Porto Vs. Benfica
翻译自官方题解。
我们首先做一些定义,这将帮助我们:
定义。 用 \(f(v)\) 表示支持者俱乐部从顶点 \(v\) 出发,想要到达顶点 \(n\) 所需的最少道路数,且警察仍然可以封锁恰好一条道路。
因此,\(f(1)\) 是问题的答案,且 \(f(n) = 0\)。
定义。 用 \(g(v, \, e)\) 表示从顶点 \(v\) 到顶点 \(n\) 的最短路径,且该路径不使用边 \(e\),并用 \(g(v)\) 表示所有与 \(v\) 相邻的边 \(e\) 对应的 \(g(v, \, e)\) 的最大值。
换句话说,\(g(v)\) 是从 \(v\) 到 \(n\) 的最短路径,且该路径不使用从 \(v\) 到 \(n\) 的最短路径上的边。现在我们有以下结论:
引理。 \(f(v) = \max\{g(v), \, 1 + \min_{v \sim u} f(u)\}\),其中 \(v \sim u\) 表示两个顶点相邻。
证明。 很容易看出,警察只会在支持者俱乐部位于与某条边相邻的顶点时封锁该边;否则,他们可以等到支持者俱乐部到达与该边相邻的顶点时再封锁它。因此,当支持者俱乐部位于某个顶点 \(v\) 时,警察有两种选择(他们会选择使支持者俱乐部需要经过的道路数最大化的选项):要么封锁与 \(v\) 相邻的某条边,要么不封锁任何边,让支持者俱乐部决定往哪里走。如果他们决定封锁道路 \(e\),那么支持者俱乐部需要经过 \(g(v, \, e)\) 条道路才能到达 \(n\),因此警察会选择 \(g(v)\) 来最大化这个值。如果他们决定不封锁任何道路,那么支持者俱乐部需要经过的道路数为 \(1\) 加上 \(f(u)\),其中 \(u\) 是支持者俱乐部最终到达的顶点。由于支持者俱乐部希望最小化经过的道路数,他们会选择使 \(f(u)\) 最小的 \(u\)。
注意到 \(g\) 的值可以通过对每个顶点 \(v\) 运行一次 BFS 在 \(O(m^2)\) 时间内找到。这对于解决问题来说太慢了,因此我们稍后会看到如何更高效地计算 \(g\),这是最棘手的部分。但首先,让我们看看在假设已经计算出 \(g\) 的情况下如何高效地找到 \(f\) 的值。
假设已知 \(g\),计算 \(f\)
为了找到 \(f\),我们可以使用一个与 Dijkstra 算法完全相同的贪心算法。考虑一个数组 \(\texttt{f}[]\),我们将用它来存储 \(f\) 的值。设置 \(\texttt{f}[n] = 0\),并对所有其他 \(v\) 设置 \(\texttt{f}[v] = g(v)\)。现在按以下方式处理每个顶点。选择当前 \(\texttt{f}[v]\) 值最小的未处理顶点 \(v\)。通过遍历所有与 \(v\) 相邻的顶点 \(u\) 并设置 \(\texttt{f}[v] = \max(g[v], \, \min(1 + \texttt{f}[u]))\) 来处理 \(v\)。直观上,这个处理步骤相当于应用引理中的 \(f\) 公式,但一次只考虑一对相邻顶点。为了高效地选择当前 \(\texttt{f}[v]\) 值最小的未处理顶点 \(v\),我们可以使用一个按 \(\texttt{f}[v]\) 排序的最小堆,该堆需要相应地更新。
该算法运行时间为 \(O(m \log n)\),因为我们每个顶点处理一次,并且对于每个顶点,我们查看其邻居并可能更新堆中的元素,堆中最多包含 \(n\) 个元素。
引理。 运行上述算法后,\(\texttt{f}[v] = f(v)\)。
证明。 该算法的正确性类似于 Dijkstra 算法的正确性。关键观察是,如果 \(v\) 是当前 \(\texttt{f}[v]\) 值最小的未处理顶点,那么此时我们有 \(\texttt{f}[v] = \max(g(v), \, 1 + \min(f(u)))\),其中最小值取自所有已处理的 \(u\)。由于 \(v\) 的当前 \(\texttt{f}[v]\) 值最小,剩余的未处理顶点无法增加 \(\texttt{f}[v]\) 的值,这意味着 \(\texttt{f}[v]\) 的当前值就是 \(f(v)\)。
计算 \(g\)
让我们从两个快速定义开始。
定义。 用 \(\text{dist}(v, \, u)\) 表示顶点 \(v\) 和 \(u\) 在道路网络图中的距离。
定义。 设 \(b(v)\) 是 \(v\) 的任意一个邻居,使得 \(\text{dist}(v, \, n) = 1 + \text{dist}(b(v), \, n)\),并任意打破平局。
因此,我们可以将 \(g(v)\) 视为从 \(v\) 到 \(n\) 的距离,且该路径不使用边 \(\{v, \, b(v)\}\)。
考虑从 \(n\) 出发的 BFS 树,这等同于说该树由所有 \(v \neq n\) 的边 \(\{v, \, b(v)\}\) 组成,并将树根设在 \(n\)。观察到对应于 \(g(v)\) 的路径必须至少使用一条非树边(否则它将是一条使用 \(\{v, \, b(v)\}\) 的路径,这是无效的)。此外,这样的路径将如下所示:从 \(v\) 开始,沿着以 \(v\) 为根的子树向下走若干步(可能为 \(0\)),然后取一条非树边,该边结束于不在以 \(v\) 为根的子树中的顶点,然后从该顶点取最短路径到 \(n\)。注意到我们可以通过从 \(n\) 运行一次 BFS 来轻松预计算从任何顶点到 \(n\) 的最短路径。
为了证明上述结论,注意到一旦我们离开了以 \(v\) 为根的子树,我们就可以自由地取最短路径到 \(n\),因为它不会使用 \(\{v, \, b(v)\}\) 边。此外,注意到我们不想取一条非树边以结束于 \(v\) 的子树中的另一个顶点,因为我们总是可以取树路径,并且它总是最短的(根据 BFS 树的定义)。
因此,我们需要为每个 \(v\) 计算所有路径中最短的一条,这些路径沿着树向下走若干步,然后取一条非树边,然后取最短路径到 \(n\)。让我们首先看看如何低效地做到这一点,然后我们会使其高效。
对于每个顶点 \(v\),计算所有所需形式的路径列表,并将其存储在集合中(因此每个顶点都有一个集合)。特别是,我们在该集合中存储两件事的对:对应路径到 \(n\) 的距离,以及我们取的非树边的端点。我们可以递归地(以 DFS 的方式)进行此操作,因此让我们首先考虑树的叶子。
如果 \(v\) 是叶子,则路径不能沿着树向下走,因此它的形式是“取一条非树边,然后取最短路径到 \(n\)”。对于每条非树边 \(\{v, \, u\}\),将 \((1 + \text{dist}(u), \, u)\) 添加到集合中。因此,我们现在知道 \(g(v)\) 是集合中的最小元素。
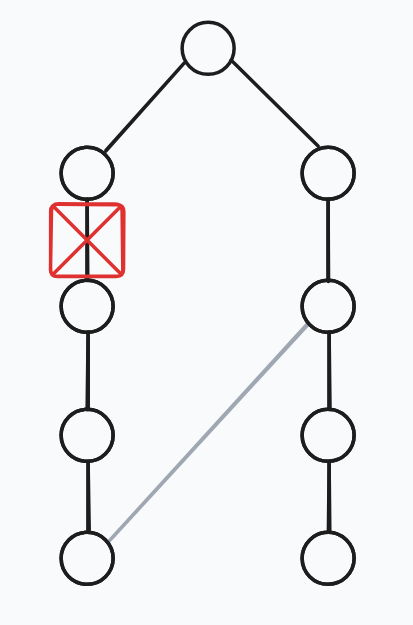
如果 \(v\) 不是叶子,首先递归计算 \(v\) 的所有子节点的距离。通过遍历每条非树边 \(\{v, \, u\}\) 并添加 \((1 + \text{dist}(u), \, u)\) 来初始化 \(v\) 的集合。现在将这个集合与 \(v\) 的所有子节点的集合“合并”。要合并两个集合,我们取子节点集合中的所有对 \((d, \, u)\) 并将 \((d + 1, \, u)\) 添加到 \(v\) 的集合中,这对应于通过从 \(v\) 到它们的边扩展每个子节点的路径。假设最小元素是 \((d, \, u)\)。那么 \(u\) 可能在以 \(v\) 为根的子树中,这是一条无效路径。如果是这种情况,我们从集合中删除 \((d, \, u)\) 并继续删除顶部元素,直到找到一个不在 \(v\) 的子树中的元素。注意到这不会影响 \(v\) 的祖先的计算,因为 \(u\) 也会在它们的子树中。为了确定 \(u\) 是否在 \(v\) 的子树中,我们可以使用 DSU(并查集)。最初,所有顶点都是它们自己的集合,当我们沿着树向下走时,我们将 \(v\) 与其子节点合并。像之前一样,现在我们知道 \(g(v)\) 是剩余集合中的最小元素。
我们几乎完成了,但这里有一个低效的步骤:合并 \(v\) 的子节点的集合可能需要 \(O(n)\) 时间,因为每个集合可能包含多达 \(n\) 个元素。为了高效地实现这一步骤,我们可以进行“小到大合并”,就像 DSU 数据结构中的按大小合并一样。当合并两个集合时,不要动最大的集合,并将最小集合的元素复制到最大集合中。然而,回想一下,当合并两个集合时,我们取子节点集合中的所有对 \((d, \, u)\) 并将 \((d + 1, \, u)\) 添加到 \(v\) 的集合中,因此如果这是子节点的集合之一,我们可能需要更改最大集合中的元素。我们可以通过假设每个集合带有一个“修饰符”来实现这一点,修饰符是一个整数 \(m\),使得如果我们在集合中有一个元素 \((d, \, u)\),则实际距离为 \(d + m\)。直观上,这个修饰符充当“懒传播器”,因此我们不必实际更改子节点集合中的元素。当我们从子节点取一个集合时,我们首先增加其修饰符,然后将其集合与 \(v\) 的集合合并。
此步骤的总运行时间为 \(O(n \log^2 m)\),因为小到大合并确保我们只在集合之间移动元素 \(O(\log m)\) 次,每次移动的成本为 \(O(\log m)\)。