整数集合
整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不时,就会使用整数集这个数据结构作为底层实现。
整数集合结构设计
整数集合本质上是一块连续内存空间,它的结构定义如下:
typedef struct intset {//编码方式uint32_t encoding;//集合包含的元素数量uint32_t length;//保存元素的数组int8_t contents[];
} intset;
可以看到,保存元素的容器是一个 contents 数组,虽然 contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。比如:
-
如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
-
如果 encoding 属性值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组中每一个元素的类型都是 int32_t;
-
如果 encoding 属性值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组中每一个元素的类型都是 int64_t;
不同类型的 contents 数组,意味着数组的大小也会不同。
整数集合的升级操作
整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割,如果 encoding 属性值为 INTSET_ENC_INT16,则每个元素的间隔就是 16 位。
举个例子,假设有一个整数集合里有 3 个类型为 int16_t 的元素。
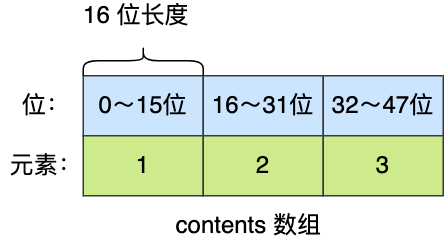
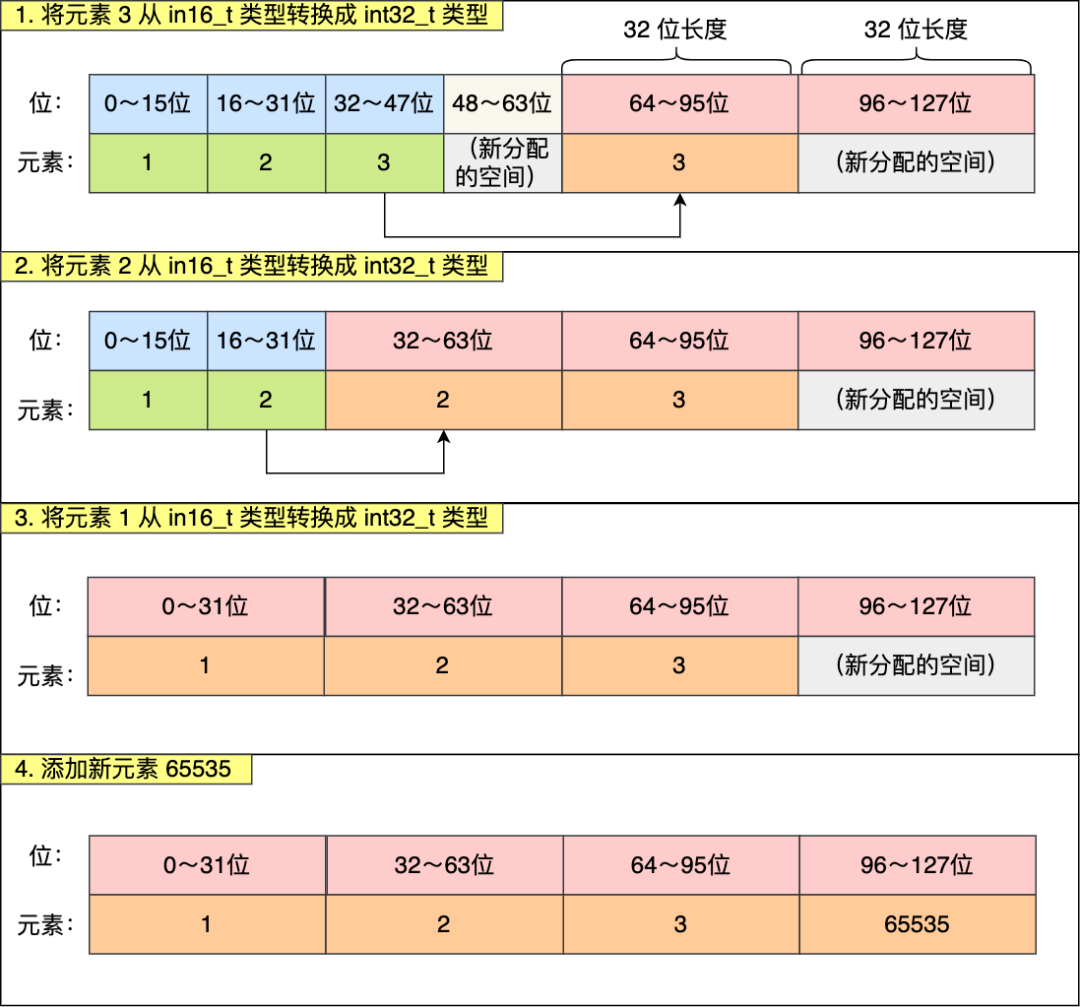
现在,往这个整数集合中加入一个新元素 65535,这个新元素需要用 int32_t 类型来保存,所以整数集合要进行升级操作,首先需要为 contents 数组扩容,在原本空间的大小之上再扩容多 80 位(4x32-3x16=80),这样就能保存下 4 个类型为 int32_t 的元素。

扩容完 contents 数组空间大小后,需要将之前的三个元素转换为 int32_t 类型,并将转换后的元素放置到正确的位上面,并且需要维持底层数组的有序性不变,整个转换过程如下:
整数集合升级有什么好处呢?
如果要让一个数组同时保存 int16_t、int32_t、int64_t 类型的元素,最简单做法就是直接使用 int64_t 类型的数组。不过这样的话,当如果元素都是 int16_t 类型的,就会造成内存浪费的情况。
整数集合升级就能避免这种情况,如果一直向整数集合添加 int16_t 类型的元素,那么整数集合的底层实现就一直是用 int16_t 类型的数组,只有在我们要将 int32_t 类型或 int64_t 类型的元素添加到集合时,才会对数组进行升级操作。
因此,整数集合升级的好处是节省内存资源。
整数集合支持降级操作吗?
不支持降级操作,一旦对数组进行了升级,就会一直保持升级后的状态。比如前面的升级操作的例子,如果删除了 65535 元素,整数集合的数组还是 int32_t 类型的,并不会因此降级为 int16_t 类型。
跳表
Redis 只有在 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。
Zset 对象是唯一一个同时使用了两个数据结构来实现的 Redis 对象,这两个数据结构一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
Zset 对象能支持范围查询(如 ZRANGEBYSCORE 操作),这是因为它的数据结构设计采用了跳表,而又能以常数复杂度获取元素权重(如 ZSCORE 操作),这是因为它同时采用了哈希表进行索引。
跳表结构设计
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表,这样的好处是能快读定位数据。
那跳表长什么样呢?我这里举个例子,下图展示了一个层级为 3 的跳表。
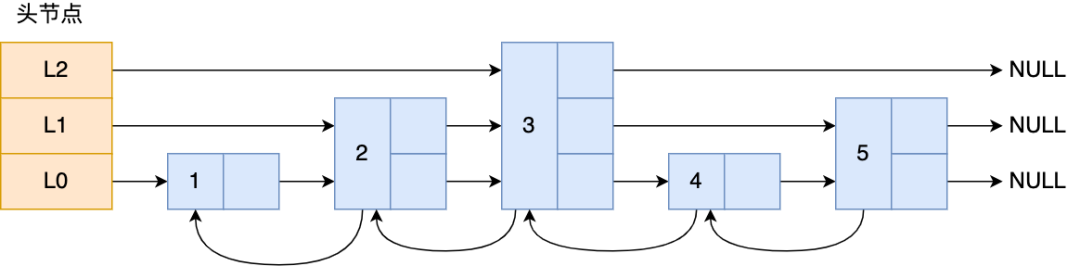
图中头节点有 L0~L2 三个头指针,分别指向了不同层级的节点,然后每个层级的节点都通过指针连接起来:
-
L0 层级共有 5 个节点,分别是节点1、2、3、4、5;
-
L1 层级共有 3 个节点,分别是节点 2、3、5;
-
L2 层级只有 1 个节点,也就是节点 3 。
如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次,而使用了跳表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再往前遍历找到节点 4。
可以看到,这个查找过程就是在多个层级上跳来跳去,最后定位到元素。当数据量很大时,跳表的查找复杂度就是 O(logN)。
那跳表节点是怎么实现多层级的呢?这就需要看「跳表节点」的数据结构了,如下:
typedef struct zskiplistNode {//Zset 对象的元素值sds ele;//元素权重值double score;//后向指针struct zskiplistNode *backward;//节点的level数组,保存每层上的前向指针和跨度struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span;} level[];
} zskiplistNode;
Zset 对象要同时保存元素和元素的权重,对应到跳表节点结构里就是 sds 类型的 ele 变量和 double 类型的 score 变量。每个跳表节点都有一个后向指针,指向前一个节点,目的是为了方便从跳表的尾节点开始访问节点,这样倒序查找时很方便。
跳表是一个带有层级关系的链表,而且每一层级可以包含多个节点,每一个节点通过指针连接起来,实现这一特性就是靠跳表节点结构体中的zskiplistLevel 结构体类型的 level 数组。
level 数组中的每一个元素代表跳表的一层,也就是由 zskiplistLevel 结构体表示,比如 leve[0] 就表示第一层,leve[1] 就表示第二层。zskiplistLevel 结构体里定义了「指向下一个跳表节点的指针」和「跨度」,跨度时用来记录两个节点之间的距离。
比如,下面这张图,展示了各个节点的跨度。

第一眼看到跨度的时候,以为是遍历操作有关,实际上并没有任何关系,遍历操作只需要用前向指针就可以完成了。
跨度实际上是为了计算这个节点在跳表中的排位。具体怎么做的呢?因为跳表中的节点都是按序排列的,那么计算某个节点排位的时候,从头节点点到该结点的查询路径上,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的排位。
举个例子,查找图中节点 3 在跳表中的排位,从头节点开始查找节点 3,查找的过程只经过了一个层(L3),并且层的跨度是 3,所以节点 3 在跳表中的排位是 3。
另外,图中的头节点其实也是 zskiplistNode 跳表节点,只不过头节点的后向指针、权重、元素值都会被用到,所以图中省略了这部分。
问题来了,由谁定义哪个跳表节点是头节点呢?这就介绍「跳表」结构体了,如下所示:
typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;
} zskiplist;
跳表结构里包含了:
-
跳表的头尾节点,便于在O(1)时间复杂度内访问跳表的头节点和尾节点;
-
跳表的长度,便于在O(1)时间复杂度获取跳表节点的数量;
-
跳表的最大层数,便于在O(1)时间复杂度获取跳表中层高最大的那个节点的层数量;
跳表节点查询过程
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
-
如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
-
如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
举个例子,下图有个 3 层级的跳表。

如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
-
先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
-
但是该层上的下一个节点是空节点,于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
-
「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
-
「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
跳表节点层数设置
跳表的相邻两层的节点数量的比例会影响跳表的查询性能。
举个例子,下图的跳表,第二层的节点数量只有 1 个,而第一层的节点数量有 6 个。

这时,如果想要查询节点 6,那基本就跟链表的查询复杂度一样,就需要在第一层的节点中依次顺序查找,复杂度就是 O(N) 了。所以,为了降低查询复杂度,我们就需要维持相邻层结点数间的关系。
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)。
下图的跳表就是,相邻两层的节点数量的比例是 2 : 1。

那怎样才能维持相邻两层的节点数量的比例为 2 : 1 呢?
如果采用新增节点或者删除节点时,来调整跳表节点以维持比例的方法的话,会带来额外的开销。
Redis 则采用一种巧妙的方法是,跳表在创建节点的时候,随机生成每个节点的层数,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是,跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。
这样的做法,相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。
quicklist
在 Redis 3.0 之前,List 对象的底层数据结构是双向链表或者压缩列表。然后在 Redis 3.2 的时候,List 对象的底层改由 quicklist 数据结构实现。
其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
在前面讲压缩列表的时候,我也提到了压缩列表的不足,虽然压缩列表是通过紧凑型的内存布局节省了内存开销,但是因为它的结构设计,如果保存的元素数量增加,或者元素变大了,压缩列表会有「连锁更新」的风险,一旦发生,会造成性能下降。
quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
quicklist 结构设计
quicklist 的结构体跟链表的结构体类似,都包含了表头和表尾,区别在于 quicklist 的节点是 quicklistNode。
typedef struct quicklist {//quicklist的链表头quicklistNode *head; //quicklist的链表头//quicklist的链表头quicklistNode *tail; //所有压缩列表中的总元素个数unsigned long count;//quicklistNodes的个数unsigned long len; ...
} quicklist;
接下来看看,quicklistNode 的结构定义:
typedef struct quicklistNode {//前一个quicklistNodestruct quicklistNode *prev; //前一个quicklistNode//下一个quicklistNodestruct quicklistNode *next; //后一个quicklistNode//quicklistNode指向的压缩列表unsigned char *zl; //压缩列表的的字节大小unsigned int sz; //压缩列表的元素个数unsigned int count : 16; //ziplist中的元素个数 ....
} quicklistNode;
可以看到,quicklistNode 结构体里包含了前一个节点和下一个节点指针,这样每个 quicklistNode 形成了一个双向链表。但是链表节点的元素不再是单纯保存元素值,而是保存了一个压缩列表,所以 quicklistNode 结构体里有个指向压缩列表的指针 *zl。
我画了一张图,方便你理解 quicklist 数据结构。
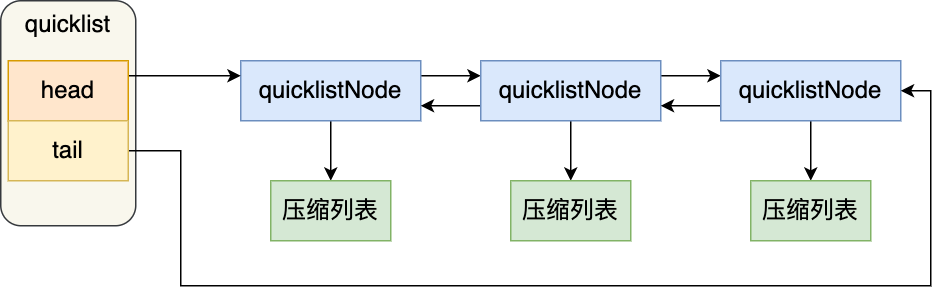
在向 quicklist 添加一个元素的时候,不会像普通的链表那样,直接新建一个链表节点。而是会检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到 quicklistNode 结构里的压缩列表,如果不能容纳,才会新建一个新的 quicklistNode 结构。
quicklist 会控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来规避潜在的连锁更新的风险,但是这并没有完全解决连锁更新的问题。
listpack
quicklist 虽然通过控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来减少连锁更新带来的性能影响,但是并没有完全解决连锁更新的问题。
因为 quicklistNode 还是用了压缩列表来保存元素,压缩列表连锁更新的问题,来源于它的结构设计,所以要想彻底解决这个问题,需要设计一个新的数据结构。
于是,Redis 在 5.0 新设计一个数据结构叫 listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
listpack 结构设计
listpack 采用了压缩列表的很多优秀的设计,比如还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点会采用不同的编码方式保存不同大小的数据。
我们先看看 listpack 结构:

listpack 头包含两个属性,分别记录了 listpack 总字节数和元素数量,然后 listpack 末尾也有个结尾标识。图中的 listpack entry 就是 listpack 的节点了。
每个 listpack 节点结构如下:
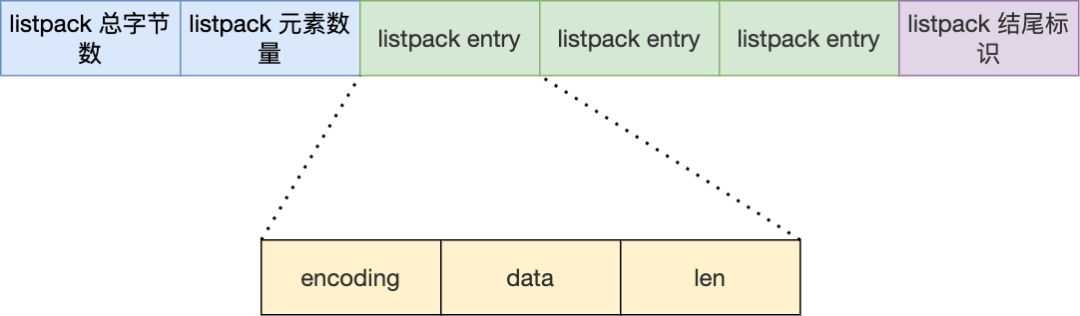
主要包含三个方面内容:
-
encoding,定义该元素的编码类型,会对不同长度的整数和字符串进行编码;
-
data,实际存放的数据;
-
len,encoding+data的总长度;
可以看到,listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。


![【java】【项目实战】[外卖九]项目优化(缓存)](https://img-blog.csdnimg.cn/3dd4b4f783c043d0b9a6091f1b91eeb1.png)