1.Redis版本及下载
找到安装的redis版本,redis3.0以上版本才支持集群
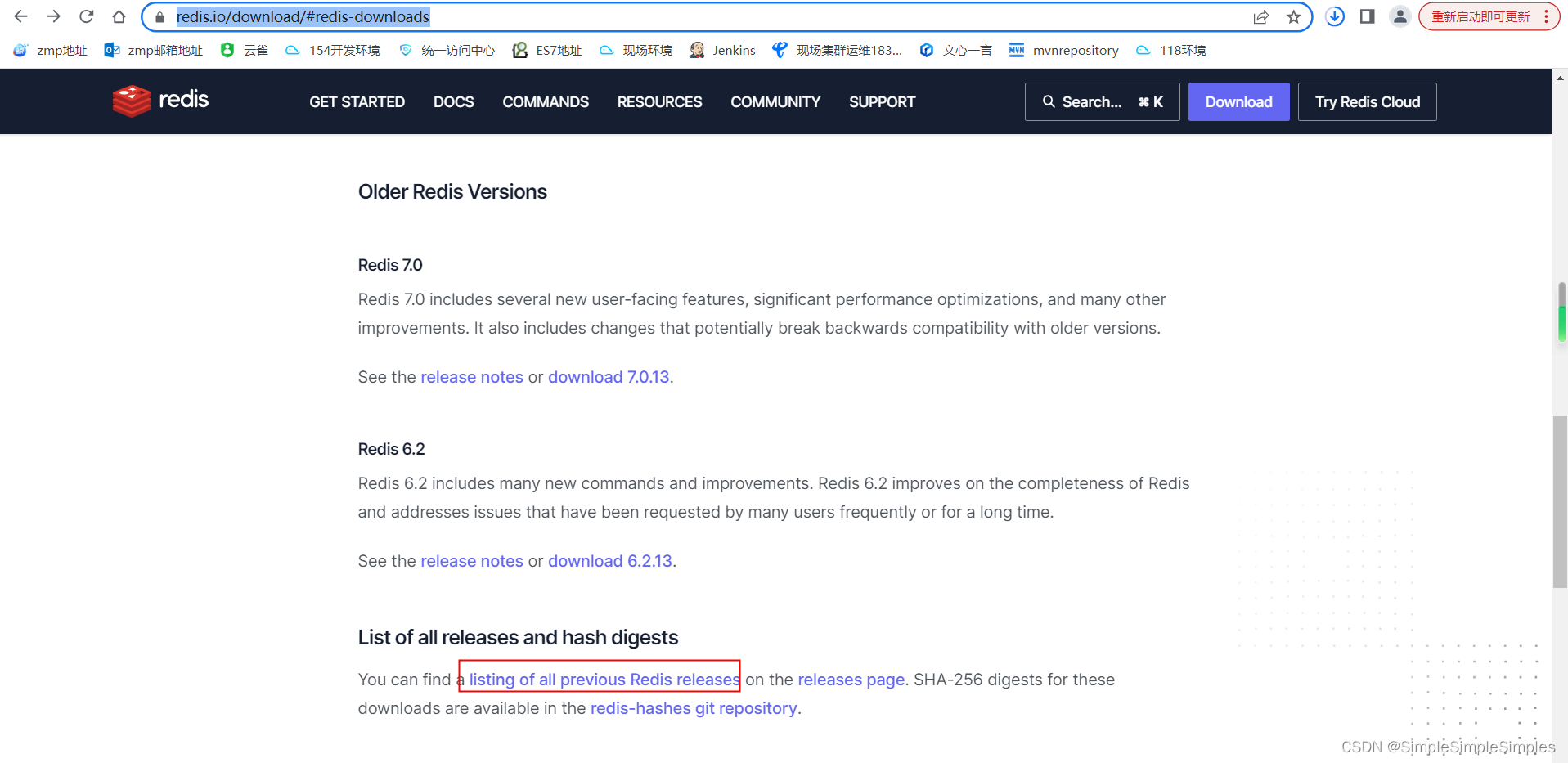
下载对应的版本
2.安装redis集群
解压上传编译
[hadoop@host152 opensource]$ tar -xvf redis-3.2.11.tar.gz
[hadoop@host152 opensource]$ cd redis-3.2.11/
[hadoop@host152 redis-3.2.11]$ make
cd src && make all
make[1]: 进入目录“/home/hadoop/opensource/redis-3.2.11/src”
CC adlist.o
/bin/sh: cc: 未找到命令
make[1]: *** [adlist.o] 错误 127
make[1]: 离开目录“/home/hadoop/opensource/redis-3.2.11/src”
make: *** [all] 错误 2
编译报错,缺少gcc,使用root用户先安装gcc,若没有报错则跳过此步骤
[root@host152 redis-3.2.11]# gcc -v
bash: gcc: 未找到命令...
[root@host152 redis-3.2.11]# yum -y install gcc
[root@host152 redis-3.2.11]# gcc -v
gcc 版本 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
需要删除原来的安装目录,重新解压编译安装redis,因为包已经弄坏
[hadoop@host152 opensource]$ rm -rf redis-3.2.11
[hadoop@host152 opensource]$ tar -xvf redis-3.2.11.tar.gz
[hadoop@host152 opensource]$ cd redis-3.2.11/
[hadoop@host152 redis-3.2.11]$ make
[hadoop@host152 redis-3.2.11]$ pwd
/home/hadoop/opensource/redis-3.2.11
[hadoop@host152 redis-3.2.11]$ cd src
[hadoop@host152 src]$ make install PREFIX=/home/hadoop/opensource/redis-3.2.11
此时可以切换到上面PREFIX指定的安装路径,可以看到bin目录下面有redis服务端和客户端生成
[hadoop@host152 src]$ cd /home/hadoop/opensource/redis-3.2.11
[hadoop@host152 redis-3.2.11]$ cd bin
[hadoop@host152 bin]$ ll
总用量 15080
-rwxr-xr-x. 1 hadoop hadoop 2433104 9月 10 23:22 redis-benchmark
-rwxr-xr-x. 1 hadoop hadoop 25008 9月 10 23:22 redis-check-aof
-rwxr-xr-x. 1 hadoop hadoop 5190752 9月 10 23:22 redis-check-rdb
-rwxr-xr-x. 1 hadoop hadoop 2585952 9月 10 23:22 redis-cli
lrwxrwxrwx. 1 hadoop hadoop 12 9月 10 23:22 redis-sentinel -> redis-server
-rwxr-xr-x. 1 hadoop hadoop 5190752 9月 10 23:22 redis-server
直接创建文件6个节点,7001-7006放置redis集群配置文件的
[hadoop@host152 redis-3.2.11]$ mkdir 7001
[hadoop@host152 redis-3.2.11]$ mkdir 7002
[hadoop@host152 redis-3.2.11]$ mkdir 7003
[hadoop@host152 redis-3.2.11]$ mkdir 7004
[hadoop@host152 redis-3.2.11]$ mkdir 7005
[hadoop@host152 redis-3.2.11]$ mkdir 7006
[hadoop@host152 redis-3.2.11]$ cp redis.conf 7001
[hadoop@host152 redis-3.2.11]$ cp redis.conf 7002
[hadoop@host152 redis-3.2.11]$ cp redis.conf 7003
[hadoop@host152 redis-3.2.11]$ cp redis.conf 7004
[hadoop@host152 redis-3.2.11]$ cp redis.conf 7005
[hadoop@host152 redis-3.2.11]$ cp redis.conf 7006
分别进入7001-7006文件夹修改改各个节点对应的配置redis.conf
bind 192.168.72.152
port 7006
daemonize yes
dir /home/hadoop/opensource/redis-3.2.11/7006
logfile "/home/hadoop/opensource/redis-3.2.11/7006/redis.log"
dbfilename "dump-7006.rdb"
cluster-enabled yes
cluster-config-file nodes-7006.conf
##设置挂某个节点,不影响集群
cluster-require-full-coverage no
启动所有节点,查看进程
[hadoop@host152 redis-3.2.11]$ ./bin/redis-server 7001/redis.conf
[hadoop@host152 redis-3.2.11]$ ./bin/redis-server 7002/redis.conf
[hadoop@host152 redis-3.2.11]$ ./bin/redis-server 7003/redis.conf
[hadoop@host152 redis-3.2.11]$ ./bin/redis-server 7004/redis.conf
[hadoop@host152 redis-3.2.11]$ ./bin/redis-server 7005/redis.conf
[hadoop@host152 redis-3.2.11]$ ./bin/redis-server 7006/redis.conf
[hadoop@host152 redis-3.2.11]$ ps -ef|grep redis
hadoop 66312 1 0 23:41 ? 00:00:00 ./bin/redis-server 192.168.72.152:7001 [cluster]
hadoop 66316 1 0 23:41 ? 00:00:00 ./bin/redis-server 192.168.72.152:7002 [cluster]
hadoop 66320 1 0 23:41 ? 00:00:00 ./bin/redis-server 192.168.72.152:7003 [cluster]
hadoop 66324 1 0 23:41 ? 00:00:00 ./bin/redis-server 192.168.72.152:7004 [cluster]
hadoop 66328 1 0 23:41 ? 00:00:00 ./bin/redis-server 192.168.72.152:7005 [cluster]
hadoop 66332 1 0 23:41 ? 00:00:00 ./bin/redis-server 192.168.72.152:7006 [cluster]
连接7001节点,使用cluster meet命令分别与7002-7006其他节点握手建立联系,显示OK即成功
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -h 192.168.72.152 -p 7001
192.168.72.152:7001> cluster meet 192.168.72.152 7002
OK
192.168.72.152:7001> cluster meet 192.168.72.152 7003
OK
192.168.72.152:7001> cluster meet 192.168.72.152 7004
OK
192.168.72.152:7001> cluster meet 192.168.72.152 7005
OK
192.168.72.152:7001> cluster meet 192.168.72.152 7006
OK
查看各个节点是否已经和7001节点connected以及节点数量
192.168.72.152:7001> cluster nodes
236bca208b8ed0ba4a1f042d756bbaec56cac6e4 192.168.72.152:7003 master - 0 1694361465216 3 connected
88be3f0f135e582f93345078e6c32d9d66083755 192.168.72.152:7001 myself,master - 0 0 2 connected
a65395ca86e3a58b48da86b400b0ae16ee20da82 192.168.72.152:7006 master - 0 1694361469252 4 connected
018b58f800f2d23d1c712c039d5fda0e90c35426 192.168.72.152:7005 master - 0 1694361465216 5 connected
45063091c71eecef8b20af40322a9b33b806972a 192.168.72.152:7002 master - 0 1694361467237 1 connected
c3320213a8c90e6154aff53d8f84fd6a171407a3 192.168.72.152:7004 master - 0 1694361468245 0 connected
192.168.72.152:7001> cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_sent:347
cluster_stats_messages_received:347
备注:或者也登陆客户端用CLUSTER NODES获取各个节点的UUID唯一编码,查看连接的节点
192.168.72.152:7001> CLUSTER NODES
88be3f0f135e582f93345078e6c32d9d66083755 :7001 myself,master - 0 0 0 connected
也可以通过cluster-config-file指定的配置.conf文件找到各个节点的编码
[hadoop@host152 redis-3.2.11]$ more 7001/nodes-7001.conf
88be3f0f135e582f93345078e6c32d9d66083755 :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
[hadoop@host152 redis-3.2.11]$ more 7002/nodes-7002.conf
45063091c71eecef8b20af40322a9b33b806972a :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
[hadoop@host152 redis-3.2.11]$ more 7003/nodes-7003.conf
236bca208b8ed0ba4a1f042d756bbaec56cac6e4 :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
[hadoop@host152 redis-3.2.11]$ more 7004/nodes-7004.conf
c3320213a8c90e6154aff53d8f84fd6a171407a3 :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
[hadoop@host152 redis-3.2.11]$ more 7005/nodes-7005.conf
018b58f800f2d23d1c712c039d5fda0e90c35426 :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
[hadoop@host152 redis-3.2.11]$ more 7006/nodes-7006.conf
a65395ca86e3a58b48da86b400b0ae16ee20da82 :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
分别登陆7004/7005/7006节点,用cluster replicate依次设置当前从节点跟随哪个主节点标识
设置7004为从节点,跟随7001
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -h 192.168.72.152 -p 7004
192.168.72.152:7004> cluster replicate 88be3f0f135e582f93345078e6c32d9d66083755
OK
设置7005为从节点,跟随7002
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -h 192.168.72.152 -p 7005
192.168.72.152:7005> cluster replicate 45063091c71eecef8b20af40322a9b33b806972a
OK
设置7006为从节点,跟随7003
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -h 192.168.72.152 -p 7006
192.168.72.152:7006> cluster replicate 236bca208b8ed0ba4a1f042d756bbaec56cac6e4
OK
分配完成后查看主从节点关系master或者slave
192.168.72.152:7006> cluster nodes
a65395ca86e3a58b48da86b400b0ae16ee20da82 192.168.72.152:7006 myself,slave 236bca208b8ed0ba4a1f042d756bbaec56cac6e4 0 0 4 connected
88be3f0f135e582f93345078e6c32d9d66083755 192.168.72.152:7001 master - 0 1694362228496 2 connected
236bca208b8ed0ba4a1f042d756bbaec56cac6e4 192.168.72.152:7003 master - 0 1694362229004 3 connected
45063091c71eecef8b20af40322a9b33b806972a 192.168.72.152:7002 master - 0 1694362226980 1 connected
018b58f800f2d23d1c712c039d5fda0e90c35426 192.168.72.152:7005 slave 45063091c71eecef8b20af40322a9b33b806972a 0 1694362227992 5 connected
c3320213a8c90e6154aff53d8f84fd6a171407a3 192.168.72.152:7004 slave 88be3f0f135e582f93345078e6c32d9d66083755 0 1694362224957 2 connected
登陆主节点7001/7002/7003分配槽点,redis集群一共有16384个节点,范围在0-16383
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -h 192.168.72.152 -p 7001
192.168.72.152:7001> cluster addslots {0..5461}
(error) ERR Invalid or out of range slot
上述分配报错原因及解决办法
原因:redis-cli的addslots 命令需要的是一个具体数组
上述的{0..5461}中的{ }在bash中是 brace explansion(括号展开)的意思,在redis-cli客户端中并不认识{}这个命令,再看redis分配slot的命令:
CLUSTER ADDSLOTS slot [slot …]
即需要的是一个数组,示例如下才是正确写法,但是总不可能从1写到5461吧,这就很扯了吧
CLUSTER ADDSLOTS 1 2 3
解决办法:用seq生成序列解决
查看下面命令
[hadoop@host152 redis-3.2.11]$ {0..10}
bash: 0: 未找到命令...
[hadoop@host152 redis-3.2.11]$ echo {0..10}
0 1 2 3 4 5 6 7 8 9 10
利用seq生成对应长度的槽点数组即可
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -h 192.168.72.152 -p 7001 cluster addslots $(seq 0 5461)
OK
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -h 192.168.72.152 -p 7002 cluster addslots $(seq 5462 10922 )
OK
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -h 192.168.72.152 -p 7003 cluster addslots $(seq 10923 16383)
OK
查看slot分布情况,16384个 槽点是否分配完毕
192.168.72.152:7001> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_sent:5553
cluster_stats_messages_received:5553
192.168.72.152:7001> CLUSTER NODES
236bca208b8ed0ba4a1f042d756bbaec56cac6e4 192.168.72.152:7003 master - 0 1694363986484 3 connected 10923-16383
88be3f0f135e582f93345078e6c32d9d66083755 192.168.72.152:7001 myself,master - 0 0 2 connected 0-5461
a65395ca86e3a58b48da86b400b0ae16ee20da82 192.168.72.152:7006 slave 236bca208b8ed0ba4a1f042d756bbaec56cac6e4 0 1694363989507 4 connected
018b58f800f2d23d1c712c039d5fda0e90c35426 192.168.72.152:7005 slave 45063091c71eecef8b20af40322a9b33b806972a 0 1694363988499 5 connected
45063091c71eecef8b20af40322a9b33b806972a 192.168.72.152:7002 master - 0 1694363987996 1 connected 5462-10922
c3320213a8c90e6154aff53d8f84fd6a171407a3 192.168.72.152:7004 slave 88be3f0f135e582f93345078e6c32d9d66083755 0 1694363987492 2 connected
至此集群创建成功,测试集群是否可用
连接7001节点
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -c -h 192.168.72.152 -p 7001
192.168.72.152:7001> set age 99
OK
192.168.72.152:7001> get age
"99"
连接7002节点
[hadoop@host152 redis-3.2.11]$ ./bin/redis-cli -c -h 192.168.72.152 -p 7002
192.168.72.152:7002> get age
-> Redirected to slot [741] located at 192.168.72.152:7001
"99"