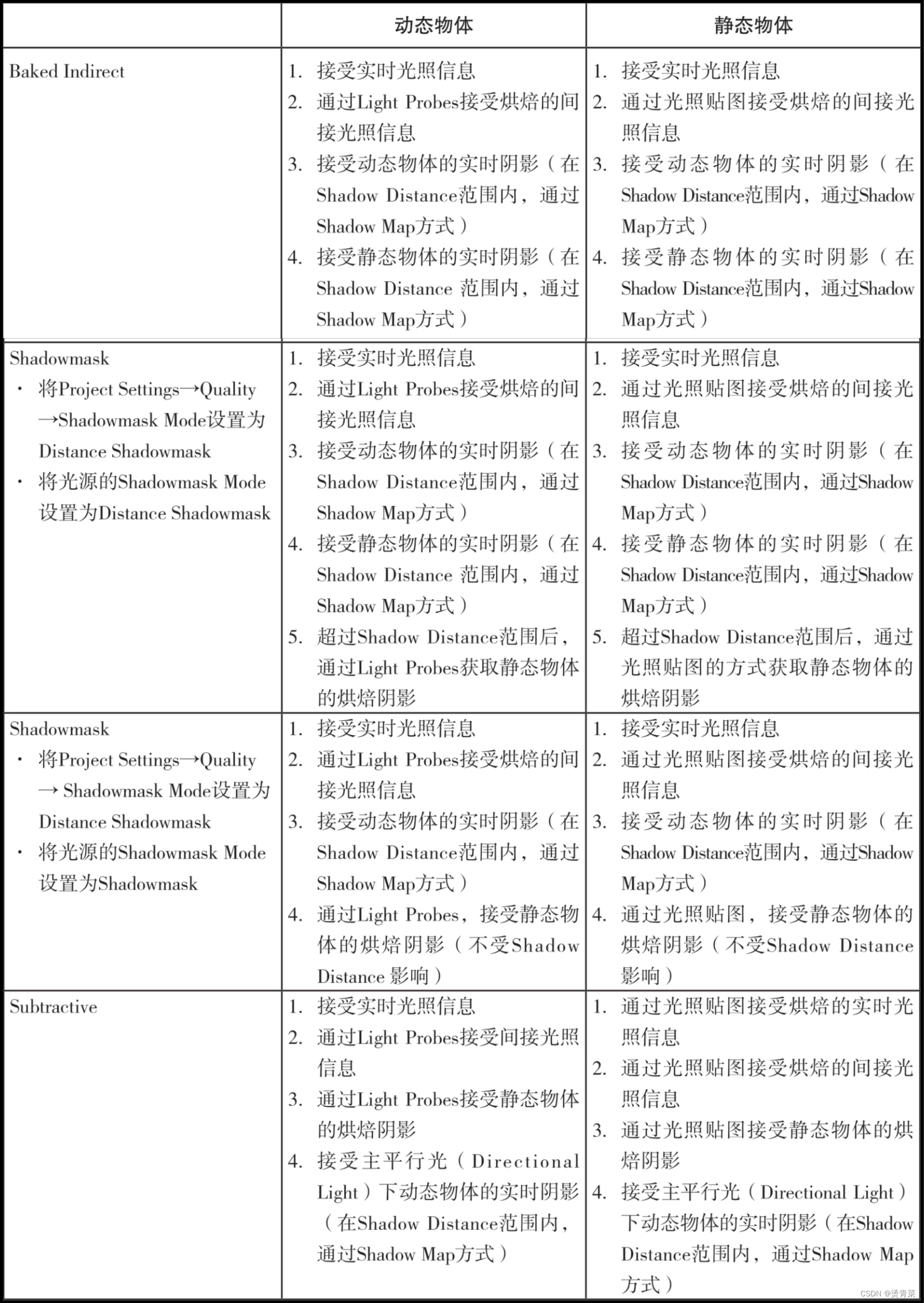
接上篇:Redis的数据类型及对应的数据结构(一)_鱼跃鹰飞的博客-CSDN博客
本篇主要讨论剩下的几种数据结构的应用场景
应用场景
集合的主要几个特性,无序、不可重复、支持并交差等操作。
因此 Set 类型比较适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等,当我们存储的数据是无序并且需要去重的情况下,比较适合使用集合类型进行存储。
但是要提醒你一下,这里有一个潜在的风险。Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。
在主从集群中,为了避免主库因为 Set 做聚合计算(交集、差集、并集)时导致主库被阻塞,我们可以选择一个从库完成聚合统计,或者把数据返回给客户端,由客户端来完成聚合统计。
点赞
Set 类型可以保证一个用户只能点一个赞,这里举例子一个场景,key 是文章id,value 是用户id。
uid:1 、uid:2、uid:3 三个用户分别对 article:1 文章点赞了。
# uid:1 用户对文章 article:1 点赞
> SADD article:1 uid:1
(integer) 1
# uid:2 用户对文章 article:1 点赞
> SADD article:1 uid:2
(integer) 1
# uid:3 用户对文章 article:1 点赞
> SADD article:1 uid:3
(integer) 1
uid:1 取消了对 article:1 文章点赞。
> SREM article:1 uid:1
(integer) 1
获取 article:1 文章所有点赞用户 :
> SMEMBERS article:1
1) "uid:3"
2) "uid:2"
获取 article:1 文章的点赞用户数量:
> SCARD article:1
(integer) 2
判断用户 uid:1 是否对文章 article:1 点赞了:
> SISMEMBER article:1 uid:1
(integer) 0 # 返回0说明没点赞,返回1则说明点赞了
共同关注
Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。
key 可以是用户id,value 则是已关注的公众号的id。
uid:1 用户关注公众号 id 为 5、6、7、8、9,uid:2 用户关注公众号 id 为 7、8、9、10、11。
# uid:1 用户关注公众号 id 为 5、6、7、8、9
> SADD uid:1 5 6 7 8 9
(integer) 5
# uid:2 用户关注公众号 id 为 7、8、9、10、11
> SADD uid:2 7 8 9 10 11
(integer) 5
uid:1 和 uid:2 共同关注的公众号:
# 获取共同关注
> SINTER uid:1 uid:2
1) "7"
2) "8"
3) "9"
给 uid:2 推荐 uid:1 关注的公众号:
> SDIFF uid:1 uid:2
1) "5"
2) "6"
验证某个公众号是否同时被 uid:1 或 uid:2 关注:
> SISMEMBER uid:1 5
(integer) 1 # 返回0,说明关注了
> SISMEMBER uid:2 5
(integer) 0 # 返回0,说明没关注
抽奖活动
存储某活动中中奖的用户名 ,Set 类型因为有去重功能,可以保证同一个用户不会中奖两次。
key为抽奖活动名,value为员工名称,把所有员工名称放入抽奖箱 :
>SADD lucky Tom Jerry John Sean Marry Lindy Sary Mark
(integer) 5
如果允许重复中奖,可以使用 SRANDMEMBER 命令。
# 抽取 1 个一等奖:
> SRANDMEMBER lucky 1
1) "Tom"
# 抽取 2 个二等奖:
> SRANDMEMBER lucky 2
1) "Mark"
2) "Jerry"
# 抽取 3 个三等奖:
> SRANDMEMBER lucky 3
1) "Sary"
2) "Tom"
3) "Jerry"
如果不允许重复中奖,可以使用 SPOP 命令。
# 抽取一等奖1个
> SPOP lucky 1
1) "Sary"
# 抽取二等奖2个
> SPOP lucky 2
1) "Jerry"
2) "Mark"
# 抽取三等奖3个
> SPOP lucky 3
1) "John"
2) "Sean"
3) "Lindy"
Zset
介绍
Zset 类型(有序集合类型)相比于 Set 类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序集合的元素值,一个是排序值。
有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。
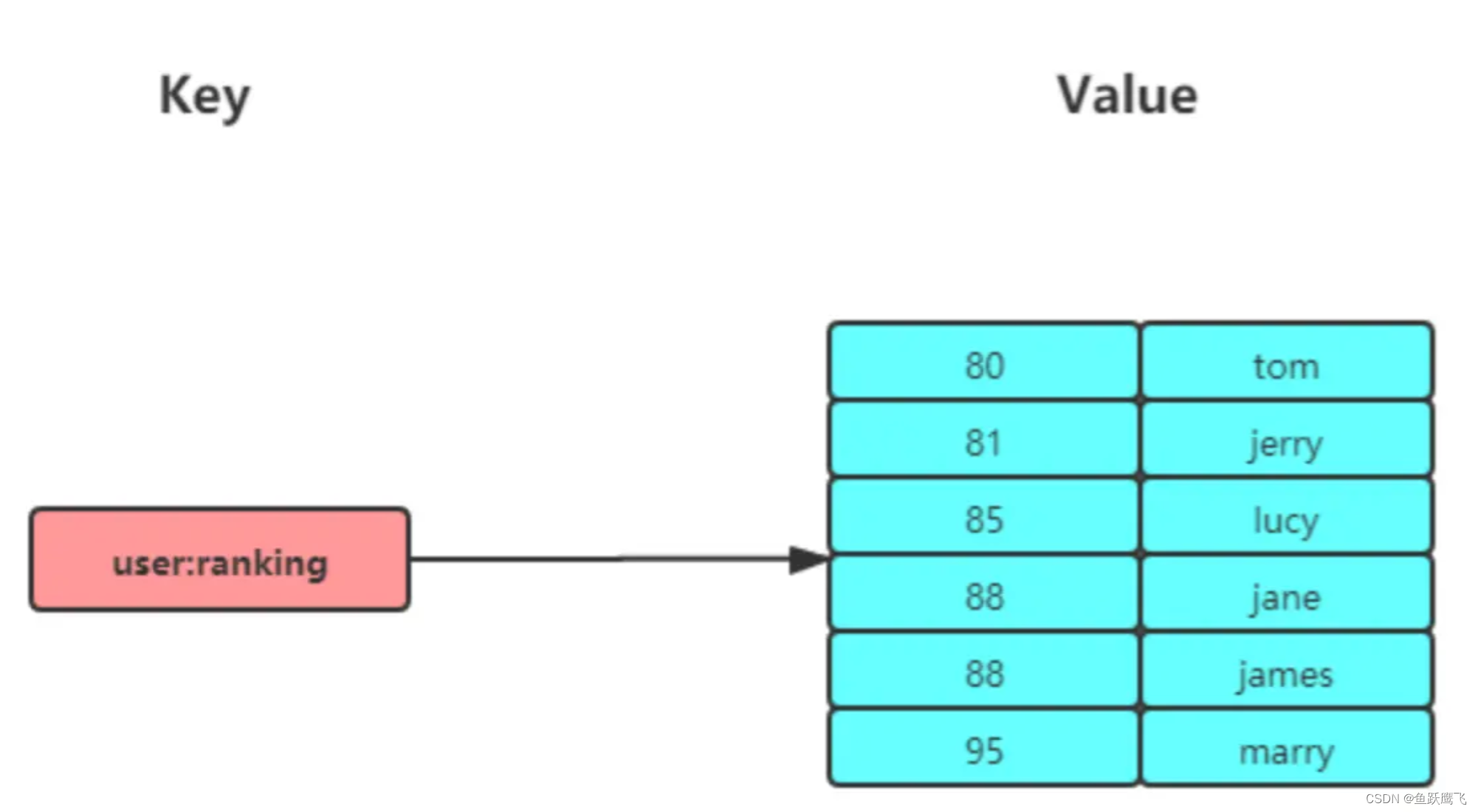
内部实现
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
- 如果有序集合的元素个数小于
128个,并且每个元素的值小于64字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构; - 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
常用命令
Zset 常用操作:
# 往有序集合key中加入带分值元素
ZADD key score member [[score member]...]
# 往有序集合key中删除元素
ZREM key member [member...]
# 返回有序集合key中元素member的分值
ZSCORE key member
# 返回有序集合key中元素个数
ZCARD key # 为有序集合key中元素member的分值加上increment
ZINCRBY key increment member # 正序获取有序集合key从start下标到stop下标的元素
ZRANGE key start stop [WITHSCORES]
# 倒序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES]# 返回有序集合中指定分数区间内的成员,分数由低到高排序。
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]# 返回指定成员区间内的成员,按字典正序排列, 分数必须相同。
ZRANGEBYLEX key min max [LIMIT offset count]
# 返回指定成员区间内的成员,按字典倒序排列, 分数必须相同
ZREVRANGEBYLEX key max min [LIMIT offset count]
Zset 运算操作(相比于 Set 类型,ZSet 类型没有支持差集运算):
# 并集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积
ZUNIONSTORE destkey numberkeys key [key...]
# 交集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积
ZINTERSTORE destkey numberkeys key [key...]
应用场景
Zset 类型(Sorted Set,有序集合) 可以根据元素的权重来排序,我们可以自己来决定每个元素的权重值。比如说,我们可以根据元素插入 Sorted Set 的时间确定权重值,先插入的元素权重小,后插入的元素权重大。
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,可以优先考虑使用 Sorted Set。
排行榜
有序集合比较典型的使用场景就是排行榜。例如学生成绩的排名榜、游戏积分排行榜、视频播放排名、电商系统中商品的销量排名等。
我们以博文点赞排名为例,小林发表了五篇博文,分别获得赞为 200、40、100、50、150。
# arcticle:1 文章获得了200个赞
> ZADD user:xiaolin:ranking 200 arcticle:1
(integer) 1
# arcticle:2 文章获得了40个赞
> ZADD user:xiaolin:ranking 40 arcticle:2
(integer) 1
# arcticle:3 文章获得了100个赞
> ZADD user:xiaolin:ranking 100 arcticle:3
(integer) 1
# arcticle:4 文章获得了50个赞
> ZADD user:xiaolin:ranking 50 arcticle:4
(integer) 1
# arcticle:5 文章获得了150个赞
> ZADD user:xiaolin:ranking 150 arcticle:5
(integer) 1
文章 arcticle:4 新增一个赞,可以使用 ZINCRBY 命令(为有序集合key中元素member的分值加上increment):
> ZINCRBY user:xiaolin:ranking 1 arcticle:4
"51"
查看某篇文章的赞数,可以使用 ZSCORE 命令(返回有序集合key中元素个数):
> ZSCORE user:xiaolin:ranking arcticle:4
"50"
获取小林文章赞数最多的 3 篇文章,可以使用 ZREVRANGE 命令(倒序获取有序集合 key 从start下标到stop下标的元素):
# WITHSCORES 表示把 score 也显示出来
> ZREVRANGE user:xiaolin:ranking 0 2 WITHSCORES
1) "arcticle:1"
2) "200"
3) "arcticle:5"
4) "150"
5) "arcticle:3"
6) "100"
获取小林 100 赞到 200 赞的文章,可以使用 ZRANGEBYSCORE 命令(返回有序集合中指定分数区间内的成员,分数由低到高排序):
> ZRANGEBYSCORE user:xiaolin:ranking 100 200 WITHSCORES
1) "arcticle:3"
2) "100"
3) "arcticle:5"
4) "150"
5) "arcticle:1"
6) "200"
电话、姓名排序
使用有序集合的 ZRANGEBYLEX 或 ZREVRANGEBYLEX 可以帮助我们实现电话号码或姓名的排序,我们以 ZRANGEBYLEX (返回指定成员区间内的成员,按 key 正序排列,分数必须相同)为例。
注意:不要在分数不一致的 SortSet 集合中去使用 ZRANGEBYLEX和 ZREVRANGEBYLEX 指令,因为获取的结果会不准确。
1、电话排序
我们可以将电话号码存储到 SortSet 中,然后根据需要来获取号段:
> ZADD phone 0 13100111100 0 13110114300 0 13132110901
(integer) 3
> ZADD phone 0 13200111100 0 13210414300 0 13252110901
(integer) 3
> ZADD phone 0 13300111100 0 13310414300 0 13352110901
(integer) 3
获取所有号码:
> ZRANGEBYLEX phone - +
1) "13100111100"
2) "13110114300"
3) "13132110901"
4) "13200111100"
5) "13210414300"
6) "13252110901"
7) "13300111100"
8) "13310414300"
9) "13352110901"
获取 132 号段的号码:
> ZRANGEBYLEX phone [132 (133
1) "13200111100"
2) "13210414300"
3) "13252110901"
获取132、133号段的号码:
> ZRANGEBYLEX phone [132 (134
1) "13200111100"
2) "13210414300"
3) "13252110901"
4) "13300111100"
5) "13310414300"
6) "13352110901"
2、姓名排序
> zadd names 0 Toumas 0 Jake 0 Bluetuo 0 Gaodeng 0 Aimini 0 Aidehua
(integer) 6
获取所有人的名字:
> ZRANGEBYLEX names - +
1) "Aidehua"
2) "Aimini"
3) "Bluetuo"
4) "Gaodeng"
5) "Jake"
6) "Toumas"
获取名字中大写字母A开头的所有人:
> ZRANGEBYLEX names [A (B
1) "Aidehua"
2) "Aimini"
获取名字中大写字母 C 到 Z 的所有人:
> ZRANGEBYLEX names [C [Z
1) "Gaodeng"
2) "Jake"
3) "Toumas"