星光下的赶路人star的个人主页
注意力的集中,意象的孤立绝缘,便是美感的态度的最大特点
文章目录
- 1、DataStream API
- 1.1 执行环境(Execution Environment)
- 1.1.1 创建执行环境
- 1.2 执行模式(Execution Mode)
- 1.3 触发程序执行
- 2、源算子(Source)
- 2.1 准备工作
- 2.2 从集合中读取数据
- 2.3 从文件中读取数据
- 2.4 从Soceket读取数据
- 2.5 从kafka读取数据
- 2.6 从数据生成器读取数据
- 2.7 Flink支持的数据类型
- 3、转换算子(Transformation)
- 3.1 基本转换算子(map/filter/flatMap)
- 3.1.1 映射(map)
- 3.1.2 过滤(filter)
- 3.1.3 扁平映射(flatMap)
1、DataStream API
DataStream API是Flink核心层API。一个Flink程序,其实就是对DataStream的各种转换。具体来说,代码基本上都由以下几部分构成:
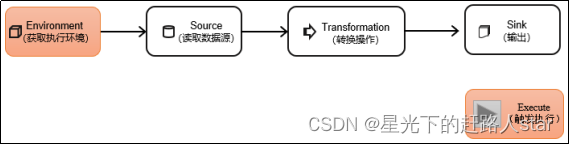
1.1 执行环境(Execution Environment)
Flink程序可以在各种上下文环境中运行;我们可以在本地JVM中执行程序,也可以提交到远程集群上运行。
不同的环境,代码提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前Flink的运行环境,从而建立起与Flink框架之间的联系。
1.1.1 创建执行环境
我们要获取的执行环境,是StreamExecutionEnviroment类的对象,这是所有Flink程序的基础。在代码中成绩执行环境的方式,就是调用这个类的静态方法,具体有一下三种。
1、getExecutionEnviroment
最简单的方式,就是直接调用getExecutionEnvironment方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
这种方式,用起来简单高效,是最常用的一种创建执行环境的方式。
2、createLocalEnviroment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则没人并行度就是本地的CPU核心数。
StreamExecutionEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment();
3、createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定JobManager的主机名和端口号,并指定要在集群中运行的Jar包。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment.createRemoteEnvironment("host", // JobManager主机名1234, // JobManager进程端口号"path/to/jarFile.jar" // 提交给JobManager的JAR包);
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。
1.2 执行模式(Execution Mode)
从Flink1.12开始,官方推荐的做法是直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理。不建议使用DataSet API。
// 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream API执行模式包括:流执行模式、批执行模式和自动模式
- 流执行模式(Streaming)
这是DataStream API最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是Streaming执行模式。 - 批执行模式(Batch)
专门用于批处理的执行模式 - 自动模式(AutoMatic)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
批执行模式的使用。主要有两种方式:
(1)通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...
(2)通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.BATCH);
1.3 触发程序执行
需要注意的是,写完输出(Sink)操作并不代表程序已经结束。因为当main()方法被调用时,其实只是定义了作业的每个执行操作,如何添加到数据流图中;这时候并没有真正处理数据–因为数据可能还没有来。Flink是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也呗称为“延迟执行”或“懒执行”。
所以我们需要显示地调用执行环境的execute()方法来触发程序的执行。execute()方法讲一直等待作业完成,如何返回一个执行结果(JobExecutionResult)。
env.execute();
2、源算子(Source)
Fink可以从各种来源获取数据,如何构建DataStream进行转换处理。一般将数据地输入来源称为数据源(data source),而读取数据的算子就是源算子。所以,source就是我们整个处理程序的输入端。

在Flink1.12以前,旧的添加source的方法是调用执行环境的addSource()方法:
DataStream<String> stream = env.addSource(...);
方法传入的参数是一个“源函数”(source function),需要实现SourceFunction接口、
从Flink1.12开始,主要使用流批一体的新Source架构:
DataStreamSource<String> stream = env.fromSource(…)
Flink直接提供了很多预实现的接口,此外还有很多外部连接工具也帮我们实现了对应的Source,通常情况下足以应对我们的实际需求。
2.1 准备工作
为了方便练习,这里使用WaterSensor作为数据模型。
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| id | String | 水位传感器类型 |
| ts | Long | 传感器记录时间戳 |
| vc | Integer | 水位记录 |
具体代码如下:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class WaterSensor {private String id;private Long ts;private Integer vc;
}
这里需要注意的点:
- 类是公共的
- 所有属性都是公有的
- 所有属性的类型都是可以序列化的
Flink会把这样的类作为一种特殊的POJO(Plain Ordinary Java Object简单的Java对象,实际就是普通JavaBeans)数据类型来对待,方便数据的解析和序列化。另外我们在类中还重写了toString()方法,主要是为了测试显示更清晰。
我们这里自定义的POJO类会在后面的代码中频繁使用,所以在后面的代码中碰到,把这里的POJO类导入就好了。
2.2 从集合中读取数据
最简单的读取数据的方式,就是在代码中直接创建一个Java集合,然后调用执行环境的fromCollection方法进行读取。这相当于将数据临时存储到内存中,形成特殊的数据结构后,作为数据源使用,一般用于测试。
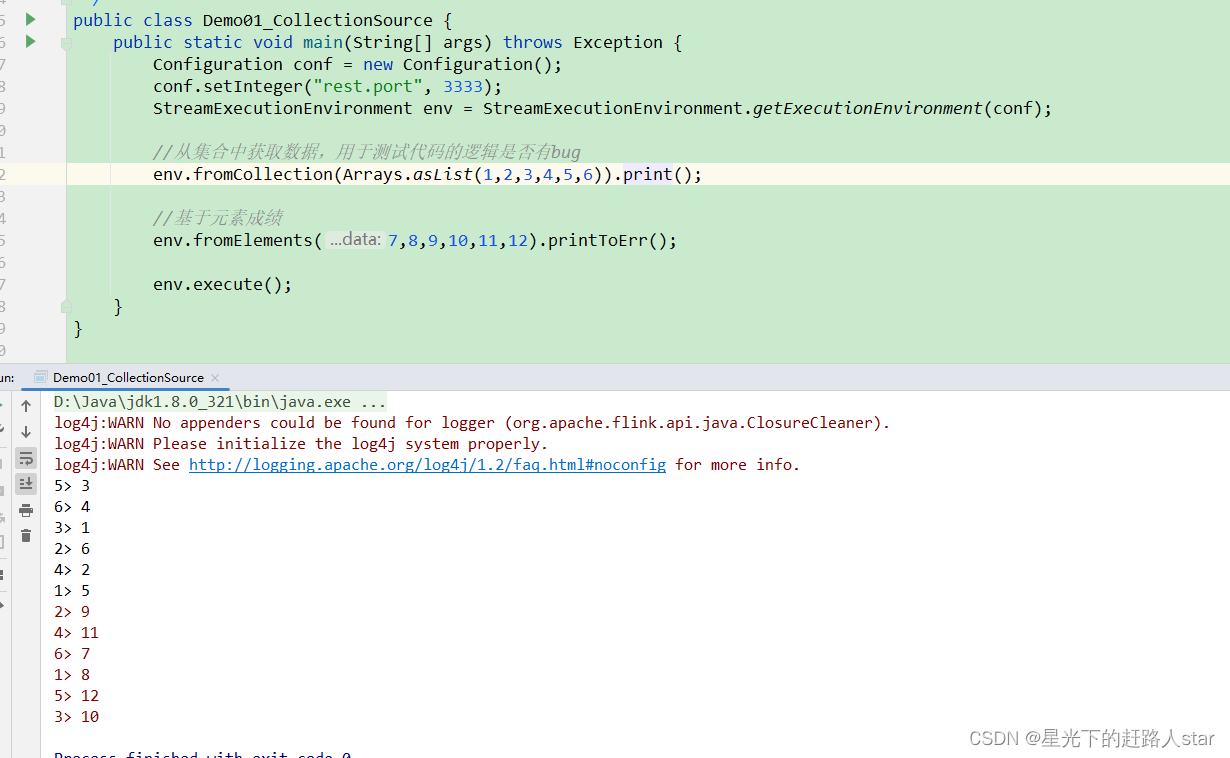
public class Demo01_CollectionSource {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.setInteger("rest.port", 3333);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);//从集合中获取数据,用于测试代码的逻辑是否有bugenv.fromCollection(Arrays.asList(1,2,3,4,5,6)).print();//基于元素成绩env.fromElements(7,8,9,10,11,12).printToErr();env.execute();}
}
运行结果:
2.3 从文件中读取数据
真正的实际应用中,自然不会直接将数据写在代码中。通常情况下,我们会从存储介质中获取数据,一个比较常见的方式就是读取日志文件。这也是批处理中最常见的读取方式。
读取文件,需要添加文件连接器依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version>
</dependency>
实操代码
public class Demo02_FileSource {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);/*** 引入file-connector** forRecordStreamFormat(* final StreamFormat<T> streamFormat,hadoop中的输入格式。代表输入的每一行数据的格式。* 压缩的文本,也能识别(部分)* final Path...paths:读取的文件的路径,可以是单个文件,也可以是一个目录,可以是本地磁盘的目录,也可以是hdfs上的文件* 如果读取hdfs上的文件,需要引入hadoop-client的依赖* )*///获取数据源FileSource<String> source = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("data/ws.json")).build();//使用就算环境,调用source算子去读数据DataStreamSource<String> streamSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "myfile");//简单打印streamSource.print();//执行env.execute();}
}运行结果

说明:
- 参数可以是目录,也可以是文件;还可以从HDFS目录下读取,使用路径hdfs://…;
- 路径可以是相对路径,也可以是绝对路径
- 相对路径是从系统属性user.dir获取路径;idea下是project的根目录,standalone模式下是集群节点根目录。
2.4 从Soceket读取数据
不论从集合还是文件,我们读取的其实都是有界数据。在流处理的场景中,数据往往是无界的。
我们之前用到的读取socket文本流,就是流处理场景。但是这种方式由于吞吐量小、稳定性较差,一般也是用于测试。
DataStream<String> stream = env.socketTextStream("hadoop102", 9999);
2.5 从kafka读取数据
Flink官方提供了连接工具flink-connector-kafka,直接帮我们实现了一个消费者FlinkKafkaConsumer,它就是用来读取Kafka数据的SourceFunction。
所以想要以Kafka作为数据源获取数据,我们只需要引入Kafka连接器的依赖。Flink官方提供的是一个通用的Kafka连接器,它会自动跟踪最新版本的Kafka客户端。目前最新版本只支持0.10.0版本以上的Kafka。这里我们需要导入的依赖如下。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version>
</dependency>
public class Demo03_KafkaSource {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);/*** 构造一个Source* kafkaSource.<OUT>builder()* OUT指kafka中读取的数据的value类型*/KafkaSource<String> kafkaSource = KafkaSource.<String>builder()//声明kafka集群地址.setBootstrapServers("hadoop102:9092")//声明读取的主题.setTopics("FlinkTest")/**设置消费者组 Source算子可以有多个并行度,每个并行度都会被创建为一个Task,每个Task都是一个消费者组,但是多个消费者组属于同一个组* 一个Source的Task可以消费一个主题的N个分区*/.setGroupId("flink")/*** 设置消费者的消费策略* 从头消费:earliest* 从尾消费:latest*///没有设置策略的话是从头消费// flink程序在启动的时候,从之前备份的状态中读取offsets,从offsets位置继续往后消费!//如果没有备份,此时参考消费策略//从头消费// .setStartingOffsets(OffsetsInitializer.earliest())//从kafka读取当前组上次提交的offset位置,如果这个组没有提交过,再从头消费
// .setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))/*** 如果你消费的数据,是没有key的,只需要设置value的反序列化器:setValueOnlyDeserializer* 如果你消费的数据,有key,需要设置key-value的反序列化器:setDeserializer*/.setValueOnlyDeserializer(new SimpleStringSchema())//设置是否自动提交消费的offset.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true")//设置自动提交的时间间隔.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000").build();env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),"kafka").print();env.execute();}
}
2.6 从数据生成器读取数据
Flink从1.11开始提供了一个内置的DataGen 连接器,主要是用于生成一些随机数,用于在没有数据源的时候,进行流任务的测试以及性能测试等。1.17提供了新的Source写法,需要导入依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-datagen</artifactId><version>${flink.version}</version></dependency>
public class Demo04_DataGenSource {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);String[] ids={"s1","s2","s3"};/*** 模拟源源不断的WaterSensor** DataGeneratorSource(* GeneratorFunction<Long,OUT> generationFunction,函数帮你模拟想要的数据OUT,你要模拟的数据类型* Long count,一共要模拟多少条数据* RateLimiterStrategy rateLimiterStrategy,速率限制* TypeInformation<OUT> typeInfo 补充OUT的类型信息* )*///模拟数据DataGeneratorSource<WaterSensor> source = new DataGeneratorSource<WaterSensor>(new GeneratorFunction<Long,WaterSensor>(){@Overridepublic WaterSensor map(Long aLong) throws Exception {return new WaterSensor(ids[RandomUtils.nextInt(0,ids.length)],System.currentTimeMillis(),RandomUtils.nextInt(100,30000));}},Long.MAX_VALUE,RateLimiterStrategy.perSecond(5d),TypeInformation.of(WaterSensor.class));//使用计算环境,调用fromSource算子去读数据DataStreamSource<WaterSensor> sensorDataStreamSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "dg");//打印sensorDataStreamSource.print();//执行env.execute();}
}
2.7 Flink支持的数据类型
1、Flink的类型系统
Flink使用”类型信息“(TypeInformation)来统一表示数据类型。TypeInformation类是Flink中所以类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
2、Flink支持的数据类型
对于常见的Java和Scala数据类型,Flink都是支持的。Flink在内部,Flink对支持不同的类型进行了划分,这些类型可以在Types工具类中找到:
(1)基本类型
所有Java基本类型及其包装类,再加上Void、String、Date、BigDecimal和BigInteger。
(2)数组类型
包括基本类型数组(Primitive_Array)和对象数组(Object_Array).
(3)复合数据类型
- java元组类型(Tuple):这是Flink内置的元组类型,是Java API的一部分。最多25个字段,也就是从Tuple0~Tuple25,不支持空字段。
- Scala样例类及Scala元组;不支持空字段。
- 行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段。
- POJO:Flink自定义的类似于Java Bean模式的类。
(4)辅助类型
Option、Either、List、Map等
(5)泛型类型(Generic)
Flink支持所有的Java类和Scala类。不过如果没有按照上面POJO类型的要求来定义,就会被Flink当作泛型类来处理。Flink会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由Flink本身序列化的,而是由Kryo序列化的。
在这些类型中,元组类型和POJO类型最为灵活,因为它们支持创建复杂类型。而相比之下,POJO还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为Flink的POJO类型。
Flink对POJO类型的要求如下:
- 类是公有(public)的
- 有一个无参的构造方法
- 所有属性都是公有(public)的
- 所有属性的类型都是可以序列化的
3、类型提示(Type Hints)
Flink还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于java中泛型擦除的存在,在某些特殊情况下(比如Lambda表达式中),自动提前的信息是不够精细的–只告诉Flink当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
为了解决这类问题,Java API提供了专门的“类型同时”(type hints)
回忆一下之前的word count流处理程序,我们在将String类型的每个词转换成(word,count)二元组后,就明确地用returns指定了返回的类型。因为对于map里传入了Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple<String,Long>。只有显示地告诉系统当前的返回类型,才能正确地解析出完整数据。
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
Flink还专门提供了TypeHint类,它可以捕获泛型的类型信息,并且一直记录下来,为运行时通过足够的信息。我们同样可以通过returns()方法,明确地指定转换之后的DataStream里元素的类型。
returns(new TypeHint<Tuple2<Integer, SomeType>>(){})
3、转换算子(Transformation)
数据源读入数据之后,我们就可以使用各种转换算子,将一个或多个DataStream转换为新的DataStream。

3.1 基本转换算子(map/filter/flatMap)
3.1.1 映射(map)
map是大家非常熟悉的大数据操作算子,主要用于将数据流中的数据进行转换,形成新的数据流。简单来说,就是一个“一一映射”,消费一个元素就产出一个元素。

我们只需要基于DataStream调用map()方法就可以进行转换处理。方法需要传入的参数是接口MapFunction的实现;返回值类型还是DataStream,不过泛型(流中的元素类型)可能改变。
下面是模拟读取数据库数据
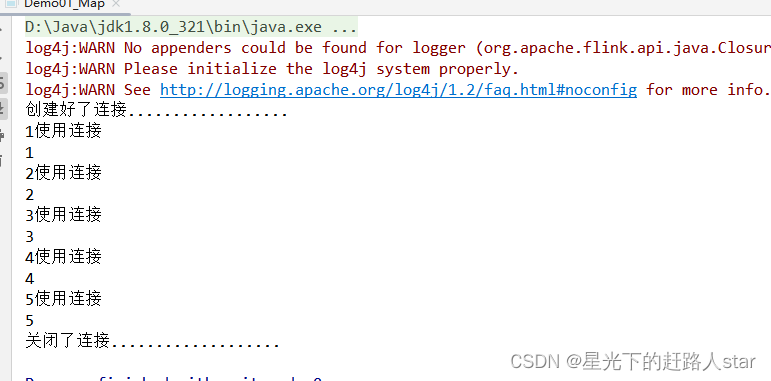
public class Demo01_Map {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);//设置并行度是1env.setParallelism(1);List<Integer> nums = Arrays.asList(1, 2, 3, 4, 5);env.fromCollection(nums).map(new MyMapFunction()).print();env.execute();}private static class MyMapFunction extends RichMapFunction<Integer, String> {private String conn;@Overridepublic String map(Integer integer) throws Exception {//使用连接,读取数据库System.out.println(integer + "使用" + conn);return integer.toString();}/*** RichFunction* 在Task被创建的时候,执行一次* @param parameters* @throws Exception*/@Overridepublic void open(Configuration parameters) throws Exception {//模拟创建连接conn="连接";System.out.println("创建好了连接..................");}/*** RichFunction* 在Task关闭的时候,执行一次* @throws Exception*/@Overridepublic void close() throws Exception {//关闭连接System.out.println("关闭了连接...................");}}
}运行截图
上面代码中,MapFuntion实现类的泛型类型与输入数据类型和输出数据的类型有关。在实现MapFunction接口的时候,需要指定两个泛型,分别是输入事件和输出事件的类型,还需要重写一个map()方法,定义从一个输入事件转换为另一个输出事件的具体逻辑。
3.1.2 过滤(filter)
filter转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为true则元素正常输出,若为false则元素被过滤掉。

进行filter转换之后的新数据流的数据类型与原数据流是相同的。filter转换需要传入的参数需要实现FilterFunction接口,而FilterFunction内要实现filter()方法,就相当于一个返回布尔类型的条件表达式。
输出偶数:
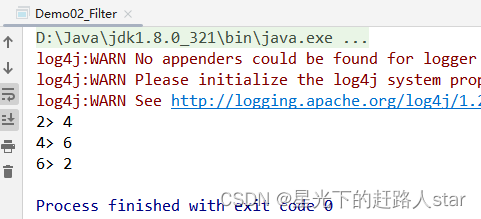
public class Demo02_Filter {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);List<Integer> nums = Arrays.asList(1, 2, 3, 4, 5, 6);env.fromCollection(nums).filter(integer -> integer%2==0).print();env.execute();}
}
运行截图:
3.1.3 扁平映射(flatMap)
flatMap操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生0到多个元素。flatMap可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。

同map一样,flatMap也可以使用Lambda表达式或者FlatMapFunction接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。
输出偶数,并且输出多次
public class Demo03_FlatMap {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);List<Integer> nums = Arrays.asList(1, 2, 3, 4, 5, 6);//炸裂(留下偶数)env.fromCollection(nums).flatMap(new FlatMapFunction<Integer, Integer>() {@Overridepublic void flatMap(Integer integer, Collector<Integer> collector) throws Exception {if (integer%2==0){collector.collect(integer);collector.collect(integer);collector.collect(integer);collector.collect(integer);}}}).print();env.execute();}
}运行截图:

![]()
您的支持是我创作的无限动力
![]()
希望我能为您的未来尽绵薄之力
![]()
如有错误,谢谢指正;若有收获,谢谢赞美



![[Linux入门]---Linux项目自动化构建工具-make/Makefile](https://img-blog.csdnimg.cn/ae23cf9f3207488a9ac8ad363149c9f3.png)