在ultraEdit中,我想选取<channel到</channel>之间的多行(进行删除)。在perl模式下,命令为“<channel[\s\S]+?</channel>”。下面是xml文件:
<!--This XML file does not appear to have any style information associated with it. The document tree is shown below.-->
<tv generator-info-name="http://epg.51zmt.top:8000" generator-info-url="QQ 31849627">
<channel id="1">
<display-name lang="zh">CCTV1</display-name>
</channel>
<channel id="2">
<display-name lang="zh">CCTV2</display-name>
</channel>
<programme start="20230917213000 +0800" stop="20230917220000 +0800" channel="591">
<title lang="zh">东方飞鹰</title>
</programme>
<programme start="20230917220000 +0800" stop="20230917230000 +0800" channel="591">
<title lang="zh">香港往事</title>
</programme>
</tv>
步骤1:ctrl+R,调出查找页面,输入查找字符“<channel[\s\S]+?</channel>”
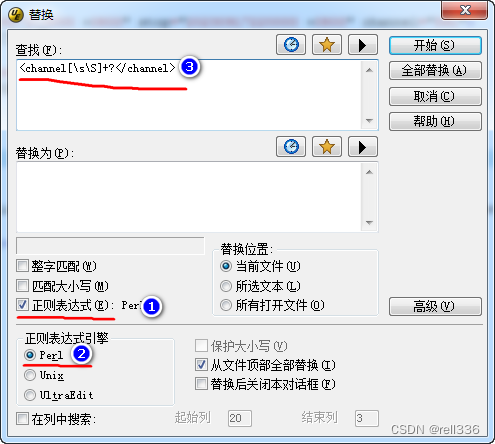
我们将查找到第1个结果,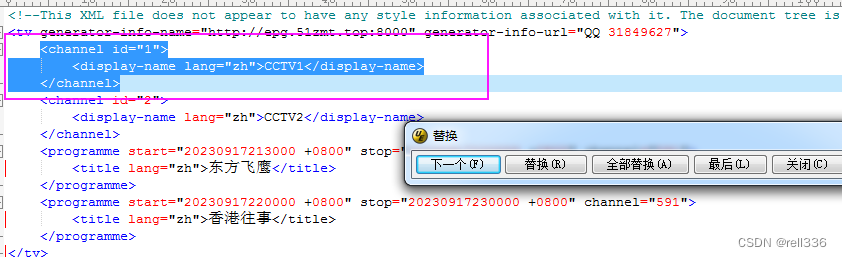
步骤2:
既然我们查找到了正确结果,我们可以选择“全部替换”来删除这些所有内容。
同理,我们用该命令也能查找1行内的内容,比如“<desc\s\S]+?</desc>”,但是结果可能会出错,因为有<desc lang="zh"/>的时候,会匹配多行到</desc>结尾处。
二、删除多行注释
/\*[\s\S]+?\*/ 删除所有/* */,文件内容:
/*/bb0227e
123
//123
*/
<div class=\
则会匹配到

备注:
\s 空白 [ \r\t\n\f]
\S 非空白 [^ \r\t\n\f]
三、在一行内查找
还是用ultraEdit模式,正则“<desc*?</desc>”