提升树和adaboost基本流程是相似的
我看到提升树的时候,懵了
这…跟adaboost有啥区别???
直到看到有个up主说了,我才稍微懂

相当于,我在adaboost里的弱分类器,换成CART决策树就好了呗?
书上也没有明说,唉。。。
还好,有大神提升树的具体讲解
看出来了,提升树主要是做二叉树分类和回归的:
- 如果是处理分类问题,弱分类器用CART决策树,就是adaboost了
- 如果是处理回归问题,弱分类器也是用CART决策树
- 每个新的弱分类器都是降低残差
1. 推导过程
-
建立提升树的加法模型
- 假设构成第i个弱分类器的参数为 θ i θ_i θi,第i个弱分类器则表示为 T ( x , θ i ) T(x,θ_i) T(x,θi)
- 当前弱分类器若表示为 T ( x , θ m ) T(x,θ_m) T(x,θm),强分类器则表示为: f m ( x ) = f m − 1 ( x ) + T ( x , θ m ) f_m(x) = f_{m-1}(x)+T(x,θ_m) fm(x)=fm−1(x)+T(x,θm)
- 预测结果为 y p r e = f m ( x ) = f m − 1 ( x ) + T ( x , θ m ) y_{pre}=f_m(x)=f_{m-1}(x)+T(x,θ_m) ypre=fm(x)=fm−1(x)+T(x,θm)
-
损失函数Loss采用平方误差损失函数
- 使用CART回归树作为弱分类器,那么每次选取的特征及特征值,都会使平方误差损失函数达到最低
- 但弱分类器是不需要完全CART回归树一次性就把所有特征及特征值都遍历训练完成的,只需要挑选平方损失函数最低的那个特征及特征值
弱分类器,只进行一个树杈的划分 - 弱分类器内部的平方损失函数,是取二分树杈的左右两个数据集的平方损失之和最小
L o s s t r e e = ∑ ( y i l e f t − y ˉ l e f t ) 2 + ∑ ( y j r i g h t − y ˉ r i g h t ) 2 Loss_{tree} = ∑(y_i^{left}-\bar{y}_{left})^2+ ∑(y_j^{right}-\bar{y}_{right})^2 Losstree=∑(yileft−yˉleft)2+∑(yjright−yˉright)2 - 强分类器的平方损失函数,是取所有样本的预测值与真实值的平方损失之和最小
L o s s = ∑ ( y i − y i p r e ) 2 Loss = ∑(y_i-y_i^{pre})^2 Loss=∑(yi−yipre)2, y i y_i yi表示真实值, y i p r e y_i^{pre} yipre表示预测值
用来选取弱分类器的特征及特征值,进而将所有样本数据划分成两个子集
每个子集的预测值,是子集的均值- 根据 y p r e = f m ( x ) = f m − 1 ( x ) + T ( x , θ m ) y_{pre}=f_m(x)=f_{m-1}(x)+T(x,θ_m) ypre=fm(x)=fm−1(x)+T(x,θm),可得
- L o s s = ∑ ( y i − f m − 1 ( x ) − T ( x , θ m ) ) 2 Loss=∑(y_i-f_{m-1}(x)-T(x,θ_m))^2 Loss=∑(yi−fm−1(x)−T(x,θm))2
- 其中 y i − f m − 1 ( x ) y_i-f_{m-1}(x) yi−fm−1(x)表示上次强分类器的预测值与实际值的差,一般叫做残差(残留的差值)
- 我们可以设为 r i = y i − f m − 1 ( x ) r_i = y_i-f_{m-1}(x) ri=yi−fm−1(x),表示残差
- 那么 要使Loss达到最小,只需要当前的弱分类器,尽可能地拟合残差即可, L o s s = ∑ ( r i − T ( x , θ m ) ) 2 Loss=∑(r_i-T(x,θ_m))^2 Loss=∑(ri−T(x,θm))2
- 那么我们无需求出当前弱分类器的参数 θ,只要计算出每次的强分类器后的残差,再新增一个弱分类器,对残差进行CART回归树的拟合即可
-
每次只对残差拟合,直到Loss函数达到某个极小的阈值、特征及特征值已完全分完了,或达到迭代次数即可
2. 程序推演
设置阈值
获取所有特征及特征值
第一轮:
- 更改CART决策树,让它只每次只选择一个特征及特征值,划分数据集
- 每次划分后,计算出当前弱分类器的预测值 T m ( x , θ ) T_m(x,θ) Tm(x,θ)——对样本的数值预测
- 计算出强分类器的预测值 f m = f m − 1 + T ( x , θ ) f_m=f_{m-1}+T(x,θ) fm=fm−1+T(x,θ)
- 再计算所有样本的残差(预测值-真实值)
- 计算强分类器的平方损失函数Loss,判断是否低于阈值,若低于阈值,停止程序
第二轮:
- 根据残差,再用CART决策树,选择一个特征及特征值,划分数据集
- 每次划分后,计算出当前弱分类器的预测值 T m ( x , θ ) T_m(x,θ) Tm(x,θ)——对样本更新后的残差预测
- 计算出强分类器的预测值 f m = f m − 1 + T ( x , θ ) f_m=f_{m-1}+T(x,θ) fm=fm−1+T(x,θ)
- 再计算所有样本残差的残差(预测值-残差值)
- 计算强分类器的平方损失函数Loss,判断是否低于阈值,若低于阈值,停止程序
第三轮同第二轮…
perfect!
二叉回归树代码
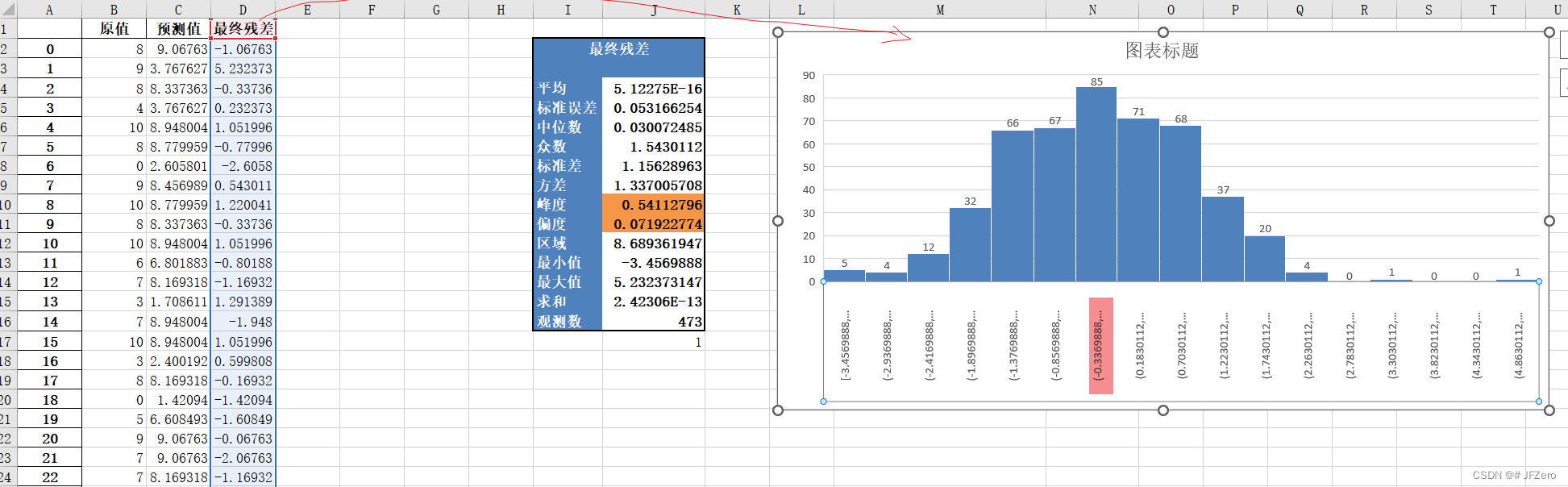
确实,预测值的还不错的感觉,但不知道会不会过拟合,还没用测试数据去试。。。大概率是会过拟合的吧。。。
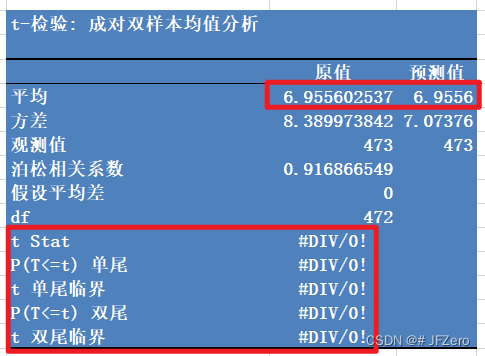
最终预测值和原值的残差,呈正态分布,且大多数聚集在0附近,本来想做个配对样本T检验的。。。但好像均值差距太小,搞不起来
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
pd.options.display.max_columns = None
pd.options.display.max_rows = None
# 获取所需数据:'推荐分值', '专业度','回复速度','服务态度','推荐类型'
datas = pd.read_excel('./datas4.xlsx')
important_features = ['专业度','回复速度','服务态度','推荐分值'] #datas_1 = datas[important_features]
Y = datas_1['推荐分值']
X = datas_1.drop('推荐分值',axis=1)
X_features = X.columns
Y_features = '推荐分值'# 设置阈值
# 获取所有特征及特征值
# 单次:
# 1. 更改CART决策树,让它只每次只选择一个特征及特征值,划分数据集
# 2. 每次划分后,计算出当前弱分类器的预测值$T_m(x,θ)$
# 3. 计算出强分类器的预测值$f_m=f_{m-1}+T(x,θ)$
# 4. **再计算并更新所有样本的残差(预测值-真实值)**
# 5. 计算强分类器的平方损失函数Loss,判断是否低于阈值,若低于阈值,停止程序
class CartRegTree:def __init__(self,datas,Y_feat,X_feat):self.tree_num = 0self.datas = datasself.Y_feat = Y_featself.X_feat = X_featself.all_feat_and_point = self.get_feat_and_point()self.T = {} # 用于存储所有弱分类器self.last_Loss = 0# 获取所有特征及特征值def get_feat_and_point(self):all_feat_and_point = {}for i in self.X_feat:divide_points = self.datas[i].unique()points = [j for j in divide_points]all_feat_and_point[i]=pointsreturn all_feat_and_pointdef get_tree_name(self):self.tree_num += 1return 'T'+str(self.tree_num)def get_subtree(self,datas):# 1. 选择最优的特征及特征值,划分数据集min_Loss = Nonefeat_and_point = Nonefor feat,points in self.all_feat_and_point.items():for point in points:temp_Loss = self.get_Loss_tree(datas,feat,point)if min_Loss == None or temp_Loss<min_Loss:min_Loss = temp_Lossfeat_and_point = (feat,point)left_datas = datas[datas[feat_and_point[0]]<=feat_and_point[1]]right_datas = datas[datas[feat_and_point[0]] > feat_and_point[1]]# 2.计算出当前弱分类器的预测值,存储左右子树的预测值left_Y = left_datas[self.Y_feat].mean()right_Y = right_datas[self.Y_feat].mean()T_name = self.get_tree_name()self.T[T_name]={'feat':feat_and_point[0],'point':feat_and_point[1],'left_Y':left_Y,'right_Y':right_Y}# 3. 计算并更新所有样本的残差,datas['Tm'] = np.where(datas[feat_and_point[0]]<=feat_and_point[1],left_Y,right_Y)datas[self.Y_feat] = datas[self.Y_feat]-datas['Tm']# 4. 计算残差平方和,判断是否停止Loss = round((datas[self.Y_feat]**2).sum(),2)if Loss==self.last_Loss or self.tree_num>10**3:return self.Telse:self.last_Loss = Lossself.get_subtree(datas)def get_Loss_tree(self,datas,feat,point):left_datas = datas[datas[feat]<=point]right_datas = datas[datas[feat]>point]# 求左右两边的平方损失和left_mean = left_datas[self.Y_feat].mean()right_mean = right_datas[self.Y_feat].mean()left_r = left_datas[self.Y_feat]-left_meanright_r = right_datas[self.Y_feat]-right_meanleft_loss = (left_r**2).sum()right_loss = (right_r**2).sum()Loss = left_loss+right_lossreturn Lossdef predict_one(self,data):Y_temp = 0for tree_key,tree_value in self.T.items():feat = tree_value['feat']point = tree_value['point']left_Y = tree_value['left_Y']right_Y = tree_value['right_Y']if data[feat]<=point:Y_temp += left_Yelse:Y_temp += right_Yreturn Y_tempdef predict(self,datas):Y_pre_all = datas.apply(self.predict_one,axis=1)return Y_pre_all
# 应用了pandas中的apply函数,将每行数据都进行predict运算预测
tree = CartRegTree(datas_1,Y_features,X_features)
tree.get_subtree(datas_1)
Y_hat = tree.predict(datas_1)
lenth = len(Y_hat)
result = pd.DataFrame([[i[0],i[1],i[2]] for i in zip(Y,Y_hat,Y-Y_hat)])
# result = pd.DataFrame([list(Y),list(Y_hat),list(Y-Y_hat)])
print(result)
# print(f"{Y},{Y_hat},残差:{Y-Y_hat}")writer = pd.ExcelWriter('datas_reg_result.xlsx')
# 获取所需数据
result.to_excel(writer,"result")
writer._save()