今天我们来学习Deeplearning.ai的在线课程 微调大型语言模型(一)的第一课:为什么要微调(Why finetune)。
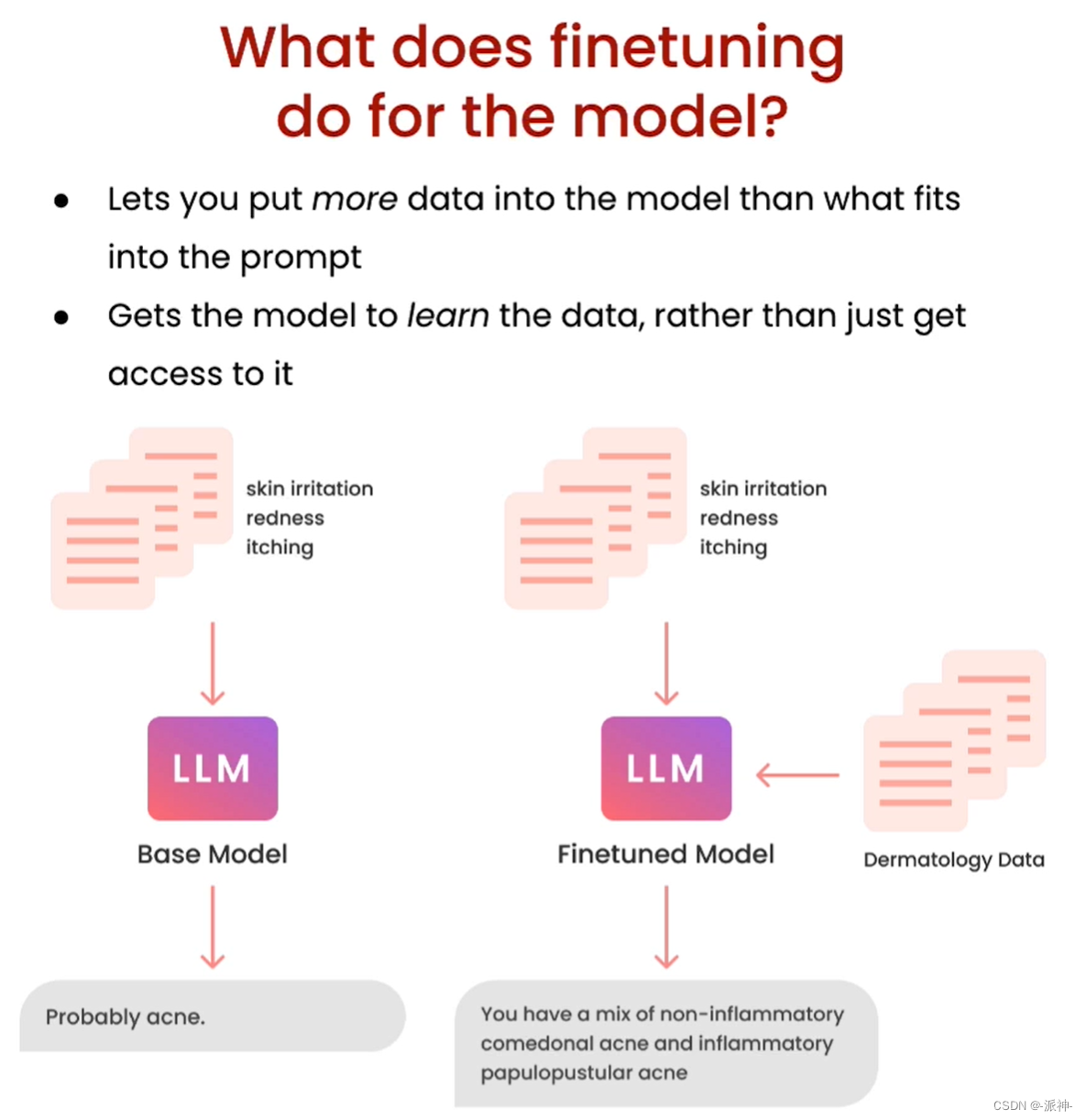
我们知道像GPT-3.5这样的大型语言模型(LLM)它所学到的知识截止到2021年9月,那么如果我们向ChatGPT询问2022年以后发生的事情,它可能会产生“幻觉”从而给出错误的答案,再比如我们有一些关于企业的某些产品的业务数据,但是由于ChatGPT没有学习过这些数据,因此它也无法正确回答出关于这些产品的问题。为了扩大LLM的知识面,让LLM能够更好的学习并掌握新知识从而更好的为用户服务,因此我们需要对LLM进行微调(Finetuning)。
由于常见的开源LLM都有较大的体积,在微调LLM时它对机器的配置有较高的要求,通常要求机器有较大的内存和GPU显存,比如64 GB内存,32G GPU 显存等。因此一般的家用PC很难满足要求,所以我们一般会通过第三方的托管平台的API来实现对开源LLM进行访问和微调,由于本课程使用的是 lamini.ai 平台的API来实现对开源大模型Llama-2-7b模型的访问和微调,因此我们需要去lamini.ai 注册一个账号(可以通过gmail账号直接登录),然后获取免费赠送的Credits(用完后可购买)和 API Key
API Key 设置
我们首先需要在代码中设置 production.key,该key就是我们在注册账号时获取到的Activate API Tokens:
# pip install lamini
from llama import LLMEnginellm = LLMEngine(id="example_llm",config={"production.key": "xxxxxxxxx"})比较微调与非微调模型
为了让大家更好的理解微调模型和非微调模型的差异,我们需要对两者产生的结果进行比较,也就是我们需要对两种模型提出相同的问题,然后比较它们各自产生的结果。
测试非微调模型
首先我们会对非微调模型Llama-2-7b-hf进行测试,我们会问它几个问题,然后观察它的回答,这里我们对Llama-2-7b-hf 提出这样一个问题:“告诉我如何训练我的狗学会坐下”,由于Llama-2模型目前并不支持中文,所以我们需要使用英语来进行提问:
from llama import BasicModelRunner#加载非微调模型
non_finetuned = BasicModelRunner("meta-llama/Llama-2-7b-hf")#问题:告诉我如何训练我的狗学会坐下
non_finetuned_output = non_finetuned("Tell me how to train my dog to sit")print(non_finetuned_output)
从上面的结果中我们看到Llama-2-7b-hf并没有正确回答问题,它似乎是根据用户的问题,然后用用户的口气又编造了很多重复的问题,这样的回复看上去完全是文不对题,完全不符合要求。下面我们把llm的回复翻译成中文,这样便于大家更好的理解:

#问题:你觉得火星怎么样?
print(non_finetuned("What do you think of Mars?"))
#问题:Twitter的老板是谁?
print(non_finetuned("Who is the boss of Twitter?"))
下面我们来模拟一个代理和客户之间的问题流程,首先代理问候客户->客户提问->代理回答->客户提问->(需要llm回答)
print(non_finetuned("""Agent: I'm here to help you with your Amazon deliver order.
Customer: I didn't get my item
Agent: I'm sorry to hear that. Which item was it?
Customer: the blanket
Agent:"""))
这里我们可以直观的感觉到Llama-2-7b-hf模型在回答用户问题时,往往会不停的重复用户的问题或者重复自己的回复,因此这样的模型完全不能正常的使用(感觉像患上了精神病)。
与微调模型进行比较
下面我们使用微调模型 Llama-2-7b-chat-hf 看看它如何来回答先前那些问题:
#加载微调模型Llama-2-7b-chat-hf
finetuned_model = BasicModelRunner("meta-llama/Llama-2-7b-chat-hf")#问题:告诉我如何训练我的狗学会坐下
finetuned_output = finetuned_model("Tell me how to train my dog to sit")print(finetuned_output)
从上面的结果看,微调模型Llama-2-7b-chat-hf似乎给出了非常正确合理的答案,我们将这个回答翻译成中文,这样方便大家更好的理解:

结果虽然符合我们的要求,但是美中不足的时在返回的结果中在文本的开头位置出现了和问题无关的内容,比如在答案的开头出现了“on command.” 这样的语句,为此我们可以在向LLM提出问题的时候,在问题的头尾两端的位置插入指令提示符合“[INST]”和“[/INST]”,这样就可以避免LLM返回的结果中出现和问题无关的内容:
print(finetuned_model("[INST]Tell me how to train my dog to sit[/INST]"))
从上面的结果中我们看到llm已经过滤掉了和问题无关的内容比如:“on command.”, 但是我们也发现Llama-2-7b-chat-hf回答的结果似乎并不完整,因为第7点的内容并没有出现,这可能是因为llm的tokens数量限制所导致的,这有待后续进一步验证。
下面我们给非微调模型Llama-2-7b-hf加上指令提示符看看会怎么样:
print(non_finetuned("[INST]Tell me how to train my dog to sit[/INST]"))
我们看到非微调模型Llama-2-7b-hf并不能识别指令提示符,它将指令提示符当成了问题组成部分,仍然在不停的重复着用户的问题。
接下来我们继续让微调模型Llama-2-7b-chat-hf回答之前剩下的问题:
#问题:你觉得火星怎么样?
print(finetuned_model("What do you think of Mars?"))
这里我们发现llm的回答又出现了内容不完整的情况,这可能是因为token数量超出限制,所以内容被截断了。
#问题:Twitter的老板是谁?
print(finetuned_model("Who is the boss of Twitter?"))
从上面的结果来看,似乎LLM并不知道 伊隆·马斯克 已经收购了Twitter,而成为了Twitter的新老板,看来它的知识储备量仍然有限,下面我们加上指令提示符看看结果会怎么样:
#问题:Twitter的老板是谁?
print(finetuned_model("[INST]Who is the boss of Twitter?[/INST]"))
从上面的结果我们看到虽然LLM仍然不知道伊隆·马斯克是Twitter的新老板,但是LLM的回答比之前没有加指令提示符的结果更加合理,逻辑更加清晰,内容更加丰富。
接下来我们继续后续的问题:
print(finetuned_model("""Agent: I'm here to help you with your Amazon deliver order.
Customer: I didn't get my item
Agent: I'm sorry to hear that. Which item was it?
Customer: the blanket
Agent:"""))
从上面的结果中我们看到,LLM仍然模拟了多轮的agent-customer之间的对话,从内容上看感觉非常的真实,并且在最后LLM做了总结还评价了agent的表现(感觉是即当球员又当裁判)。
与ChatGPT的比较
接下来我们让ChatGPT来回答之前的第一个关于训练狗的问题,我们来看看ChatGPT的回答与微调模型Llama-2-7b-chat-hf的回答有什么不同:
chatgpt = BasicModelRunner("chat-gpt")#问题:告诉我如何训练我的狗学会坐下
print(chatgpt("Tell me how to train my dog to sit")) x
x
下面我们将ChatGPT的回答也翻译成中文,这样便于大家更好的理解:

我们将与之前使用指令提示符的微调模型的结果做一下比对,下面是微调模型Llama-2-7b-chat-hf的结果:

我们发现微调模型Llama-2-7b-chat-hf的结果与ChatGPT3.5模型的结果从质量上来说已经非常的接近了,这似乎说明Llama-2-7b-chat-hf在某些应用场景下存在可以替代ChatGPT3.5的可能性。
总结
今天我们学习了如何使用lamini.ai的API接口来分析开源大模型Llama-2的原始版本和微调版本之间的差异,我们分别加载了原始模型和微调模型,对于相同的问题原始模型表现非常的糟糕,微调模型的表现相对较好,当我们使用指令提示符后微调模型表现的更加优秀,同时我们也发现了微调模型的输出结果不完整的情况, 这可能是由于token数量限制被截断造成的,这有待后续进一步验证,最后我们还比较了ChatGPT和Llama-2微调模型的结果,我们发现Llama-2微调模型的结果的质量非常接近ChatGPT,因此可以认为Llama-2是目前开源LLM中较为优秀的模型。
参考资料
https://lamini-ai.github.io/
DLAI - Learning Platform Beta