很多linux命令支持正则表达式,sed也不例外。
行开始 ( ^ )
插入符^匹配一行的开始。比如说,匹配以103打头的行:
sed -n '/^103/p' data.txt注意,插入符只有在表达式的首位时,才表示行首匹配。
行尾( $)
美元符$匹配行尾。比如说,输出以g结尾的行:
sed -n '/g$/p' data.txt单字符 (.)
句点(.)匹配除行字符结尾的任何单个字符。一个点匹配一个字符,两个点匹配两个,三个点匹配三个,以此类推。
比如,把L及随后的一个字符替换为Lee:
sed -n 's/L./Lee/p' data.txt 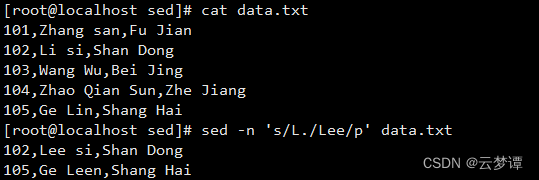
字符出现零或多次(*)
星号(*)表示它之前的字符出现零或多次。比如说:’1*’表示匹配零个或多个连续的1.
比如说,有这样一个log文件,其内容如下:
log: Input Validated
log:
log: testing resumed
log:
log:output created假设你只关注有内容的行,那么可以这样做:
sed -n '/log: *./ p' log.txt注意星号后面有一个句点,这是必要的。否则它会输出所有行。
字符出现一次或多次(\+)
元字符“\+”匹配它之前的字符,它出现一或多次。比如,在上面的log文件里,匹配有log:后跟空格的行:
sed -n '/log: \+/ p' log.txt字符出现零或一次 (\?)
元字符(\?) 表示匹配它之前的字符,出现零或一次。
sed -n '/log: \?/ p' log.txt元字符转义 (\)
如果需要匹配包含元字符的内容(比如说星号、句点),那么,需要对元字符进行转义。
sed -n '/127\.0\.0\.1/ p' /etc/hosts字符集匹配 ([0-9])
字符集用方括号表示,它用于匹配集合里提及的元素。比如说,匹配包含2、3或4的行:
sed -n '/[234]/ p' data.txt在方括号里,可以用连接符-来表示范围。比如 [0123456789]等价于 [0-9],它还可用于字符集,比如说[a-z],[A-Z] 。
sed -n '/[2-4]/ p' data.txt逻辑或(|)
管道符(|) 表示逻辑或,“subexpression1|subexpression2”匹配subexpression1或subexpression2。
sed -n '/101\|102/ p' data.txt注意管道符是转义的。
准确匹配m次出现({m})
假设有一个numbers.txt文件,其内容如下:
1
12
123
1234
12345
123456- 打印包含阿拉伯数字字符的行:
sed -n '/[0-9]/ p' numbers.txt- 打印五位数
sed -n '/^[0-9]\{5\}$/ p' numbers.txt指定出现次数的范围({m,n})
- 打印3到五位数
sed -n '/^[0-9]\{3,5\}$/ p' numbers.txt范围可以只指定下限,或上限,比如{m,}或{,n}
sed -n '/^[0-9]\{3,\}$/ p' numbers.txt
sed -n '/^[0-9]\{,5\}$/ p' numbers.txt单词边界 (\b)
元字符(\b)用于匹配单词边界。它匹配单词间的字符。
sed -n '/Zhao\b/ p' data.txt反向引用(\n)
这里(\n) 中的n是数值。反向引用可以提取表达式里的内容供后面使用。
比如要"2022 2021 2023"按次序排列,其他就可以使用反向引用中\2 \1 \3来排序,排列的结果为"2021 2022 2023"
echo -e "2022 2021 2023" | sed -e "s/\(.*\) \(.*\) \(.*\)/\2 \1 \3/g"![[PG]将一行数据打散成多行数据](https://img-blog.csdnimg.cn/22956aaab07c42f4abc39969e97b9dc6.png)