一、安装JDK
1、创建文件夹tools和training用于存放压缩包和解压使用,tools存放压缩包,training用于解压后安装jdk和hadoop的路径。
1)回到路径为 / 的位置
cd /

2) 创建 tools 和 training
mkdir tools
mkdir training
3) 进入tools文件夹
cd tools

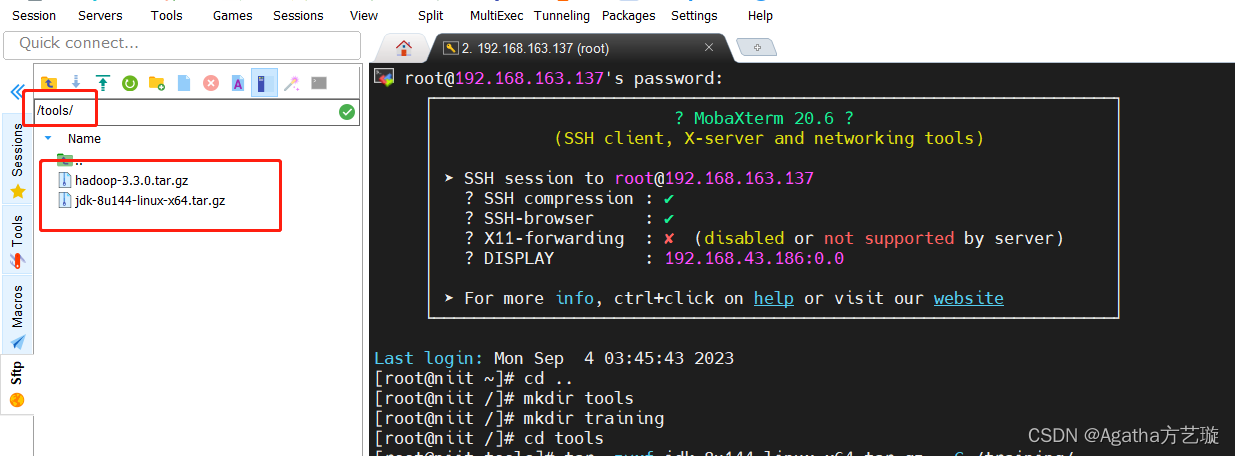
4) 左边mobaxterm里面点击进入/tools文件夹,将发给大家的压缩包直接鼠标拖入进去,拖的是tar.gz压缩包,不要在电脑里面解压过了!,拖的时候有进度条,上传完后如图所示
2、JDK解压
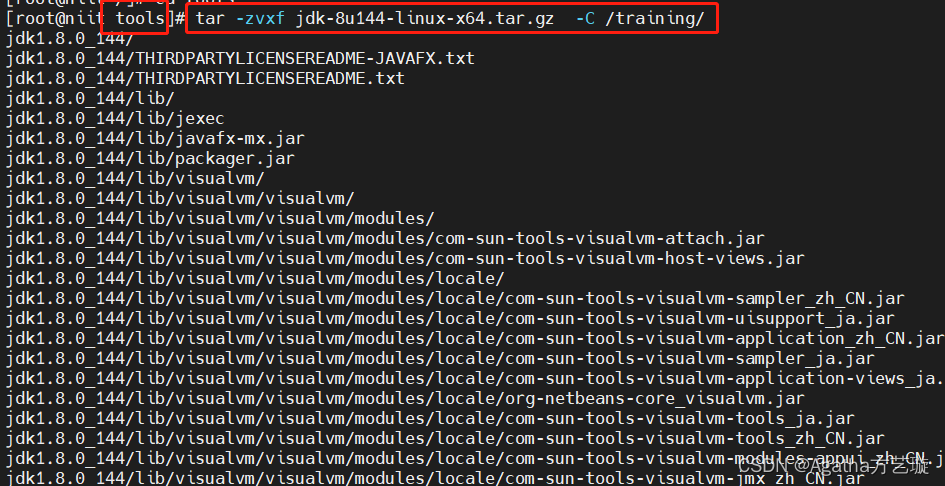
1) 在控制台输入以下命令,将文件解压至training文件夹,如图所示,路径在tools里面,会有一堆进度条,等他运行停止以后进行下一步
tar -zvxf jdk-8u144-linux-x64.tar.gz -C /training/
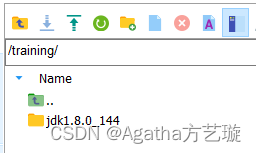
2) 查看mobaxterm左边,点击文件夹进到training里面查看解压情况,有这个文件夹了就说明解压成功了。
3、JDK安装
1)控制台输入此命令回车进行环境配置
vi ~/.bash_profile

2) 进入文件后是不可编辑的阅读状态,使用键盘上下左右键将光标移动到蓝色的export PATH 的H上面,按一下电脑的 i 键盘,进入编辑模式,按右键挪到H的后面,然后回车两次,在进行下一步。

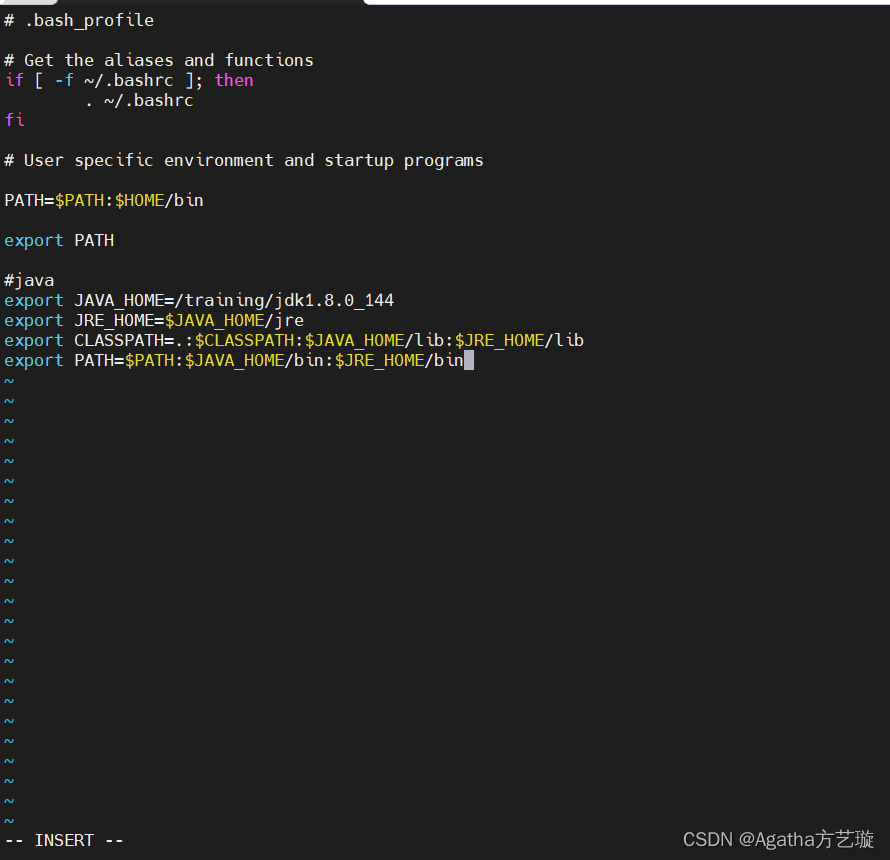
3) 在文件中添加此配置,直接复制粘贴,若java版本不是从我这下的,和我不同,请自行在配置里更改版本编号144,具体如图
#java
export JAVA_HOME=/training/jdk1.8.0_144
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
4) 按一下esc退出编辑模式
5) 输入 冒号wq,然后回车, 不可复制,直接键盘自己输,此操作是保存文件并退出,w是保存,q是退出,后面不会讲这么细,忘记可以翻回来看,如果不下心改错了,不想保存退出,则使用 :wq! ,就是不保存退出。
:wq

6) 环境变量更改以后,需要让他生效,所以输入一下命令让环境变量生效。
source ~/.bash_profile

7) 输入此命令,检查java是否安装完毕,如果弹出对应版本信息则成功安装java。
java -version

二、安装Hadoop
1、关闭centos的防火墙,不然影响后面hadoop远程连接
systemctl stop firewalld.service

systemctl disable firewalld.service

2、更改主机名为niit和我一样,方便后续文件直接复制粘贴不用更改,更改后不会马上显示,关掉mobaxterm重新连接一下就好了。
hostnamectl --static set-hostname niit
3、配置映射关系
1)进入centos的hosts映射文件
vi /etc/hosts
2)添加ip编号 空格 主机名
(每个人ip都不一样,自己用自己的)
具体怎么添加的参考上面的详细环境变量文件更改和保存操作,一样的。
192.168.163.137 niit

3):wq保存退出
:wq
4、配置另一个映射文件
1)进入文件
vi /etc/sysconfig/network
2)添加主机名在这个文件里
niit
3) :wq 保存退出
:wq
5、进入/tools文件夹
cd /tools
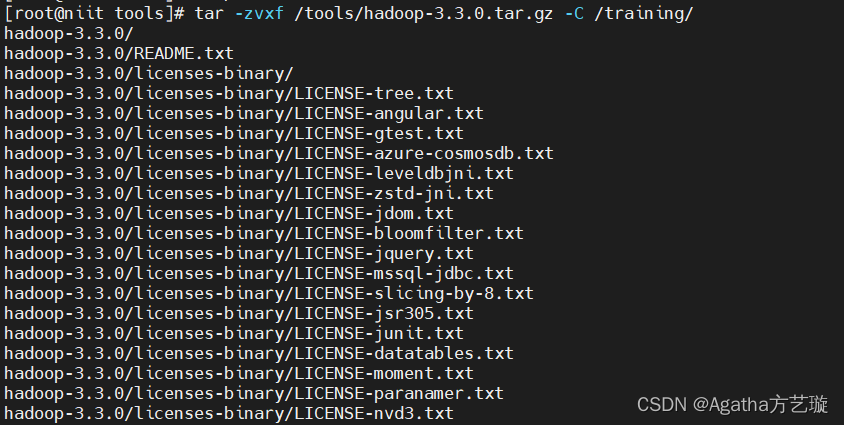
6、解压hadoop压缩包到training文件夹
tar -zvxf /tools/hadoop-3.3.0.tar.gz -C /training/

7、Hadoop环境配置
1)再次进入环境变量配置文件
vi ~/.bash_profile
2)添加如下配置,别动到之前的java,在后面换行添加就行
#hadoop
export HADOOP_HOME=/training/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
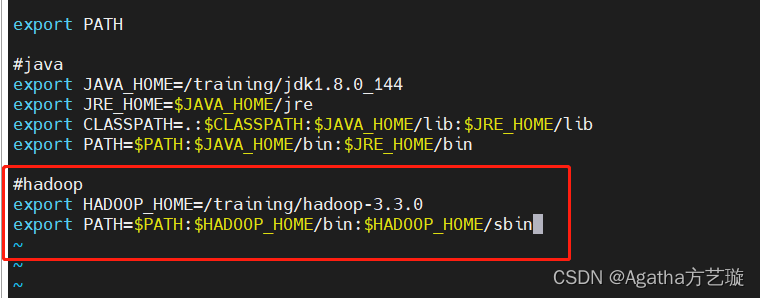
3):wq保存退出
4)生效环境变量
source ~/.bash_profile

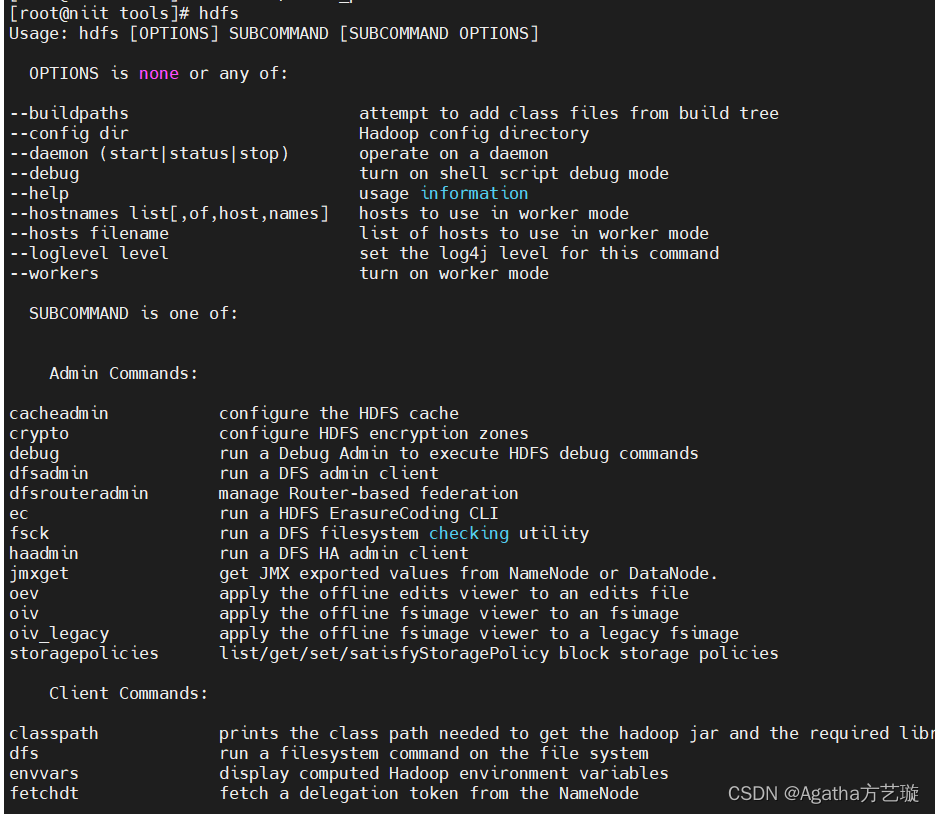
5)输入hdfs检查hadoop是否安装成功,如果有这些东西出来了,说明成功安装,接下来去进行hadoop配置文件的配置。
hdfs
三、Hadoop免密登录配置
1、创建免密登录数据存放文件
1)在hadoop安装路径下创建一个tmp文件夹用于存放配置数据
mkdir /training/hadoop-3.3.0/tmp

2、免密配置
1)进行hadoop ssh免密配置
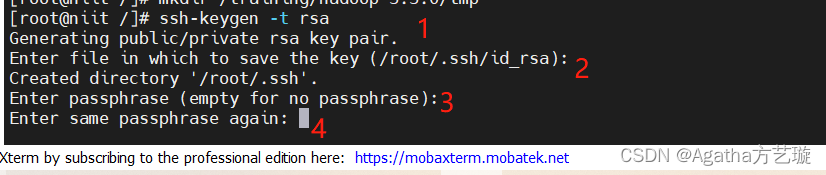
a、输入以下代码,回车四次,什么都不要输入,快速回车4次,然后你会得到一个密码图形,每个人不一样,不用看我的图,有图形就好了
ssh-keygen -t rsa
b、输入以下命令
cd ~/.ssh/

c、输入以下命令(niit是主机名,和我不一样得换自己的)
具体如图所示
ssh-copy-id -i id_rsa.pub root@niit

四、Hadoop5个配置文件设置
1、进入Hadoop配置文件地址
cd /training/hadoop-3.3.0/etc/hadoop/
2、第一个配置文件:hadoop-env.sh,用于设置jdk的
1)输入命令进入编辑
vi hadoop-env.sh

2)进去后长这样
3)往下滑动鼠标找到
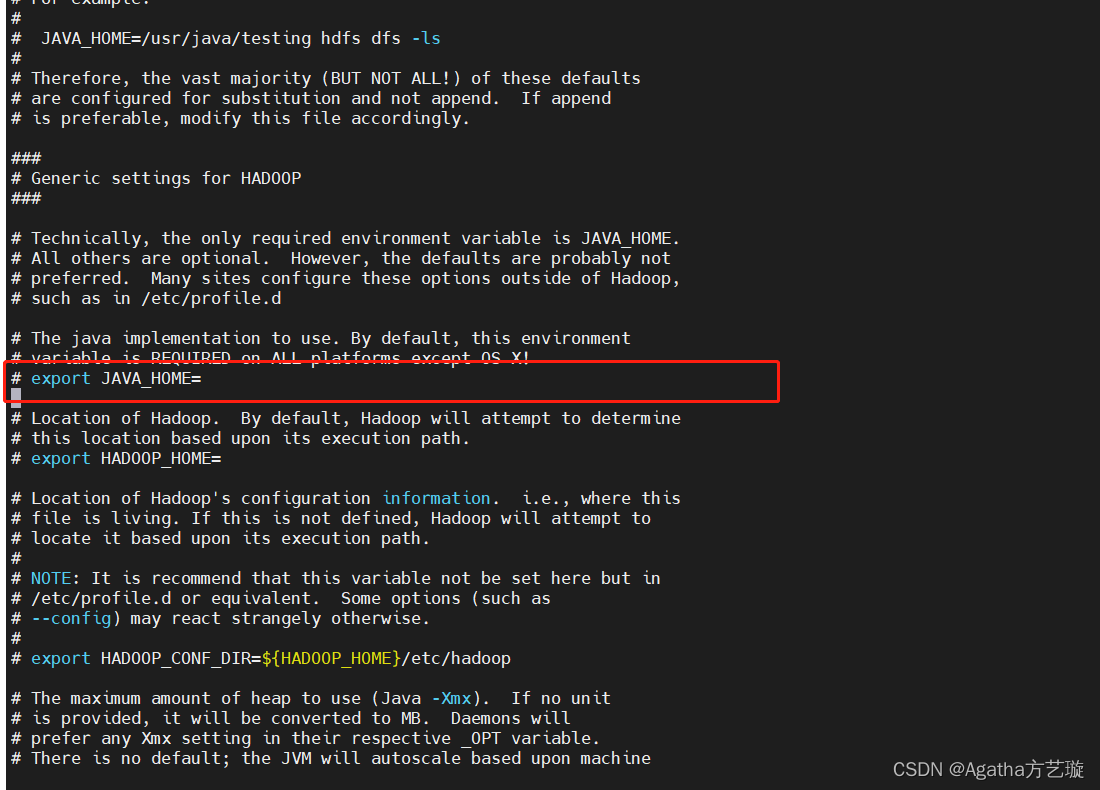
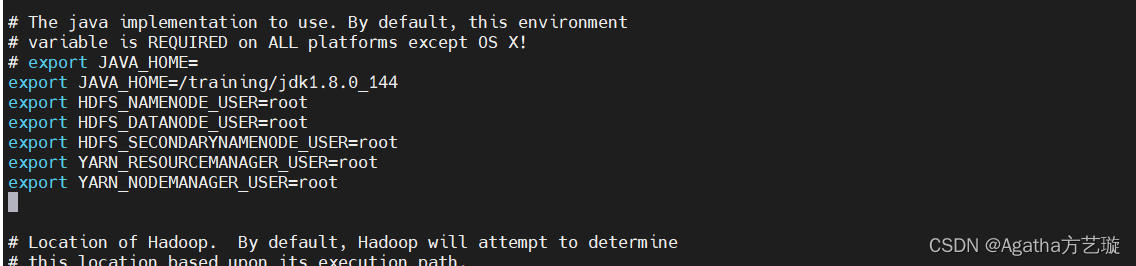
4)进入编辑模式,在这一行下面一行添加此内容
export JAVA_HOME=/training/jdk1.8.0_144
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
5):wq保存退出
3、第二个配置文件:hdfs-site.xml,用于设置权限和数据块备份数量
1)进入文件
vi hdfs-site.xml

2)进去长这样,在两个configuration中间添加配置
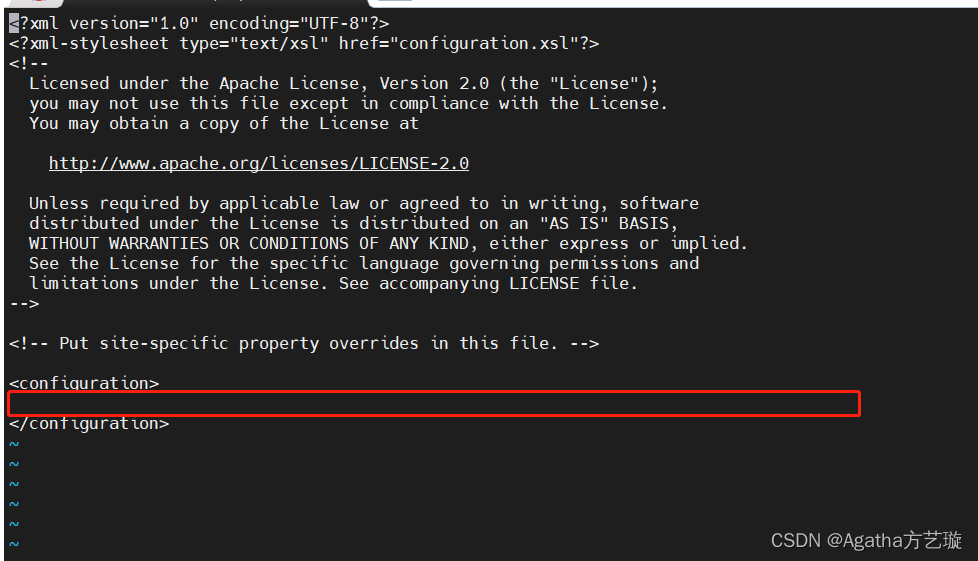
3)进入编辑模式添加内容
<property><name>dfs.replication</name><value>1</value>
</property>
<property><name>dfs.permissions</name><value>false</value>
</property>
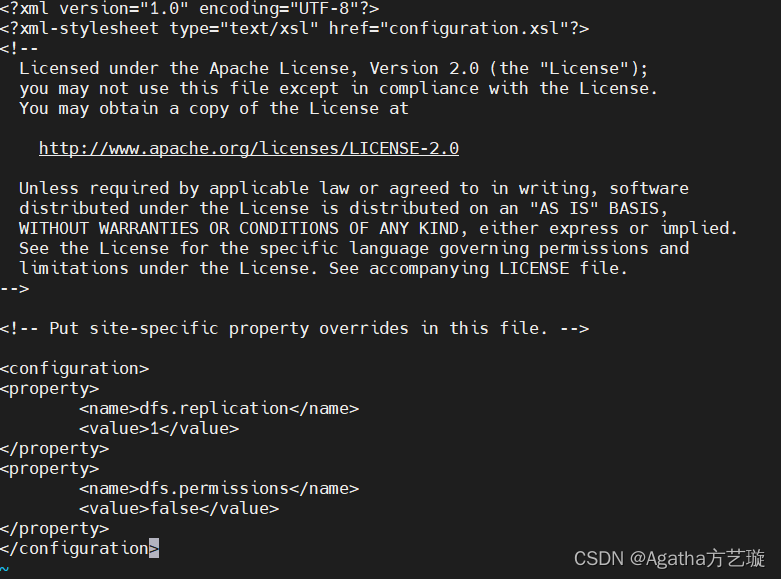
4):wq保存退出
4、第三个配置文件:core-site.xml,用于设置主节点和临时文件夹
1)进入文件
vi core-site.xml

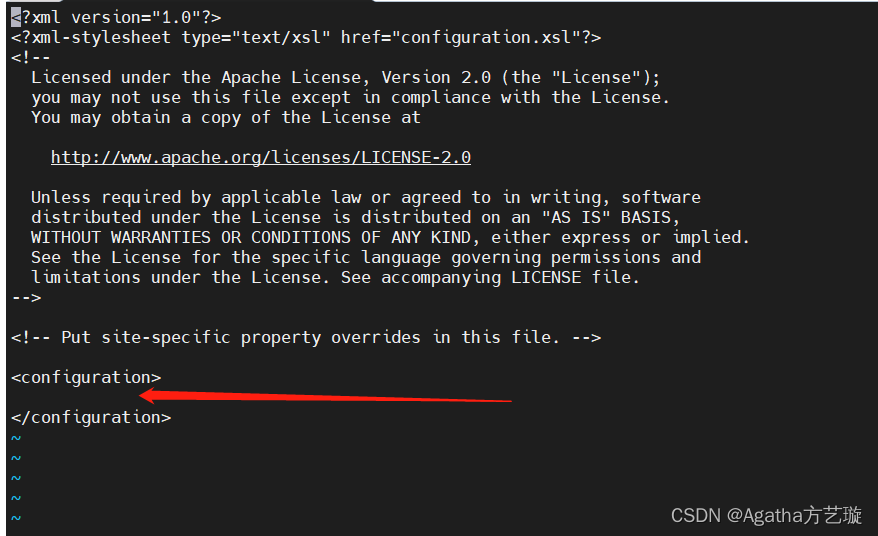
2)进去长这样,在configuration中间加
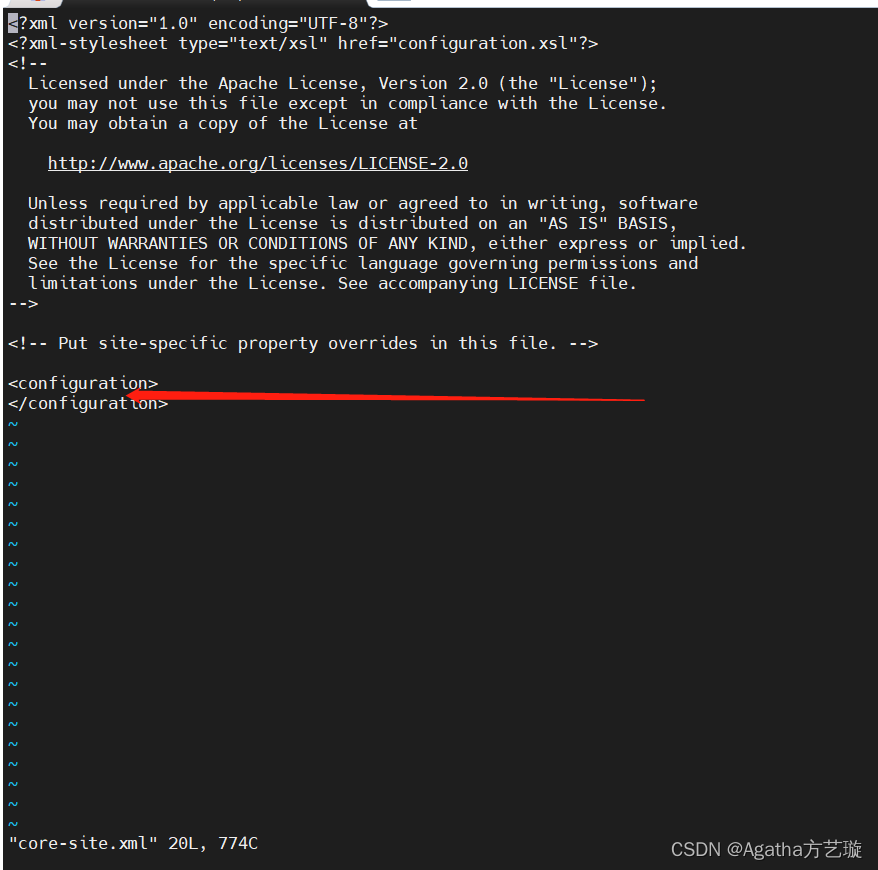
3)添加内容,niit是主机名,不一样记得改,8020不用动
<property><name>fs.defaultFS</name><value>hdfs://niit:8020</value>
</property>
<property><name>hadoop.tmp.dir</name><value>/training/hadoop-3.3.0/tmp</value>
</property>
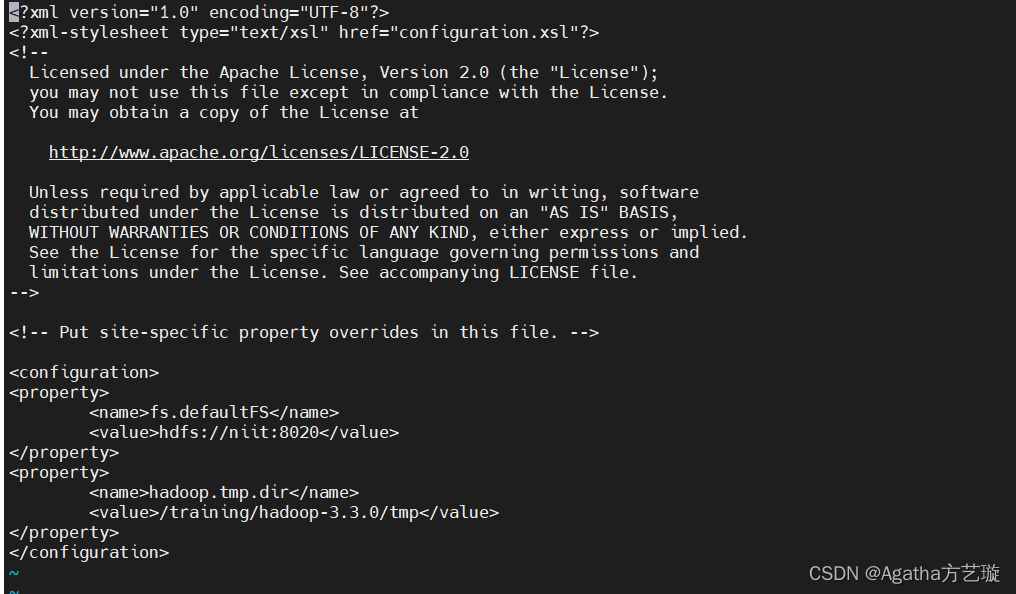
4):wq保存退出
5、第四个配置文件:mapred-site.xml,用于设置mapreduce的运行环境
1)进入文件
vi mapred-site.xml

2)进去长这样,在configuration中间加
3)添加内容
<property> <name>mapreduce.framework.name</name><value>yarn</value>
</property>
6、第五个配置文件:yarn-site.xml,用于设置yarn
1)进入文件
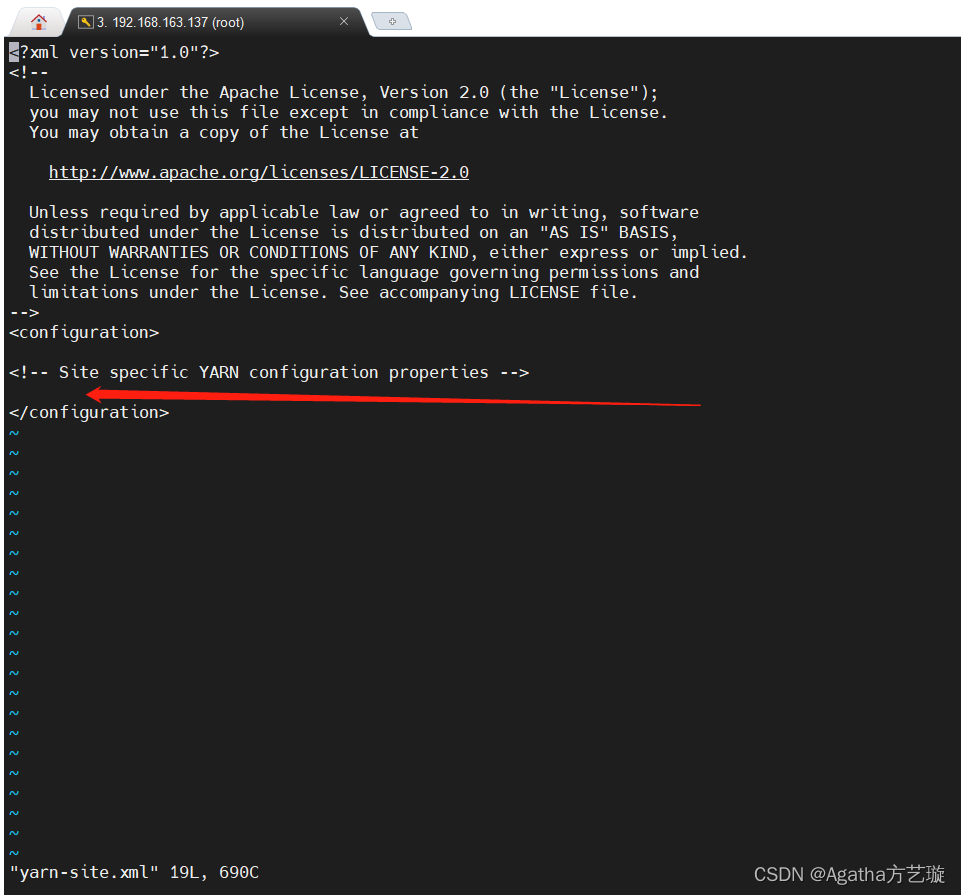
vi yarn-site.xml

2)进入长这样,在箭头处添加
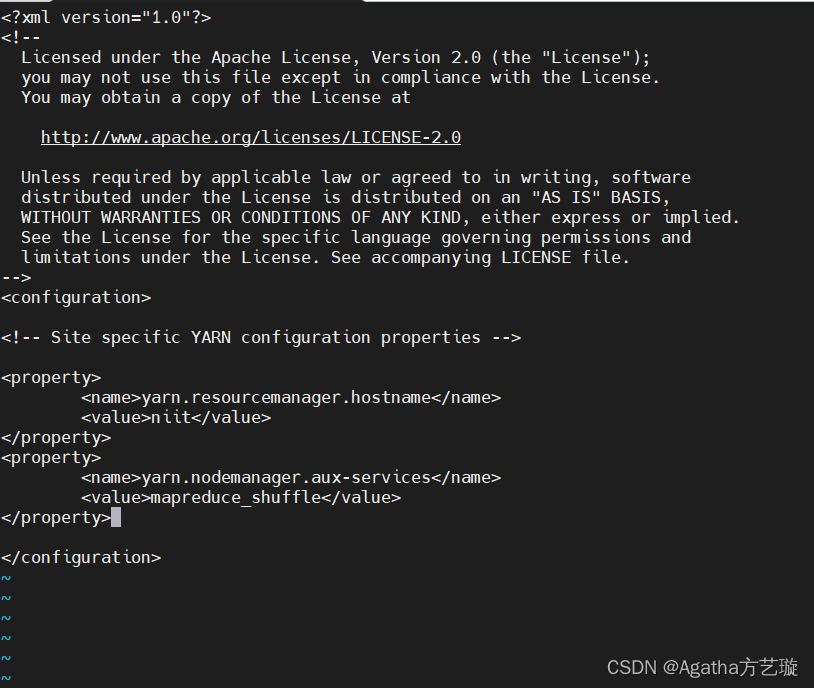
3)添加内容
<property><name>yarn.resourcemanager.hostname</name><value>niit</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
4):wq保存退出
五、Hadoop格式化主节点
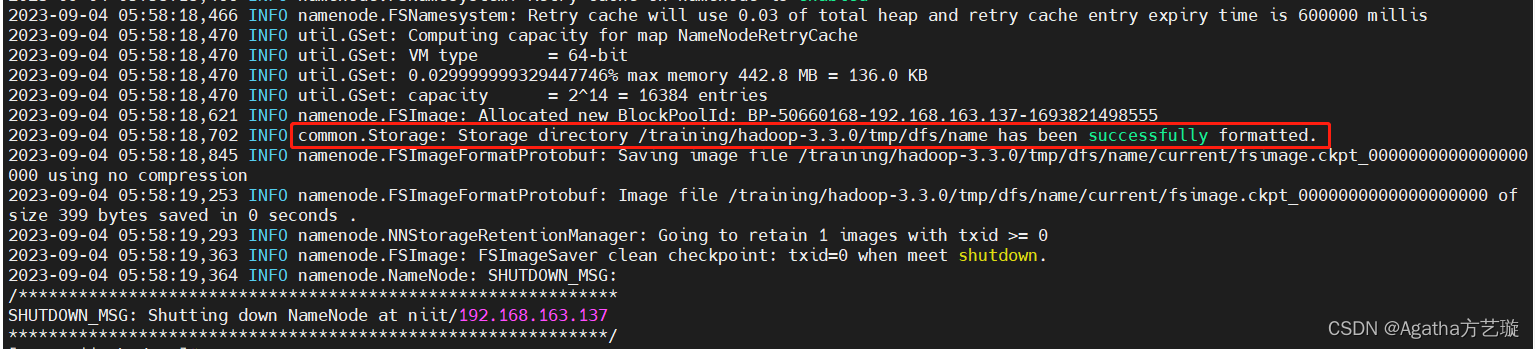
hdfs namenode -format
#注意: 如果格式化成功,你可以看到如下信息:
common.Storage: Storage directory /training/hadoop-3.3.0/tmp/dfs/name has been successfully formatted.
六、Hadoop启动与关闭
1、启动Hadoop
1)启动命令
start-all.sh
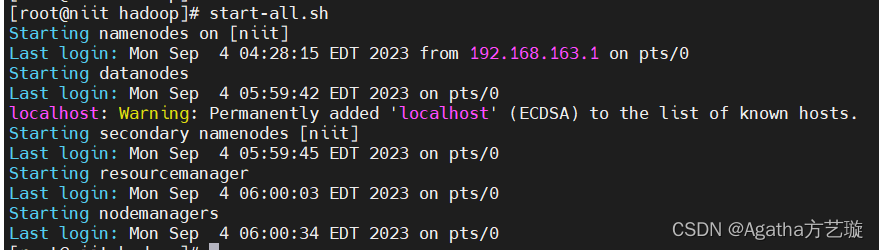
2)是否启动成功进程检查
jps
成功会有5个进程,1个jps进程
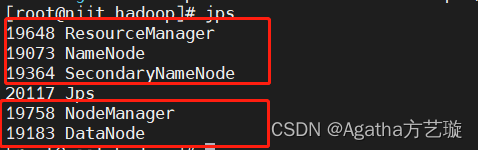
如果成功看到5个hadoop进程恭喜你成功了,只要少了任何一个进程说明上述所有步骤一点点小问题都会有影响,从头检查一遍。
2、关闭Hadoop
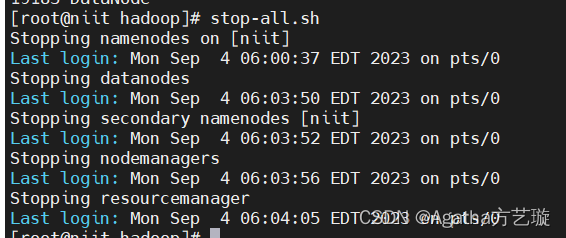
stop-all.sh




![java八股文面试[多线程]——CompletableFuture](https://img-blog.csdnimg.cn/img_convert/d039c7beedf24de3dd72bf4118b4fc9f.png)