目录
内核物理内存分配接口
内存分配行为(物理上)
内存分配的行为操作
内存 三个水位线
水线计算
水位线影响内存分配行为
内存分配核心__alloc_pages
释放页
1、内核物理内存分配接口
struct page *alloc_pages(gfp_t gfp, unsigned int order);用于向底层伙伴系统申请2的order次幂个物理内存页;gfp是分配行为的修饰符;该函数返回值时一个struct page类型的指针用于指向申请内存中第一个物理内存页。
申请
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)底层还是依赖了 alloc_pages 函数,只不过 order 指定为 0;
vmalloc 分配机制底层就是用的 alloc_page
以上返回的是物理页,而CPU直接访问的是虚拟页
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{struct page *page;// 不能在高端内存中分配物理页,因为无法直接映射获取虚拟内存地址page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);if (!page)return 0;// 将直接映射区中的物理内存页转换为虚拟内存地址return (unsigned long) page_address(page);
}page_address 函数用于将给定的物理内存页转换成虚拟地址,这里的地址是直接映射区 ;如果物理内存处于高端内存,不能直接转换,通过alloc_pages函数申请物理内存页,再调用kmap映射将page映射到内核虚拟地址空间。
分配单页的函数,依赖于 __get_free_pages 函数,参数 order 指定为 0
#define __get_free_page(gfp_mask) \__get_free_pages((gfp_mask), 0)申请内存并初始化为0
unsigned long get_zeroed_page(gfp_t gfp_mask)
{return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}从DMA 内存区域申请物理页
unsigned long __get_dma_pages(gfp_t gfp_mask, unsigned int order);释放
释放多页
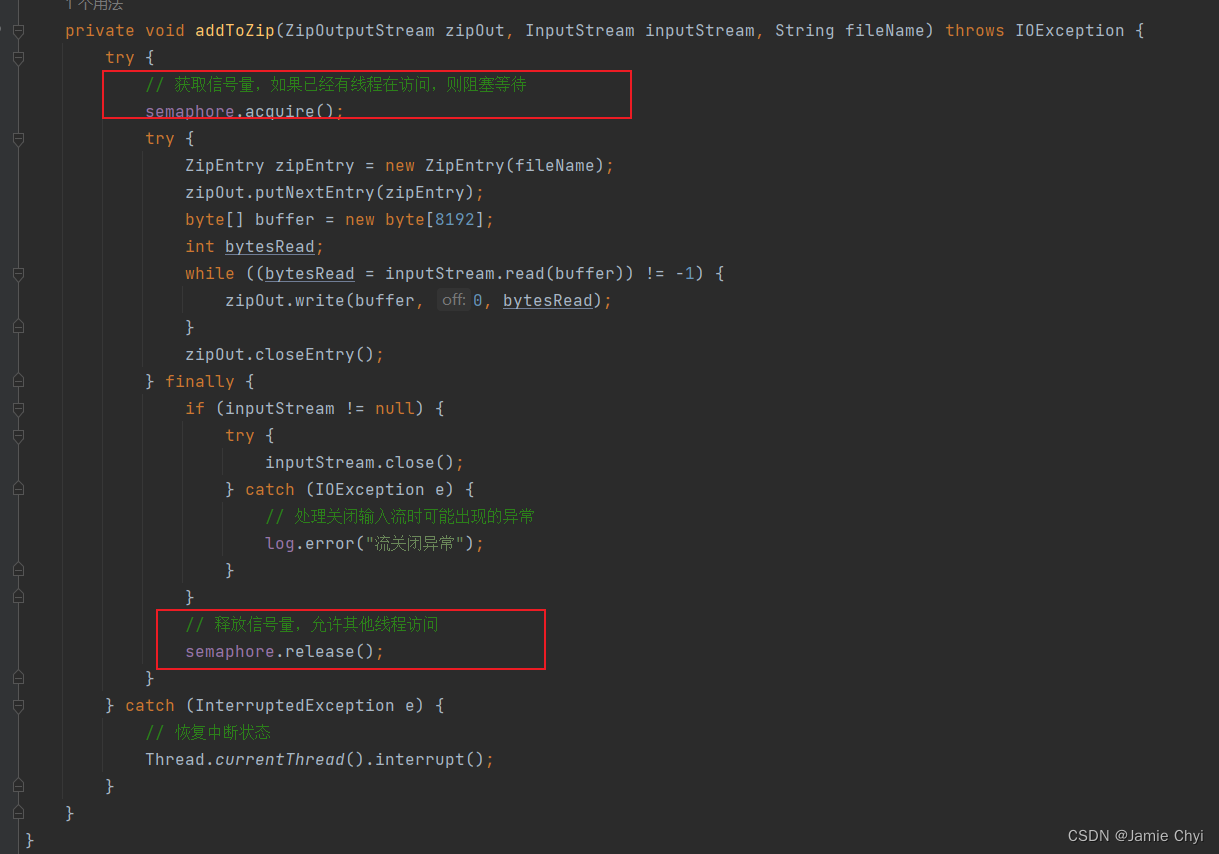
void __free_pages(struct page *page, unsigned int order);
void free_pages(unsigned long addr, unsigned int order);释放单页
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr), 0)2、内存分配行为(物理上)
从哪里分配gfp_mask (GFP 是 get free page )
根据物理内存功能不同,将 NUMA 节点内的物理内存划分为:ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM 这几个物理内存区域。
gfp_mask 中的低 4 位用来表示应该从哪个物理内存区域 zone 中获取内存页 page
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x08u物理内存的分配主要是落在 ZONE_NORMAL 区域中,如果我们不指定物理内存的分配区域,那么内核会默认从 ZONE_NORMAL 区域中分配内存;
ZONE_HIGHMEM -> ZONE_NORMAL -> ZONE_DMA 的顺序依次降级
如果 ZONE_NORMAL 区域中的空闲内存不够,内核则会降级到 ZONE_DMA 区域中分配。
gfp_zone
用于将我们在物理内存分配接口中指定的 gfp_mask 掩码转换为物理内存区域
static inline enum zone_type gfp_zone(gfp_t flags)
{enum zone_type z;int bit = (__force int) (flags & GFP_ZONEMASK);z = (GFP_ZONE_TABLE >> (bit * GFP_ZONES_SHIFT)) &((1 << GFP_ZONES_SHIFT) - 1);VM_BUG_ON((GFP_ZONE_BAD >> bit) & 1);return z;
}3、内存分配的行为操作
/include/linux/gfp.h
#define ___GFP_RECLAIMABLE 0x10u
#define ___GFP_HIGH 0x20u
#define ___GFP_IO 0x40u
#define ___GFP_FS 0x80u
#define ___GFP_ZERO 0x100u
#define ___GFP_ATOMIC 0x200u
#define ___GFP_DIRECT_RECLAIM 0x400u
#define ___GFP_KSWAPD_RECLAIM 0x800u
#define ___GFP_NOWARN 0x2000u
#define ___GFP_RETRY_MAYFAIL 0x4000u
#define ___GFP_NOFAIL 0x8000u
#define ___GFP_NORETRY 0x10000u
#define ___GFP_HARDWALL 0x100000u
#define ___GFP_THISNODE 0x200000u
#define ___GFP_MEMALLOC 0x20000u
#define ___GFP_NOMEMALLOC 0x80000u- __GFP_RECLAIMABLE 指定分配的页面是可以回收的
- __GFP_MOVABLE 分配的页面可以移动
- __GFP_HIGH 内存分配请求是高优先级,不允许失败
- __GFP_IO 在分配物理内存的时候,可以发起IO操作;
- __GFP_FS 允许内核执行底层文件系统操作
- __GFP_ZERO 内存初始化后,将初始化填充字节0
- __GFP_ATMOIC 分配时不允许睡眠,如中断程序中。不能被重新安全调度的上下文。
- __GFP_DIRECT_RECLAIM 内核分配时,可以进行内存回收
- __GFP_KSWAPD_RECLAIM 分配内存时,如果剩余内存容量在WMARK_MIN与WMARK_LOW之间,会唤醒kswapd进程开始异步回收,直到剩余内存高于WMARK_HIGH为止。
- __GFP_NOWARN 当内核分配失败时,抑制内核的分配失败错误警告。
- __GFP_RETRY_MAYFAIL 内核分配失败,运行重试,重试若干次后停止。
- __GFP_NORETRY 表示 内存分配失败,不允许重试
- __GFP_NOFAIL 分配失败时一直重试直到成功为止
- __GFP_HARDWALL 内存分配行为只能在当前分配到的CPU关联的NUMA节点上进行分配,当进程可以运行的CPU受限制时,才有意义。
- __GFP_THISNODE 只能在当前NUMA几点或者指定NUMA节点中分配
- __GFP_MEMALLOC 可以从所有内存区域获取内存,包括紧急预留内存,但是需要保证会很快释放
- __GFP_NOMEMALLOC禁止从紧急预留内存中获取内存;优先级高于__GFP_MEMALLOC
为了简化使用以上修饰符,内核提供以下组合,避免出错
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)GFP_ATOMIC,表示内存分配行为必须是原子的,是高优先级;不允许睡眠,如果内存不够则从紧急预留内存中分配。
GFP_KERNEL 常用,可能会阻塞;可以运行内核置换出一些不活跃的内存页到磁盘中。适用于可以安全调度的进程上下文中。
GFP_NOIO和GFP_NO_FS 禁止内核在分配内存时进行磁盘IO和文件IO操作
GFP_USER 用于映射到用户空间的内存分配,可以被内核或者硬件直接访问,如硬件设备会将Buffer直接映射到用户空间中。
GFP_DMA和GFP_DMA32表示 从DMA和DMA32中获取适用于DMA的内存页。
GFP_HIGHUSER用于给用户空间分配高端内存,因为在用户虚拟内存中,都是通过页表来访问非直接映射的高端内存。
4、内存 三个水位线
内存水位影响内存分配的行为
enum zone_watermarks {WMARK_MIN,WMARK_LOW,WMARK_HIGH,NR_WMARK
};struct zone {// 物理内存区域中的水位线unsigned long _watermark[NR_WMARK];
}物理剩余内存高于WMARK_HIGH时,内存非常充足
LOW<内存<HIGH 内存有一定的消耗,但不影响分配
MIN<内存<LOW 内存有压力,但是可以满足进程此时内存分配要求,分配后会唤醒kswap进程开始回收内存,直到剩余内存高于HIGH为止(异步完成)。
内存<MIN 时,内核直接进行回收,此时内存回收任务由请求进程同步完成。
最低水线以下的内存称为紧急预留内存;
进程设置标志PF_MEMALLOC可以使用仅仅预留内存;内存管理子系统以外不应该使用这个标志,典型的例子是页回收线程kswap,在页回收中可能要申请内存。
水线计算参数
1)min_free_kbytes 最小空闲字节数,
默认值是,并且限制在范围[128,65535]以内。
其中lowmem_kbytes是低端内存大小,单位是KB
可以通过文件/proc/sys/vm/min_free_kbytes设置最小空闲字节数
源码文件 mm/page_alloc.c 中函数 init_zone_wmark_min
2)watermark_scale_factor 水线缩放因子。默认值为10,
通过/proc/sys/vm/watermark_scale_factor修改水线缩放因子,范围[1,1000]
水线计算
mm/page_alloc.c中函数__setup_per_zone_wmarks
1、最低水线计算方法
1)min_free_pages = min_free_kbytes对应的页数
2)lowmem_pages =所有低端内存区域中伙伴分配器管理的页数总和;
3)高端内存区域的最低水线= zone->managed_pages/1024,并且限制范围[32,128]以内
zone->managed_pages是内存区域伙伴分配器管理的页数,在内核初始化过程中引导分配器分配出去的物理页。
4)低端内存区域水线= min_free_pages * zone->managed_pages/lowmem_pages 即把min_free_pages按比例分配到每个低端内存区域;
2、计算低水线和高水线方法
- 增量 = (最低水线/4,zone->managed_pages * watermark_scale_factor/1000)取最大值
- 最低水线 = 低水线 + 增量
- 最高水线 = 高水线 + 增量*2
5、水位线影响内存分配行为
#define ALLOC_WMARK_MIN WMARK_MIN
#define ALLOC_WMARK_LOW WMARK_LOW
#define ALLOC_WMARK_HIGH WMARK_HIGH
#define ALLOC_NO_WATERMARKS 0x04 /* don't check watermarks at all */#define ALLOC_HARDER 0x10 /* try to alloc harder */
#define ALLOC_HIGH 0x20 /* __GFP_HIGH set */
#define ALLOC_CPUSET 0x40 /* check for correct cpuset */#define ALLOC_KSWAPD 0x800 /* allow waking of kswapd, __GFP_KSWAPD_RECLAIM set */ALLOC_NO_WATERMARKS 表示不考虑三个水位线
ALLOC_WMARK_HIGH 表示内存必须达到HIGH要求
ALLOC_WMARK_LOW 表示内存必须达到LOW要求
ALLOC_WMARK_MIN 表示内存必须达到MIN要求
ALLOC_HARDER 表示内存分配,放宽内存分配规则的限制,其实就是降低MIN水位,使内存分配最大可能成功。
ALLOC_HIGH gfp_t掩码设置__GFP_HIGH时才有作用,表示当前内存分配请求是高优先级的,不允许失败,可以从紧急预留内存中分配。
ALLOC_CPUSET 只能在当前进程所允许的CPU所关联的NUMA节点进行分配。如:cgroup功能。
ALLOC_KSWAPD表示允许唤醒NUMA节点中的KSWAPD进程,异步内存回收,每个NUMA几点分配一个kswapd进程用于回收不经常使用的页面。
6、内存分配核心__alloc_pages
7、释放页
void __free_pages(struct page *page, unsigned int order)
{if (put_page_testzero(page))free_the_page(page, order);
}static inline void free_the_page(struct page *page, unsigned int order)
{if (order == 0) /* Via pcp? */free_unref_page(page);else__free_pages_ok(page, order);
}
先把引用计数减一,只有页的引用计数变成0,才真正释放页;
如果阶是0 不还给伙伴系统,而是作为冷热页添加到每处理器页集合中,如果页集合中页数量大于或等于高水线,那么批量返回给伙伴分配器;
如果阶大于0 调用__free_pages_ok释放页;
static void free_unref_page_commit(struct page *page, unsigned long pfn)
{struct zone *zone = page_zone(page);//获取zonestruct per_cpu_pages *pcp;//per-cpuint migratetype;migratetype = get_pcppage_migratetype(page);__count_vm_event(PGFREE);/** We only track unmovable, reclaimable and movable on pcp lists.* Free ISOLATE pages back to the allocator because they are being* offlined but treat HIGHATOMIC as movable pages so we can get those* areas back if necessary. Otherwise, we may have to free* excessively into the page allocator*///每处理器只存放,不可移动,可回收和可移动三种类型,超过这三种类型处理方法//1)如果是隔离类型的页,直接释放//2)其他类型的页添加到可移动链表中,page->index保存真实迁移类型。if (migratetype >= MIGRATE_PCPTYPES) {if (unlikely(is_migrate_isolate(migratetype))) {free_one_page(zone, page, pfn, 0, migratetype);return;}migratetype = MIGRATE_MOVABLE;}//添加到per-cpu中pcp = &this_cpu_ptr(zone->pageset)->pcp;list_add(&page->lru, &pcp->lists[migratetype]);pcp->count++;//数量++//如果count大于或等于高水线,批量还给伙伴分配器if (pcp->count >= pcp->high) {unsigned long batch = READ_ONCE(pcp->batch);free_pcppages_bulk(zone, batch, pcp);}
}
__free_pages_ok 最终调用__free_one_page
如果伙伴系统是空闲的,并且伙伴在同一个内存区域,那么和伙伴合并;
隔离块和其他类型的页块不能合并
假设最后合并的页阶数是order,如果order小于MAX_ORDER-2 则检查 order+1阶的伙伴是否有空闲,如果有空闲,那么order阶的伙伴可能正在释放,很快合并成order+2阶的块;
为了防止当前块很快被分配出去,把当前页块添加到空闲链表的尾部。
static void __free_pages_ok(struct page *page, unsigned int order)
{unsigned long flags;int migratetype;unsigned long pfn = page_to_pfn(page);if (!free_pages_prepare(page, order, true))return;migratetype = get_pfnblock_migratetype(page, pfn);local_irq_save(flags);__count_vm_events(PGFREE, 1 << order);free_one_page(page_zone(page), page, pfn, order, migratetype);local_irq_restore(flags);
}static void free_one_page(struct zone *zone,struct page *page, unsigned long pfn,unsigned int order,int migratetype)
{spin_lock(&zone->lock);if (unlikely(has_isolate_pageblock(zone) ||is_migrate_isolate(migratetype))) {migratetype = get_pfnblock_migratetype(page, pfn);}__free_one_page(page, pfn, zone, order, migratetype);spin_unlock(&zone->lock);
}static inline void __free_one_page(struct page *page,unsigned long pfn,struct zone *zone, unsigned int order,int migratetype)
{unsigned long combined_pfn;unsigned long uninitialized_var(buddy_pfn);struct page *buddy;unsigned int max_order;struct capture_control *capc = task_capc(zone);//可移动性分组的阶数max_order = min_t(unsigned int, MAX_ORDER, pageblock_order + 1);VM_BUG_ON(!zone_is_initialized(zone));VM_BUG_ON_PAGE(page->flags & PAGE_FLAGS_CHECK_AT_PREP, page);VM_BUG_ON(migratetype == -1);if (likely(!is_migrate_isolate(migratetype)))__mod_zone_freepage_state(zone, 1 << order, migratetype);VM_BUG_ON_PAGE(pfn & ((1 << order) - 1), page);VM_BUG_ON_PAGE(bad_range(zone, page), page);continue_merging://如果伙伴系统是空闲的,和伙伴合并,重复while (order < max_order - 1) {if (compaction_capture(capc, page, order, migratetype)) {__mod_zone_freepage_state(zone, -(1 << order),migratetype);return;}buddy_pfn = __find_buddy_pfn(pfn, order);//得到伙伴的起始物理页号buddy = page + (buddy_pfn - pfn);//得到伙伴的第一页的page实例if (!pfn_valid_within(buddy_pfn))goto done_merging;//查询伙伴是空闲并且在相同的区域内存if (!page_is_buddy(page, buddy, order))goto done_merging;/** Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,* merge with it and move up one order.*///开启了调试页分配器配置宏CONFIG_DEBUG_PAGEALLOC,伙伴充当警戒页if (page_is_guard(buddy))clear_page_guard(zone, buddy, order, migratetype);else//伙伴是空闲的并且在相同内存区del_page_from_free_area(buddy, &zone->free_area[order]);combined_pfn = buddy_pfn & pfn;page = page + (combined_pfn - pfn);pfn = combined_pfn;order++;}//阻止把隔离类型的页块和其他类型的页块合并if (max_order < MAX_ORDER) {/* If we are here, it means order is >= pageblock_order.* We want to prevent merge between freepages on isolate* pageblock and normal pageblock. Without this, pageblock* isolation could cause incorrect freepage or CMA accounting.** We don't want to hit this code for the more frequent* low-order merging.*/if (unlikely(has_isolate_pageblock(zone))) {int buddy_mt;buddy_pfn = __find_buddy_pfn(pfn, order);buddy = page + (buddy_pfn - pfn);buddy_mt = get_pageblock_migratetype(buddy);//如果是隔离类型的页块,另一个是其他类型不能合并if (migratetype != buddy_mt&& (is_migrate_isolate(migratetype) ||is_migrate_isolate(buddy_mt)))goto done_merging;}max_order++;//继续合并goto continue_merging;}done_merging:set_page_order(page, order);/** If this is not the largest possible page, check if the buddy* of the next-highest order is free. If it is, it's possible* that pages are being freed that will coalesce soon. In case,* that is happening, add the free page to the tail of the list* so it's less likely to be used soon and more likely to be merged* as a higher order page*/if ((order < MAX_ORDER-2) && pfn_valid_within(buddy_pfn)&& !is_shuffle_order(order)) {struct page *higher_page, *higher_buddy;combined_pfn = buddy_pfn & pfn;higher_page = page + (combined_pfn - pfn);buddy_pfn = __find_buddy_pfn(combined_pfn, order + 1);higher_buddy = higher_page + (buddy_pfn - combined_pfn);if (pfn_valid_within(buddy_pfn) &&page_is_buddy(higher_page, higher_buddy, order + 1)) {add_to_free_area_tail(page, &zone->free_area[order],migratetype);return;}}if (is_shuffle_order(order))add_to_free_area_random(page, &zone->free_area[order],migratetype);elseadd_to_free_area(page, &zone->free_area[order], migratetype);}