🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
个人主页:beixi@
本文章收录于专栏(点击传送):【大数据学习】
💓💓持续更新中,感谢各位前辈朋友们支持学习~
文章目录
- 1.Flink组件介绍
- 2.环境准备
- 3.Flink搭建
1.Flink组件介绍
Flink(Apache Flink)是一个开源的流处理和批处理框架,它具有高性能、低延迟、容错性和灵活性的特点。Flink拥有强大而灵活的数据处理能力,用户可以根据自己的需求选择合适的组件和API来构建复杂的数据处理流程和批处理任务。以下是 Flink 的一些重要组件的介绍:
- Flink Core: Flink核心组件提供了任务调度、作业管理、资源管理、容错机制和数据传输等基础功能。它负责将用户提交的作业进行解析、分配任务并对其进行执行。
- DataStream API: DataStream API 是 Flink提供的用于处理无界流式数据的高级API。它允许用户定义有状态的流处理操作,如转换、过滤、聚合、窗口操作等。DataStream API支持事件时间和处理时间,并且具备低延迟和高吞吐量的能力。
- DataSet API: DataSet API 是 Flink 用于处理有界静态数据集的API。它提供了类似于传统编程模型的操作符,如Map、Reduce、Join、GroupBy 等。DataSet API 适用于离线批处理任务,具有良好的可扩展性和优化能力。
- Table API 和 SQL: Table API 和 SQL 提供了类似于关系型数据库的查询语言和操作符。用户可以使用 SQL查询和操作流或批数据,也可以在 Table API 中使用类似的操作符来处理数据。这种方式使得数据处理更加直观和易用。
- CEP(Complex Event Processing): Flink 提供了复杂事件处理的能力。CEP库允许用户定义规则来监测数据流中的模式和事件,并触发相应的操作。它可以用于实时监控、异常检测、欺诈检测等场景。
- Gelly: Gelly 是 Flink的图处理库,支持执行图算法和操作。它提供了一组高级算法,如图遍历、连通性分析、最短路径等。Gelly 可以在图结构数据上进行大规模的并行计算。
- Connectors: Flink 提供了与各种数据源和数据存储的连接器,如 Kafka、Hadoop HDFS、AmazonS3、Elasticsearch 等。这些连接器使得 Flink 可以方便地与外部系统集成,读取和写入数据。

2.环境准备
本次用到的环境有:
1.Oracle Linux 7.4
2.JDK 1.8
3.Flink 1.13.0
3.Flink搭建
1.解压flink压缩文件至/opt目录下
tar -zxvf /root/experiment/file/flink-1.13.0-bin-scala_2.11.tg -C /opt

2.修改解压后为文件名为flink
mv /opt/flink-1.13.0 /opt/flink

3.修改环境变量
vim /etc/profile
4.按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码
export FLINK_HOME=/opt/flink
export PATH=$PATH:$FLINK_HOME/bin
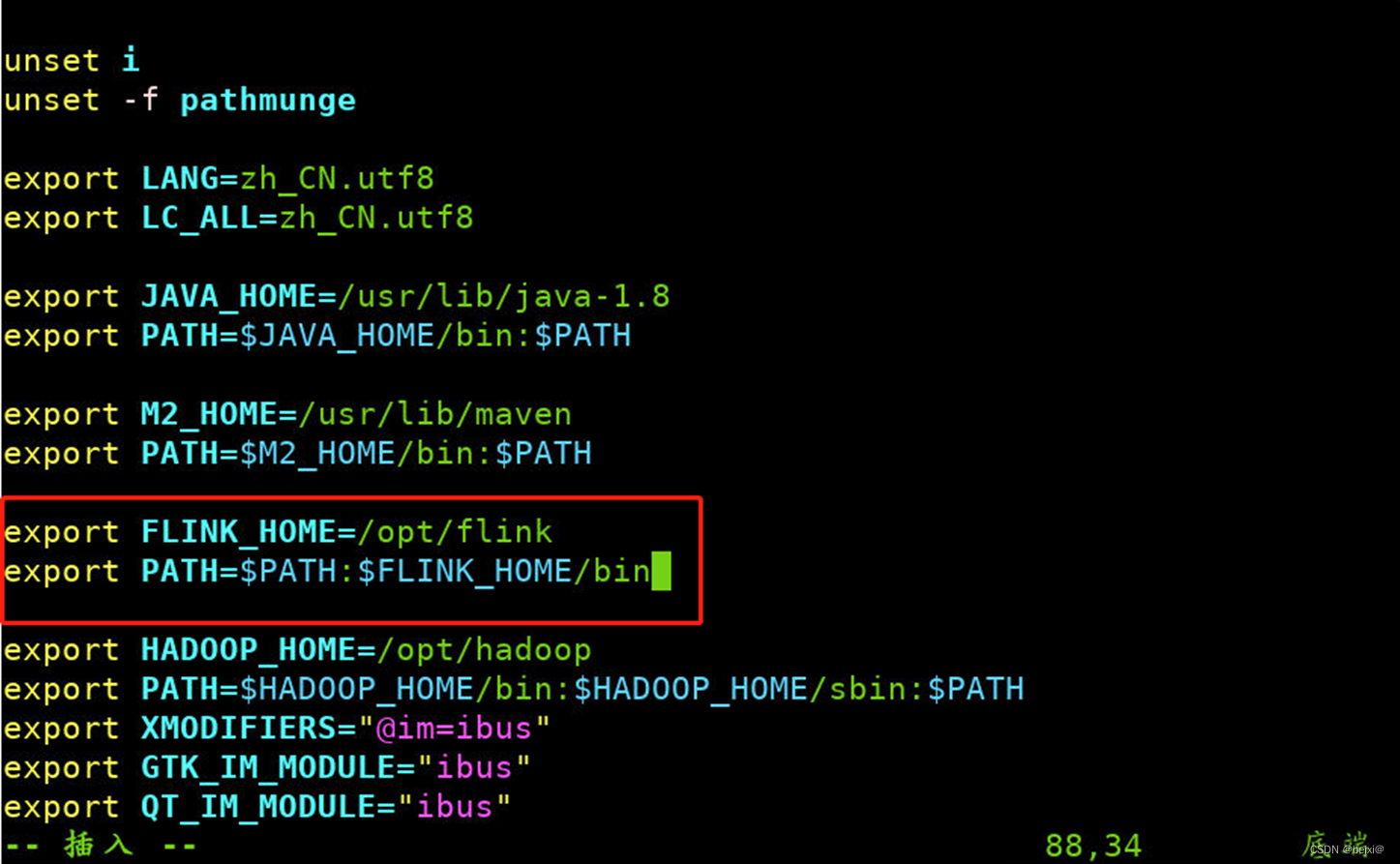
5.按键Esc,按键:wq保存退出
6.刷新配置文件
source /etc/profile

7.启动flink。
start-cluster.sh

8.查看flink版本信息。
flink --version

9.关闭flink。
stop-cluster.sh

至此,Flink搭建就到此结束了,如果本篇文章对你有帮助记得点赞收藏+关注~