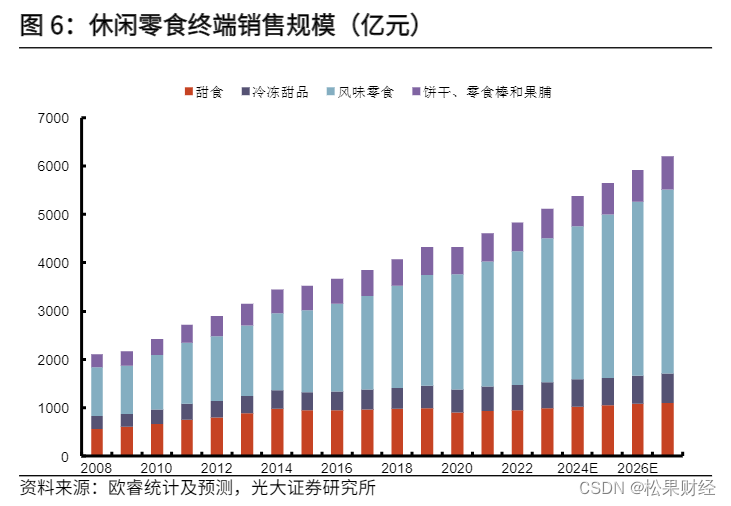
继上一篇浅谈高并发分布式架构演进路径,单体服务完成分布式架构改造,转型为微服务。随着微服务数量的急剧增加,跨应用、跨系统的调用越来越多,调用关系和依赖关系日益复杂,这种复杂性增加了系统的设计、实施和维护的难度。下图是由某系统生成的全局调用关系图:

带来的一些问题:
-
运维成本增加:分布式系统如何适应快速迭代上线,分布式系统如何处理节点故障;
-
资源成本增加:构建和维护分布式系统通常需要更多的资源、硬件、网络和人力投入,从而带来更高的成本;
-
系统集成: 将不同的分布式组件和服务集成到一个完整的系统中可能会导致兼容性和集成问题;
-
一致性难度增大:不同的一致性模型(如强一致性、弱一致性、最终一致性等)在不同的场景下可能会引发数据一致性问题,开发人员需要权衡不同的一致性要求;
-
数据分区与复制需要考虑: 数据在分布式系统中通常会被分区和复制到不同的节点上,以提高性能和可用性。然而,数据分区和复制会引发数据一致性、更新冲突等问题;
死锁与并发控制需要精通:在分布式系统中,由于资源分布在不同节点上,死锁和并发控制问题可能变得更加复杂,需要特殊的算法和机制来解决。
本篇将聊聊1~3方面的问题和解决方案,4~6会在下一篇数据一致性进行专题说明。对应运维成本和资源成本的增加,业界一般是通过云原生的能力来提升运维效率和资源使用率。
云
在说云相关技术前,先说一下什么是云计算。 “云”这个名字其实能困扰技术小白好长时间,什么是云?
云就是资源(如网络、服务器、存储、应用及服务等),云计算是一种资源的服务模式,该模式可以随时随地、便捷按需地从可配置计算资源共享池中获取所需的资源,资源能够快速供应并释放,大大减少了资源管理工作开销。
降低系统上云难度 - 容器
但随着云的发展,由于没有一个统一的标准,造成各家都有自己的云解决方案,如IaaS发展主要以虚拟机为最小粒度的资源单位,出现了资源利用率低、调度分发慢、软件栈环境不统一等问题。Docker技术的出现解决了虚机的一些问题,Docker容器以资源分割和调度为基本单位,封装整个软件运行时环境,是一个跨平台、可移植并简单易用的容器解决方案。Docker可在容器内部快速自动化的部署应用,并通过操作系统内核技术(namespaces、cgroups等)为容器提供资源隔离和安全保障。
Docker镜像
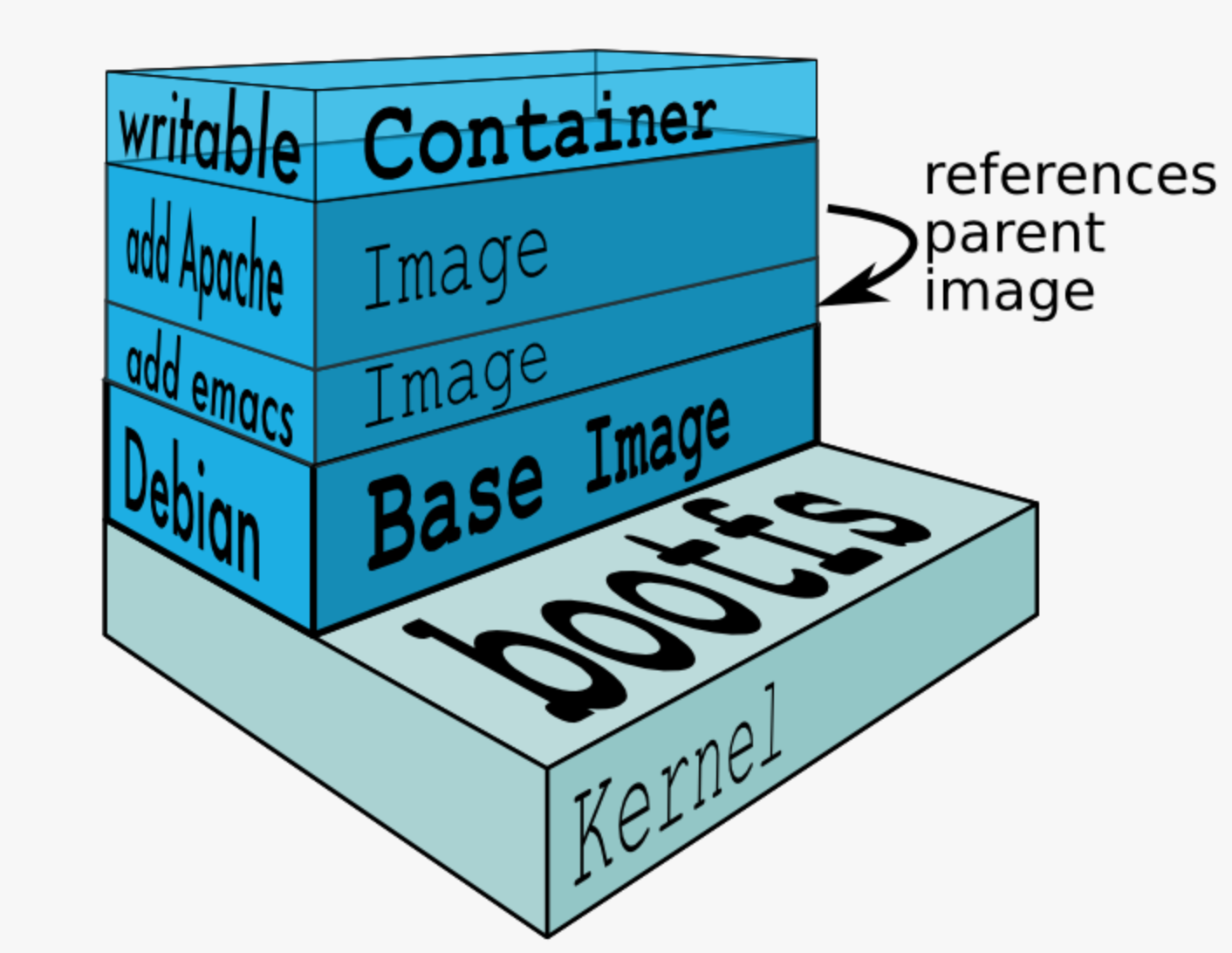
Docker镜像(Docker Image)就是一个只读的模板。比如,一个镜像可以包含一个完整的Ubuntu操作系统环境。其中只读层被称为镜像,镜像是永远不会变的。
仿真环境测试搭建场景
可别小看这个设计,有了这个设计可以使容器消除线上线下的环境差异,保证应用生命周期环境的一致性和标准化。比如阿里每年都会为双11做成千上万套预案和各种测试场景,如何将线上环境快速部署到测试环境,通过手动配置?这是不可能实现的。有了镜像技术,开发人员使用线上系统的Docker容器镜像,实现测试环境的构建,完全保证线上线下系统和环境完全一致,使测试更加准确真实。
基础组件更新替换场景
Docker这种一层一层的镜像技术,为基础插件更新和添加提供了极大的便利。举个栗子,公司有100台装有Java1.6环境的机器,现在需要将Java1.6统一升级到1.8,传统的运维解决方案就是一台一台的安装,如果使用Docker的话,只需要加一层JDK1.8的容器镜像,系统重新编译后重启一下就OK了,运维效率可以得到很大的提升。
容器编排及管理 - Kubernetes
Docker解决了节点级(单机)服务的一些问题,随着微服务系统拆分的越来越多,彼此之间解耦,具备了独立开发、部署、升级和伸缩能力,迭代频率变得越来越高。这就需要一整套业界标准的解决方案,Kubernetes基于上述需求提供了一套自动化运维解决措施,并形成了统一的业界标准,从而解决成千上万系统的管理问题,帮助企业获得更高的基础设施利用率。
比如一些常见的运维问题,如:
-
线上服务宕机问题,如何自动拉去、如何将重要的服务分不到不同的物理机中;
-
某核心服务线上几十个节点,如何保证线上自动化部署、如何保证上线时业务依然稳定运行。
Kubernetes提供了自动化容灾、无损上线和自动扩缩容等解决方案。
自动化容灾
在日常系统运维期间,对于一些影响到业务的核心系统是需要重点保障的,各个公司都有自己的各自解决方案,除了应急预案和日常应急演练外,常规的自动恢复功能也是要有的。在虚机时代常用的解决方案:
-
服务挂掉重启,可以通过监听系统进程,判断系统是否挂掉,通过Agent触发重启脚本,将应用拉起;
-
通过VM厂商自带产品功能,将同一个服务的应用程序,防止在不同的物理机器中。如果没有VM厂商,只能自己手动选择物理节点放置。
不过这些能力都需要自研或借助厂商产品的能力,对于CPU、内存、连接池100%等服务假死场景,虚拟机时代的功能也是力不从心的。Kubernetes提供的探针和区域亲和性技术,可以很好的解决上述运维问题。
系统挂掉场景
使用Liveness探针,可以定义容器的运行状况。如果容器处于不健康状态(例如,应用程序崩溃),Kubernetes 将自动重启容器,实现系统自愈的能力。

系统启动或假死场景
通过Readiness探针,可以告诉 Kubernetes 何时应该将流量引导到容器。当容器准备好接收流量时,Readiness探针返回成功,否则返回失败。这有助于防止流量发送到尚未完全启动或故障的容器上。
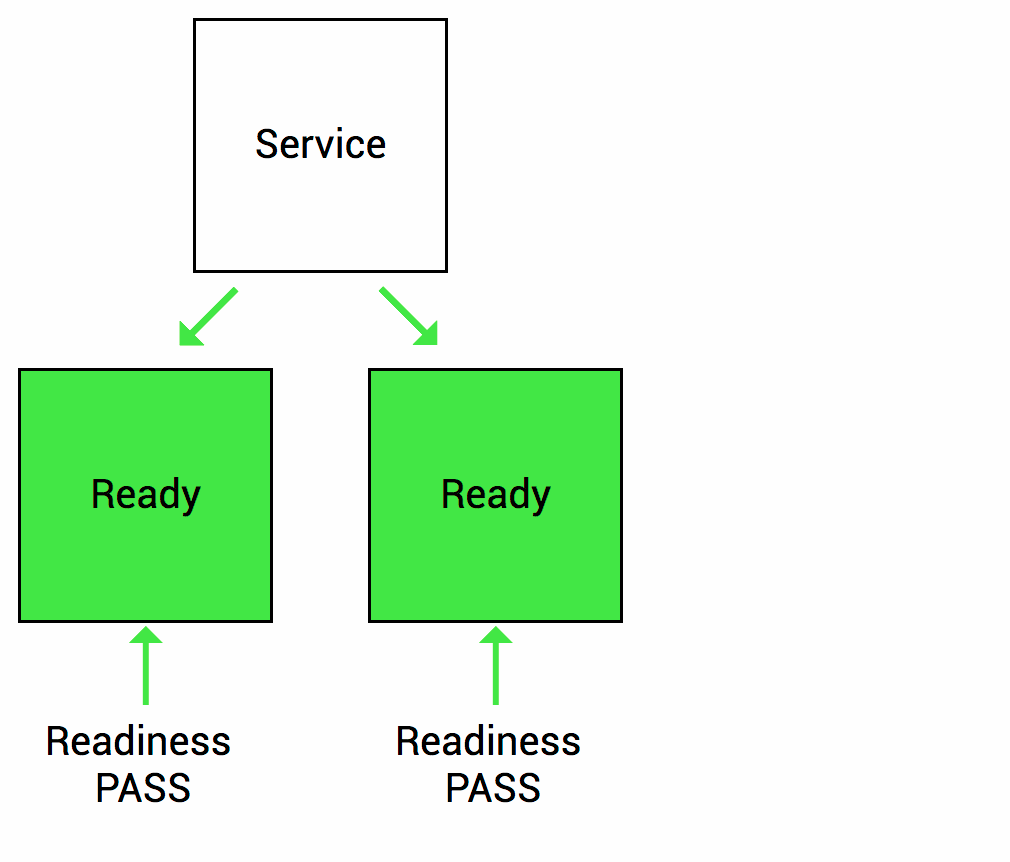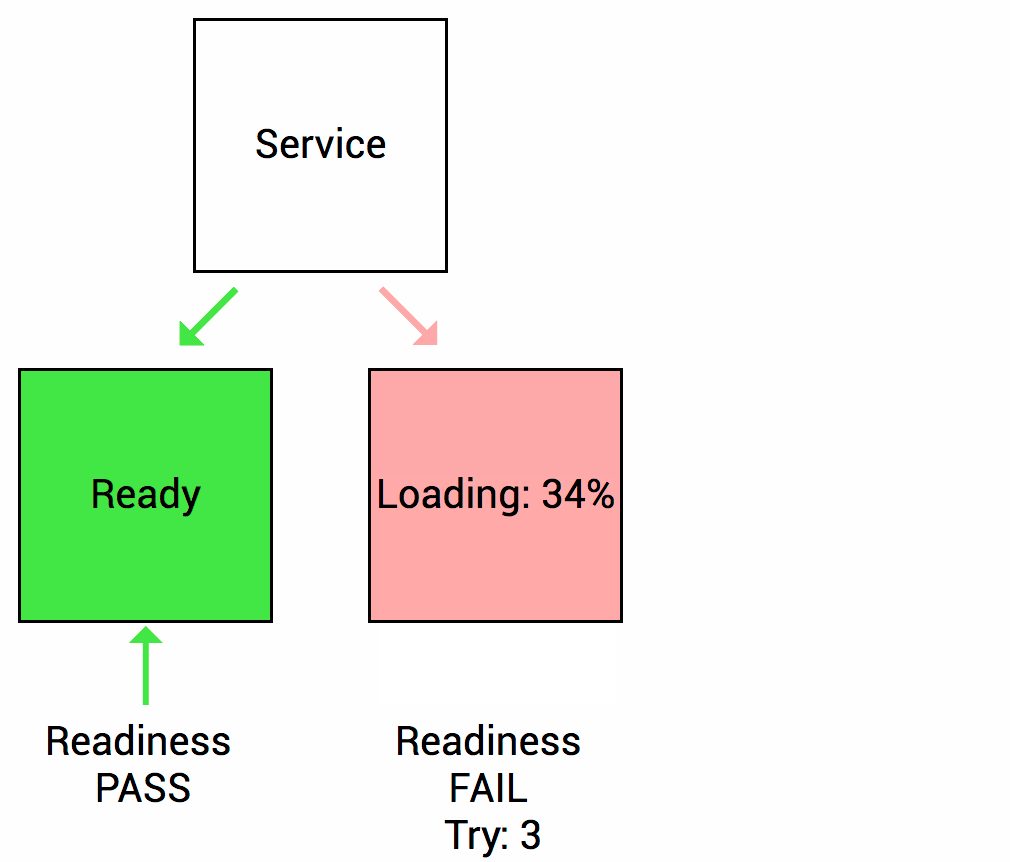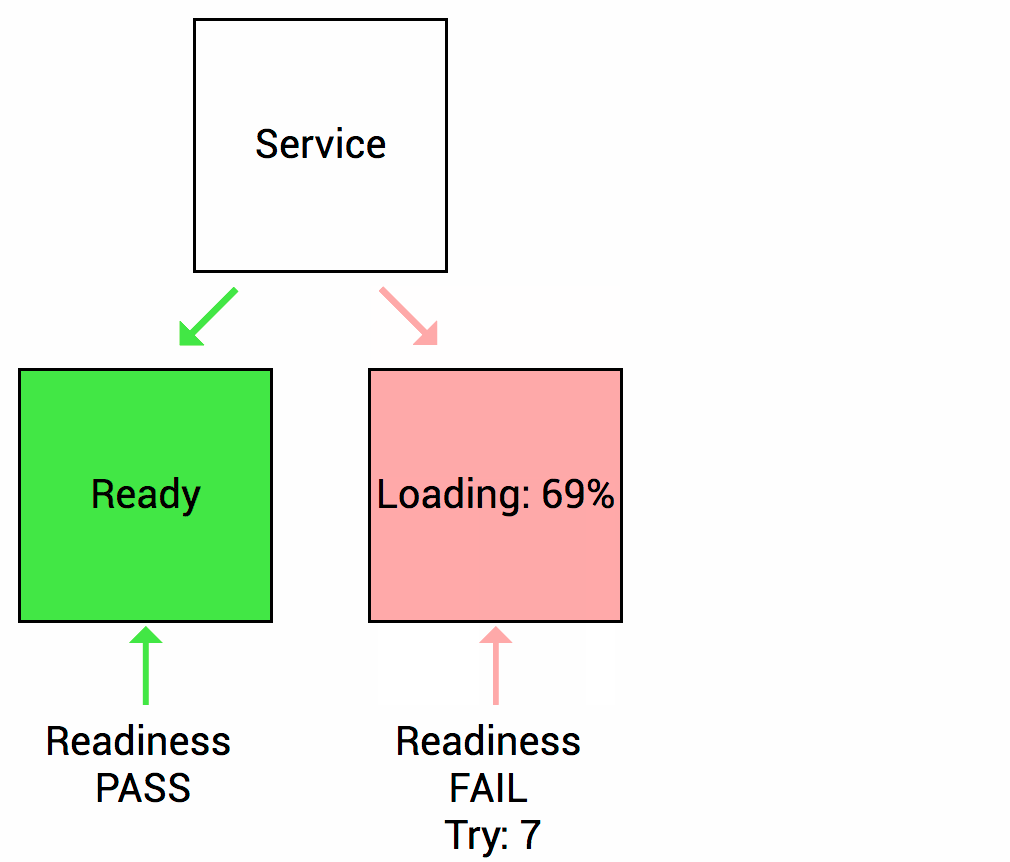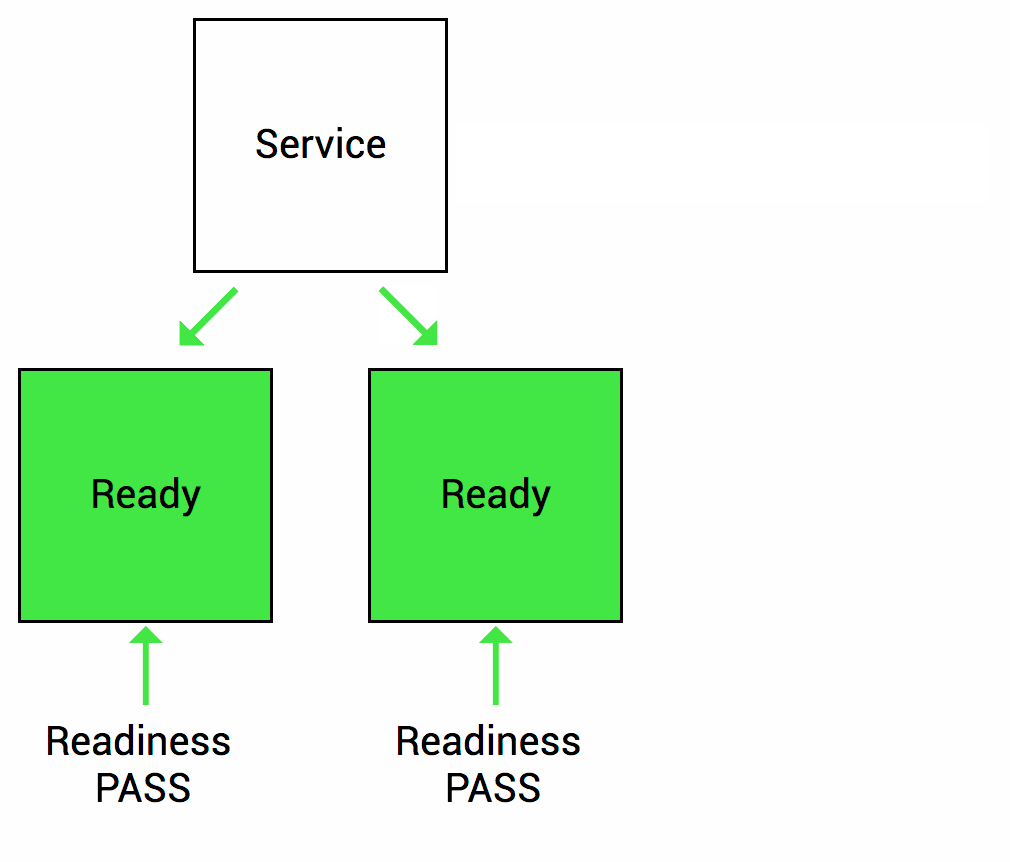
Spring Boot 2.3版本以后对Kubernetes的readiness和liveness探针做了支持,如果没有特殊自定义要求,直接使用即可。
YAML示例
apiVersion: v1
kind: Pod
metadata:name: my-app
spec:containers:- name: my-app-containerimage: my-app-imagereadinessProbe:httpGet:path: /actuator/health/readinessport: 8080livenessProbe:httpGet:path: /actuator/health/livenessport: 8080亲和性和非亲和性场景
Kubernetes 可以通过 Node 亲和性规则来控制 Pod 在哪些节点上运行,可以使用这些规则确保相关的 Pod 在不同的可用区或区域中运行,以提高容灾性。
亲和性
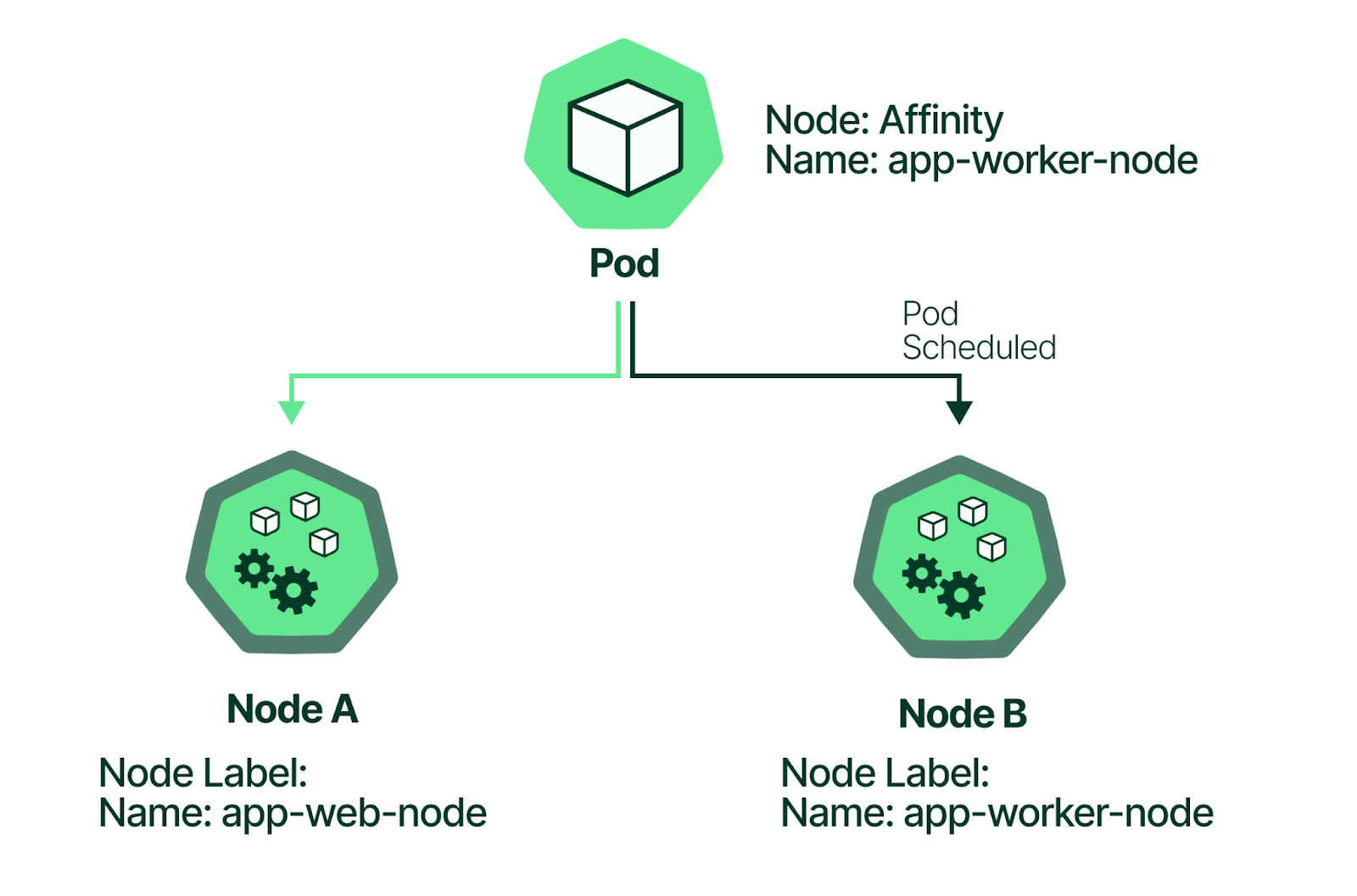
有两个Node节点A、B,希望将app-worker-node镜像部署到Node B上,就可以使用亲和性能力,在Node B添加name:app-worker-node标签,通过affinity将app-worker-node的pod调度到name:app-worker-node的Node B节点上。
affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: nameoperator: Invalues:- app-worker-node非亲和性
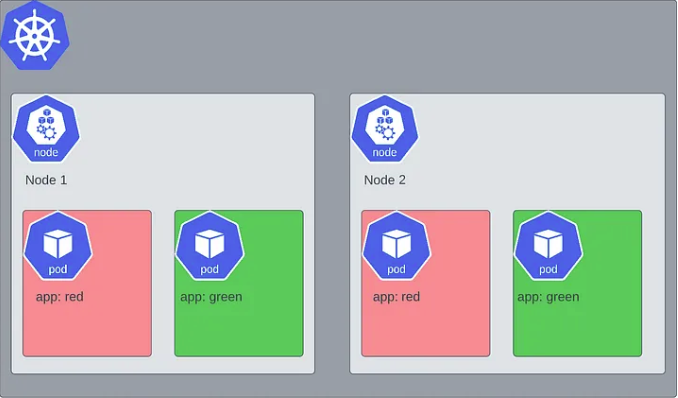
有两个app:green的Pod,为了提升容灾能力,希望分布在不同的Node服务节点上,就可以通过如下YAML实现。
apiVersion: apps/v1
kind: Deployment
metadata:name: greenlabels:app: green
spec:replicas: 2selector:matchLabels:app: greentemplate:labels:app: greenspec:containers:- name: greenimage: green:latestaffinity:podAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 100podAffinityTerm:labelSelector:matchLabels:app: greentopologyKey: "kubernetes.io/hostname"非亲和性与亲和性相反,可以让调度器将同一组Pod分配到不同的Node节点或不同的可用性区域,这样当某个节点或区域出现故障时,不会使整个服务不可用,可以有效提升业务连续性。
业务流量无损版本发布
滚动发布
滚动发布就是将旧版本逐步替换为新版本的过程,滚动进行旧版本下线新版本上线,最后所有版本都发布为新版本。配合无损下线,可以起到发布新版本时业务无感,依然保持连续性。
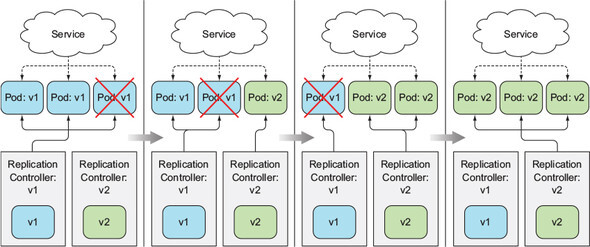
通过maxSurge和maxUnavailable来控制滚动速率,特别适用于服务节点较多或较少的发布场景。当服务节点较多时,可以一次部署多个节点,保持部分节点可用,这样提升能上线效率;对于只有少量节点,为保持业务连续性,可以一个节点一个节点的部署,如下图所示。
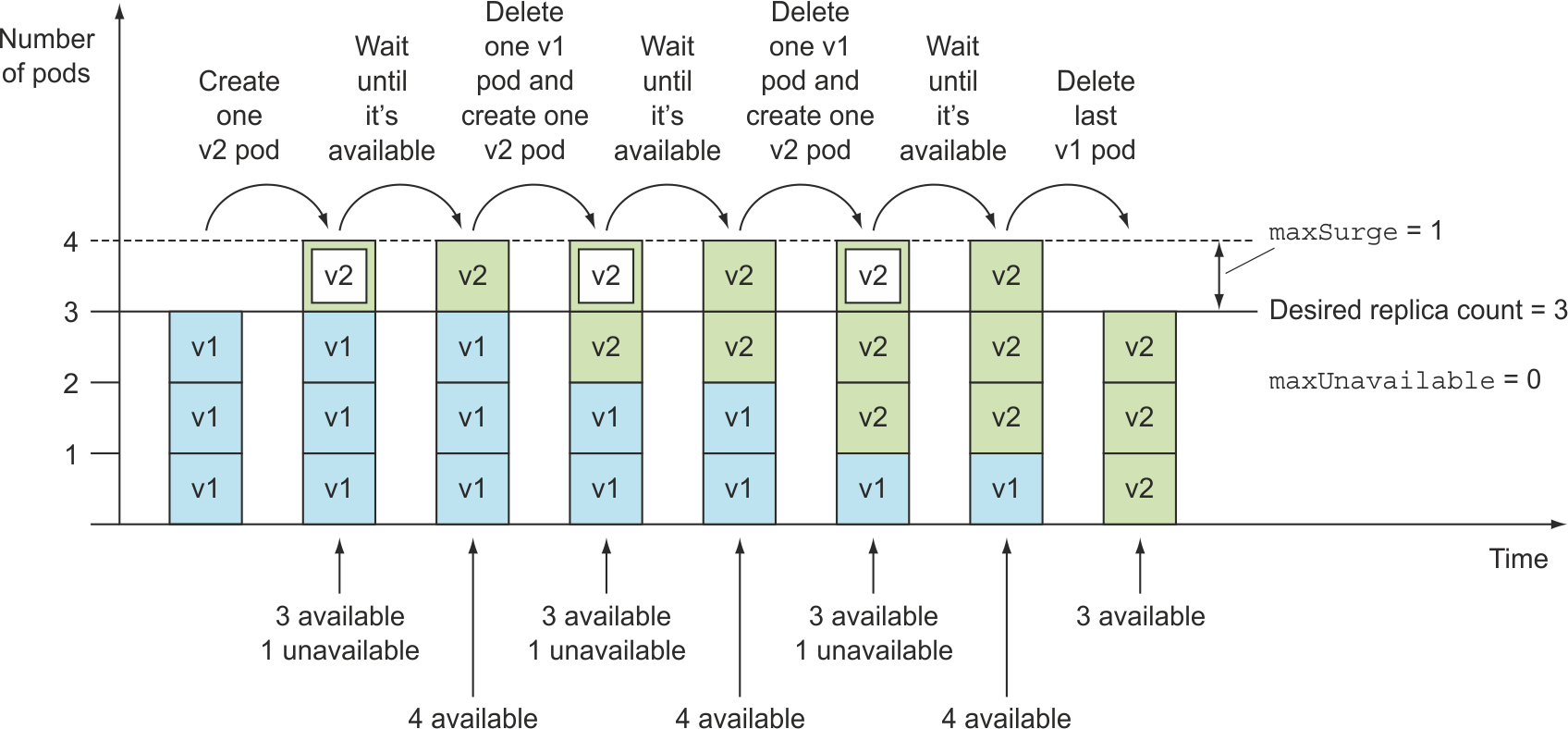
详细的可参考《Kubernetes in Action》第9章内容。
灰度发布
灰度发布有别与滚动发布,主要是灰度发布可以发布少量新版本,通过导入少量流量,小范围测试,如果出现问题,只会影响小范围流量,减轻新版本发布代码等问题对业务造成的影响。但如果想做金丝雀发布等AB测试,Kubernetes目前是不具备这个能力,需要借助Istio的Flagger来完成。
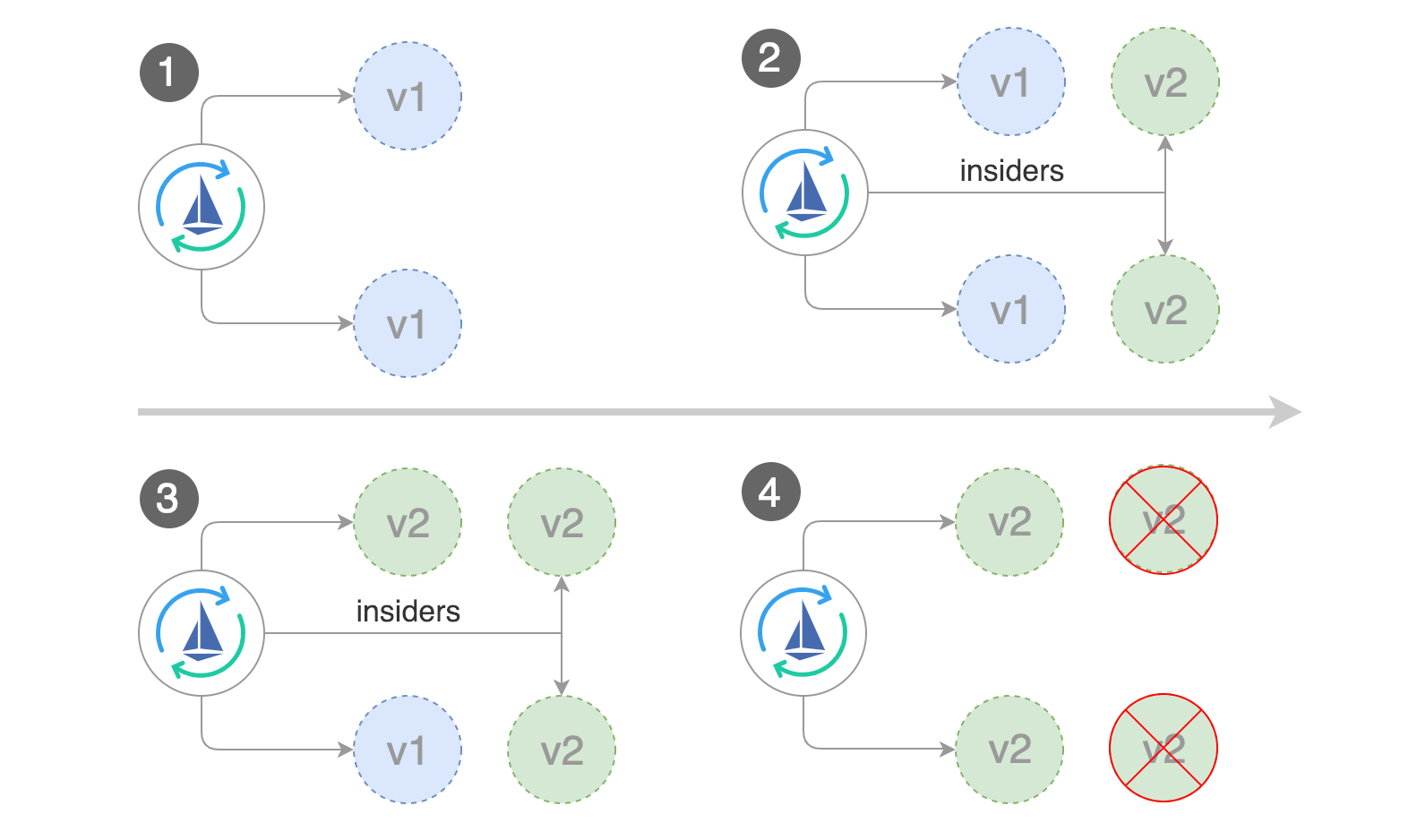
自动扩散容
Kubernetes可以通过控制Pod副本数量实现自动伸缩的能力,一般通过HorizontalpodAutoscaler(HPA)资源,周期性检查pod的度量(如CPU、内存使用情况)实现自动扩缩容。
常用应用场景
-
应用程序的负载通常会随时间变化。有些应用程序可能在白天负载高,而在夜间负载较低,而另一些应用程序可能会在特定事件或促销期间负载高。HPA可以根据这些负载变化来动态调整资源,以适应不同的负载模式,从而提高资源的利用率;
-
HPA会根据应用程序的实际负载情况动态调整Pod的副本数量。当负载增加时,HPA会自动增加Pod的副本数量,以满足应用程序的需求。当负载减少时,HPA会自动减少Pod的副本数量。这种动态性质使得资源的使用更加高效,因为它可以根据需求提供足够的容器实例,而无需手动干预;
资源利用率提升
对应虚拟机场景下的运维,一般都是固定节点资源,这可能导致过多或过少的资源。过多的资源配置势必会造成资源浪费;配置过少的资源,应用程序可能无法满足负载,会出现性能问题。

总结
微服务实现了系统的解耦,使系统节点横向扩展变为了可能。但随之而来的是系统复杂度的提升,微服务+云可以有效降低运维和资源成本,已Docker和Kubernetes等云技术,进一步降低上云系统门槛,统一业界云技术标准,形成了多场景的云化应用和中间件,使云原生相关的技术得到了蓬勃发展。
参考:
-
京东微服务平台架构解密-微服务 (uml.org.cn)
-
《Docker容器与容器云》
-
《Kubernetes in Action》
-
Kubernetes best practices: Setting up health checks with readiness and liveness probes
-
Kubernetes node affinity: examples & instructions - (kubecost.com)
-
K8s Pod Anti-affinity. How to ensure high availability when… | by Daniel Weiskopf | Medium
-
Kubernetes Deployment Strategies (weave.works)