概念
- timestamp: influxdb所有的数据都会有一个列_time来存timestamp。默认是以nanosecond格式存储的。
- field: field就是mysql中的字段,field key存储在_field字段中,field value就是字段值,存储在_value字段中。field key和field value对组成的集合field set。其中key只能是string类型,value可以是integer,string,float,boolean四种类型。field是没有索引的。如果查询条件是field,则会扫描符合条件的所有field的值。field用于保存具体的时序数据,也就是随时间变化的数据。比如定位信息,温度信息。
- tag:同field,唯一区别就是tag是索引,并且value只能是string。所以建议用tag来做查询条件。tag key就直接作为字段名,没有像_field固定的字段来存储key,value就是tag key字段的值。可以将tag理解为自定义字段加索引。tag一般用于保存数据来源的信息。比如设备id。
- measurement:有点像mysql中的表,_measument字段来表示,作为key,tag和timestamp的集合。用measurement来表示数据。
- retention policy:数据保留策略,默认是永久保留,副本数量为1。
- series key: servies key是point的集合。series key包括measurment,tag set和field key。可以理解为一个列的所有数据集合的key。
- series: 包括时间戳和series对应的field value。同一个series的数据在物理上会按照时间顺序排序在一起。可以理解为一个列的所有数据和时间戳的集合。

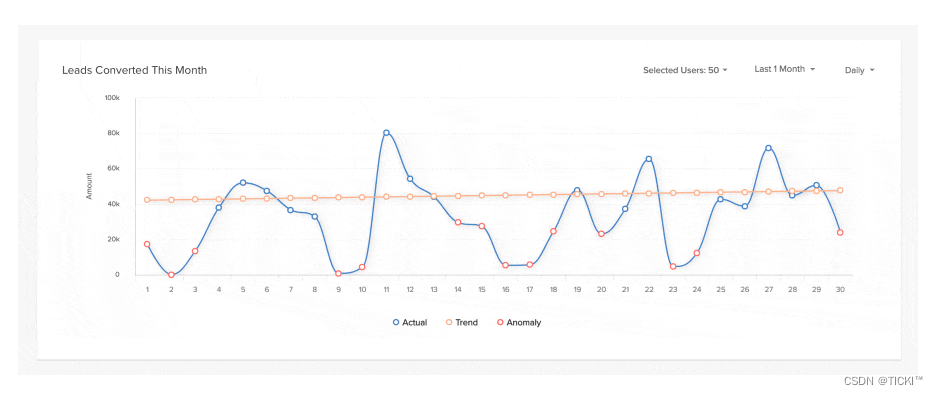
census是measurment,两个等号是两个tag kv,bees是field key。23和28是field value。
- point:就是一个数据行,一条记录,多个point组成series。表示某个采集时间点的数据,包括series key(里面并不包括field key)和对应的field value,timestamp。

图片中前面是timestamp,census是measurment,ants和30是tag kv,portland和mullen是field value。 - database:等同于mysql的database,里面存有多个measurement,retention policy。2.x版本中已经移除database的概念。
- bucket:结合了database和retention period,bucket属于organization。
- organization:可以理解为工作空间,包括多个用户。buckets和users都是属于oraganization。
总结:上层的概念是oraganization,所有的数据都是属于org的。数据的存储都是在bucket里面。可以理解为数据库,2.x版本中没有database这个概念了。measurement可以理解成为一张表,但是实际上不是一个表。数据中point表示一条数据,每条数据都有一个_time表示时间戳,series表示point的集合,field是固定字段_field,key和value都是值,没有索引,tag是自定义字段名和值,索引的结合
安装
mac安装
brew update
brew install influxdb
启动执行influxd &或者brew services start influxdb,默认端口号是8086,启动完之后,在控制台打开localhost:8086来访问控制台。用brew安装会连同客户端命令一起安装。
influxdb默认端口号是8086,如果要修改端口,可以使用
influxd --http-bind-address=localhost:9000
删除influxdb
brew uninstall influxdb
rm -rf /opt/homebrew/etc/influxdb
rm -rf ~/.influxdbv2/ 其中engine/data目录是数据目录,每个子目录都是一个bucket_id,且必须bucket里面插入数据时,才会创建对
rm -rf ~/.influx_history
rm -rf /var/lib/influxdb
一定要删除上面三个目录文件才能彻底删除。
如果是用tar包安装的就要按照具体的配置的路径去删除。
docker安装
influxdb是用go语言开发的,可以直接使用docker进行安装。
docker run --name influxdb -p 8086:8086 influxdb:2.7.0,安装的版本是2.7。默认的端口是8086。
启动完成后,可以直接通过localhost:8086来访问,打开控制台来操作influxdb。
服务端命令
influxd version: 查看服务端的版本
influxd run: 运行服务端,默认不加run也可以。
influxd inspect: 检查磁盘上面的数据
influxd print-config: 打印当前服务端的完整配置
influxd upgrade: 升级inflxud
influxdb目录结构
配置文件在/opt/homebrew/etc/influxdb2/onfig.yml文件, linux是/etc/influxdb/config.toml
数据目录默认在~/.influxdbv2/,其中engine是数据目录。
默认的配置文件是~/.influxdbv2/configs。在里面可以查看各个config中指定的auth token。如果你忘了token,想要查看,除了可以用命令行以外,也可以来这个文件中查看。
安装命令行客户端
如果要操作influxdb除了可以使用控制台以外,还可以使用命令行。默认情况下,influxdb命令行工具是需要额外安装的,直接用brew安装或使用压缩包安装都可以,直接从官网下载即可。这里不再赘述。只介绍以下一个技巧,influx命令行自动补全,方便自动补子命令,防止打错。
zsh
source <(influx completion zsh)
bash
source $(brew --prefix)/etc/bash_completion.d
source <(influx completion bash)
初始化操作
安装好influxdb之后,默认是没有用户,也没有任何数据库的,需要先进行初始化操作。初始化操作分为两种方式:控制台和命令行。
控制台初始化
打开控制台,localhost:8086,会先创建一个用户,输入username,password,org,bucket,token。token一定要保存下来,因为默认没办法查。按步骤操作完成后就完成初始化了。
命令行初始化
influx setup
会进入交互式的初始化,输入用户名,密码,org,bucket。同时默认会创建一个token和一个默认的config,初始化之后默认客户端就有权限了,直接通过influx auth list来查询。如果没有权限执行auth,可以查看~/.influxdbv2/configs文件中的token信息。
如果setup命令报错:failed to check if already set up: Get “http://localhost:8086/api/v2/setup”,说明influxdb的端口并不是8086,因此setup要指定host,influx setup --host=localhost:port来执行。
初始化操作默认只能进行一次,初始化之后正常情况下无法再进行第二次初始化。除非是将上面所有的数据和配置卸载干净,卸载方法文章最后有
创建config
默认情况下,需要直接输入命令是没有权限的,会报401错误。

需要在所有的命令后面加上-t token,才能认证通过。如果不想每次都加上-t,则需要创建config。config可以理解客户端存储token信息的地方。后续输入命令就不用每次都加token了
可以使用以下命令来创建config。
influx config create --config-name=test --host-url=http://localhost:8086 --org=test --token=token_value --active
org是最外层的空间,一个config只能对应一个org,一个用户同时也只能访问一个org。org可以包含多个bucket,bucket可以理解为一个database,用来存储数据的。该config与服务端的config不是一回事
auth就是一个认证,即一个token对应一个用户,通过auth命令可以查看token,但是前提也是需要有token认证的时候才有权限去查看。因此无论如何,第一次生成的token必须要保存下来。
在虚拟机centos上安装influxdb2
因为虚拟机也是arm的cpu,所以要选择arm类型
cat <<EOF | sudo tee /etc/yum.repos.d/influxdata.repo
[influxdata]
name = InfluxData Repository - Stable
baseurl = https://repos.influxdata.com/stable/\$basearch/main
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdata-archive_compat.key
EOF
将上面一段代码copy进入,回车,是为了将influx的库添加到yum中。
sudo yum install influxdb2 安装influxdb2。
如果使用yum安装时报错Peer’s Certificate has expired,跟本地操作系统是没有关系的,可以使用命令sudo yum update -y ca-certificates更新一下。再尝试安装。
centos卸载influxdb2
sudo yum -y remove influxdb2
sudo rm -rf /etc/influxdb
sudo rm -rf /var/lib/influxdb
sudo rm -rf ~/.influxdbv2 # 数据文件和配置文件
安装influx-cli
安装influx-cli,这个在linux上面需要单独安装的。
wget https://dl.influxdata.com/influxdb/releases/influxdb2-client-2.7.3-linux-arm64.tar.gz
tar xvzf influxdb2-client-2.7.3-linux-arm64.tar.gz
sudo cp influx /usr/local/bin/
初始化
influx setup创建用户,org,bucket即可。
恢复到初始状态
如果对influxdb不想重新安装,只是想恢复到初始状态,直接删除对应的数据目录和配置目录即可。
rm -rf /opt/homebrew/etc/influxdb2
rm -rf ~/.influxdbv2/
rm -rf ~/.influx_history
配置文件在/opt/homebrew/etc/influxdb2/config.yml
连接远程服务器
influx bucket list -t HHsaJIz4CMSEXnavR09BJ0rg8oo5Gu1hzyGn4H0UNmaYG3Ypw4o0fa2z35Qb1eHMy7xC3GoQWcSqiDJCoskS-g== --host http://192.167.57.90:8086 -o earth
-t指定服务器上面的token
–host指定服务器的地址
-o指定服务器的org
添加自动补全命令工具
使用zsh用以下命令即可,后面输入influx的子命令都可以自动补全
source <(influx completion zsh)
bash
source $(brew --prefix)/etc/bash_completion.d
source <(influx completion bash)
bash for linux
source /etc/bash_completion.d/authselect-completion.sh
source <(influx completion bash)