森林(RF)和GBDT模型的效果,我就用以下语句。
KFold_Classificaton(data, 5, classification_model=rf, shuffle=True, random_state=1)
KFold_Classificaton(data, 5, classification_model=gbdt, shuffle=True, random_state=1)
部分结果输出如下。首先输出5次交叉验证的精度评估报告,然后汇总了5次结果并进行总体结果的评估。
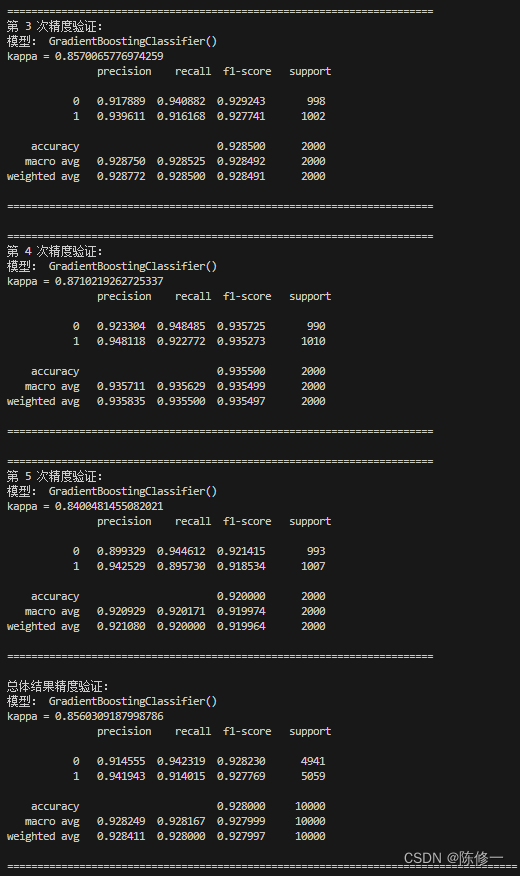
好了,到目前为止我们的任务完成了。
完整代码见下方,注释写得很详细了。
3 完整代码
import pandas as pd
from pandas import DataFramedef read_data(data_path, data_sheet):"""读取excel表格中的数据输入excel文件路径,输出dataframe格式的数据data_path: excel文件(xlsx或xls)的路径data_sheet: excel文件的sheet名称"""from pandas import read_excelfile = data_path # 读取数据路径data = read_excel(open(file, "rb"), sheet_name=data_sheet) # 读取数据return datadef KFold_Classificaton(data, KNumber, classification_model, shuffle=False, random_state=None):"""K折交叉验证输入数据和K折交叉验证所需参数,打印各次模型的精度指标data: dataframe格式数据KNumber: 折数classification_model: 实例化后的分类模型shuffle: 是否打乱样本,默认不打乱random_state: 随机种子target_names: 目标类名输出所有折验证的结果"""from sklearn.model_selection import KFoldfrom sklearn.metrics import classification_reportfrom sklearn.metrics import accuracy_score, precision_score, f1_score, recall_score, cohen_kappa_scorekf_model = KFold(n_splits=KNumber, shuffle=shuffle, random_state=random_state) # KFold规则,KNumber为折数results_list = [] # 存放所有结果dataframe的list# 每折的计算fold_counter = 1 # 折数计数器model_copy = classification_modelfor train_index, test_index in kf_model.split(data):results = DataFrame()print("=======================================================================")# 分割训练集和验证集的特征和目标x_train = data.iloc[train_index, 0:-1]y_train = data.iloc[train_index, -1]x_test = data.iloc[test_index, 0:-1]y_test = data.iloc[test_index, -1]model_copy.fit(x_train, y_train) # 训练模型y_predict = model_copy.predict(x_test) # 模型预测kappa = cohen_kappa_score(y_test, y_predict) # kappa系数model_report = classification_report(y_test, y_predict, digits=6) # 分类精度报告# 存放结果results["true"] = y_testresults["pred"] = y_predictresults["fold"] = fold_counterresults_list.append(results)# 显示结果print(f"第 {fold_counter} 次精度验证:\n模型: {model_copy}\nkappa = {kappa}\n", model_report)fold_counter += 1print("=======================================================================\n")# 整合结果tot_results = pd.concat(results_list, axis=0) # 合并所有结果tot_results = tot_results.reset_index(drop=True) # 重置索引y_test = tot_results["true"]y_predict = tot_results["pred"]kappa = cohen_kappa_score(y_test, y_predict) # kappa系数model_report = classification_report(y_test, y_predict, digits=6) # 分类精度报告print(f"总体结果精度验证:\n模型: {model_copy}\nkappa = {kappa}\n", model_report)print("=====================================================================================\n")return tot_results# 1.决策树分类
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
# 2.SVM分类
from sklearn.svm import SVC
svm = SVC()
# 3.KNN分类
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
# 4.随机森林分类
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100)
# 5.Adaboost分类
from sklearn.ensemble import AdaBoostClassifier
adb = AdaBoostClassifier(n_estimators=100)
# 6.GBDT分类
from sklearn.ensemble import GradientBoostingClassifier
gbdt = GradientBoostingClassifier(n_estimators=100)
# 7.Bagging分类
from sklearn.ensemble import BaggingClassifier
bag = BaggingClassifier(n_estimators=100)
# 8.极端数分类
from sklearn.tree import ExtraTreeClassifier
et = ExtraTreeClassifier()
# 9.朴素贝叶斯分类
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()data = read_data("data.xlsx", "data") # 读取数据
print(data) # 样本数据# 交叉验证
KFold_Classificaton(data, 5, classification_model=dt, shuffle=True, random_state=1)
KFold_Classificaton(data, 5, classification_model=svm, shuffle=True, random_state=1)
KFold_Classificaton(data, 5, classification_model=knn, shuffle=True, random_state=1)
KFold_Classificaton(data, 5, classification_model=rf, shuffle=True, random_state=1)
KFold_Classificaton(data, 5, classification_model=adb, shuffle=True, random_state=1)
KFold_Classificaton(data, 5, classification_model=gbdt, shuffle=True, random_state=1)
KFold_Classificaton(data, 5, classification_model=bag, shuffle=True, random_state=1)
KFold_Classificaton(data, 5, classification_model=et, shuffle=True, random_state=1)
KFold_Classificaton(data, 5, classification_model=gnb, shuffle=True, random_state=1)
如果对你有帮助,还望支持一下~点击此处施舍或扫下图的码。
-----------------------分割线(以下是乞讨内容)-----------------------




![BUU [网鼎杯 2020 青龙组]AreUSerialz](https://img-blog.csdnimg.cn/img_convert/4aae068ae9e3745be8f2b6cee7547f8a.png)