1.目的是什么
当我们找到一个算法去计算某些东西的时候,我们通常要对这个算法进行一定的分析,比如时间复杂度,空间复杂度(前者更加重要),来进行比较,判断一个算法的优劣性.
对于一个训练的模型来说,同样需要某种模型来进行分析,例如代价函数等等,通过比较拟合程度,正确精度等信息来判断出这个模型的好坏,从而选择更好的模型
2.对于模型的评价
(1)测试集,训练集
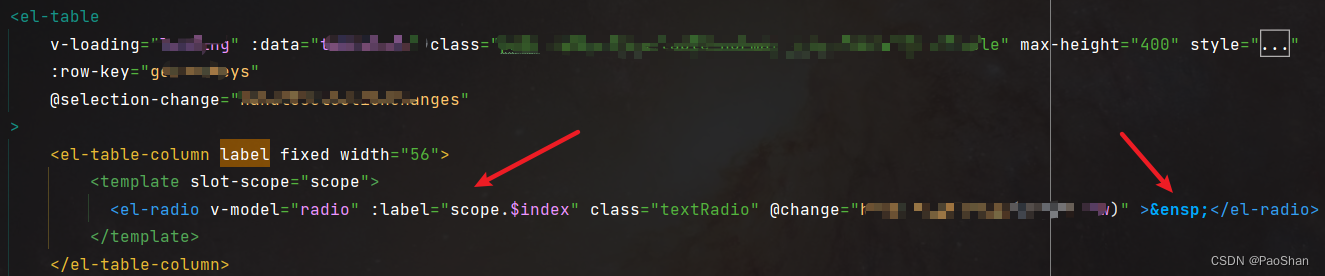
对于一个数据集合来说,我们最长做的一件事就是把集合划分,一部分集合用来训练数据,而另一部分集合用来测试我们拟合的结果(其实就是让训练好的集合去预测没见过的数据,就能检测出我们模型的拟合效果)这是肥肠常用的一种方法

如上图所示,我们把前面70%的数据单独取出来.作为训练模型和用到的数据.而剩下的30%,则称之为验证集合.
和前面一样,我们通过最小化训练集合的代价函数,来让这个模型处于"最佳状态"
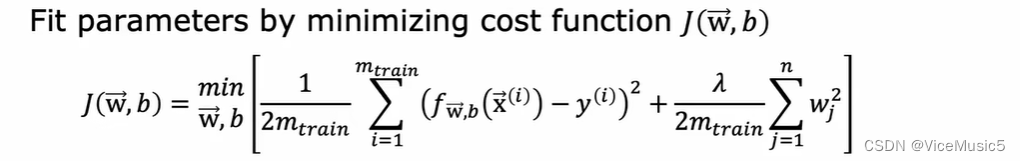 达到最佳状态以后,我们可以分别计算对于测试集合和训练集合的拟合效果,使用不用惩罚参数的代价函数来进行衡量(最小二乘error)
达到最佳状态以后,我们可以分别计算对于测试集合和训练集合的拟合效果,使用不用惩罚参数的代价函数来进行衡量(最小二乘error)
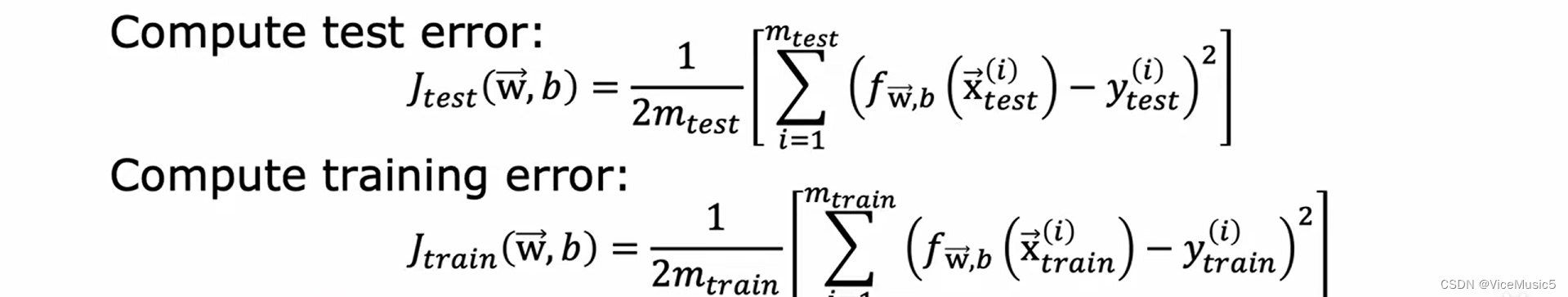 其中我们主要关注test error 的数值,这个一般反映了函数对于未曾见过的数据的预测效果
其中我们主要关注test error 的数值,这个一般反映了函数对于未曾见过的数据的预测效果
(2)交叉验证集合
有时候单独的一个测试集合效果可能不是很好,因为单一验证集合可能因为种种原因产生'过于乐观'的情况,即在验证集合上的效果可能会比实际应用会好很多.
为了避免这种情况,也为了验证能更加有效,在这两个集合的基础上,我们又划分出一些数据,称之为交叉验证集合(cross validation validation是验证的意思,这里也可以称之为cv)

使用交叉验证集合,让数据具有更多颗粒度和隔离性,尽量从多个角度去测试一个模型的效果 ,通俗点可以理解为:多测试几次
我们使用Jcv来实现对于交叉测试集合的状态评估
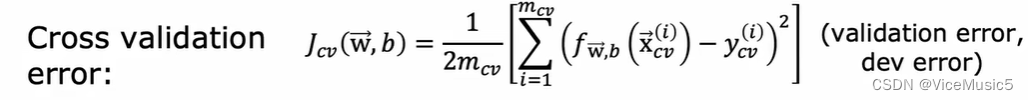
在下面我们会主要使用Jcv来统称所有的测试集合, 将训练集合和交叉验证集合进行配合,我们客体分析出一些情况.
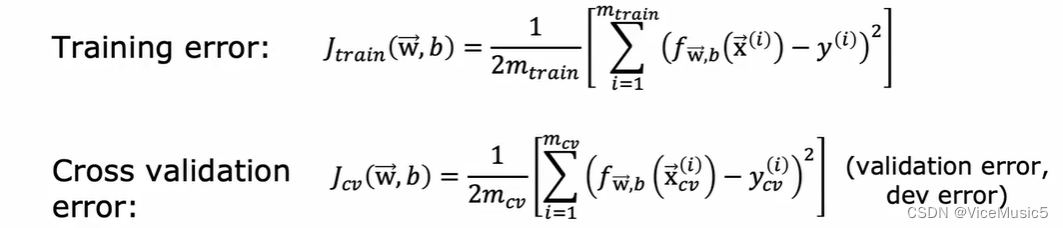
(3)偏差bias和方差variance
模型在有些时候效果不太理想,其原因可能是就是这两种
高偏差bias,指的是模型在训练数据上就表现得很差,相比于正常的表现(一般我们会存在某一个baseline performance,比如说真人去做的时候的代价函数,作为一个比较标准)Jtrain显得更高,这种时候一般是high bias 引起的情况
高方差variance, 指的是模型在训练数据上表现的太好了(这个太好了的意思指的是,模型在训练数据上完美契合,但是对于交叉验证的估计可能不是太好).常见的特征是Jcv > Jtrain
举个例子,在某个函数拟合时候效果可能是这样的

对于一个模型来说,不可能是二者兼顾的,我们需要在其中做出一些tradeOff(权衡) 一些因素可能会影响到bias和variance的变化,下面我会使用图片的形式作为展示内容.
模型函数的高次项阶数:degree of polynomial
其实从上面那张图就可以看出来,随着高次项阶数的增加,训练效果是一定会越变越好的
但是对于验证集合来说,初步的高次项拟合可以向着更好的拟合靠拢,但是一旦发生了过度拟合的情况,就会产生一些高方差,对于预测效果会更差
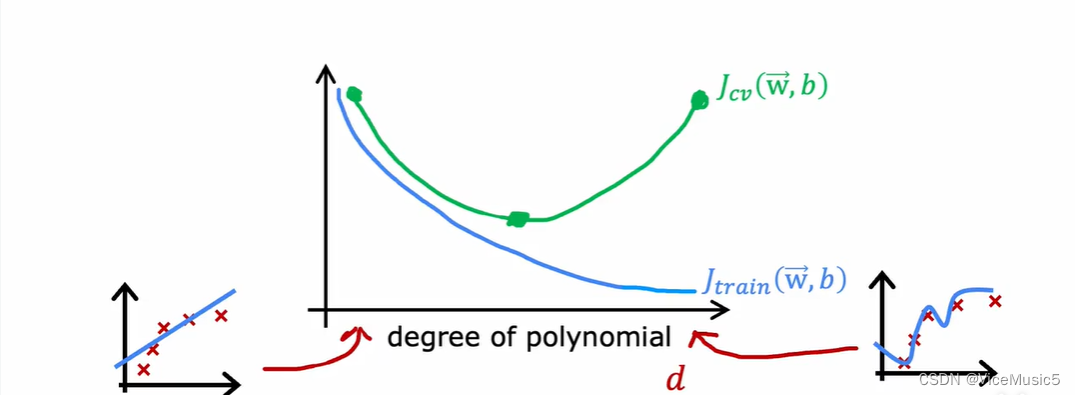
也就是说,从这张曲线分析上,过低的多项式高次项可能导致高偏差
而过高的多项式高次项则会导致高方差
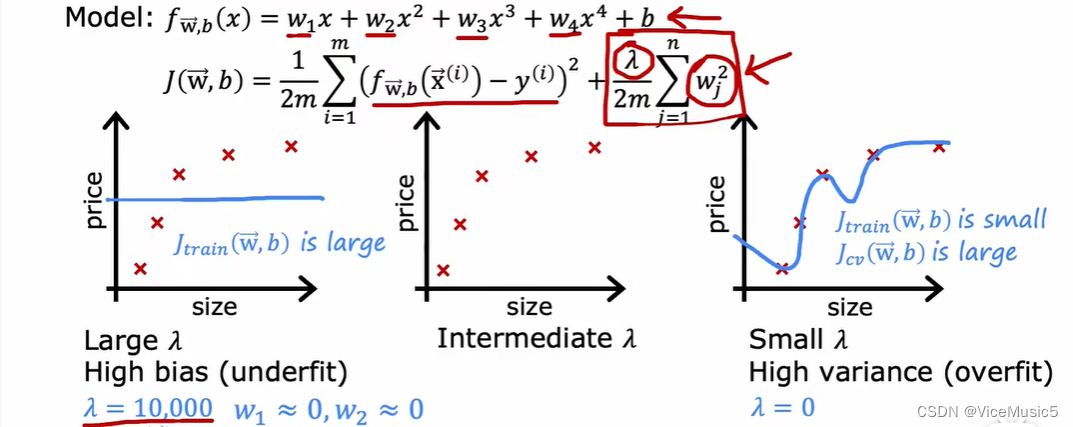
正规化参数
正规化参数又叫惩罚参数penail parameter,具体的原理解释可以看前面的博客
惩罚参数起到的效果是让特定的某个权重分量wi在梯度下降的时候下降的更快,在一般的代价函数计算中,我们通常是对所有参数进行统一惩罚,让权重分布的更加均衡(全都接近0).
简而言之就是惩罚参数越大,w越均衡
但是惩罚参数过大的时候,产生的影响就是权重失效(全变成很接近0的数字了),最后你的模型只剩下bias了,这不就妥妥的high bias,并且与此同时,连喂给ai的训练数据都不怎么杨,更何况是测试数据,所以过高的惩罚参数同样会引发高方差问题
但是惩罚参数过小,对于权重的控制能力太多,高次项产生了高方差的影响.
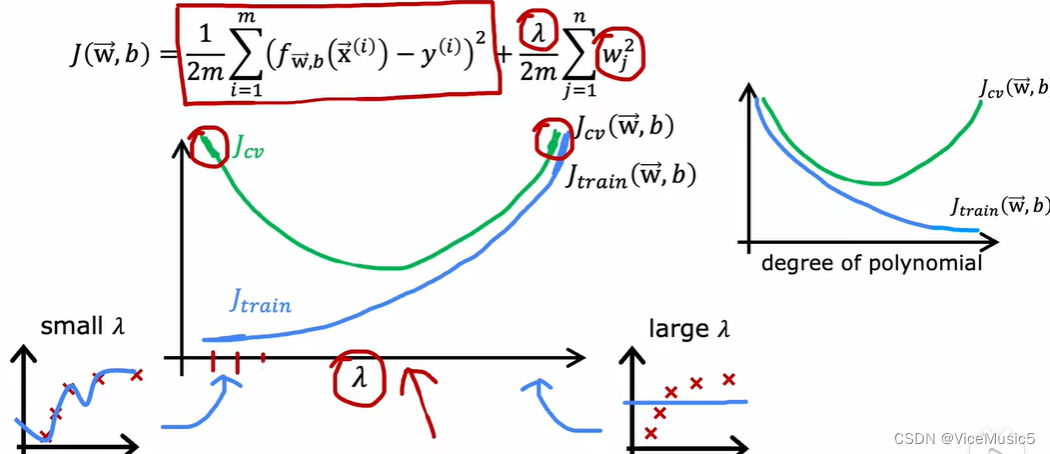
所以随着惩罚参数的变化,我们可以有这个曲线
学习规模:
训练数据的规模同样是影响因素,这个可能和常规的认知有些偏差一哈
虽然大量的训练数据可以让模型更快地拿捏数据的走势,但是训练数据如果太多,在拟合方面肯定是无法好地照顾到所有的数据点
这就导致了,如果训练数据过多,会导致高偏差,但是会降低方差
(图片后续补充)
(4)处理方法
当我们通过曲线等等手段知道了问题出在高方差还是高偏差的时候,我们可以采用一些手段进行处理
高偏差的修正方法: high bias
1. 增加更多的特征值
2. 增加更高次项的特征值
3. 增加惩罚数值
高方差的处理方法: high variance
1. 增加更多训练数据
2. 减少多项式次数
3. 适当减少惩罚数值
此外,比较大型的神经网络系统也是一种降低方差的方法,只要在训练的时候用了比较合适的惩罚参数
2.对于训练误差的处理
对于一些特别的数据和情况,我们需要进行一个专门化的处理,在后面会提到强化学习这一特点
(1)专门化数据处理
对于一些特殊的情况,模型的识别可能不是那么理想,例如对于识别数字,发现对于数字9的识别效果不好,那么训练数据中就可以增加一些9有关的数字,来专门增强对于某个他特征学习效果不理想的情况
(2)数据添加
训练数据需要重新生成的时候,一般有两种方法,第一种是数据修改,通过对原有数据的一些修改,比如图像的旋转,失真操作(distort),生成新的数据
第二种方式是数据生成,使用人工生成的数据来组合成新的训练集合
(3)迁移学习
迁移学习的意思为将一个模型的计算结果作为另一个模型的输入
(关于这个板块主要是理解一下概念即可,后续有机会仍然会继续补充
3.precision,recall (精度和召回率)
cv代价函数是一种很常用的,衡量模型的方式,但是这种方式仍然只是其中的一种
比较算法的优劣性,我们可以使用另一种量化的评价方法,precision and recall
这种方法经常用于神经网络的识别操作中,我们举个例子,这其中1是我们想要监听的类的展示

其中精度就是所有检测值中的正确率
召回率是所有正确样本中检测到了多少
这两个东西需要一个平衡,所以存在F1 score衡量两个指标