现在我们把表demo 的行格式修改为 Redundant :

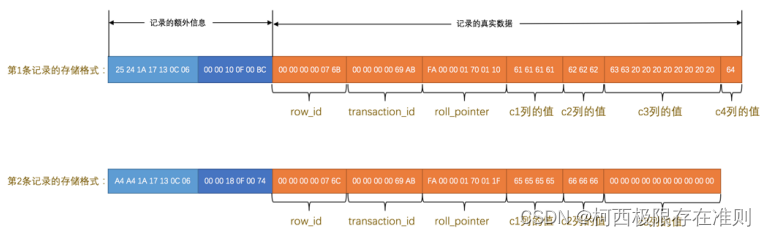
为了方便大家理解和节省篇幅,我们直接把表 demo 在Redundant 行格式下的两条记录的真实存储数据提供出来,之后我们着重分析两种行格式的不同即可。
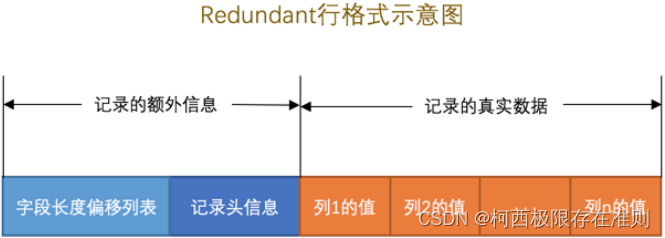
下边我们从各个方面看一下 Redundant 行格式有什么不同的地方:
字段长度偏移列表
注意 Compact 行格式的开头是 变长字段长度列表 ,而 Redundant 行格式的开头是 字段长度偏移列表 ,与变长字段长度列表有两处不同:
没有了变长两个字,意味着 Redundant 行格式会把该条记录中所有列(包括 隐藏列 )的长度信息都按照逆序存储到 字段长度偏移列表 。
多了个偏移两个字,这意味着计算列值长度的方式不像 Compact 行格式那么直观,它是采用两个相邻数值的差值来计算各个列值的长度。
比如第一条记录的 字段长度偏移列表 就是:
25 24 1A 17 13 0C 06
因为它是逆序排放的,所以按照列的顺序排列就是:
06 0C 13 17 1A 24 25
按照两个相邻数值的差值来计算各个列值的长度的意思就是:
第一列(`row_id`)的长度就是 0x06个字节,也就是6个字节。
第二列(`transaction_id`)的长度就是 (0x0C - 0x06)个字节,也就是6个字节。
第三列(`roll_pointer`)的长度就是 (0x13 - 0x0C)个字节,也就是7个字节。
第四列(`c1`)的长度就是 (0x17 - 0x13)个字节,也就是4个字节。
第五列(`c2`)的长度就是 (0x1A - 0x17)个字节,也就是3个字节。
第六列(`c3`)的长度就是 (0x24 - 0x1A)个字节,也就是10个字节。
第七列(`c4`)的长度就是 (0x25 - 0x24)个字节,也就是1个字节。
记录头信息
Redundant 行格式的记录头信息占用 6 字节, 48 个二进制位,这些二进制位代表的意思如下:
|名称|大小(单位:bit)|描述| |:--:|:--:|:--:| | 预留位1 | 1 |没有使用| | 预留位2 | 1 |没有使用|| delete_mask | 1 |标记该记录是否被删除| | min_rec_mask | 1 |B+树的每层非叶子节点中的最小记录都会添加该标记| | n_owned | 4 |表示当前记录拥有的记录数| | heap_no | 13 |表示当前记录在页面堆的位置信息|| n_field | 10 |表示记录中列的数量| | 1byte_offs_flag | 1 |标记字段长度偏移列表中每个列对应的偏移量是使用1字节还是2字节表示的| | next_record | 16 |表示下一条记录的相对位置|
第一条记录中的头信息是:
00 00 10 0F 00 BC
根据这六个字节可以计算出各个属性的值,如下:
预留位1:0x00
预留位2:0x00
delete_mask: 0x00
min_rec_mask: 0x00
n_owned: 0x00
heap_no: 0x02
n_field: 0x07
1byte_offs_flag: 0x01
next_record:0xBC
Redundant 行格式中 NULL 值的处理
因为 Redundant 行格式并没有 NULL值列表 ,所以设计 Redundant 行格式的大叔在 字段长度偏移列表 中的各个列对应的偏移量处做了一些特殊处理 —— 将列对应的偏移量值的第一个比特位作为是否为 NULL 的依据,该比特位也可以被称之为 NULL比特位 。也就是说在解析一条记录的某个列时,首先看一下该列对应的偏移量的 NULL比特位 是不是为 1 ,如果为 1 ,那么该列的值就是 NULL ,否则不是 NULL 。
4.3.3.1 CHAR(M)列的存储格式
我们知道 Compact 行格式在 CHAR(M) 类型的列中存储数据的时候还挺麻烦,分变长字符集和定长字符集的情况,而在 Redundant 行格式中十分干脆,不管该列使用的字符集是啥,只要是使用 CHAR(M) 类型,占用的真实数据空间就是该字符集表示一个字符最多需要的字节数和 M 的乘积。比方说使用 utf8 字符集的 CHAR(10) 类型的列占用的真实数据空间始终为 30 个字节,使用 gbk 字符集的 CHAR(10) 类型的列占用的真实数据空间始终为 20 个字节。由此可以看出来,使用 Redundant 行格式的 CHAR(M) 类型的列是不会产生碎片的。