在日常工作中,你是否也遇到过下面几种情况:
-
使用一个已有接口进行业务开发,上线后出现严重的性能问题,被老板当众质疑:“你为什么不使用缓存接口,这个接口全部走数据库,这怎么能抗住!”
-
开发一个后台管理功能,业务反馈说数据一直不对,对比后发现缓存与数据库不一致,为什么要使用缓存接口呢,你陷入沉思?
-
产品要求在 xxx 上增加新功能,编码、测试、上线一气呵成,最后发现另外一个流程被躺枪,出现异常不得不进行回滚!
-
在一个高并发的场景,DB 成为了系统瓶颈,不加索引查询扛不住,加索引更新扛不住,又该如何处理?
-
随着数据量的激增,系统变得越来越慢,特别是后台管理复杂的查询场景下,复杂的 Join 让 DB 不堪重负
-
……
为什么会出现这种现象?其本质仍旧是代码组织结构不合理,我们将不同的复杂性揉在一起,从而造成了更大的复杂性,然后如此往复,不知不觉中陷入巨大的复杂性旋涡不可自拔。
1. CQRS 是什么?
CQRS 是 Command Query Responsibility Segregation 得简称,简单理解就是对 “写”(Command) 和 “读” (Query)操作进行分离。反应快的同学会说:“也不是什么高深技术吗,不就是数据库的读写分离吗?”
是的,数据库的读写分离也算是一种 CQRS,但 CQRS 的含义要比这复杂的多。
CRQS 既是一种流行的业务架构,又是一种设计思维。
CQRS 的核心是“拆分”,将复杂系统拆分为 Command 和 Query 两个部分,针对不同的场景使用不同的模式,选择最合适的技术落地最佳解决方案,避免两者相互掣肘相互影响。
CQRS的目的是降低整个系统的复杂性,那它背后的逻辑是什么?
假设,在一个系统中:
-
Command 的复杂性为 M
-
Query 的复杂性为 N
如果使用同一套模型来处理 Command 和 Query,那在极端情况下,系统的复杂性为 M * N,因为两者相互影响,调整一方的同时要时刻关注对另一方的影响。
这种“你中有我,我中有你”的设计方式,“两者的相互影响”成为系统最为复杂之处,大量精力消耗在“排查影响”,而非最有价值的设计和编码。
如果,将 Command 和 Query 彻底分离,系统的复杂性变成 M + N。Command 的变更不会影响 Query,而 Query 的修改也不会影响 Command。
当然,以上两个极端在实际工作中也很少见,通常系统的复杂性介于两者之间。
这只是从理论进行推导,在实际工作中随处可见的“冲突”也是对“拆分”的一种暗示。
2. 分层架构中的冲突
以最常见的分层架构进行介绍,具体如下:

如图所示,将系统分成5层,每层的含义如下:
-
Web 接入层。主要用于处理系统输入,对输入信息进行验证,调用应用服务完成业务操作,对结果进行转换,最终返回给调用方;
-
应用服务层。主要处理业务流程编排,从仓库中获取领域对象,执行领域模型的业务操作,将最新的对象状态通过仓库同步到数据存储引擎,并对外发布领域事件;
-
领域层。业务逻辑的承载点,是业务价值的集中体现,通常构建于面向对象设计之上,基于封装、继承、多态等特性保障业务逻辑的复用性和扩展性;
-
仓库层。主要用于数据访问,向上为应用服务提供数据操作服务,向下屏蔽各类存储引擎的差异;
-
数据层。主要用于数据保存和检索,常见的数据存储引擎全部属于这一层,比如 MySQL、Redis、ES 等;
其实,分层架构本身也是一种“拆分”,将不同的关注点封装在不同的层次。但除了横向分层,还可以基于 CQRS 对其进行纵向拆分,也就是将每个层的组件拆分为 Command 和 Query 两部分。
由于接入层冲突较小,本身拆分的意义不大,在此不做要求,但从严格意义上讲,仍旧建议进行拆分。
3. 应用服务层冲突与拆分
应用服务层拆分就是将一个应用服务拆分为 CommandService 和 QueryService 两组。

这样做可以避免很多不必要的麻烦,Command 和 Query 存在较大的区别,具体如下:
| CommandService | QueryService | |
|---|---|---|
| 依赖组件不同 | ValidateService 验证服务;LazyLoaderFactory 延迟加载服务;CommandRepository 不带缓存的仓库;EventPublisher 事件发表器 | QueryRepository 带缓存功能的仓库;JoinService 数据聚合服务;Converter 数据转换服务 |
| 核心流程不同 | 验证、加载、业务操作、同步、发布事件 | 验证、加载、数据组装、转换 |
| 功能加强不同 | 主要是事务管理器 | 主要是缓存组件 |
回想开篇时提到的场景,完成应用层拆分,就不在为使用错组件而烦恼:
-
CommandService 的 Repository 不使用缓存,仅操作数据库
-
QueryService 的 Repository 可以使用缓存,以提升访问性能
除此之外,针对统一的操作流程,还可以进一步抽象来消除重复的“模板代码”,比如:
-
引入“模板方法设计模式” 以达到核心逻辑的复用
-
抽象出 BaseCommandService 和 BaseQueryService 两个父类用于统一核心流程
-
子类实现 BaseCommandService 和 BaseQueryService 的抽象方法完成功能扩展
-
-
基于“约定优于配置” 使用 Proxy 模型,只定义接口不写实现代码
-
按规范定义 CommandService 和 QueryService 接口,通过注解完成相关配置
-
自动生成 Proxy 实现类,完成流程编排
-
4. 模型层冲突与拆分
模型层是系统的核心,它的设计直接影响整个系统的质量。作为承接业务逻辑的核心,比较流程的实现策略包括:
-
DDD 领域驱动设计,其核心是使用面向对象的高级特性(封装、继承、多态、组合等)来进行设计,非常适合复杂的业务场景。其体现就是存在很多高内聚低耦合的对象组(聚合根),业务逻辑由这些小对象相互协作共同完成;
-
事务脚本,使用过程式思维,将数据操作编织到流程中,比较适合并不复杂的业务场景。其体现就是存在很多“上帝 Service”,Service 中存在很多非常长的方法,业务逻辑由这些方法完成;
关于哪个才是最优解,网上已经争论多年,最终也没有结论。但我始终认为“没有业务场景就讨论方案,就是在耍流氓”。
从不同应用场景出发便可得到如下结论:
-
Command 场景需要保障严谨的业务逻辑,通常复杂性偏高,所以DDD 是最优解
-
Query 场景需要更灵活的数据组装能力作为支持,通常比较简单,所以 事务脚本 是最优解
我经常说:“最简单的“写”也是复杂,最复杂的“读”也是简单”,其背后逻辑是基于对 Command 和 Query 的场景判断。
将模型拆分为 Command 和 Query,具体如下:
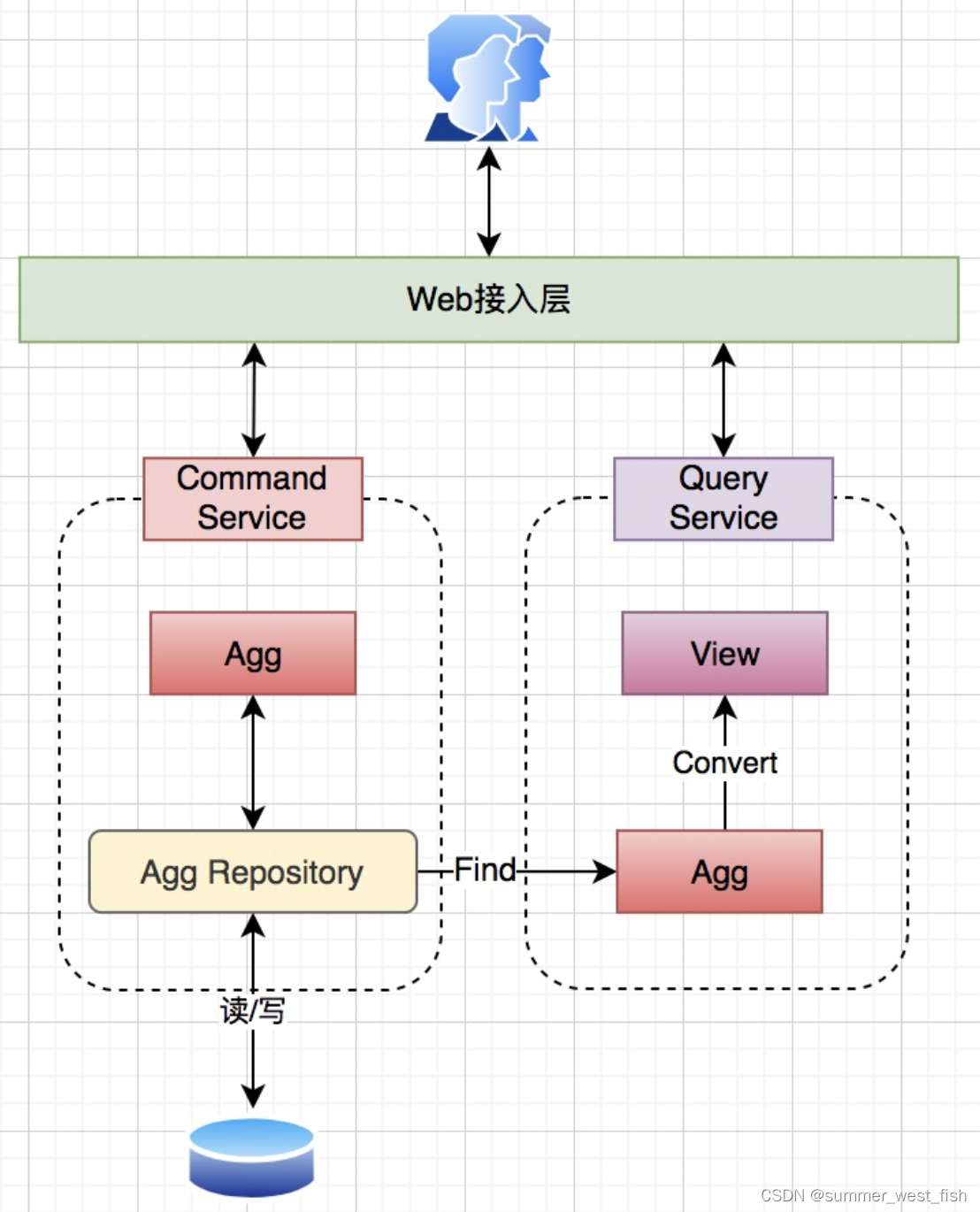
完成模型拆分后,新模型具有以下特征:
-
Agg 也就是 DDD 中聚合根,主要用于处理复杂的 Command 逻辑,由具有大量业务操作的"富对象"构成;
-
View 是标准的 POJO,主要充当 Query 结果对象,典型的“贫血对象”,仅作为数据的载体,根据展示需求对数据进行组装;
-
View 没有自己的 Repository,只能依赖 CommandRepository 获取数据,Converter 组件负责将 Agg 模型转换为 View 模型;
这块是拆分的重点,为了方便理解,简单举个例子:
比如在电商的订单模块:
-
生单流程,由 Order 作为聚合根对内部 OrderItem 和 PayInfo 进行统一协调
-
订单列表页,只需展示 Order 和 User 信息
-
订单详情,需要展示Order、User、Address、OrderItem、PayInfo、Product等信息
如果让一个模型同时支持着三个场景,那模型自己就变的非常复杂,很难判断某个方法、某个字段究竟属于哪个场景。
此时,应该根据场景对模型进行拆分:
-
OrderBO 以 DDD 方式进行建模,对外提供统一的业务操作,对内协调 OrderItem 和 PayInfo 等多个实体对象;
-
OrderListVO 以 POJO 方式进行建模,属性中包含 Order 和 User 信息;
-
OrderDetailVO 以 POJO 方式进行建模,属性中包括 Order、User、Address、OrderItem、PayInfo、Product 等信息;
三个模型相互独立,互不影响。
当然,由于使用统一的 Repository 还需提供对应 VO 的 Converter:
-
OrderListVOConverter 将 OrderBO 转换为 OrderListVO 对象
-
OrderDetailVOConverter 将 OrderBO 转化为 OrderDetailVO 对象
5. 仓库层冲突与拆分
仓库层拆分也是非常有必要的,在这一层主要有几项冲突:
| CommandRepository | QueryRepository | |
|---|---|---|
| 底层实现不同 | 主要基于 DB 实现 | 基于 DB、Redis、ES 等多种存储引擎 |
| 方法复杂性不同 | 提供仅有的少量方法并足以支持大多数场景,比如 save、update、getById 等 | 根据业务场景进行定制,方法多种多样(单条、批量、分页、排序、统计等),维度多种多样(id、user、status) |
| 返回值不同 | 直接返回装配完整的富对象 | 根据业务场景定制返回值 |
仓库拆分后整体架构如下:

仓库拆分具有以下特点:
-
View 不在需要 Converter 组件完成数据转换
-
View 的数据来自于自己的 Repository,可以根据展示需求进行灵活定制
-
Command 和 Query 仍旧使用同一套数据库、同一套数据表
6. 数据层冲突与拆分
数据层拆分是最重要的拆分,提到分离第一反应也是“数据库主从分离”。
数据层拆分的本质是:各种数据存储引擎的最佳应用场景相差巨大,读 和 写 优化往往存在矛盾。
仍旧以最常见的数据库为例:
-
提升查询性能,建议为各种查询维度建立索引
-
提升写入性能,需要让表上的索引越来越少
-
为了加速更新性能,建议使用三范式设计表结构,减少冗余信息
-
为了加速查询性能,建议使用反范式设计,尽量冗余数据,避免数据表间的 Join 操作
鱼和熊掌不可兼得,在数据库层展示的淋漓尽致!
数据层拆分后架构如下:
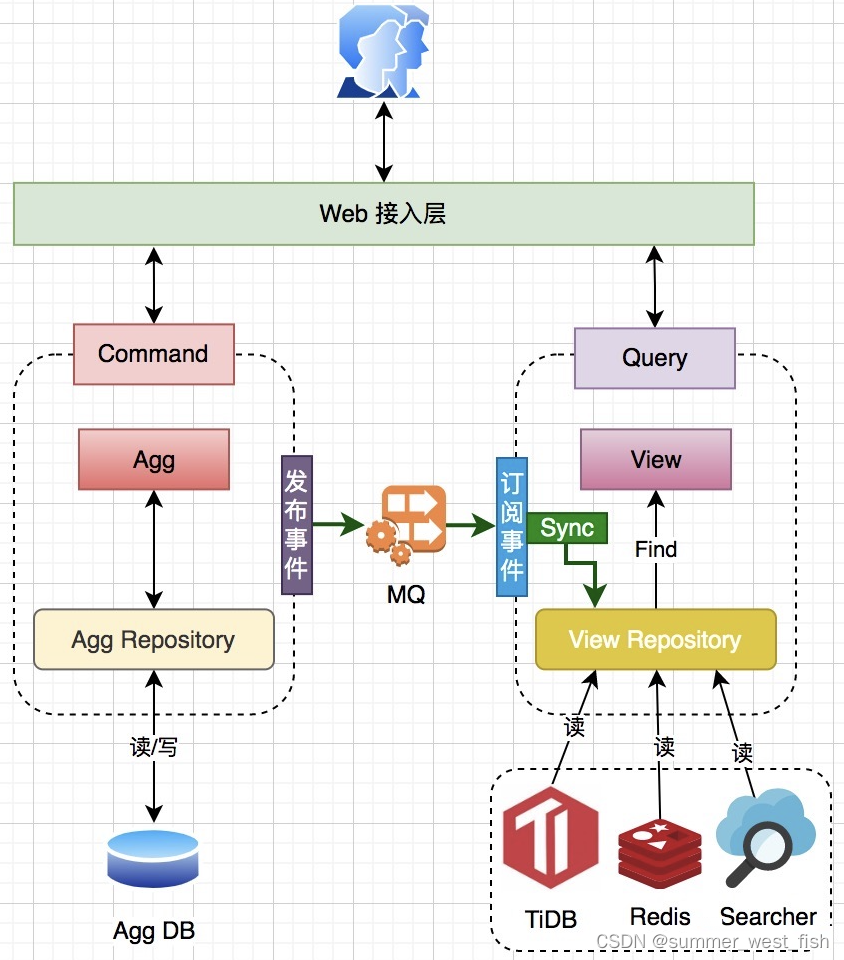
该模型具有以下特点:
-
数据存储进行了彻底拆分;Command 和 Query 都可以灵活的选择最合适的存储引擎;
-
Command 与 Query 需要引入一套同步机制以完成两者的数据同步,常见的同步机制有:
-
工作在应用层基于领域事件的数据同步,如图所示
-
工作在数据层基于log的数据同步,如 MySQL 的主从同步、Canal2XX 等
-
数据层拆分是大型系统最终的归宿,仍旧以订单系统为例:
-
订单作为一致性要求极高的系统,Command 侧首选仍旧为具有 ACID 的关系型数据库,哪怕是分库分表底层存储仍旧不变;
-
为了满足高性能查询需求,需要在 Query 侧引入 Redis 作为分布式缓存对访问进行加速;
-
为了满足后台复杂且多维度的业务查询,需要在 Query 侧引入 ES 为全文检索进行加速;
-
为了满足各种实时报表需求,需要在 Query 侧引入 TiDB 以满足海量数据的实时检索;
这就是我们面临的现状:“数据密集型系统”越来越多的应用程序有着各种严格而广泛的要求,单个工具不足以满足所有的数据处理和存储需求。取而代之的是,总体工作被拆分成一系列能被单个工具高效完成的任务,并通过应用代码将它们缝合起来,通过 API 的方式,对外提供服务,屏蔽内部的复杂性。
7. 关系型数据库性能提升方法
提升关系数据库性能是许多大型应用程序和网站面临的重要挑战之一。以下是两种常见的提升关系数据库性能的方式:
读写分离(Read-Write Separation)
-
概念:读写分离是一种将数据库的读操作和写操作分开处理的策略。通常,应用程序的读操作远远多于写操作,因此可以将读操作分配给一个或多个只负责读取数据的数据库服务器,而将写操作发送到主数据库服务器。
-
工作流程:
- 主数据库(写数据库):负责处理写操作,包括插入、更新和删除数据。
- 从数据库(读数据库):负责处理读操作,包括查询数据。从数据库通常是主数据库的复制,以确保数据的一致性。
-
优势:
- 提高读操作的性能,因为它们可以并行处理。
- 减轻主数据库的负载,使其更专注于写操作。
- 提高数据库的可伸缩性,通过添加更多的从数据库来支持更多的读操作。
-
注意事项:
- 数据复制可能导致一些延迟,因此读操作可能不会立即反映最新的写操作。
- 需要考虑数据一致性和同步策略。
分库分表(Sharding)
-
概念:分库分表是一种将数据库拆分成多个独立的子数据库或数据表的策略。每个子数据库或表负责存储特定范围或条件下的数据。这样,查询和写入可以分布到不同的数据库节点,减轻单一数据库的负载。
-
工作流程:
- 数据库表水平分片:根据数据的某个字段(例如,用户ID或时间戳)将数据分布到不同的表中。
- 数据库库水平分片:根据数据的某个属性(例如,地理位置或业务类型)将数据分布到不同的数据库中。
-
优势:
- 提高数据库的扩展性,因为数据可以分布在多个节点上。
- 减轻单一数据库的负载,提高性能。
- 使数据库更容易维护和备份,因为数据分散存储。
-
注意事项:
- 需要设计良好的分片策略,以确保数据均匀分布。
- 需要跨分片执行查询时,可能需要复杂的查询计划。
这些方法可以单独或结合使用,根据应用程序的需求和性能要求来选择。例如,一个大型电子商务网站可以使用读写分离来提高产品搜索的性能,并使用分库分表来处理订单数据的存储和检索。综合考虑这些策略可以帮助应对不同层面的数据库性能挑战。
8. 小结
“拆分”是“分离关注点”的重要手段之一。拆分的目的是将问题进行归类,然后采取有针对性的手段更好的解决问题。
CQRS 作为一种架构,将业务系统不同部分进行归类,接下来需要为 Command 和 Query 寻找最优解决方案:
-
Command,以 DDD 作为理论基础将战术模型中最佳实战进行落地,包括
-
聚合设计
-
仓库设计
-
LazyLoad + Context 模式
-
业务验证
-
领域事件
-
…
-
-
Query,以数据检索和组装作为核心能力,设计留给开发人员,实现留给框架,包括
-
QueryObject 查询对象模式
-
内存 Join 模式
-
宽表&冗余表模式
-