在MySQL中,可以使用自连接(self-join)来获取上一条记录的结束时间和下一条记录的开始时间,并将它们组合成一条记录。首先,需要为表创建一个包含记录ID和时间信息的临时表,然后使用自连接获取相邻记录的时间信息。
数据准备:
-- demo.schedule definitionCREATE TABLE `schedule` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',`start_time` datetime NOT NULL,`end_time` datetime NOT NULL,`employee_id` int(10) unsigned DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=latin1;
INSERT INTO demo.schedule
(start_time, end_time, employee_id)
VALUES('2023-09-08 07:50:00', '2023-09-08 12:00:00', 1);
INSERT INTO demo.schedule
(start_time, end_time, employee_id)
VALUES('2023-09-08 12:40:00', '2023-09-08 17:20:00', 1);
INSERT INTO demo.schedule
(start_time, end_time, employee_id)
VALUES('2023-09-08 18:10:00', '2023-09-08 20:30:00', 1);以下是一个示例查询,假设你的表名为schedule,其中包含id和start_time、end_time字段:
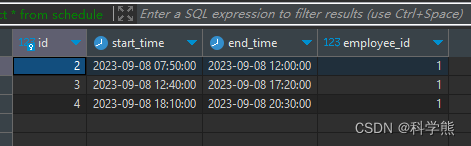
select * from schedule;
输出:
-- 创建临时表并插入数据
CREATE TEMPORARY TABLE temp_schedule (prev_id INT,curr_id INT,prev_end_time DATETIME,curr_start_time DATETIME
);INSERT INTO temp_schedule (prev_id, curr_id, prev_end_time, curr_start_time)
SELECTt1.id AS prev_id,t2.id AS curr_id,t1.end_time AS prev_end_time,t2.start_time AS curr_start_time
FROMschedule t1
JOINschedule t2 ON t1.id = t2.id - 1;select * from temp_schedule
输出:
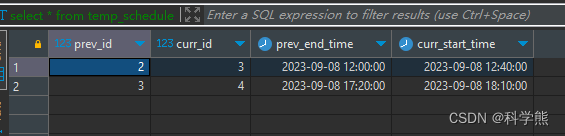
这个查询将创建一个名为temp_schedule的临时表,其中包含相邻记录的ID、上一条记录的结束时间和下一条记录的开始时间。最后,通过在临时表上执行查询,选择上一条记录的结束时间和下一条记录的开始时间的结果。
注意:这个查询假设记录按时间顺序排列,并且每个记录的ID是唯一的。如果你的表结构或数据不符合这些要求,你需要根据实际情况进行调整。