基于Transformer的端到端三维人体姿态估计
摘要
基于Transformer的架构已经成为自然语言处理中的常见选择,并且现在正在计算机视觉任务中实现SOTA性能,例如图像分类,对象检测。然而,卷积方法在3D人体姿态估计的许多方法中仍然保持SOTA性能。受视觉变换器最近发展的启发,我们设计了一个无热图结构,使用标准的变换器架构和可学习的对象查询来建模每个帧内的人体关节关系,然后输出准确的关节位置和类型,我们还提出了一个基于变换器的姿势识别架构,没有任何贪婪算法来在运行时对预测的骨骼进行后处理。在实验中,我们实现了最佳的性能之间的方法,直接回归3D关节位置从一个单一的RGB图像,并报告与许多2D到3D提升方法的竞争结果。

我们模型的整体架构。遵循DETR的模式,我们使用CNN主干来提取多尺度特征,然后使用位置编码和可学习的层编码来补充扁平化的多尺度特征,然后使用3D直接方法人体姿势Transformer从输入特征中回归3D人体姿势。为了突出集合预测和对3D HPE上的Transformer器的从粗到细训练的重要性,我们设计了两种类型的变换器,其细节将在后面描述。
我们的方法的贡献如下:
·我们提出了一个单级端到端3D人体姿态估计网络。在此基础上,验证了DETR算法对三维关键点检测的有效性。
·为了降低模型直接学习3D空间中人体关键点表示的难度,我们提出了一种基于由粗到细中间监督的解码器连接结构。
通过比较强制对齐Transformer检测网络和我们提出的网络,我们研究了可学习的联合查询和二分匹配损失对最终效果的影响。
方法
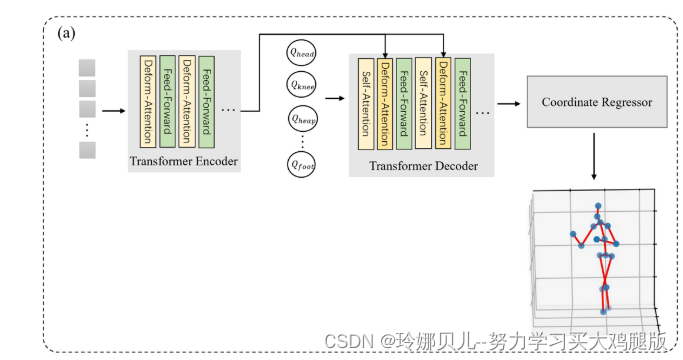
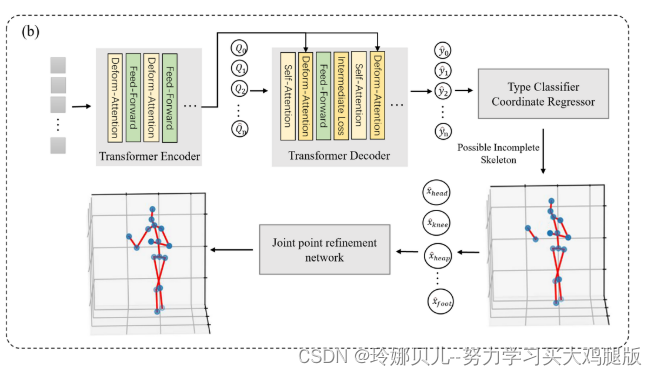
Transformer 3D HPE baseline由三部分组成:具有可变形注意力以利用多尺度特征的Transformer编码器,具有固定查询大小和类型的Transformer解码器,以及多层感知。基于基线架构,联合检测Transformer在解码器中增加了中间训练和集合预测,并且还增加了后处理阶段以完成可能不完整的骨架。
三个要素对于解释直接估计和2D到3D提升方法之间的性能差距至关重要:
(1)多尺度输入图像特征
(2)捕捉图像特征与关节位置之间的关系,这导致遮挡下的巨大性能下降;
(3)有先验知识的由粗到精的培训;
我们还发现,Transformer中的自注意机制可以代替一般检测网络中的检测头,捕获联合查询之间的联合关系,该机制可以解释为细化输入特征向量(Q)、特征到结果映射向量(K)、结果向量(V)的隐藏表示,该过程可以用公式表示(√ dk是缩放参数):

多尺度可变形注意力[18]解决了Transformer架构在计算机视觉任务中只能使用单层特征,并且需要很长的训练时间才能专注于部分图像特征的问题。

其中,Aqk是关注值,φl(Φ pq)是特征层l的归一化参考点,Δ pq是可学习参考点偏移。
整体架构如图2所示。我们首先介绍我们的姿势识别基线网络与forcealigned Transformer和多层变形注意,然后我们介绍我们的联合检测变压器,最后一个联合细化网络,以填补不完整的预测骨架。
A. Transformer 3D HPE baseline
我们实现了我们的基线模型与标准的Transformer为基础的架构。基线模型使用固定的联合查询大小,并且仅利用Resnet输出的最后一层特征(见图2(a)),我们还将Transformer编码器中的自注意层和变换器解码器中的交叉注意层替换为多尺度可变形注意。在编码器阶段,由Resnet生成的图像特征被展平并馈送到Transformer编码器中以产生上下文敏感的图像特征。编码器还利用位置嵌入和尺度级嵌入来保留原始图像的位置和层信息。该过程可以被公式化为:
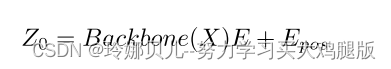
通过主干网络进行特征提取后,对特征图进行E ∈ R1 × 1 × C卷积,然后将特征图的空间维数折叠成一维d × HW。为了显示可学习的联合查询在3D姿态估计任务中的有效性,我们的基线网络将每个查询与相应的联合对齐。对于输入序列X ∈ RJ×h,J表示地面真值节点的个数,h是Transformer的隐维数,xi ∈ R1 ×(h)|i = 1,2,…J指示每个查询的输入向量。然后将输出序列Xdec ∈ Rf×3馈送到可选的关键点完成网络中,以重建丢失的关键点并细化预测的姿态。
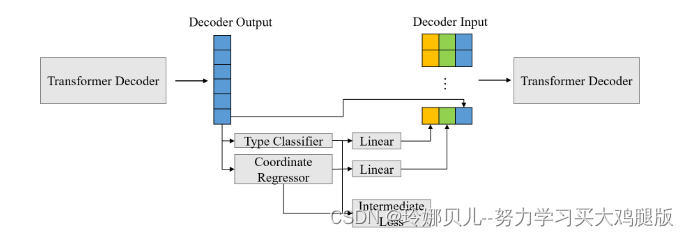
B.联合检测Transformer
基于上述基线模型,我们做了一些改进,解码器现在将N个查询的固定大小集合作为输入,其中N显著大于大多数人体姿势估计数据集中的典型关节数,在我们的情况下,我们将N设置为100。并且在解码器层的末端,分类头在J种类型的关节和背景之间进行预测,并且3通道回归头输出每个关键点的基于根的3d坐标。参见图2(B)。由于解码器预测的关节数量大于地面真实骨架,因此我们应用二分损失函数来训练我们的网络,以找到预测(表示为P的量)和地面真实对象(表示为G的量)之间的最佳匹配,我们模型的优化目标是以最低成本找到函数σ ∈ [P] → [G]。

其中LHungarian旨在以最低成本找到预测集和地面实况集之间的匹配。将σ(i)定义为对应于地面实况关节i的预测指数,将(pσ(i)(ci)定义为Lmatch的类别ci的概率,并且将(bσ(i),bi)定义为预测关节位置和地面实况关节位置。当配对的地面实况对象是时,我们手动定义配对成本Lmatch = 0,并且当配对的地面实况对象是真实的关节(即,不是)时,预测的关节类型与地面实况对象匹配的概率越大,或者两者之间的关节损失越小,配对成本Lmatch越小。在推理阶段,我们不能使用地面真值密钥,所以我们只使用分类概率来匹配N个预测与J个类型的关节。在我们的实现中,我们使用分类概率和联合位置误差的加权混合来匹配我们的对象查询,损失被定义为λclsLcls(bi,bσ(i))+ λregLreg(bi,bσ(i)),其中λcls和λreg是控制给定预测联合及其最佳匹配的联合类型分类损失和联合位置损失的权重的2个超参数。
为了减轻模型学习在3D HPE任务中常见的高度非线性三维坐标的难度,我们在解码器阶段采用了由粗到精的训练,我们希望解码器能够逐渐学习到关节点的位置信息(如图3所示),
所以我们设计关节位置回归损失Ljoint如下:


其中,θ(i)给出地面实况联合i的最佳匹配,xdl是对应解码器层的阈值,γydl是衰减系数。我们将分类损失Lcls定义为:

我们对每个解码器层应用上述损耗计算,并且逐层地将xdl减小到最后一层处的0。此外,我们不仅使用由粗到精的训练方法来训练我们的模型,以逐层细化关节点的预测,我们还特别设计了一种连接方法,以便后一层的解码器可以使用前一层的预测。
C.关节点细化网络
虽然对象查询机制可以减少遮挡的影响,但由于严重遮挡或训练期间空关节和其他关节类型的比例不平衡,仍然可能存在未检测到的关节。为了解决这个问题,我们设计了一个网络来完成不完整的骨架,我们将这个网络命名为联合点精化网络。受BERT的掩模机制的启发,对于每个不完整的预测关节集vi =(xj,yj,zj)J,j=1(地面实况定义的关节大小捐赠J),我们选择预测关节集的20%。如果选择了预测骨架的第i个关节点,则将其替换为(1)骨架树中其父节点和子节点的中点(如果所选节点是叶节点,则直接设置为父节点位置)80%的时间(2)第i个关节位置在20%的时间内不变,然后与其非空的父关节和子关节连接,并将掩蔽集输入到多层感知器中以生成相应的完整关节集,并使用回归头来回归最终的骨架输出,我们期望模型学习预测骨架的内部关系并使用现有的关节位置来完成骨架。对于训练,我们仅计算掩蔽关节的损失,我们应用损失函数Lc如下:
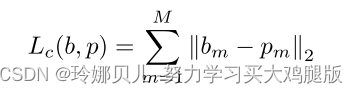
其中,B是关节点细化网络的输出关节,p是真实关节点,M是所选关节的数量。与普通的三维人体姿态估计相比,关节点精化网络的训练数据更容易获得。训练这个网络只需要骨架数据,这些数据可以从多个来源收集。
结论
本文提出了一种基于Transformer的端到端人体姿态估计方法。Transformer编码器使用可变形多尺度注意力来接收由骨干网络产生的多尺度特征图输出作为输入。然后将增强的联合查询和编码的图像特征用作Transformer解码器的输入,与二分图像匹配损失相结合以获得3D人体姿势。我们的方法降低了学习三维人体姿势表示的模型的难度。在多个数据集上的实验定性和定量地验证了该方法的有效性。