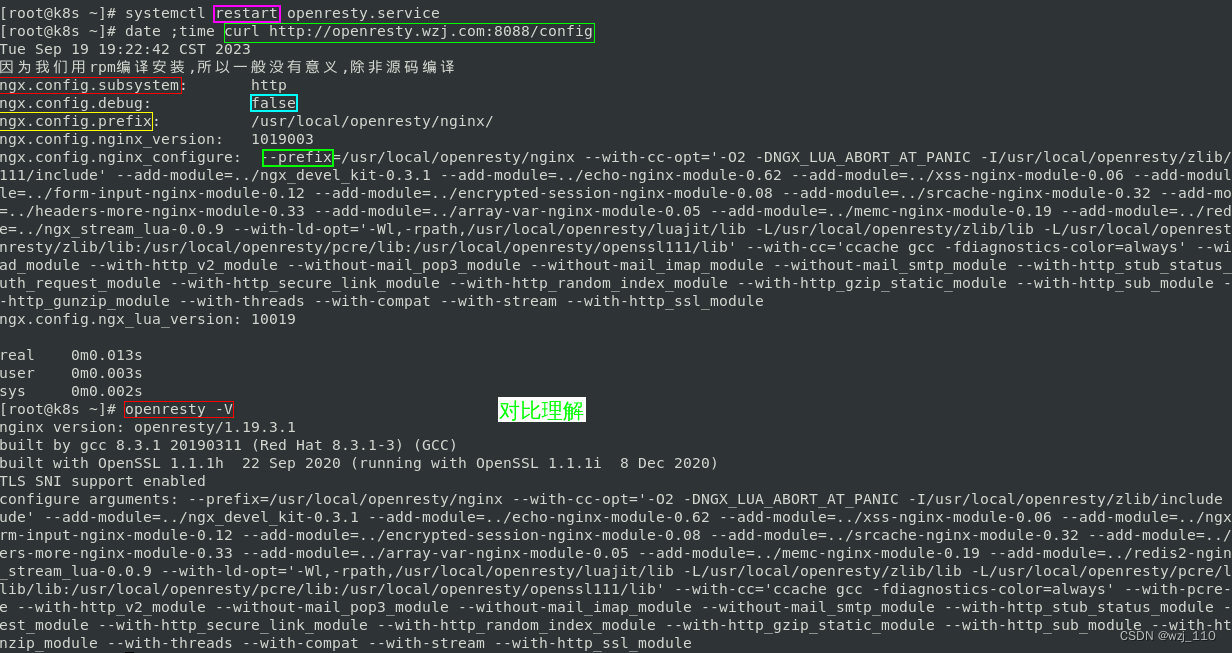
要求,查询一个文件中的pdf文件中的关键字,输出关键字所在PDF文件的文件名及对应的页数。
import os
import PyPDF2def search_pdf_files(folder_path, keywords):# 初始化结果字典,以关键字为键,值为包含关键字的页面和文件名列表results = {keyword: [] for keyword in keywords}# 遍历指定文件夹下的所有文件for root, dirs, files in os.walk(folder_path):for filename in files:if filename.endswith(".pdf"):# 构建PDF文件的完整路径pdf_path = os.path.join(root, filename)# 打开PDF文件with open(pdf_path, "rb") as pdf_file:pdf_reader = PyPDF2.PdfReader(pdf_file)# 获取PDF的总页数total_pages = len(pdf_reader.pages)# 遍历PDF的每一页for page_num in range(total_pages):# 读取页面内容page = pdf_reader.pages[page_num]page_text = page.extract_text()# 检查所有关键字for keyword in keywords:if keyword in page_text:results[keyword].append({"file_name": filename,"page_number": page_num + 1 # PDF页码从1开始})return results# 示例用法
folder_to_search = r"C:\Users\Administrator\Desktop\2"
search_keywords = ["SVD", "线性回归", "XGBoost", "不存在的关键字"] # 添加多个关键字,包括不存在的关键字
results = search_pdf_files(folder_to_search, search_keywords)# 打印结果
for keyword, keyword_results in results.items():if keyword_results:print(f"关键字 '{keyword}' 所在的文件及页数:")for result in keyword_results:print(f"文件 '{result['file_name']}' 的第 {result['page_number']} 页")else:print(f"没有找到关键字 '{keyword}'。")print() # 输出换行以区分不同关键字的结果

为了方便且高效看论文。
用了上面那个之后发现不太对劲,找到文件后,就可以ctrl+F了,所以去掉了页数。代码如下:
import os
import PyPDF2def search_pdf_files(folder_path, keywords):# Initialize a results dictionary with keywords as keys and lists of files as valuesresults = {keyword: [] for keyword in keywords}# Initialize a set to keep track of processed files for each keywordprocessed_files = {keyword: set() for keyword in keywords}# Traverse all files in the specified folderfor root, dirs, files in os.walk(folder_path):for filename in files:if filename.endswith(".pdf"):# Build the full path of the PDF filepdf_path = os.path.join(root, filename)# Open the PDF filewith open(pdf_path, "rb") as pdf_file:pdf_reader = PyPDF2.PdfReader(pdf_file)# Get the total number of pages in the PDFtotal_pages = len(pdf_reader.pages)# Iterate through each page of the PDFfor page_num in range(total_pages):# Read the page contentpage = pdf_reader.pages[page_num]page_text = page.extract_text()# Check all keywordsfor keyword in keywords:if keyword in page_text:# Check if this file has not been processed for this keywordif filename not in processed_files[keyword]:results[keyword].append({"file_name": filename,"page_number": page_num + 1 # PDF page numbers start from 1})processed_files[keyword].add(filename)return results# 示例用法
folder_to_search = r"C:\Users\Administrator\Desktop\优秀论文"
search_keywords = ["ARIMA", "XGBoost", "SVM", "支持向量机","线性回归","决策树","随机森林","模拟退火","粒子群","遗传算法","LSTM","BP神经网络","t-SNE","LightGBM","GMM","距离相关系数","灰色关联分析","互信息","信息熵","递归特征消除","综合评价","熵权法"] # 添加多个关键字,包括不存在的关键字
results = search_pdf_files(folder_to_search, search_keywords)# 打印结果
for keyword, keyword_results in results.items():if keyword_results:print(f"关键字 '{keyword}' 所在的文件及页数:")for result in keyword_results:print(f"文件 '{result['file_name']}'")else:print(f"没有找到关键字 '{keyword}'。")print() # 输出换行以区分不同关键字的结果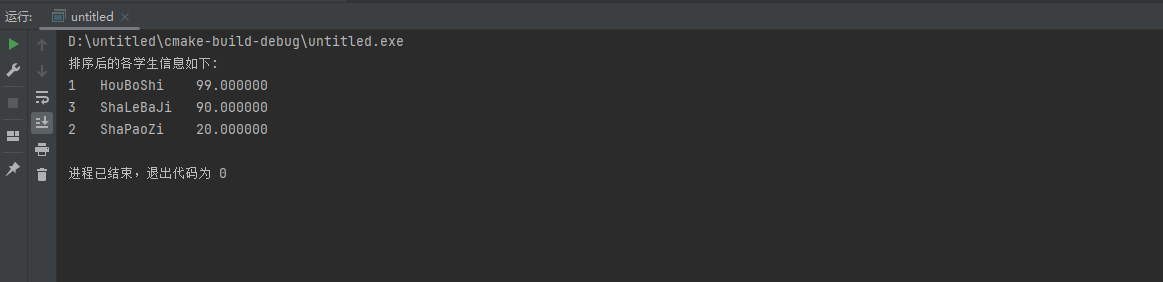

![[Linux入门]---Linux项目自动化构建工具-make/Makefile](https://img-blog.csdnimg.cn/ae23cf9f3207488a9ac8ad363149c9f3.png)