分词
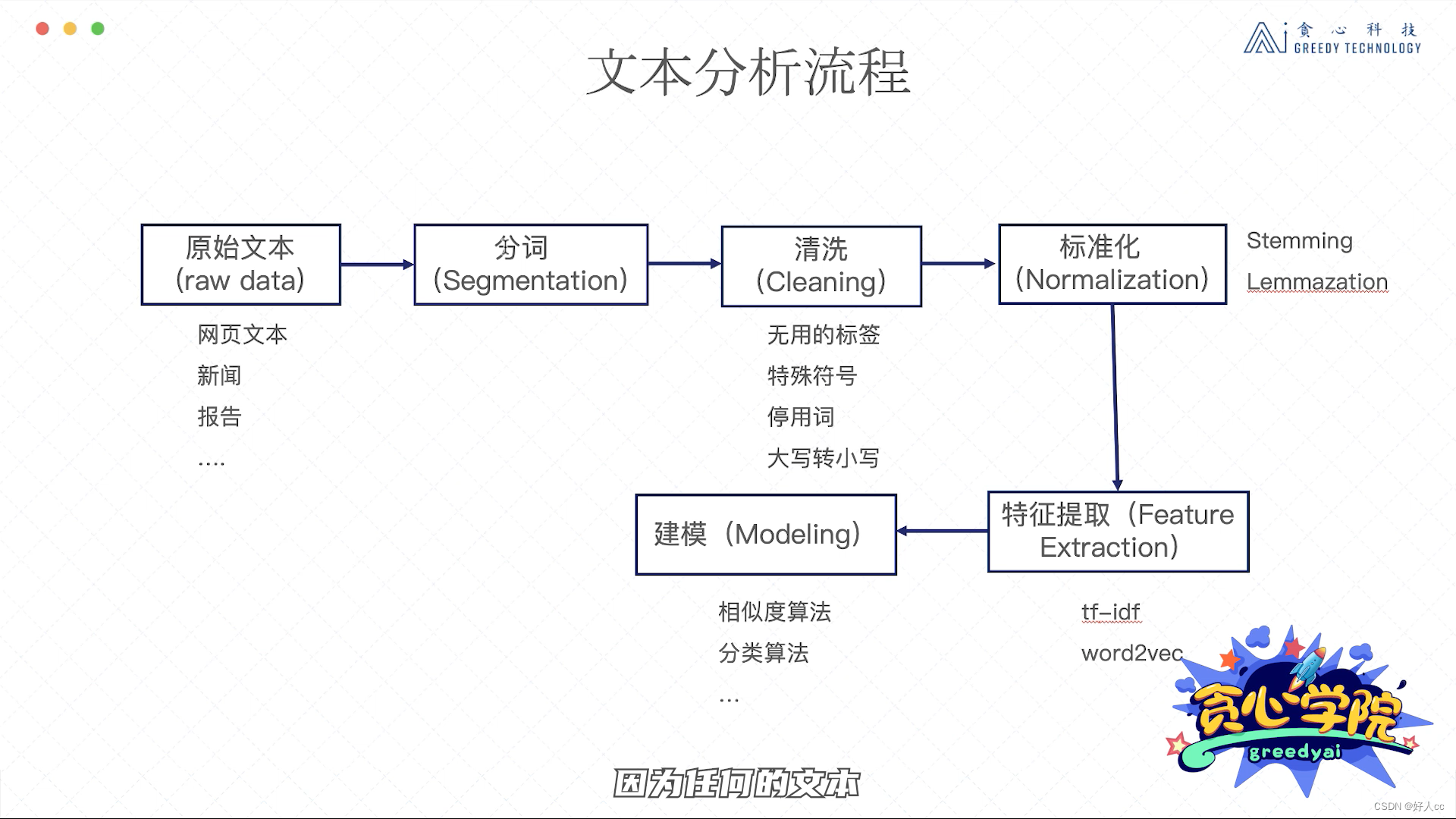
分词是最基本的第一步。无论对于英文文本,还是中文文本都离不开分词。英文的分词相对比较简单,因为一般的英文写法里通过空格来隔开不同单词的。但对于中文,我们不得不采用一些算法去做分词。
常用的分词工具

# encoding=utf-8
import jieba
# 基于jieba的分词 参考: https://github.com/fxsjy/jieba
seg_list = jieba.cut("贪心学院是国内最专业的人工智能在线教育品牌", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))
# 在jieba中加入"贪心学院"关键词
jieba.add_word("贪心学院")
seg_list = jieba.cut("贪心学院是国内最专业的人工智能在线教育品牌", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))结果:
Default Mode: 贪心/ 学院/ 是/ 国内/ 最/ 专业/ 的/ 人工智能/ 在线教育/ 品牌
Default Mode: 贪心学院/ 是/ 国内/ 最/ 专业/ 的/ 人工智能/ 在线教育/ 品牌一般情况下,我们还是要定义属于自己的专有名词的。如果我们考虑的是医疗领域,则需要把医疗领域我们比较关注的词先加入到词库里,再通过结巴工具做分词,毕竟很多的专有词汇并不存在于结巴的词库里。大部分情况下只需要使用工具去分词就可以了,没必要自己造轮子。但有一些特殊情况,比如这些开源工具的效果很一般,或者它们缺少某些方面的考虑,则可能需要自己写一个分词工具。实际上,自己写一个分词工具也不难,可以基于HMM, CRF等方法来构造分词器。具体算法细节超出了此课程的范围,感兴趣的可以关注下我们高阶的训练营。
单词的过滤
接下来,我们一般做单词的过滤或者字符的过滤。比如把一些出现次数特别多的单词过滤掉也叫作停用词的过滤,或者把那些出现次数特别少的单词过滤掉,或者把一些特殊符号比如#@过滤掉。

那什么叫停用词呢? 其实很容易理解:就是那些出现特别频繁,但对于一个句子贡献不是特别大的单词。比如”的“, ”他“可以认为是停用词。去掉停用词的方法也超级简单,就是提前设计好停用词库,然后做文本分析时把这些停用词忽略掉就可以了。
停用词库的构建可以有三种方法。 第一、手动去设置停用词库,把所有的停用词写入一个文件。这个过程比较耗费时间,但对于非常垂直类的应用还是最有效的。第二、从网上搜索停用词库,一般来讲网络上可以找到大部分语言的停用词库,这些都是别人已经整理好的,所以基本都是通用的。但有些时候确实由于应用本身的特点,这些停用词库可能还满足不了需求。所以,这时候需要适当地加入一些人工方式来整理的单词。第三、从第三方工具中导入停用词库,比如NLTK这些工具已经集成了不同语言的停用词库,所以使用的时候直接调用就可以了。
# 方法1: 自己建立一个停用词词典
stop_words = ["the", "an", "is", "there"]
# 在使用时: 假设 word_list包含了文本里的单词
word_list = ["we", "are", "the", "students"]
filtered_words = [word for word in word_list if word not in stop_words]
print (filtered_words)
# 方法2:直接利用别人已经构建好的停用词库
from nltk.corpus import stopwords
cachedStopWords = stopwords.words("english")
print(cachedStopWords)
除了停用词,我们也通常会去掉出现次数特别少的单词,毕竟这些单词的频次太低,对整个训练来说起到的作用也不大。那如何去制定什么样的单词才叫作出现次数少的呢? 这里其实没有一个标准答案,还是需要去了解一下每个单词出现的次数,从而再去判断这个阈值。一般来讲,比如一个单词出现少于10次或者20次,我们可以归类为是可以去掉的单词。 但这个也取决于手里的语料库大小。如果语料库本身总共只包含了不到一千个单词,那这个阈值显然有点高了。对于特殊符号,我们也需要做一些处理。特殊符号其实就是我们觉得不太有用的符号。比如一个文章里出现的@#&,这些可以认为是特殊符号,进而可以去掉。
词的标准化操作
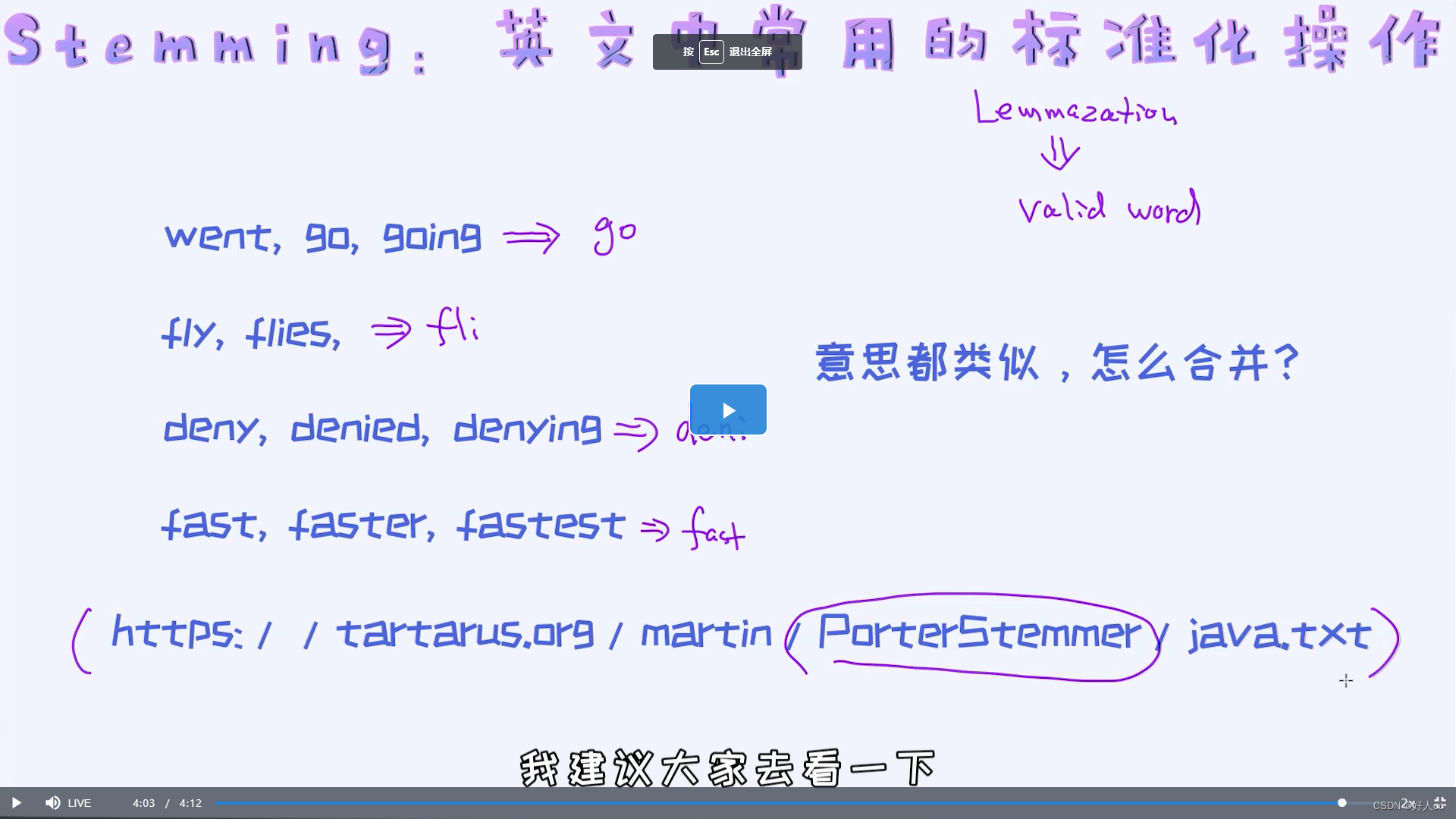
对于英文文本,我们通常会做单词标准化的操作,也就是把类似含义的单词统一表示成一种形式。这里有两种常用的方法,分别是stemming和lemmazation。
stemming有可能出的结果不合理 但是lemmazation肯定合理

这些标准化的操作一般应用于英文等语言上,但对于中文用的不多,也是因为中文本身的特点不像英文那样有一种固定的格式比如单数或者复数。做完这些预处理工作之后,我们就可以开始对文本本身做处理了,也就是把文本表示成向量的形式,之后再把它放入模型当中。那如何把文本表示成向量呢? 让我们进入下一节的内容!
单词的表示了解完了(独热编码),接下来就要考虑如何表示一个句子了。这里有几种常用的方法,分别是boolean表示、count表示以及tf-idf的表示。

所以,这样的表示方法使得向量非常地稀疏,只有一个位置是11,剩下的全是00,而且向量的长度等于词库的长度,也就是我们的词库有多大,每一个单词向量的长度就有多大。这种方式虽然很简单,但明显也有个缺点,就是不考虑一个单词出现的次数。出现次数越多,有可能对句子的贡献也会越大。我们希望把这部分信息也考虑进去。

其实上面的表示法是有些问题的,因为出现次数越多代表不了它就越重要,有可能反倒是更不重要。所以呢,我们希望把一个单词的重要性也考虑进去,而不仅仅考虑单词出现的次数。这个新的方法叫作tf-idf表示法。
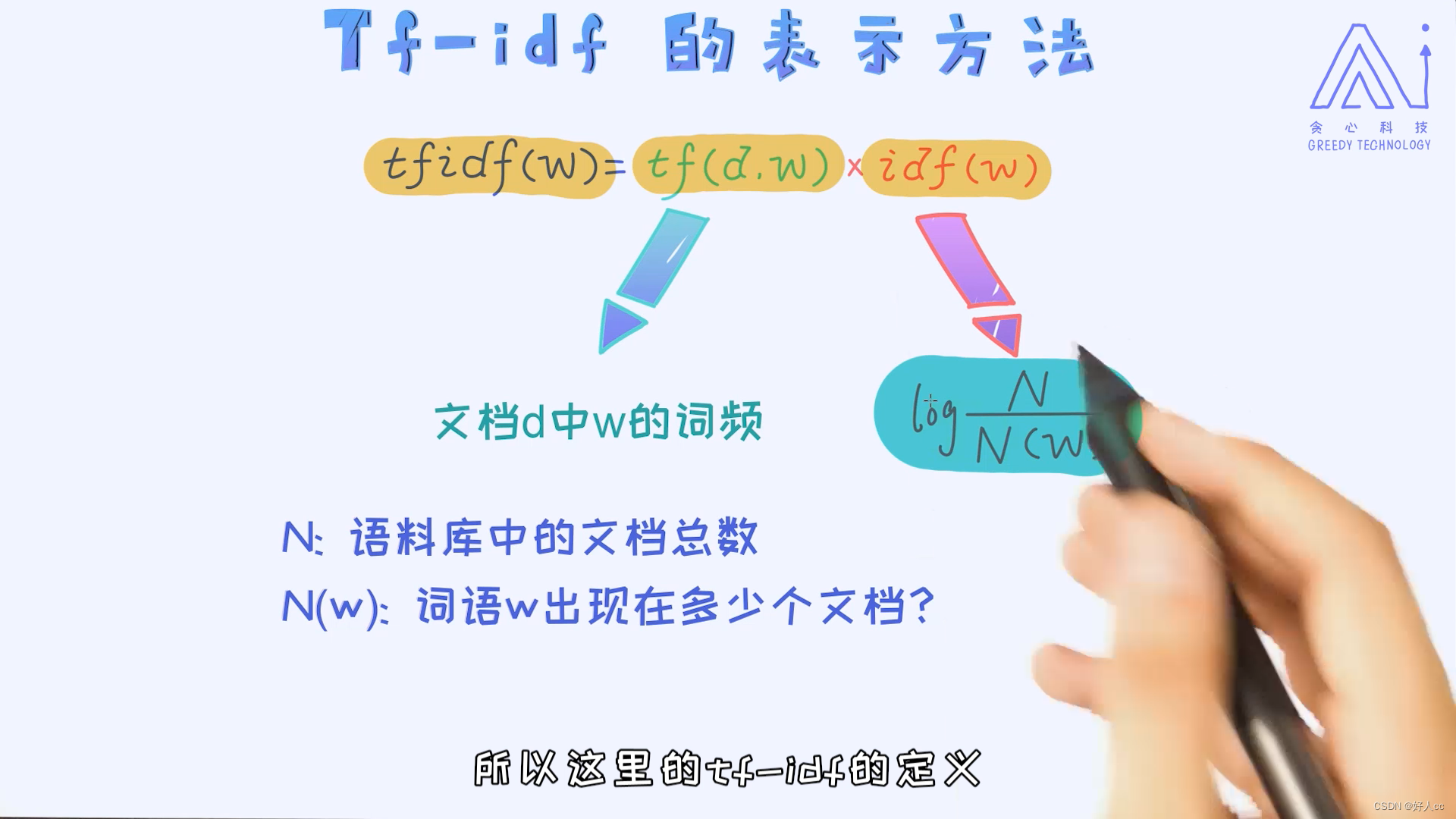

文本相似度比较
在文本分析领域,还有一个工作特别重要,就是计算两个文本之间的相似度。计算相似度是理解文本语义来说也是很重要的技术,因为一旦我们理解了某一个单词或者句子,我们可以通过相似度计算方法来寻找跟这个语义类似的单词或者文本。计算文本相似度有很多种方法,这里我们重点来讲解两个方法:计算欧式距离的方法和计算余弦相似度的方法。它们都可以用来评估文本的相似度,但前者是基于距离的计算,后者是基于相似度的计算。需要注意的一点是:距离越大相似度越小。


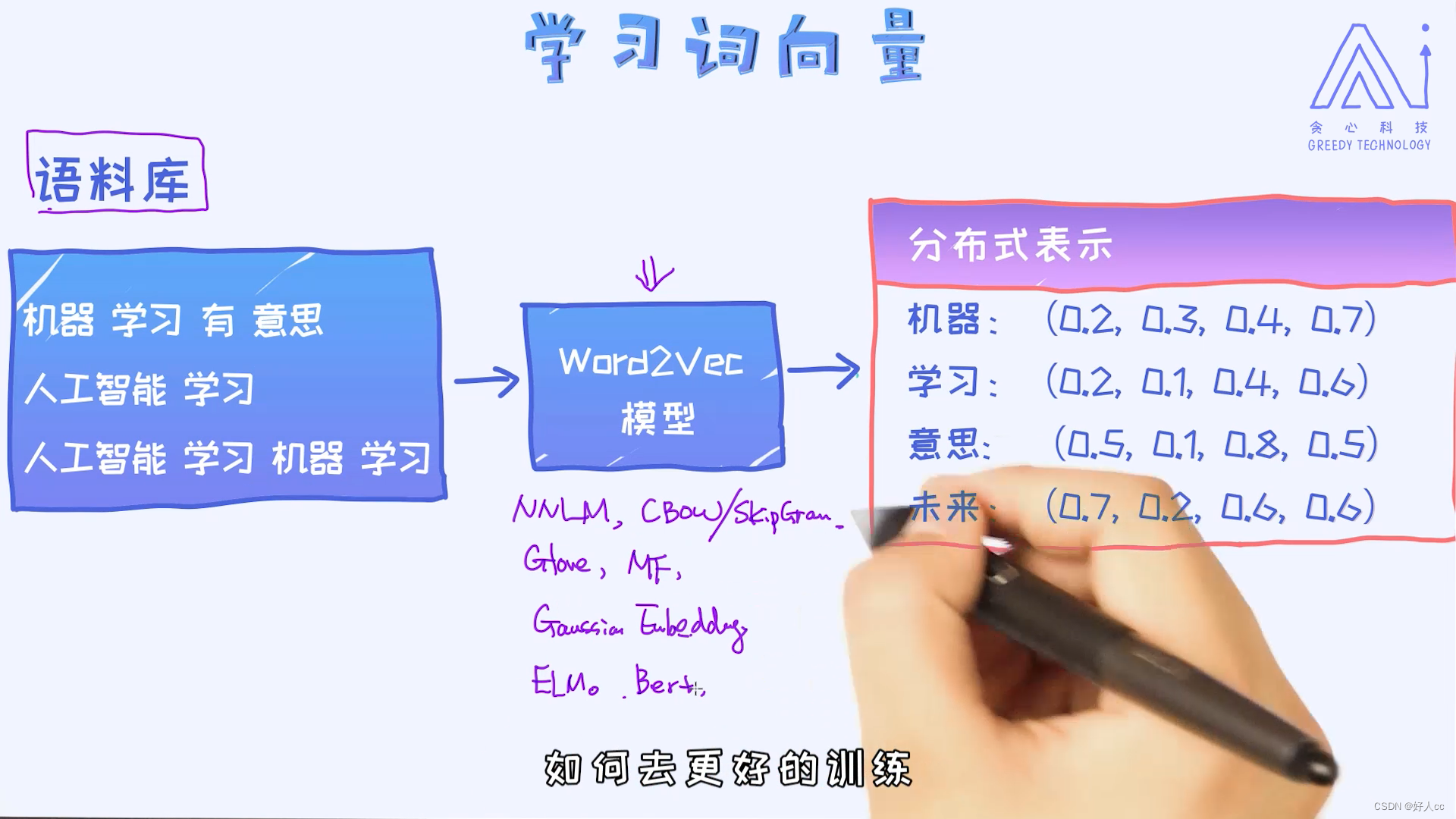
词向量的训练
独热编码->分布式表示 可以体现出单词的相似度
具体训练词向量的方法很多,各有各的优缺点。在这里,我们就把它当作是一个黑盒子就可以了。而且网上有大量已经训练好的词向量,我们可以直接把它拿过来用。

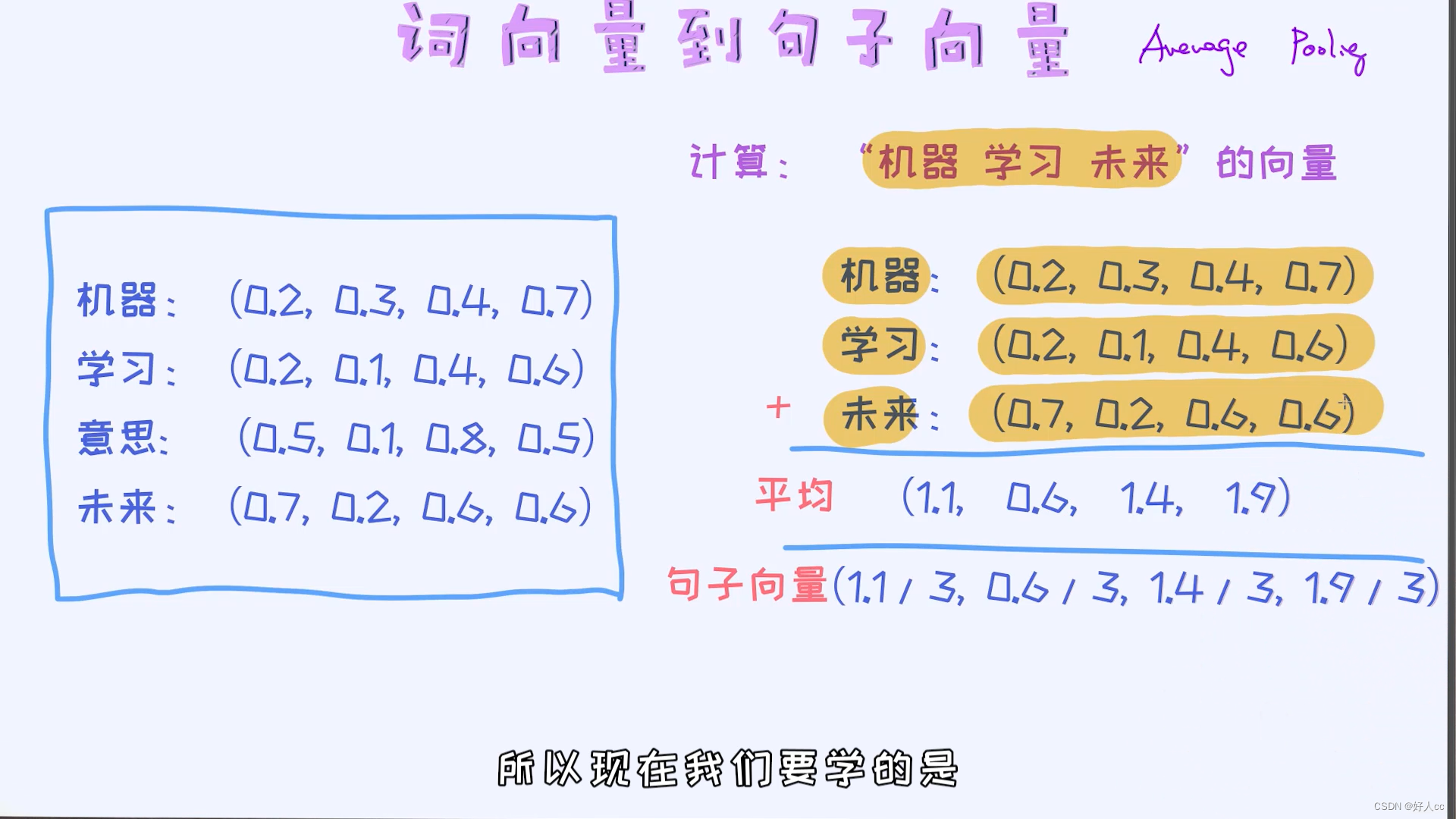
从词向量到句子向量
理解了如何通过词向量来表示一个单词之后,接着我们来看一下如何表示一个句子? 这里我给出最为简单的方法,就是平均法,也叫作average pooling。
![[MAUI]实现动态拖拽排序网格](https://img-blog.csdnimg.cn/03ff870c203b4b96ac9d1cfadbb3ce41.gif)