文章目录
- 一、目标检测介绍
- 二、YOLOv5介绍
- 2.1 和以往版本的区别
- 三、代码获取
- 3.1 视频代码介绍
- 四、环境搭建
- 五、数据集准备
- 5.1 数据集转换
- 5.2 数据集验证
- 六、模型训练
- 七、模型验证
- 八、模型测试
- 九、评价指标
一、目标检测介绍
目标检测(Object Detection)是计算机视觉领域的一个重要研究方向,其主要任务是从图像或视频中识别并定位出感兴趣的目标对象。目标检测技术在许多实际应用中具有广泛的用途,如自动驾驶、视频监控、医学影像分析等。
目标检测的主要方法可以分为两大类:基于传统机器学习的方法和基于深度学习的方法。
-
基于传统机器学习的方法:这些方法主要依赖于手工设计的特征提取器和分类器。常用的特征提取器包括SIFT、SURF、HOG等,而分类器则可以是支持向量机(SVM)、随机森林(Random Forest)、K-近邻(KNN)等。这类方法通常需要大量的标注数据进行训练,但在一些特定场景下,它们仍具有一定的性能。
-
基于深度学习的方法:近年来,深度学习在目标检测领域取得了显著的进展。深度学习方法主要包括卷积神经网络(CNN)和区域卷积神经网络(R-CNN)。
- 卷积神经网络(CNN):CNN通过多层卷积层和池化层来自动学习图像的特征表示。著名的目标检测网络有Faster R-CNN、Faster R-CNN v2和YOLO(You Only Look Once)。这些网络可以生成候选框,然后使用非极大值抑制(NMS)等技术去除重叠的框,从而得到最终的目标检测结果。
- 区域卷积神经网络(R-CNN):R-CNN通过引入Region Proposal Network (RPN)来生成候选框。RPN首先在图像中生成一系列可能包含目标的区域,然后将这些区域送入CNN进行特征提取和分类。著名的R-CNN网络有Fast R-CNN、Faster R-CNN和Mask R-CNN。这些网络相较于传统的目标检测方法具有更高的准确率和速度。
随着深度学习技术的发展,目标检测的性能得到了显著提升,同时计算复杂度也得到了降低。这使得目标检测技术在各种应用场景中得到了广泛应用。
二、YOLOv5介绍
YOLOv5是一种目标检测算法,是YOLO(You Only Look Once)系列的较新版本。它由ultralytics团队开发的,采用PyTorch框架实现。
YOLOv5相较于之前的版本,有以下几个显著的改进:
- 更高的精度:YOLOv5在精度上有了显著提升,特别是在小目标检测方面。
- 更快的速度:YOLOv5相较于YOLOv4,速度更快,可以实时运行在较低的硬件设备上。
- 更小的模型:YOLOv5相较于YOLOv4,模型大小更小,占用更少的存储空间。
- 更好的可扩展性:YOLOv5可以很容易地进行模型的扩展和修改,以适应不同的任务和数据集。
YOLOv5的工作流程如下:
- 输入图像被分割成一系列的网格。
- 每个网格预测一系列的边界框,以及每个边界框属于不同类别的概率。
- 使用非极大值抑制(NMS)算法,去除重叠较多的边界框,并选择最终的检测结果。
YOLOv5可以用于各种目标检测任务,如人脸检测、车辆检测、行人检测等。它在许多计算机视觉竞赛中取得了优异的成绩,并且被广泛应用于实际应用中,如自动驾驶、视频监控等。
2.1 和以往版本的区别
YOLOv1:
- 主干部分主要由卷积层、池化层组成,输出部分由两个全连接层组成用来预测目标的位置和置信度。
- 原理:将每一张图片平均的分成7x7个网格,每个网格分别负责预测中心点落在该网格内的目标。
- 优点:检测速度快、迁移能力强
- 缺点:输入尺寸是固定的,有较大的定位误差
YOLOv2:
- 在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),**识别对象更多(Stronger)**这三个方面进行了改进
- 加入BN层,加速收敛;加入先验框解决物体漏检问题;多尺度训练,网络可自动改变尺寸等等
- 优点:收敛速度快、可自动改变训练尺寸。
- 缺点:对于小目标检测不友好
YOLOv3:
- 针对v2的缺点,1)加入了更好的主干网络(Darknet53),而不是VGG;2)为了提升小目标检测还加入了FPN网络;3)通过聚类生成先验框(一个框:长宽,根据纵横比和它的尺寸生成的先验框);4)加入了更好的分类器-二元交叉熵损失。
- 优点:增强了对于小目标的检测
- 缺点:参数量太大
YOLOv4:
- 差别:
- 特征提取网络的不同:1)Darknet53变成CSPDarknet53(降低了计算量,丰富了梯度信息,降低了梯度重用)相当于多个一个大残差边,再将这部分融合;2)加入了SPP-空间金字塔池化,增加感受野;3)加入了PAN操作,增加一条下采样操作
- 激活函数不同:由leakyrelu变为mish激活函数
- loss不同:余弦退火衰减,学习率会先上升再下降
- 数据增强方法:采用了Cutout(随机剪切框)、GridMask(图像的区域隐藏在网格中)、MixUp(两张图混合)、Mosaic(四张图混合)等方法
- 优点:激活函数无边界,从而避免饱和;融合了多种tricks提升网络性能;参数量相比v3更低,速度更快。
- 缺点:不够灵活,代码对用户体验不好
YOLOv5:
- 差别:
- 自定锚框定义:自动预先利用聚类自定义锚框
- 控制模型大小:通过控制深度和宽度来控制模型的大小,从而区分出s,m,l,x的不同尺寸的模型
- 优化函数:提供了两个优化函数Adam和SGD,并都预设了与之匹配的训练超参数
- 非极大值抑制:DIoU-nms变为加权nms。
- Focus操作:加入切片操作,提升训练速度
- 优点:灵活性更强,速度更快;使用Pytorch框架对用户更好,精度高。
- 缺点:Focus的切片操作对嵌入式并不友好,网络量化不支持Focus;精度和速度不平衡。
- 正负样本匹配策略:通过k-means聚类获得9个从小到大排列的anchor框,一个GT可以同时分配给多个anchor,它们是直接使用Anchor模板与GT Boxes进行粗略匹配,如果GT与某个anchor的iou大于给定的阈值,GT则分配给该Anchor,也就是说可以定位到对应cell的对应Anchor。以前是一个GT只分配给一个anchor。
- 坐标定义1:xyxy→通常为(x1, y1, x2, y2),先两个表示左上角的坐标,再两个表示右下角的坐标。具体来说,这里的‘x1’表示bbox左上角的横坐标,‘y1’表示bbox左上角的纵坐标,‘x2’表示bbox右下角的横坐标,‘y2’表示bbox右下角的纵坐标。
- 坐标定义2:xywh→通常为(x, y, w, h),也就是先两个表示bbox左上角的坐标,再两个表示bbox的宽和高,因此被称为 ‘xywh’ 表示。具体来说,这里的‘x’表示bbox左上角的横坐标,‘y’表示bbox左上角的纵坐标,‘w’表示bbox的宽度,‘h’表示bbox的高度。
三、代码获取
https://github.com/ultralytics/yolov5
3.1 视频代码介绍
可参考这个视频代码讲解:点击
四、环境搭建
安装ultralytics、cuda、pytorch、torchvision,然后执行pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
如果是cpu,则直接安装cpu对应的pytorch和torchvision,然后再执行后面的pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple。
参考这个博客:点击
五、数据集准备
首先我们可以通过labelImg来对图片进行标注,标注的适合我们可以选择保存为VOC或者YOLO格式的数据集,VOC对应为XML,YOLO对应为TXT。具体的准备过程可参考这篇博客:数据集学习笔记(六):目标检测和图像分割标注软件介绍和使用,并转换成YOLO系列可使用的数据集格式
5.1 数据集转换
参考这篇博客:数据集学习笔记(六):目标检测和图像分割标注软件介绍和使用,并转换成YOLO系列可使用的数据集格式
5.2 数据集验证
参考这篇博客:数据集学习笔记(六):目标检测和图像分割标注软件介绍和使用,并转换成YOLO系列可使用的数据集格式
import cv2
import os# 读取txt文件信息
def read_list(txt_path):pos = []with open(txt_path, 'r') as file_to_read:while True:lines = file_to_read.readline() # 整行读取数据if not lines:break# 将整行数据分割处理,如果分割符是空格,括号里就不用传入参数,如果是逗号, 则传入‘,'字符。p_tmp = [float(i) for i in lines.split(' ')]pos.append(p_tmp) # 添加新读取的数据# Efield.append(E_tmp)passreturn pos# txt转换为box
def convert(size, box):xmin = (box[1] - box[3] / 2.) * size[1]xmax = (box[1] + box[3] / 2.) * size[1]ymin = (box[2] - box[4] / 2.) * size[0]ymax = (box[2] + box[4] / 2.) * size[0]box = (int(xmin), int(ymin), int(xmax), int(ymax))return boxdef draw_box_in_single_image(image_path, txt_path):# 读取图像image = cv2.imread(image_path)pos = read_list(txt_path)for i in range(len(pos)):label = classes[int(str(int(pos[i][0])))]print('label is '+label)box = convert(image.shape, pos[i])image = cv2.rectangle(image,(box[0], box[1]),(box[2],box[3]),colores[int(str(int(pos[i][0])))],2)cv2.putText(image, label,(box[0],box[1]-2), 0, 1, colores[int(str(int(pos[i][0])))], thickness=2, lineType=cv2.LINE_AA)cv2.imshow("images", image)cv2.waitKey(0)if __name__ == '__main__':img_folder = "D:\Python\company\Object_detection\datasets\mask_detection/train\images"img_list = os.listdir(img_folder)img_list.sort()label_folder = "D:\Python\company\Object_detection\datasets\mask_detection/train/labels"label_list = os.listdir(label_folder)label_list.sort()classes = {0: "no-mask", 1: "mask"}colores = [(0,0,255),(255,0,255)]for i in range(len(img_list)):image_path = img_folder + "\\" + img_list[i]txt_path = label_folder + "\\" + label_list[i]draw_box_in_single_image(image_path, txt_path)六、模型训练
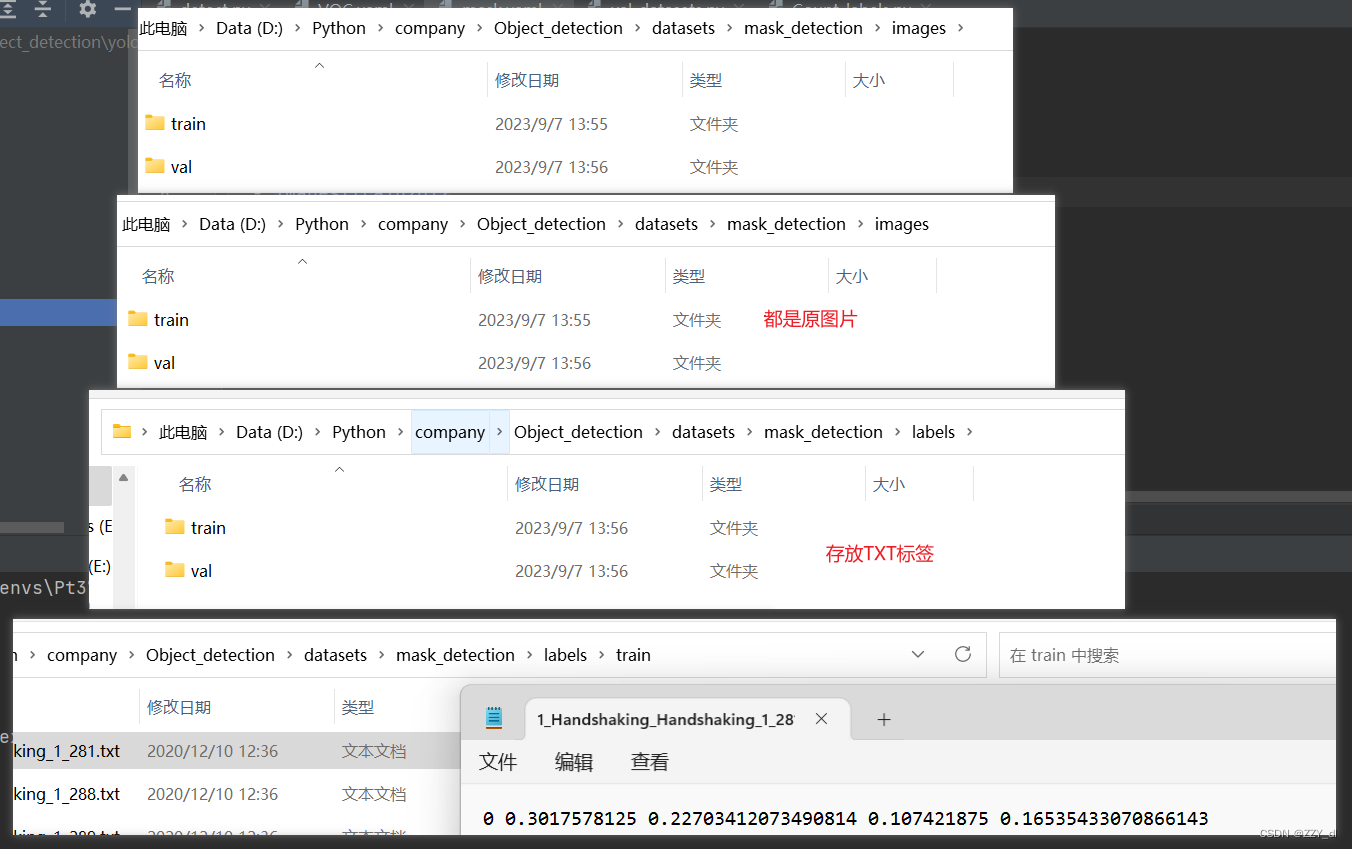
我们将所有的原图和TXT标签得到之后,为下图结构:
mask_detection
- images
- train
- val
- labels
- train
- val
修改yaml数据集配置文件:
统计口罩佩戴的数量信息:
# 只需要修改txt路径和样本数和类别名
import ostxt_path = "D:\Python\company\Object_detection\datasets\mask_detection/train/labels" # txt所在路径
class_num = 2 # 样本类别数
classes = {0: "no-mask", 1: "mask"}
class_list = [i for i in range(class_num)]
class_num_list = [0 for i in range(class_num)]
labels_list = os.listdir(txt_path)
for i in labels_list:file_path = os.path.join(txt_path, i)file = open(file_path, 'r') # 打开文件file_data = file.readlines() # 读取所有行for every_row in file_data:class_val = every_row.split(' ')[0]class_ind = class_list.index(int(class_val))class_num_list[class_ind] += 1file.close()
# 输出每一类的数量以及总数
for i in classes:print(classes.get(i),":",class_num_list[i])
print('total:', sum(class_num_list))
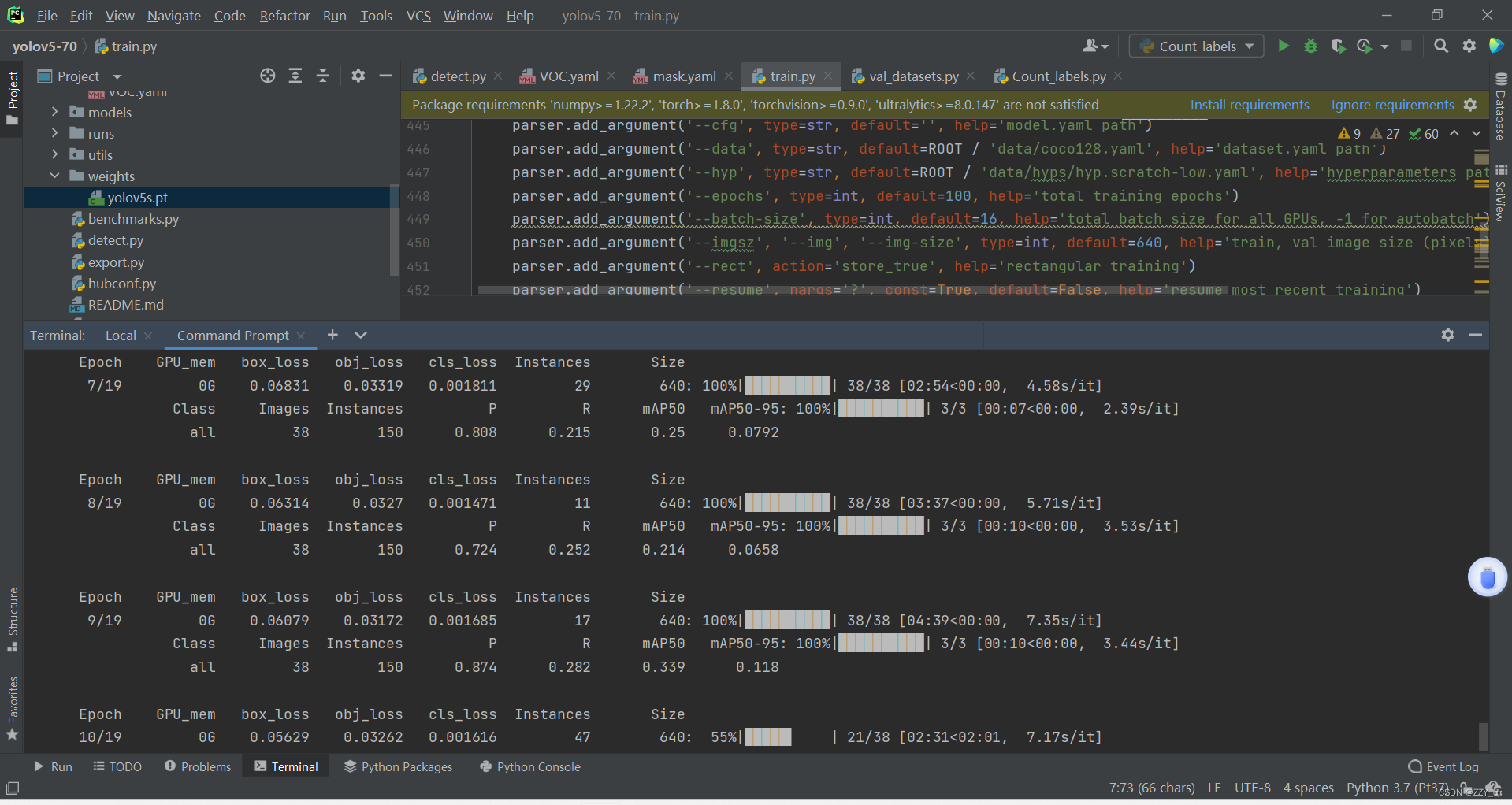
开始准备训练:
python train.py --data data/mask.yaml --weights weights/yolov5s.pt --img 640 --epochs 20 --workers 4 --batch-size 8
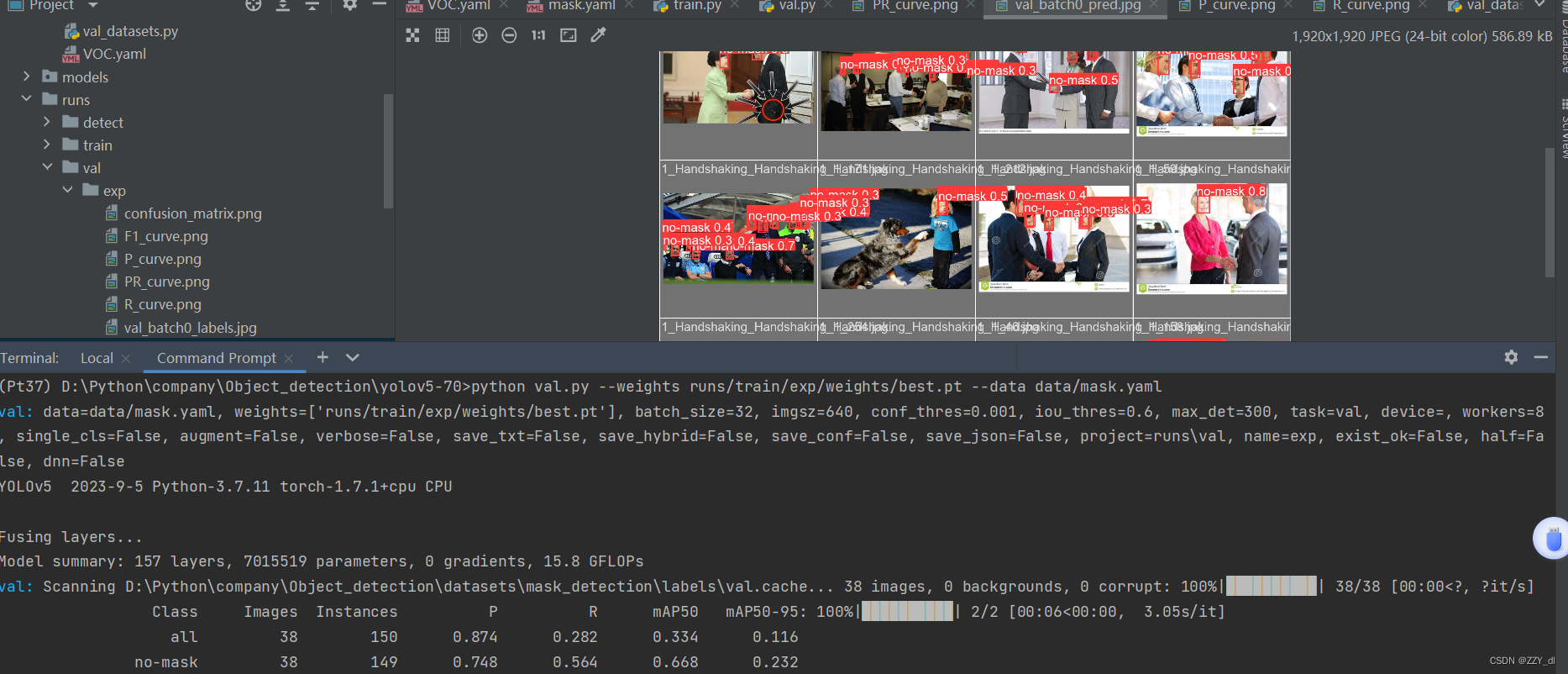
七、模型验证
python val.py --weights runs/train/exp/weights/best.pt --data data/mask.yaml
八、模型测试
python detect.py --weights runs/train/exp/weights/best.pt

九、评价指标
YOLOv5是一种用于目标检测的深度学习模型,它使用了YOLO(You Only Look Once)算法。评价指标是用来衡量模型性能的指标,以下是YOLOv5常用的评价指标介绍:
-
mAP(mean Average Precision):平均精度均值。mAP是目标检测中最常用的评价指标之一,它综合考虑了准确率和召回率。mAP的取值范围是0到1,数值越高表示模型性能越好。
- mAP50:是指平均精确度(mean Average Precision)的值,其中计算的是检测模型在IoU(Intersection over Union)阈值为0.5时的平均精确度。
- mAP50-95 : mAP50-95是指在计算平均精确度时,使用IoU阈值从0.5到0.95的范围进行计算,然后取平均值。这个指标可以更全面地评估检测模型在不同IoU阈值下的表现。
-
Precision(精确率):精确率是指模型预测为正例中真正为正例的比例。Precision的计算公式是预测为正例且正确的样本数除以预测为正例的样本数。
-
Recall(召回率):召回率是指真实为正例中被模型正确预测为正例的比例。Recall的计算公式是预测为正例且正确的样本数除以真实为正例的样本数。
-
F1-score:F1-score是精确率和召回率的调和平均值,它综合考虑了两者的性能。F1-score的计算公式是2 * (Precision * Recall) / (Precision + Recall)。
-
AP(Average Precision):平均精度。AP是mAP的组成部分,它是在不同的置信度阈值下计算得到的精度值的平均值。
-
IoU(Intersection over Union):交并比。IoU是计算预测框和真实框之间重叠部分的比例,用于判断预测框和真实框的匹配程度。一般情况下,当IoU大于一定阈值时,认为预测框和真实框匹配成功。