1、存储
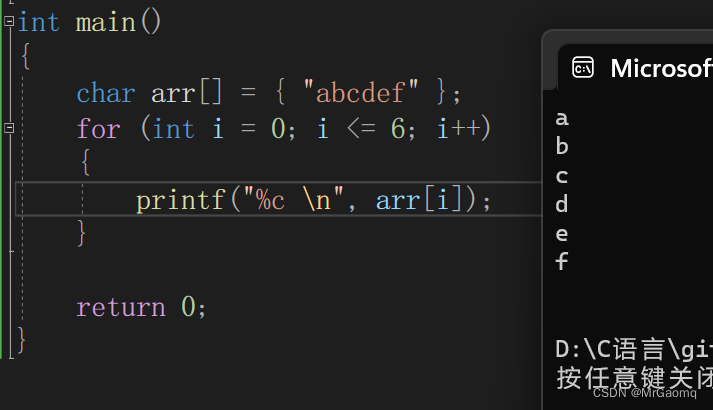
单片机端编译后分为code ro rw zi几个区域,其中code是执行文件,ro(read only)只读区域,存放const修饰常量、字符串。rw(read write)存放已初始化变量。zi存放未初始化变量。编译完成后bin大小为code+ro+rw。运行时所需内存为rw+zi。
在电脑端编译完后会分为text data bss三种,其中text为可执行程序,data为初始化过的ro+rw变量,bss为未初始化或初始化为0变量。
2、内存分配
内存分配分为静态存储区、栈、堆三种。
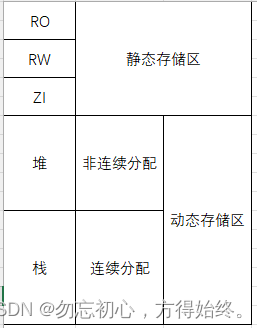
可以看到静态存储区保存全局变量、常量,除此外函数内使用static修饰的变量也会储存在该区域(通常函数内变量存储在栈中,函数返回时销毁)。由此可以看到static修饰其中一个作用:使得变量存放在静态存储区,在程序运行期间均有效。虽然全局静态变量与局部静态变量在程序运行期间均存活,但局部静态变量仅在其作用域可访问。
堆由动态内存相关函数进行操作,如malloc free。栈由编译器分配,主要是调用函数时的参数、变量以及保护现场压栈使用。
3、运算符优先级
| 序号 | 运算符 | 结合方向 |
| 1(最高) | () [] -> . | 左到右 |
| 2 | * & sizeof() (强转) ++ -- ! ~ -(负号) | 右到左 |
| 3 | * / % | 左到右 |
| 4 | + - | 左到右 |
| 5 | >> << | 左到右 |
| 6 | >= <= < > | 左到右 |
| 7 | != == | 左到右 |
| 8 | & | 左到右 |
| 9 | ^ | 左到右 |
| 10 | | | 左到右 |
| 11 | && | 左到右 |
| 12 | || | 左到右 |
| 13 | ?: | 右到左 |
| 14 | = += -= *= /= %= >>= <<= &= ^= |= | 右到左 |
| 15(最低) | , | 左到右 |
由上表可知,将q复制到p数组可以表示为:*p++=*q++,*优先级高,先取到对应q数组的值,然后两个++都是在后面,该行运算完后执行++。可以分为*p=*q;p++,q++;两行。
4、函数调用时的参数运算
例如:int a = 1,b=2,c=3;printf("%d,%d,%d\n",a+b+c,b+=2,c*=2);本该是不同编译器结果不同,但是尝试了g++ msvc都是先计算c,再计算b,最后得到a+b+c是经过赋值以后的b和c参与计算而不是6。
5、static
static作用分为三种:局部变量,全局变量,函数。
修饰全部变量和函数作用一样:仅在模块/文件内使用。
修饰局部变量:将其存放到静态存储区,不会随着函数结束销毁。从而导致其值不会每次都重新初始化,而是初始化一次后续每次都是上一次的值。其他文件内函数无法访问,这是局部变量的特点。
6、大小端
大端是常见的理解形式,高字节放在低地址,0x12345678中0x12是最高字节,0x78是最低字节。而小端中高字节在低地址。具体区分方法参考https://blog.csdn.net/qq_29144629/article/details/104986767
7、指针
指针与数组相关参考c语言指针与数组_勿忘初心,方得始终。的博客-CSDN博客
8、结构体
结构体定义方式:
typedfe struct _type_def{int val;struct _type_def *ptr;
}type_def;后续可以使用type_def A;或者struct _type_def A;的形式定义变量。注意二者区别以及如果使用链表形式时需要在结构体里面使用struct _type_def去定义,这样不会报错,如果使用type_def去定义会有一些编译器报错。
结构体大小不是简单的累加和,而是最长数据类型的整数倍,所以要尽可能把短的数据放在一起,而不是各自占用一个新空间。例如:
typedef struct{
char A;
int B;
char C;
}my_typedef;所占用空间是int的三倍,具体取决于int的长度。而不是两个char加一个int的大小。如果定义为:
typedef struct{
char A;
char C;
int B;
}my_typedef;只占用两倍int空间,同样,如果在C与B中间再加上一个char D;其结果还是两倍int空间。
如果想要结构体占用其数据类型对应的大小个字节需要使用attribute将其强制1字节对其。具体参考:C语言__attribute__学习记录___attribute__ (( section可以把变量放到多个段中吗_勿忘初心,方得始终。的博客-CSDN博客
9、位域
位域用于不需要太长数据类型对象,例如1个或者几个bit。通常与结构体结合使用:(可以使用空位域)
typedef struct{unsigned int F1_Bit:2;unsigned int :1;unsigned int F2_Bit:10;
}Bit_typedef;10、联合体
联合体与结构体定义方式类似,形如:
typedef union _learn
{int a[7];char b;double c;
}learn;其中所有变量共用同一块内存,在dsp配置中比较常见,可以直接配置寄存器,或者对不同功能的不同位进行配置。其占用空间对其方式与结构体类似,需要与最长数据类型对其,也就是整数倍。上例中a占用28个字节(32位系统),但是double位8字节,28不能整除所以需要往上取整,结果占用32个字节。
通过联合体与结构体加上位域可以实现对寄存器全读写或者部分读写:
typedef struct{unsigned int F1_Bit:2;unsigned int F2_Bit:10;
}Bit_typedef;typedef union _Reg_t
{unsigned int Reg;Bit_typedef Bit;}Reg_t;可以通过Reg_t regA;regA.Reg = 0X12345678;对整个4字节赋值,或者通过regA.Bit.F1_Bit进行读写。
12、内联函数
内联函数的优点是可以提高代码的执行效率,减少函数调用的开销。此外,内联函数也可以进行类型检查,避免了宏定义的类型错误。但是,内联函数也有一些缺点。首先,内联函数的代码会被复制到调用它的地方,如果内联函数的代码很长,会导致可执行文件变大,影响程序的运行效率。其次,内联函数的定义必须放在头文件中,这会增加头文件的大小,降低编译速度。最后,内联函数的使用必须谨慎,过度使用内联函数会导致程序的可维护性变差。
13、预处理
预处理是指在程序代码实际编译之前,对代码进行一系列的处理操作。预处理器是一种能够读取代码文件并执行预处理操作的程序,它可以执行宏定义替换、文件包含、条件编译等操作,从而提高程序代码的效率和可读性。
14、转义字符串
当\出现在字符串中时如果后面有x或则0会对后续数字进行转义,如"\x412","\098",\x是获取16进制值,\取8进制值,且\后面仅仅有三位为转义,如"\01234"结果是{10,‘2’,‘3’,‘4’,0}。但是\x就没有该限制"\x132178471"结果为{0X132178471,0};