原创 | 文 BFT机器人

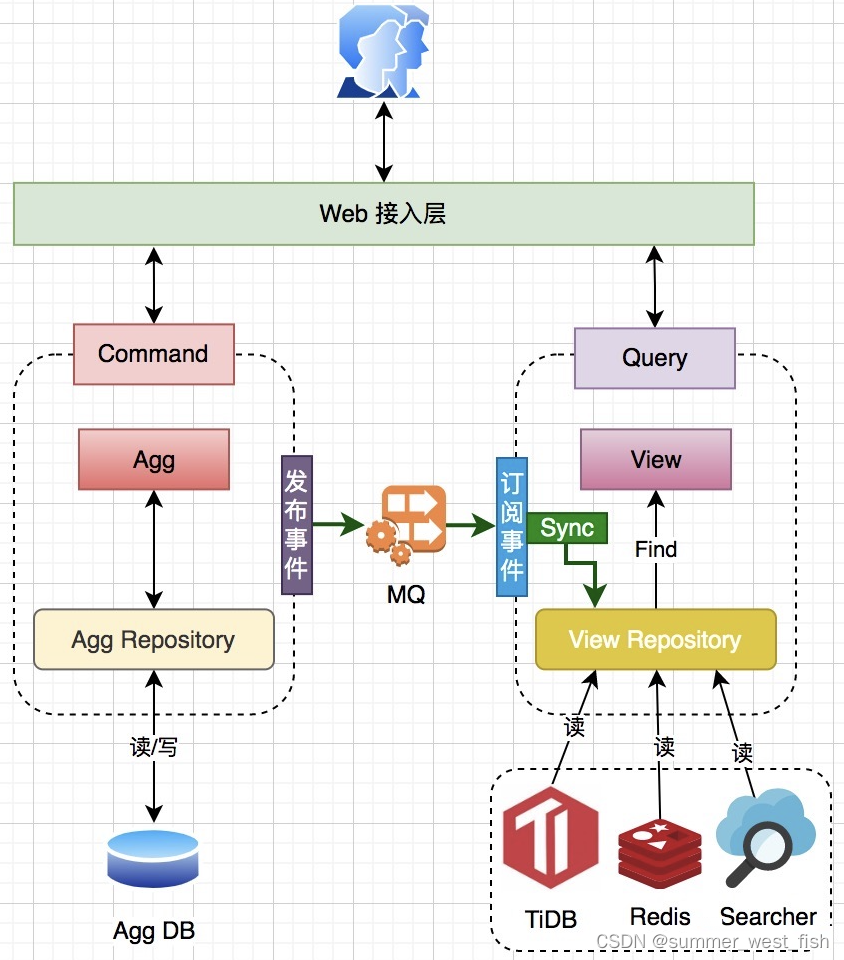
KITTI 是作为基准测试是自动驾驶中最具影响力的数据集之一,在学术界和工业界都被广泛使用。现有的三维对象检测器存在着两个限制。第一是现有方法的远程检测能力相对较差。其次,如何充分利用图像中的纹理信息仍然是一个开放性的问题。
多任务学习是三维目标检测的未来发展方向。有的学习了一个跨模态表示,以通过合并多个任务来实现最先进的检测性能。还有三维目标跟踪和场景流估计是一个新兴的研究课题得到了越来越多人的研究。
三维点云分割这一重要方向,它需要我们理解全局几何结构和每个点的细粒度细节。根据分割粒度分割方法可分为语义分割(场景级)、实例分割(目标级)和部分分割(部分级)三类。
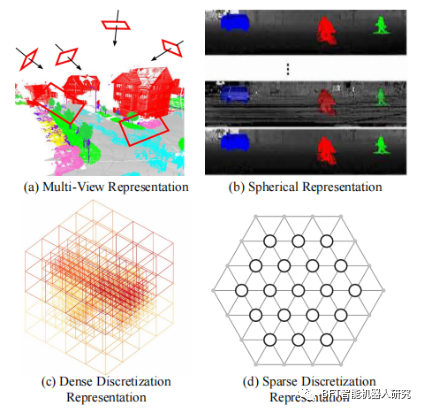
局部表示方法主要是通过对每个点的局部邻域进行建模来描述点云的局部特征,例如使用球形邻域或K近邻方法。全局表示方法则是通过对整个点云进行建模来描述点云的全局特征,例如使用基于几何形状的描述符或基于深度学习的方法。 主要讨论的是点云的局部和全局表示方法可以互相补充,从而提高点云的特征表达能力和分类性能。局部表示方法可以捕捉点云的局部特征和局部形状信息,而全局表示方法可以捕捉点云的全局特征和全局形状信息。因此,综合使用局部和全局表示方法可以更好地描述点云的形状和特征,提高点云的分类和识别性能。
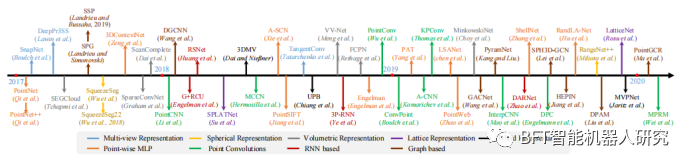
图2 基于深度学习的三维语义分割方法的时间顺序概述
点云表示中的采样和重构问题。具体来说,采样问题是指如何从原始点云中选择一部分点来表示整个点云,以减少计算量和存储空间。而重构问题则是指如何从采样点中重建出原始点云的形状和结构,以保证重构点云的准确性和完整性。采样过程中需要选择合适的采样密度和采样方法,以保证采样点的代表性和完整性。重构过程中需要选择合适的重构算法和参数,以保证重构点云的准确性和完整性,并尽可能减少重构误差和计算量。因此,该节的主要目的是介绍点云采样和重构的基本概念和方法,并讨论如何在采样和重构过程中平衡点云的准确性和效率。
01
实例分析
文中介绍了两种主要的语义分割方法:
基于图的方法和基于深度学习的方法。 基于图的方法主要是通过构建点云的图模型来实现语义分割,其中点云的每个点作为图的节点,点之间的关系作为图的边。然后,通过对图进行分割来实现点云的语义分割。
该方法的优点是可以利用点云的拓扑结构和几何信息,但是需要手动设计特征和权重,计算量较大。基于深度学习的方法主要是通过使用深度神经网络来实现点云的语义分割,其中点云的每个点作为网络的输入,网络输出每个点的语义类别。该方法的优点是可以自动学习特征和权重,计算量较小,但是需要大量的标注数据和计算资源。
零件分割
三维形状的零件分割的困难是双重的。首先,具有相同语义标签的形状部分具有较大的几何变化和模糊性。第二,具有相同语义意义的对象中的部分数量可能会有所不同。
零件分割是将三维形状分成其组成部分的任务,可用于形状分析和建模等任务。在零件分割中,一个三维形状被分成多个部分,每个部分都有一个语义标签。例如,在汽车的零件分割中,可以将汽车分成车门、车轮、引擎盖等部分。零件分割的难点在于,同一语义标签的形状部分具有很大的几何变化和歧义,而且具有相同语义含义的对象的零件数量可能不同。为了解决这些问题,研究人员提出了许多方法,例如基于体素的方法和基于表面的方法。其中,VoxSegNet和基于FCN的方法与基于表面的CRF相结合的方法是实现细粒度零件分割的一些方法。此外,零件分割还可以通过使用卷积神经网络(CNN)来实现。CNN可以从点云中提取特征,并将其用于零件分割。
此外,一些研究人员还使用图卷积神经网络(GCN)来处理点云数据,以实现更准确的零件分割。总的来说,零件分割是三维点云深度学习中的一个重要任务,其应用广泛,包括机器人、自动驾驶和虚拟现实等领域。
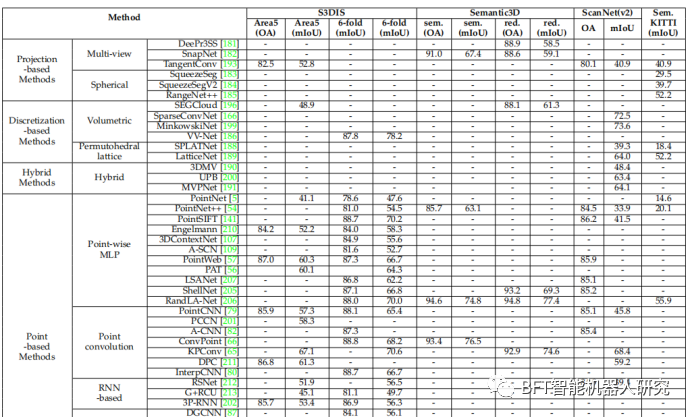
图3 S3DIS、语义3D、ScanNet和语义KITTI数据集的比较语义分割结果
02
总结
本文介绍了现在最先进的三维理解方法,包括三维形状分类、三维物体检测和跟踪,以及三维场景和物体分割。并对这些方法进行了全面的分类和性能比较。同时也介绍了各种方法的优缺点,并列出了潜在的研究方向。
作者 | 小雨点
排版 | 春花
审核 | 猫
若您对该文章内容有任何疑问,请于我们联系,将及时回应。如果想要了解更多的前沿资讯,记得点赞关注哦~