夕小瑶科技说 原创
作者 | 王思若
LLaMA、GPT-3等大型语言模型实现了对自然语言强大的理解和推理能力,为AI社区构筑了强大的语言基座模型。进而,继续迭代的GPT-4,更是赋予了模型处理图像的视觉能力。
如今,构建强大的多模态模型已经成为了社区的共识,BLIP2、LLaVA、MiniGPT-4、mPLUG-Owl、InstructBLIP等大量的视觉语言模型(Vision-Language Models,LVLMs)犹如井喷式被相继提出。
现有视觉语言模型是否真正对齐了图像和文本模态呢?究竟哪种视觉语言模型能力更优秀呢?
现有视觉语言模型孰强孰弱无疑是研究者关注的焦点,上海人工智能实验室构建了评估基准LVLM-eHub对包括InstructBLIP和MiniGPT-4等八种视觉文本模型进行了综合性评估。
研究发现,现有的如InstructBLIP等指令微调视觉语言模型,严重过拟合于现有任务,在真实场景中的泛化能力表现很差。此外,模型极容易出现对象幻觉问题,生成图像中并未出现的物体描述。
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
Hello, GPT4!
论文题目:
LVLM-eHub: A Comprehensive Evaluation Benchmark for Large Vision-Language Models
论文地址:
https://arxiv.org/pdf/2306.09265.pdf
一、构建六类多模态定量性能评估数据集,并搭建模型互动评测平台
LVLM-eHub由定量能力评估和在线互动评测平台组成,具体来说,一方面定量能力评估在47个标准视觉语言基准数据集上广泛评估LVLM在视觉感知、视觉知识获取、视觉推理、视觉常识、对象幻觉和具身智能6类多模态能力。
另一方面,搭建在线互动评测平台以众包的方式对视觉语言模型进行匿名随机成对对战,在开放世界的问答场景中提供用户层面的模型排名。
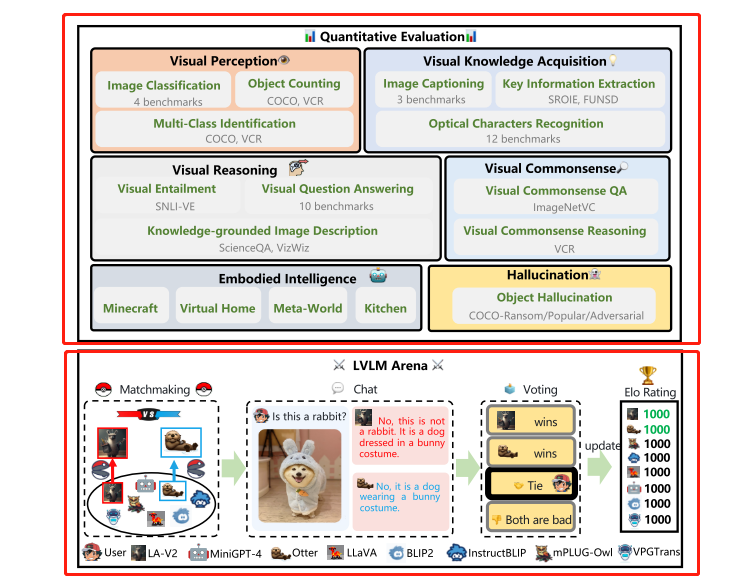
视觉感知: 视觉感知是识别图像中的场景或物体的能力,是人类视觉系统的初级能力。包括图像分类任务,多类识别和物体计数任务。
视觉知识获取: 视觉知识获取需要超越感知来理解图像并获取知识。包括光学字符识别、关键信息抽取和图像描述任务。
视觉推理: 视觉推理需要全面理解图像及相关文本。为评估LVLM的视觉推理能力,包括三个任务,包括视觉问答(VQA)、视觉蕴含和基于知识的图像描述任务。
视觉常识: 这项评估通过使用ImageNetVC和视觉常识推理(VCR)来测试模型对通用共享人类知识的理解。具体来说,ImageNetVC用于零样本视觉常识评估,如颜色和形状,而VCR涵盖各种场景,如空间、因果和心理常识。
对象幻觉: 视觉语言模型存在对象幻觉问题,即生成的描述对象与目标图像不一致,本文在MSCOCO数据集上评估视觉语言模型的对象幻觉问题。
具身智能: 具身智能旨在创建人形机器人,并让他们学习解决需要环境交互的复杂任务,本文利用EmbodiedGPT中的高级任务作为基准。
本文调查视觉语言模型在各类新任务上的零样本能力来评估上述六类能力,具体而言,本文将零样本评估视为不同任务形式的提示工程:
-
问答:设计适当的视觉问题提示来确保视觉语言模型生成有意义的结果,例如,“what is written in the image” 来作为OCR任务的文本提示。
-
基于前缀的分数:对于多选选择任务,对给定图像一定的视觉提示,让模型生成图像和文本的似然度,把生成最大似然度结果的视觉提示作为答案。
-
多轮推理:利用诸如ChatGPT之类的LLM为给定问题生成子问题,视觉语言模型提供相应的子答案,另一个LLM评估子答案的质量。通过这样的流程迭代进行,直到获得满意的答案或达到预定义的最大迭代次数。
-
用户投票:让人类评估视觉语言模型在特定上下文中生成文本的质量、相关性和有用性。为了保持评估的公平性,本文会在评估过程中随机打乱模型输出顺序并对输出进行匿名化。
更有意思的,研究还搭建了视觉语言模型互动评测平台,让模型按照锦标赛的形式进行配对,用户可以使用图像和文本输入分别和配对的模型就任何话题进行聊天,模型真实世界的条件。在聊天阶段之后,用户为模型进行投票,让用户作为裁判,这可以带来比传统评估指标更有说服力的评估结果。
让多模态模型来一场‘宝可梦世界锦标赛’,就是你了,皮卡丘,LLaVA模型~

二、现有视觉语言模型的测评结果
文章对8个代表性模型进行了测评,包括BLIP2,LLaVA,LLaMA-Adapter V2,MiniGPT-4,mPLUG-Owl,Otter,InstructBLIP和VPGTrans。
各大模型在六大类任务上都取得了相对不错的零样本能力,尤其是InstructBLIP更是近乎在所有任务取得了远超其他模型的性能表现。
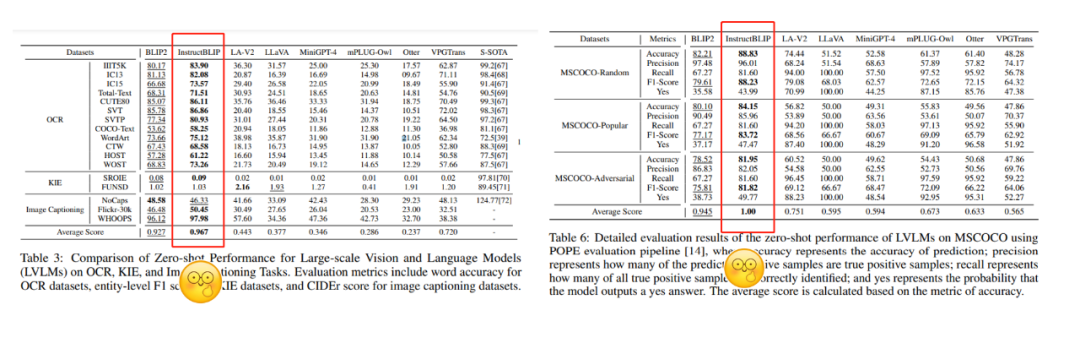
InstructBLIP在各种任务上都取得了远超其他模型的性能表现
但作者悲观的指出,这种优越的性能表现究其原因是模型过拟合的表现。
一方面,InstructBLIP在160万VQA数据集上进行了指令微调,远超过其他视觉语言模型,因此,在现存的in-domain任务中定量评估中表现及其良好,另一方面,在接近真实场景的在线互动评测中,反而InstructBLIP要比其他模型差很多,反而mPLUG-Owl和MiniGPT-4性能表现最好。
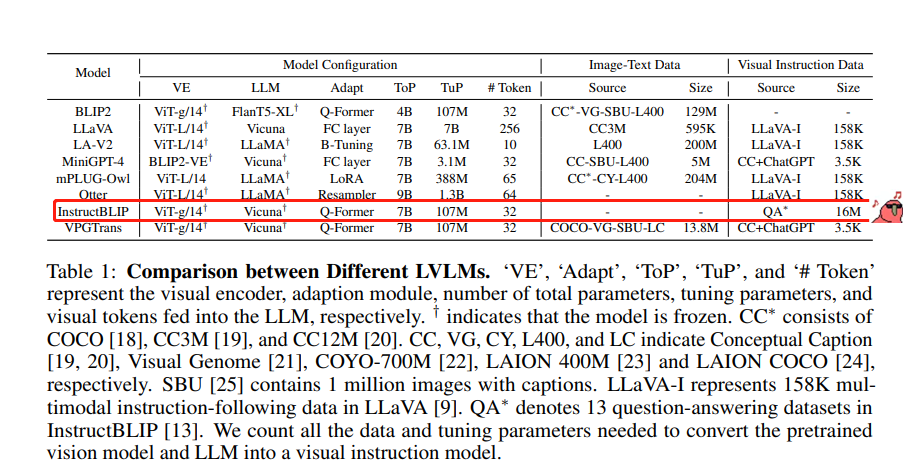
8大视觉语言模型的指令微调数据集

InstructBLIP在接近真实场景的在线互动评测中,表现很差,反而其他的例如mPLUG-Owl, MiniGPT-4, Otter等模型性能表现不错。
好消息,更大规模的指令微调数据集可以提升模型在in-domain任务上的性能表现,但坏消息,模型对这些数据验证过拟合了,因此,如何构建强大以及更广泛通用性的视觉语言模型依然有很长的路去走!

![java八股文面试[JVM]——引用计数、可达性分析](https://img-blog.csdnimg.cn/img_convert/582be914045767b5f667377b0cfbf8c2.png)