实现功能
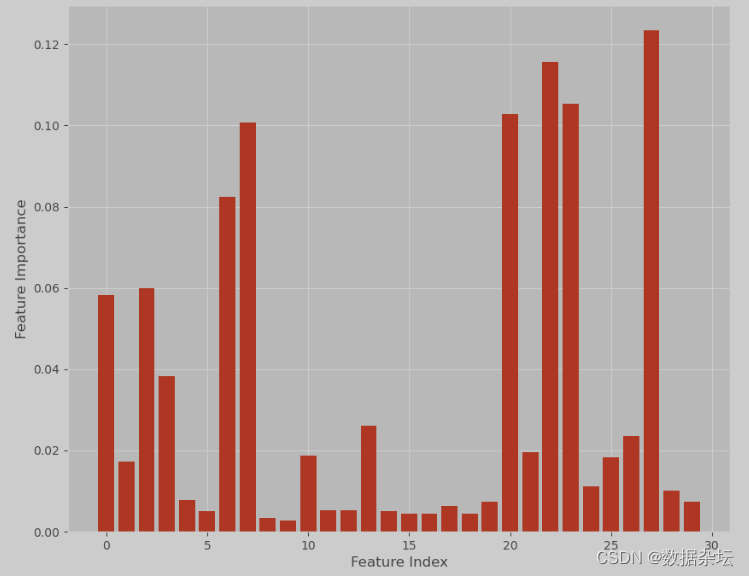
一些模型,如线性回归和随机森林,可以直接输出特征重要性分数。这些显示了每个特征对最终预测的贡献。
实现代码
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as pltX, y = load_breast_cancer(return_X_y=True)rf = RandomForestClassifier(n_estimators=100, random_state=1)
rf.fit(X, y)importances = rf.feature_importances_# Plot importances
plt.style.use('ggplot')
plt.figure(figsize=(10, 8))
plt.bar(range(X.shape[1]), importances)
plt.xlabel('Feature Index')
plt.ylabel('Feature Importance')
plt.show()实现效果
本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据挖掘相关科研工作,对数据挖掘有一定认知和理解,会结合自身科研实践经历不定期分享关于python机器学习、深度学习、数据挖掘基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
邀请三个朋友关注V订阅号:数据杂坛,即可在后台联系我获取相关数据集和源码,送有关数据分析、数据挖掘、机器学习、深度学习相关的电子书籍。