151. LinkedList特征分析
增删快
可以打断连接,重新赋值引用,不
涉及数据移动操作,效率高
查询慢
双向链表结构数据存储非连
续,需要通过元素一一 跳转
152 ArrayList和LinkedList对比分析
ArrayList特征
查询快。增删慢
适用于数据产出之后,后期用于查询,遍历,过滤,排序操作。
常用结构为 ArrayList 结构
LinkedList特征
增删快,查询慢
适用于数据产出之后,在链表头,和链表尾进行数据的增删操作,查询操作。
资源性质的数据需要结构存储,一般采用 LinkedList 线程池,数据库连接池
153.TreeSet和TreeMap存储元素要求对应实现内容,代码演示
虽然 TreeMap 和 TreeSet 实现的接口规范不同,但 TreeSet 底层是通过 TreeMap 来实现的(如同HashSet底层是是通过HashMap来实现的一样),因此二者的实现方式完全一样。而 TreeMap 的实现就是红黑树算法。
相同点:TreeMap和TreeSet都是有序的集合,也就是说他们存储的值都是拍好序的。TreeMap和TreeSet都是非同步集合,因此他们不能在多线程之间共享,不过可以使用方法Collections.synchroinzedMap()来实现同步运行速度都要比Hash集合慢,他们内部对元素的操作时间复杂度为O(logN),而HashMap/HashSet则为O(1)。不同点:最主要的区别就是TreeSet和TreeMap非别实现Set和Map接口TreeSet只存储一个对象,而TreeMap存储两个对象Key和Value(仅仅key对象有序)TreeSet中不能有重复对象,而TreeMap中可以存在
154.Treemap和Treeset实现排序
@Test
public void testCalculate() {
Student stu1 = new Student("张三", 80);
Student stu2 = new Student("李四", 60);
Student stu3 = new Student("王二", 90);
Student stu4 = new Student("麻子", 70);
// 定义排序类型,按照分数排序
TreeSet<Student> stuSet = new TreeSet<>(Comparator.comparingInt(Student::getScore));
//添加数据的时候排序
stuSet.add(stu1);
stuSet.add(stu2);
stuSet.add(stu3);
stuSet.add(stu4);
for(Student stu: stuSet){
System.out.println(stu);
}
System.out.println("******************************");
//更改数据不会影响原来的顺序,TreeSet使用的时候最好不要修改数据
stu4.setScore(95);
for(Student stu: stuSet){
System.out.println(stu);
}
}
Student(name=李四, score=60)
Student(name=麻子, score=70)
Student(name=张三, score=80)
Student(name=王二, score=90)
******************************
Student(name=李四, score=60)
Student(name=麻子, score=95)
Student(name=张三, score=80)
Student(name=王二, score=90)
@Test
public void testCalculate() {
Student stu1 = new Student("张三", 80);
Student stu2 = new Student("李四", 60);
Student stu3 = new Student("王二", 90);
Student stu4 = new Student("麻子", 70);
TreeMap<Student, String> stuMap = new TreeMap<>(Comparator.comparingInt(Student::getScore));
//添加数据的时候排序
stuMap.put(stu1, "");
stuMap.put(stu2, "");
stuMap.put(stu3, "");
stuMap.put(stu4, "");
for (Student student : stuMap.keySet()) {
System.out.println(student);
}
System.out.println("******************************");
//更改数据不会影响原来的顺序,TreeMap使用的时候最好不要修改数据
stu4.setScore(95);
for (Student student : stuMap.keySet()) {
System.out.println(student);
}
}
测试结果:
Student(name=李四, score=60)
Student(name=麻子, score=70)
Student(name=张三, score=80)
Student(name=王二, score=90)
******************************
Student(name=李四, score=60)
Student(name=麻子, score=95)
Student(name=张三, score=80)
Student(name=王二, score=90)
155.代码阅读题
class Type {
static Type t1 = new Type();
static Type t2 = new Type();
{
System.out.println("1构造代码块");
}
static {
System.out.println("2静态代码块");
}
public Type() {
System.out.println("3构造方法");
}
}
==
public class Demo {
public static void main(String[] args) {
Type t = new Type();
}
}
1313213
156.try-catch块中存在return语句,是否还执行finally块? 如果执行,说出执行顺序
结论:
1.不管有没有异常,finally块中代码都会执行;
2.当try.catch中有return时,finally仍然会执行;
3.finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
4.在执行时,是return语句先把返回值写入内存中,然后停下来等待finally语句块执行完,return再执行后面的一段。
5.至于返回值到底变不变,当finally调用任何可变的API,会修改返回值;当finally调用任何的不可变的API,对返回值没有影响。
157.try-catch-finally执行流程
最终结论:任何try或者catch中的return语句之前,如果finally存在的话,都会先执行finally语句,如果finally中有return语句,那么程序程序就结束了。
158.调用start()方法和run()方法的区别
线程的run()方法是由java虚拟机直接调用的,如果我们没有启动线程(没有调用线程的start()方法)而是在应用代码中直接调用run()方法,那么这个线程的run()方法其实运行在当前线程(即run()方法的调用方所在的线程)之中,而不是运行在其自身的线程中,从而违背了创建线程的初衷;
159.线程有哪些状态?状态之间如何转换?
六种状态
public enum State {
//线程刚创建
NEW,
//在JVM中正在运行的线程
RUNNABLE,
//线程处于阻塞状态,等待监视锁,可以重新进行同步代码块中执行
BLOCKED,
//等待状态
WAITING,
//调用sleep() join() wait()方法可能导致线程处于等待状态
TIMED_WAITING,
//线程执行完毕,已经退出
TERMINATED;
}
- 新建(NEW):创建后尚未启动的线程处于这种状态。
2.运行(RUNNABLE):调用start()方法,RUNNABLE包括了操作系统线程状态中的Running和Ready,也就是处于此状态的线程有可能正在执行,也有可能正在等待着CPU为它分配执行时间(该线程已经获取了除CPU资源外的其他资源,等待获取CPU 资源后才会真正处于运行状态)。
3.无限期等待(WAITING):处于这种状态的线程不会被分配CPU执行时间,它们要等待被其他线程显式地唤醒。以下方法会让线程陷入无限期的等待状态:
4.限期等待(TIMED_WAITING):处于这种状态的线程也不会被分配CPU执行时间,不过无须等待被其他线程显式地唤醒,在一定时间之后它们会由系统自动唤醒。以下方法会让线程进入限期等待状态
5.阻塞(BLOCKED):线程被阻塞了,“阻塞状态”与“等待状态”的区别是:“阻塞状态”在等待着获取到一个排他锁,这个事件将在另外一个线程获得锁的时候可能发生,比如synchronized之外;而“等待状态”则是在获得锁之后,主动释放锁,进入等待一段时间,或者等待唤醒动作的发生
6.结束(TERMINATED):已终止线程的线程状态,线程已经结束执行。
160.多线程同步的作用是什么
线程有可能和其他线程共享一些资源,比如,内存,文件,数据库等。
当多个线程同时读写同一份共享资源的时候,可能会引起冲突。这时候,我们需要引入线程“同步”机制,即各位线程之间要有个先来后到,不能一窝蜂挤上去抢作一团。
线程同步的真实意思和字面意思恰好相反。线程同步的真实意思,其实是“排队”:几个线程之间要排队,一个一个对共享资源进行操作,而不是同时进行操作。 [
161.手写代码,实现对int scores[]={89,56,45,78,12,3}数组的冒泡排序
package test01;
public class TestSort {
public static void bubbleSort(int[] arrary){
//从第一个元素开始,向后依次成对比较,逆序则交换。
//对所有的元素都进行这一操作 。
int temp ;
for(int i = 0 ; i < arrary.length-1; i++){
for(int j = 0; j <arrary.length-1;j++){
//1、比较第一对相邻的元素。判断第一个元素是否大于第二个元素如果是则交换.
//2、此时要比较的是第J-1个元素。要不停的向后移动
if(arrary[j]>arrary[j+1]){
temp = arrary[j];
arrary[j] = arrary[j+1];
arrary[j+1] = temp;
}
}
System.out.print("第"+(i+1)+"轮");
for(int j:arrary) {
System.out.print(j + ",");
}
System.out.println();
}
}
public static void main(String[]args){
int [] arrary = {3,5,1,-7,4,9,-6,8,10,4};;
TestSort.bubbleSort(arrary);
}
}
第1轮3,1,-7,4,5,-6,8,9,4,10,
第2轮3,-7,1,4,-6,5,8,4,9,10,
第3轮3,-7,1,-6,4,5,4,8,9,10,
第4轮3,-7,1,-6,4,4,5,8,9,10,
-----实际上但排序了4次以后我们已经完成了整个数组的排序。后面的5轮都是无意义的。
第5轮3,-7,1,-6,4,4,5,8,9,10,
第6轮3,-7,1,-6,4,4,5,8,9,10,
第7轮3,-7,1,-6,4,4,5,8,9,10,
第8轮3,-7,1,-6,4,4,5,8,9,10,
第9轮3,-7,1,-6,4,4,5,8,9,10,
从以上结果我们可以看出,当我们第4轮排序以后我们就已经不在进行了排序,因此我们可以确定当元素不在进行交换的时候我们就能确定整个排序实际上已经完成了
优化版本
public static void bubbleSort(int[] arrary){
//从第一个元素开始,向后依次成对比较,逆序则交换。
//对所有的元素都进行这一操作 。
int temp ;
boolean success ;
for(int i = 0 ; i < arrary.length-1; i++){
//一开始就是成功了
success=true;
for(int j = 0; j <arrary.length-1 ;j++){
//1、比较第一对相邻的元素。判断第一个元素是否大于第二个元素如果是则交换.
//2、此时要比较的是第J-1个元素。要不停的向后移动
if(arrary[j]>arrary[j+1]){
temp = arrary[j];
arrary[j] = arrary[j+1];
arrary[j+1] = temp;
//进行优化 1、当不在比较失败的时候我们就退出整个循环
//证明还在排序
success=false;
}
}
//如果没有排序了我们则认为已经完成了所有的排序
if(success){
break;
}
System.out.print("第"+(i+1)+"轮"+success);
for(int j:arrary) {
System.out.print(j + ",");
}
System.out.println();
}
}
162.创建多线程的方式
一, 自定义线程类,继承Thread类,重写run方法,创建自定义线程对象,直接调用start方法,开启线程
public class Demo1 extends Thread{
//重写的是父类Thread的run()
public void run() {
System.out.println(getName()+"is running...");
}
public static void main(String[] args) {
Demo1 demo1 = new Demo1();
Demo1 demo2 = new Demo1();
demo1.start();
demo2.start();
}
}
二,自定义线程类,遵从Runnable接口,重写run(),使用自定义遵从接口Runnable实现类对象,作为Thread构造方法参数,借助Thread类对象和start方法开启线程。
public class Demo2 implements Runnable{
//重写的是Runnable接口的run()
public void run() {
System.out.println("implements Runnable is running");
}
public static void main(String[] args) {
Thread thread1 = new Thread(new Demo2());
Thread thread2 = new Thread(new Demo2());
thread1.start();
thread2.start();
}
}
实现Runnable接口相比第一种继承Thread类的方式,使用了面向接口,将任务与线程进行分离,有利于解耦
三.匿名内部类方式:适用于创建启动线程次数较少的环境,书写更加简便
创建启动线程的第三种方式————匿名内部类
public class Demo3 {
public static void main(String[] args) {
//方式1:相当于继承了Thread类,作为子类重写run()实现
new Thread() {
public void run() {
System.out.println("匿名内部类创建线程方式1...");
};
}.start();
//方式2:实现Runnable,Runnable作为匿名内部类
new Thread(new Runnable() {
public void run() {
System.out.println("匿名内部类创建线程方式2...");
}
} ).start();
}
}
四.带返回值的线程(实现implements Callable<返回值类型>)
以上两种方式,都没有返回值且都无法抛出异常。
Callable和Runnbale一样代表着任务,只是Callable接口中不是run(),而是call()方法,但两者相似,即都表示执行任务,call()方法的返回值类型即为Callable接口的泛型
方式4:实现Callable<T> 接口
含返回值且可抛出异常的线程创建启动方式
public class Demo5 implements Callable<String>{
public String call() throws Exception {
System.out.println("正在执行新建线程任务");
Thread.sleep(2000);
return "新建线程睡了2s后返回执行结果";
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
Demo5 d = new Demo5();
/* call()只是线程任务,对线程任务进行封装
class FutureTask<V> implements RunnableFuture<V>
interface RunnableFuture<V> extends Runnable, Future<V>
*/
FutureTask<String> task = new FutureTask<>(d);
Thread t = new Thread(task);
t.start();
System.out.println("提前完成任务...");
//获取任务执行后返回的结果
String result = task.get();
System.out.println("线程执行结果为"+result);
}
}
五.线程池的实现(java.util.concurrent.Executor接口)
降低了创建线程和销毁线程时间开销和资源浪费
public class Demo7 {
public static void main(String[] args) {
//创建带有5个线程的线程池
//返回的实际上是ExecutorService,而ExecutorService是Executor的子接口
Executor threadPool = Executors.newFixedThreadPool(5);
for(int i = 0 ;i < 10 ; i++) {
threadPool.execute(new Runnable() {
public void run() {
System.out.println(Thread.currentThread().getName()+" is running");
}
});
}
}
}
运行完毕,但程序并未停止,原因是线程池并未销毁,若想销毁调用threadPool.shutdown(); 注意需要把我上面的Executor threadPool = Executors.newFixedThreadPool(10); 改为ExecutorService threadPool = Executors.newFixedThreadPool(10); 否则无shutdown()方法
若创建的是CachedThreadPool则不需要指定线程数量,线程数量多少取决于线程任务,不够用则创建线程,够用则回收。
利用线程池创建的优点:
1.提高响应速度(减少了创建新线程的时间)
2.降低资源消耗(重复利用线程池中线程,不需要每次都创建)
3.便于线程管理:
corePoolSize:核心池的大小
maximumPooSize: 最大的线程数
keepAliveTime: 线程没有任务时最多保持长时间会终止
package com.bupt.ThreadPoolDemo;/**
- 创建线程方式四:线程池
- 好处:
- 1、提高响应速度,减少了创建新线程的时间
- 2、降低资源消耗,重复利用线程池中的线程,不需要每次都创建。
- 3、便于线程管理
- corePoolSize:核心池的大小
- maximumPool: 最大线程数
- keepAliveTime: 线程没有任务时最多保持多长时间会中终止*创建多线程:四种方式**/
class Number implements Runnable{
@Override
public void run() {
for (int i = 0; i < 100; i++) {
if( i % 2 == 0){
System.out.println(Thread.currentThread().getName()+": "+i);
}
}
}
}
class Number1 implements Runnable{
@Override
public void run() {
for (int i = 0; i < 100; i++) {
if( i % 2 != 0){
System.out.println(Thread.currentThread().getName()+": "+i);
}
}
}
}
public class ThreadPool {
public static void main(String[] args) {
//1. 提供指定数量的线程池
ExecutorService service = Executors.newFixedThreadPool(10);
ThreadPoolExecutor service1 = (ThreadPoolExecutor) service;
//设置线程池的属性
service1.setCorePoolSize(15);
//2. 执行指定的线程操作,需要提供实现Runnable接口测试或callable接口实现类的对象
service1.execute(new Number());//适合于Runnable
service1.execute(new Number1());//适合于Runnable
//service.submit;//适合使用Callable
//3.关闭连接池
service.shutdown();
}
}
Executor是一个接口,它是Executor框架的基础,它将任务的提交与任务的执行分离开来。
ExecutorService接口继承了Executor,在其上做了一些shutdown()、submit()的扩展,可以说是真正的线程池接口;
AbstractExecutorService抽象类实现了ExecutorService接口中的大部分方法;
ThreadPoolExecutor是线程池的核心实现类,用来执行被提交的任务。
ScheduledExecutorService接口继承了ExecutorService接口,提供了带"周期执行"功能ExecutorService;
ScheduledThreadPoolExecutor是一个实现类,可以在给定的延迟后运行命令,或者定期执行命令。ScheduledThreadPoolExecutor比Timer更灵活,功能更强大。
Future接口和实现Future接口的FutureTask类,代表异步计算的结果。
Runnable接口和Callable接口的实现类,都可以被ThreadPoolExecutor或Scheduled-ThreadPoolExecutor执行。
164.线程控制
1,start方法:
创建一个线程。值得注意的是,new一个线程的时候,只是表示该线程处于新建状态,并不是执行状态。使用start方法后启动一个线程,线程处于就绪状态,也并不是说直接就在运行了,它表示这个线程可以运行了,但是什么时候开始运行,取决于JVM里线程调度器的调度。
2,stop方法:
结束一个线程。容易导致死锁,不推荐使用。值得注意的是,不要试图在一个线程已死亡的情况下再次调用start方法来启动该线程,会报illegalThreadStateException错的。
3,join方法:
在一个线程中加入一个线程。当在某个程序执行流中调用了其他线程的join方法时,调用线程将被阻塞,直到被join方法加入的join线程完成为止。
4,sleep方法:
让线程睡觉。使当前正在执行的线程暂停一段时间,并进入阻塞状态。
5,yield方法:
和sleep方法相似,让当前正在执行的线程暂停一下,但是他不会阻塞这个线程,它只是将这个线程转入就绪状态。
6,setPriority方法
:设置线程优先级。set和getPriority设置和获得线程的优先级,1到10一共10个数字,默认是5,数字越大优先级越高,越容易获得执行机会。 为了跨平台,最好不要使用优先级决定线程的执行顺序。这个时候使用3个静态常量:max_Priority,min_Priority,norm_Priority。
7,setDaemon方法:
设置后台线程。 Daemon Threads(daemon 线程)是服务线程,当其他线程全部结束,只剩下daemon线程时,虚拟机会立即退出。
Thread t = new DaemonThread();
t.setDaemon(true);//setDaemon(true)把线程标志为daemon,其他的都跟一般线程一样
t.start();//一定要先setDaemon(true),再启动线程
在daemon线程内启动的线程,都定为daemon线程
8,wait(),Notify()方法
在后面介绍同步锁的时候在仔细说。 在运行状态中,线程调用wait(),表示这线程将释放自己所有的锁标记,同时进入这个对象的等待队列。等待队列的状态也是阻塞状态,只不过线程释放自己的锁标记。用notify()方法叫出之后,紧跟着刚才wait();的位置往下执行。如果一个线程调用对象的notify(),就是通知对象等待队列的一个线程出列。进入锁池。如果使用notifyall()则通知等待队列中所有的线程出列。
有一个问题,在什么情况下,一个线程将进入阻塞状态?
1,线程调用了sleep方法,主动放弃它所占有的处理器资源
2,线程调用了阻塞式IO方法,在方法返回之前,线程阻塞了
3,线程试图获得一个同步监听器,但是该同步监视器正被其他的线程持有
4,线程在等待某一个notify通知
5,线程调用了suspend方法将线程挂起了。
要是让一个线程由阻塞状态变成了就绪状态正好和上面的情况相反,最后一点使用resume方法就好了。值得注意的是:suspend()将运行状态推到阻塞状态(注意不释放锁标记)。恢复状态用resume()。Stop()释放全部。这几个方法上都有Deprecated 标志,说明这个方法不推荐使用。一般来说,主方法main()结束的时候线程结束,可是也可能出现需要中断线程的情况。对于多线程一般每个线程都是一个循环,如果中断线程我们必须想办法使其退出。如果想结束阻塞中的线程(如sleep 或wait),可以由其他线程对其对象调用interrupt()。用于对阻塞(或锁池)会抛出例外Interrupted。
165.java集合的理解
java提供的一个工具包,继承自java.util
两大接口:collection和map
166.重写和重载
重写和重载的区别重写:1.子类或者实现类中可以重写2.重写要求方法声明必须一致(权限修饰符返回值类型方法名(形式参数列表) )3.可以重新完成方法体内容4.强制要求使用@override 开启代码格式严格检查重载:1.同一个类内或者同一个接口内2.要求方法名必须一致3.要求方法参数类型必须不-致
167.stream流特性
- Stream流不是一种数据结构,不保存数据,它只是在原数据集上定义了一组操作。
- 这些操作是惰性的,即每当访问到流中的一个元素,才会在此元素上执行这一系列操作。
- Stream不保存数据,故每个Stream流只能使用一次。
关于应用在Stream流上的操作,可以分成两种:Intermediate(中间操作)和Terminal(终止操作)。中间操作的返回结果都是Stream,故可以多个中间操作叠加;终止操作用于返回我们最终需要的数据,只能有一个终止操作
使用Stream流,可以清楚地知道我们要对一个数据集做何种操作,可读性强。而且可以很轻松地获取并行化Stream流,不用自己编写多线程代码,可以让我们更加专注于业务逻辑。
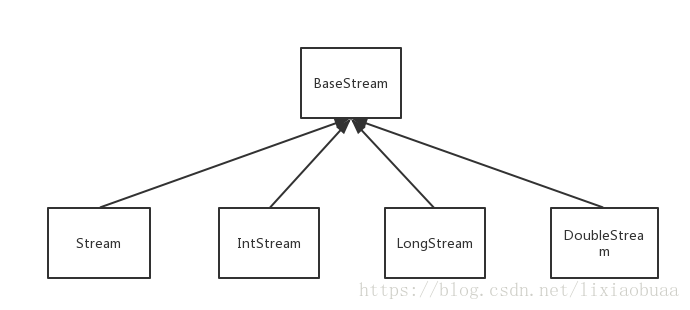
接下来看一下Stream流的接口继承关系:
168、 流的生成方法
Collection接口的stream()或parallelStream()方法静态的Stream.of()、Stream.empty()方法Arrays.stream(array, from, to)静态的Stream.generate()方法生成无限流,接受一个不包含引元的函数静态的Stream.iterate()方法生成无限流,接受一个种子值以及一个迭代函数Pattern接口的splitAsStream(input)方法静态的Files.lines(path)、Files.lines(path, charSet)方法静态的Stream.concat()方法将两个流连接起来
169.流的Intermediate方法(中间操作)
filter(Predicate)将结果为false的元素过滤掉map(fun)转换元素的值,可以用方法引元或者lambda表达式flatMap(fun)若元素是流,将流摊平为正常元素,再进行元素转换limit(n)保留前n个元素skip(n)跳过前n个元素distinct()剔除重复元素sorted()将Comparable元素的流排序sorted(Comparator)将流元素按Comparator排序peek(fun)流不变,但会把每个元素传入fun执行,可以用作调试
170.流的Terminal方法(终结操作)
约简操作
max(Comparator)
min(Comparator)
count()
findFirst()返回第一个元素
findAny()返回任意元素anyMatch(Predicate)任意元素匹配时返回trueallMatch(Predicate)所有元素匹配时返回truenoneMatch(Predicate)没有元素匹配时返回truereduce(fun)从流中计算某个值,接受一个二元函数作为累积器,从前两个元素开始持续应用它,累积器的中间结果作为第一个参数,流元素作为第二个参数reduce(a, fun)a为幺元值,作为累积器的起点reduce(a, fun1, fun2)与二元变形类似,并发操作中,当累积器的第一个参数与第二个参数都为流元素类型时,可以对各个中间结果也应用累积器进行合并,但是当累积器的第一个参数不是流元素类型而是类型T的时候,各个中间结果也为类型T,需要fun2来将各个中间结果进行合并收集操作
iterator()forEach(fun)forEachOrdered(fun)可以应用在并行流上以保持元素顺序toArray()toArray(T[] :: new)返回正确的元素类型collect(Collector)collect(fun1, fun2, fun3)fun1转换流元素;fun2为累积器,将fun1的转换结果累积起来;fun3为组合器,将并行处理过程中累积器的各个结果组合起来
然后再看一下有哪些Collector收集器:
Collectors.toList()Collectors.toSet()Collectors.toCollection(集合的构造器引用)Collectors.joining()、Collectors.joining(delimiter)、Collectors.joining(delimiter、prefix、suffix)字符串元素连接Collectors.summarizingInt/Long/Double(ToInt/Long/DoubleFunction)产生Int/Long/DoubleSummaryStatistics对象,它有getCount、getSum、getMax、getMin方法,注意在没有元素时,getMax和getMin返回Integer/Long/Double.MAX/MIN_VALUECollectors.toMap(fun1, fun2)/toConcurrentMap两个fun用来产生键和值,若值为元素本身,则fun2为Function.identity()Collectors.toMap(fun1, fun2, fun3)/toConcurrentMapfun3用于解决键冲突,例如(oldValue, newValue) -> oldValue,有冲突时保留原值Collectors.toMap(fun1, fun2, fun3, fun4)/toConcurrentMap默认返回HashMap或ConcurrentHashMap,fun4可以指定返回的Map类型,为对应的构造器引元Collectors.groupingBy(fun)/groupingByConcurrent(fun)fun是分类函数,生成Map,键是fun函数结果,值是具有相同fun函数结果元素的列表Collectors.partitioningBy(fun)键是true/false,当fun是断言函数时用此方法,比groupingBy(fun)更高效Collectors.groupingBy(fun1, fun2)fun2为下游收集器,可以将列表转换成其他形式,例如toSet()、counting()、summingInt/Long/Double(fun)、maxBy(Comparator)、minBy(Comparator)、mapping(fun1, fun2)(fun1为转换函数,fun2为下游收集器)最后提一下基本类型流,与对象流的不同点如下:
IntStream和LongStream有range(start, end)和rangeClosed(start, end)方法,可以生成步长为1的整数范围,前者不包括end,后者包括endtoArray方法将返回基本类型数组具有sum、average、max、min方法summaryStatics()方法会产生类型为Int/Long/DoubleSummaryStatistics的对象可以使用Random类的ints、longs、doubles方法产生随机数构成的流对象流转换为基本类型流:mapToInt()、mapToLong()、mapToDouble()基本类型流转换为对象流:boxed()
171.反射的定义
java的反射(reflection) 机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性,既然能拿到嘛,那么,我们就可以修改部分类型信息;这种动态获取信息以及动态调用对象方法的功能称为 java语言的反射(reflection)机制。
172.习题
(1) 设计一个类代表二维空间的一个点(2) 设计一个类代表二维空间的一个圆。要求两个成员变量。一个是圆心,一 个是半径,提供计算面积的方法。(3) 为上述Cricle类添加一个方法,计算一个点(Point对象)是否在圆(Cricle对象)内,并写程序验证
public class Text {
public static void main(String[] args) {
Point p1 = new Point(0, 0);
Point p2 = new Point(2, 0);
Cricle c = new Cricle() ;
c.setP1(p1);//圆心
c.setP2(p2);//随便一点
c.setR(2);//半径
c.sum();//面积
c.inOrOut();//是否在圆内
}
}
class Point{
private double x,y;//点的坐标
public Point(double x, double y) { super(); this.x = x; this.y = y; } public double getX() { return x; } public void setX(double x) { this.x = x; }. public double getY() { return y; } public void setY(double y) { this.y = y; }
}class Cricle { Point p1 ; // 圆心 Point p2 ; // 随便一点 private double r ;//半径
public void sum () {//求圆面积 System.out.println("圆的面积为:"+Math.PIrr); } public void inOrOut () {//判断一点是否在圆内 if( Math.pow( p1.getX()-p2.getX() , 2) + Math.pow( p1.getY()-p2.getY() , 2 ) >= Math.pow(r, 2)) System.out.println("不在圆内"); else System.out.println("在圆内"); } public Point getP1() { return p1; } public void setP1(Point p1) { this.p1 = p1; } public Point getP2() { return p2; } public void setP2(Point p2) { this.p2 = p2; } public double getR() { return r; } public void setR(double r) { this.r = r; }
}
173.Date类概述
SimpleDateFormat类作用
●可以对Date对象或时间毫秒值格式化成我们喜欢的时间形式。●也可以把字符串的时间形式解析成日期对象。格式化:Date对象------------>2099年11月11日11:11:时间毫秒值--------->2099年11月11日11:11:解析: 2099年11月11日 11:11:11----->Date对象
174.Junit单元测试是做什么的?
测试类中方法的正确性的。
174.Junit单元测试
* 测试分类: 1. 黑盒测试:不需要写代码,给输入值,看程序是否能够输出期望的值。 2. 白盒测试:需要写代码的。关注程序具体的执行流程。* Junit使用:白盒测试 * 步骤: 1. 定义一个测试类(测试用例)* 建议:* 测试类名:被测试的类名Test CalculatorTest* 包名:xxx.xxx.xx.test cn.itcast.test2. 定义测试方法:可以独立运行* 建议:* 方法名:test测试的方法名 testAdd() * 返回值:void* 参数列表:空参3. 给方法加@Test4. 导入junit依赖环境* 判定结果:* 红色:失败* 绿色:成功* 一般我们会使用断言操作来处理结果* Assert.assertEquals(期望的结果,运算的结果);* 补充: * @Before: * 修饰的方法会在测试方法之前被自动执行 * @After:* 修饰的方法会在测试方法执行之后自动被执行
175.Junit单元测试的优点是什么?
jUnit可以选择执行哪些测试方法,可以- -键执行全部测试方法的测试。jUnit可以生测试报告, 如果测试良好则是绿色;如果测试失败,则是红色。单元测试中的某个方法测试失败了,不会影响其他测试方法的测试。
176jUnit单 元测试的实现过程是什么样的?
必须导入Junit框 架的jar包。定义的测试方 法必须是无参数无返回值,且公开的方法。测试方 法使用@Test注解标记。
177.jUnit测试某个方法,测试全部方法怎么处理?成功的标志是什么
测试某个方 法直接右键该方法启动测试。测试全部方法, 可以选择类或者模块启动。红色失败, 绿色通过。
178.Junit常用注解junit4
| 注解 | 说明 |
| @Test | 测试方法 |
| @Before | 用来修饰实例方法,该方法会在每一个测试方法执行之 前执行一次。 |
| @After | 用来修饰实例方法,该方法会在每一一个测试方法执行之后执行- -次。 |
| @BeforeClass | 用来静态修饰方法,该方法会在所有测试方法之前只执行一-次。 |
| @AfterClass | 用来静态修饰方法,该方法会在所有测试方法之后只执行一-次。 |
●开始执行的方法:初始化资源。●执行完之后的方法:释放资源。
179.注解、
* 概念:说明程序的。给计算机看的
* 注释:用文字描述程序的。给程序员看的* 定义:注解(Annotation),也叫元数据。一种代码级别的说明。它是JDK1.5及以后版本引入的一个特性,与类、接口、枚举是在同一个层次。它可以声明在包、类、字段、方法、局部变量、方法参数等的前面,用来对这些元素进行说明,注释。
* 概念描述:* JDK1.5之后的新特性* 说明程序的* 使用注解:@注解名称
* 作用分类:①编写文档:通过代码里标识的注解生成文档【生成文档doc文档】②代码分析:通过代码里标识的注解对代码进行分析【使用反射】③编译检查:通过代码里标识的注解让编译器能够实现基本的编译检查【Override】 * JDK中预定义的一些注解* @Override :检测被该注解标注的方法是否是继承自父类(接口)的* @Deprecated:该注解标注的内容,表示已过时* @SuppressWarnings:压制警告* 一般传递参数all @SuppressWarnings("all")* 自定义注解* 格式:元注解public @interface 注解名称{属性列表;}* 本质:注解本质上就是一个接口,该接口默认继承Annotation接口* public interface MyAnno extends java.lang.annotation.Annotation {}* 属性:接口中的抽象方法* 要求:1. 属性的返回值类型有下列取值* 基本数据类型* String* 枚举* 注解* 以上类型的数组2. 定义了属性,在使用时需要给属性赋值1. 如果定义属性时,使用default关键字给属性默认初始化值,则使用注解时,可以不进行属性的赋值。2. 如果只有一个属性需要赋值,并且属性的名称是value,则value可以省略,直接定义值即可。3. 数组赋值时,值使用{}包裹。如果数组中只有一个值,则{}可以省略* 元注解:用于描述注解的注解* @Target:描述注解能够作用的位置* ElementType取值:* TYPE:可以作用于类上* METHOD:可以作用于方法上* FIELD:可以作用于成员变量上* @Retention:描述注解被保留的阶段* @Retention(RetentionPolicy.RUNTIME):当前被描述的注解,会保留到class字节码文件中,并被JVM读取到* @Documented:描述注解是否被抽取到api文档中* @Inherited:描述注解是否被子类继承 * 在程序使用(解析)注解:获取注解中定义的属性值1. 获取注解定义的位置的对象 (Class,Method,Field)2. 获取指定的注解* getAnnotation(Class)//其实就是在内存中生成了一个该注解接口的子类实现对象public class ProImpl implements Pro{public String className(){return "cn.itcast.annotation.Demo1";}public String methodName(){return "show";}}3. 调用注解中的抽象方法获取配置的属性值
180.反射概述
●反射是指对于任何一-个Class类, 在"运行的时候"都可以直接得到这个类全部成分。●在运行时, 可以直接得到这个类的构造器对象: Constructor●在运行时,可以直接得到这个类的成员变量对象: Field●在运行时,可以直接得到这个类的成员方法对象: Method●这种运行时动态获取类信息以及动态调用类中成分的能力称为Java语言的反射机制。
181. 反射的基本作用、关键?
●反射是在运行时获取类的字节码文件对象:然后可以解析类中的全部成分。●反射的核心思想和关键就是:得到编译以后的class文件对象。
182. 获取class对象
反射的第一步 是什么?●获取Class类对象, 如此才可以解析类的全部成分获取Class类的对象的三种方式●方式-: Class c1 = Class.forName(“全类名”);●方式二: Class c2=类名.class●方式三: Class c3 =对象.getClass();
183.反射获取构造器对象
184.利用反射技术获取构造器对象的方式
■getDeclaredConstructors()■getDeclaredConstructor (Class<?>... parameterTypes)
185反射得到的构造器可以做什么?
●依然是创建对象的■public newInstance(0bject... initargs)
186.如果是非public的构造器,需要打开权限(暴力反射) ,然后再创建对象
■setAccessible(boolean)■反射可以破坏封装性, 私有的也可以执行了。
187.反射获取成员变量对象
使用反射技术获取成员变量对象并使用●获取成员变量的作用依然是在某个对象中取值、赋值Field类中用于取值、赋值的方法符号说明void set(Object obj, Object value): 赋值Object get(Object obj)获取值。
1.利用反射技术获取成员变量的方式●获取类中成员变量对象的方法.■getDeclaredFields()■getDeclaredField (String name )2.反射得到成员变量可以做什么?●依然是在某个对象中取值和赋值。■void set(0bject obj, 0bject value):■object get(0bject obj )●如果某成员变量是非public的,需要打开权限(暴力反射),然后再取值、赋值■setAccessible(boolean)
188.反射获取方法对象
使用反射技术获取方法对象并使用●反射的第一步是先得到类对象, 然后从类对象中获取类的成分对象。●Class类中用于获取成员方法的方法方法说明Method[] getMethods()返回所有成员方法对象的数组(只能拿public的)Method[] getDeclaredMethods()返回所有成员方法对象的数组,存在就能拿到Method getMethod(String name,Class<?>... parameterTypes)返回单个成员方法对象(只能拿public的)Method getDeclaredMethod(String name, Class<?>... parameterTypes )返回单个成员方法对象,存在就能拿到
使用反射技术获取方法对象并使用●获取成员方法的作用依然是在某个对象中进行执行此方法Method类中用于触发执行的方法符号说明运行方法参数一:用obj对象调用该方法Object invoke(Object obj, object... args)参数二:调用方法的传递的参数(如果没有就不写)返回值:方法的返回值(如果没有就不写)
利用反射技术获取成员方法对象的方式●获取类中成员方法对象■getDeclaredMethods()■getDeclaredMethod (String name, Class<?>... parameterTypes)反射得到成员方法可以做什么?●依然是在某个对象中触发该方法执行。■0bject invoke(0bject obj, 0bject... args)●如果某成员方法是非public的,需要打开权限(暴力反射),然后再触发执行■setAccessible(boolean)
189.反射的作用-绕过编译阶段为集合添加数据
●反射是作用在运行时的技术,此时集合的泛型将不能产生约束了,此时是可以为集合存入其他任意类型的元素的。ArrayList<Integer> list = new ArrayList<>();list.add(100);// list.add(“黑马"); //报错list.add(99);●泛型只是在编译阶段可以约束集合只能操作某种数据类型,在编译成Class文件进入运行阶段的时候,其真实类型都是ArrayList了,泛型相当于被擦除了。
190.反射为何可以给约定了泛型的集合存入其他类型的元素?
●编译成Class文件进入运行阶段的时候, 泛型会自动擦除。●反射是作用在运行时的技术,此时已经不存在泛型了。
191.反射的作用?
●可以在运行时得到-个类的全部成分然后操作。●可以破坏封装性。( 很突出)●也可以破坏泛型的约束性。(很突出)●更重要的用途是适合:做Java高级框架**
192.注解的作用
●对Java中类,方法、成员变量做标记,然后进行特殊处理。
●例如: jUnit框架中,标记了注解@Test的方法就可以被当成测试方法执
行,而没有标记的就不能当成测试方法执行
193.自定义注解
●自定义注解就是自己做一个注解来使用。public @interface 注解名称{public 属性类型 属性名() default 默认值;}
194.元注解
元注解:就是注解注解的注解。
元注解有两个:●@Target:约束自定义注解只能在哪些地方使用,
@Target中可使用的值定义在ElementType枚举类中,常用值如下■TYPE,类,接口FIELD,成员变量.■METHOD,成员方法■PARAMETER,方法参数■CONSTRUCTOR,构造器■LOCAL_ VARIABLE,局部变量
●@Retention:申明注解的生命周期
@Retention中可使用的值定义在RetentionPolicy枚举类中,常用值如下■SOURCE: 注解只作用在源码阶段,生成的字节码文件中不存在■CLASS: 注解作用在 源码阶段,字节码文件阶段,运行阶段不存在,默认值.■RUNTIME:注解作用在源码阶段,字节码文件阶段,运行阶段(开发常用)
195.注解的解析
动态代理● 代理 就是被代理者没有能力或者不愿意去完成某件事情,需要找个人代替自己去完成这件事,动态代理就是用来对业务功能(方法)进行代理的。 关键步骤1.必须有接口,实现类要实现接口(代理通常是基于接口实现的)。 3.创建一个实现类的对象,该对象为业务对象,紧接着为业务对象做-一个代理对象。 动态代理的优点●非常的灵活,支持任意接口类型的实现类对象做代理,也可以直接为接本身做代理。●可以为被代理对象的所有方法做代理。●可以在不改变方法源码的情况下,实现对方法功能的增强。●不仅简化了编程工作、提高了软件系统的可扩展性,同时也提高了开发效率。