《Dataset Condensation with Differentiable Siamese Augmentation》
在本文中,我们专注于将大型训练集压缩成显著较小的合成集,这些合成集可以用于从头开始训练深度神经网络,性能下降最小。受最近的训练集合成方法的启发,我们提出了可微暹罗增强方法,它可以有效地利用数据增强来合成更具信息的合成图像,从而在使用增强方法训练网络时获得更好的性能。在多个图像分类基准上的实验表明,该方法在CIFAR10和CIFAR100数据集上取得了较先进水平的显著提高,提高了7%。结果表明,该方法在MNIST、FashionMNIST、SVHN、CIFAR10上的相对性能分别为99.6%、94.9%、88.5%、71.5%,数据量不到1%。
方法:
1. 简单介绍DC(Data Condensation)
假设我们有一个巨大的训练集 T = \mathcal{T}= T= { ( x 1 , y 1 ) , … , ( x ∣ T ∣ , y ∣ T ∣ ) } \left\{\left(\boldsymbol{x}_1, y_1\right), \ldots,\left(\boldsymbol{x}_{|\mathcal{T}|}, y_{|\mathcal{T}|}\right)\right\} {(x1,y1),…,(x∣T∣,y∣T∣)} 其中有 ∣ T ∣ |\mathcal{T}| ∣T∣ 个图片和标签对. DC (Zhao et al., 2021)目标是学习一个更小的数据集 ∣ S ∣ |\mathcal{S}| ∣S∣ 生成图片和标签对。 S = \mathcal{S}= S= { ( s 1 , y 1 ) , … , ( s ∣ S ∣ , y ∣ S ∣ ) } \left\{\left(\boldsymbol{s}_1, y_1\right), \ldots,\left(\boldsymbol{s}_{|\mathcal{S}|}, y_{|\mathcal{S}|}\right)\right\} {(s1,y1),…,(s∣S∣,y∣S∣)} 来自于(通过学习) T \mathcal{T} T 并且在数据集 S \mathcal{S} S 上训练的神经网络效果和在 T \mathcal{T} T 上训练得到的神经网络效果接近。 用 ϕ θ T \phi_{\boldsymbol{\theta}^{\mathcal{T}}} ϕθT 和 ϕ θ S \phi_{\boldsymbol{\theta}^{\mathcal{S}}} ϕθS 表示深度神经网络,其参数分别为 θ T \boldsymbol{\theta}^{\mathcal{T}} θT 和 θ S \boldsymbol{\theta}^{\mathcal{S}} θS,分别在训练集 T \mathcal{T} T 和 S \mathcal{S} S 上训练得到。DC的目标是如下方程:
E x ∼ P D [ ℓ ( ϕ θ τ ( x ) , y ) ] ≃ E x ∼ P D [ ℓ ( ϕ θ S ( x ) , y ) ] \begin{equation} \mathbb{E}_{\boldsymbol{x} \sim P_{\mathcal{D}}}\left[\ell\left(\phi_{\boldsymbol{\theta}^\tau}(\boldsymbol{x}), y\right)\right] \simeq \mathbb{E}_{\boldsymbol{x} \sim P_{\mathcal{D}}}\left[\ell\left(\phi_{\boldsymbol{\theta}^{\mathcal{S}}}(\boldsymbol{x}), y\right)\right] \end{equation} Ex∼PD[ℓ(ϕθτ(x),y)]≃Ex∼PD[ℓ(ϕθS(x),y)]
在真实数据分布 P D P_{\mathcal{D}} PD 上的损失 ℓ \ell ℓ (i.e. cross-entropy loss)。
在浓缩数据集 S \mathcal{S} S 上训练得到的模型参数要尽可能接近原始数据集的结果, i.e. θ S ≈ θ T \boldsymbol{\theta}^{\mathcal{S}} \approx \boldsymbol{\theta}^{\mathcal{T}} θS≈θT。
然后作者就开始举例DC有哪些不好的地方。
例如:
- 在每一轮都假设 θ t T \boldsymbol{\theta}^{\mathcal{T}}_t θtT 和 θ t S \boldsymbol{\theta}^{\mathcal{S}}_t θtS相等,继续训练。
- 只对一个模型进行提取。
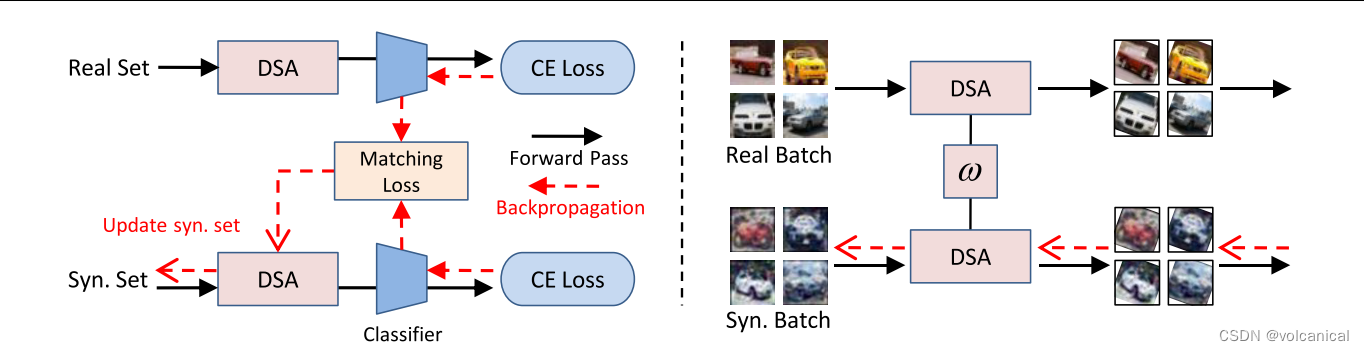
2. DSA
方法就是在DC前面套了一层数据增强,可微的数据增强
进入正题,那么本文提出的DSA,可微暹罗增强(我也不知道为什么是暹罗)
2.1 暹罗增强
首先是暹罗增强,在图片数据中基本就是裁剪,旋转,颜色变换等
min S D ( ∇ θ L ( A ( S , ω S ) , θ t ) , ∇ θ L ( A ( T , ω T ) , θ t ) ) \min _{\mathcal{S}} D\left(\nabla_{\boldsymbol{\theta}} \mathcal{L}\left(\mathcal{A}\left(\mathcal{S}, \omega^{\mathcal{S}}\right), \boldsymbol{\theta}_t\right), \nabla_{\boldsymbol{\theta}} \mathcal{L}\left(\mathcal{A}\left(\mathcal{T}, \omega^{\mathcal{T}}\right), \boldsymbol{\theta}_t\right)\right) SminD(∇θL(A(S,ωS),θt),∇θL(A(T,ωT),θt))
此处 ω T \omega^{\mathcal{T}} ωT和 ω S \omega^{\mathcal{S}} ωS分别代表了在两个数据集上进行的数据增强参数。然后作者指出,如果使用随机分布的 ω T \omega^{\mathcal{T}} ωT和 ω S \omega^{\mathcal{S}} ωS会导致训练无法收敛,因此在文中使用的 ω T = ω S \omega^{\mathcal{T}} = \omega^{\mathcal{S}} ωT=ωS。
那么因为,浓缩数据集 S \mathcal{S} S和原始数据集 T \mathcal{T} T肯定是不一样的,那就没有一个一对一的关系,来进行同样的数据增强,那么文中的方法就是,一个batch的数据使用一样的数据增强。一个batch里 S \mathcal{S} S和 T \mathcal{T} T相互对应。
2.2 可微增强
要让这个过程可以BP训练,那么这个数据增强必须是可以微分的,即:
∂ D ( ⋅ ) ∂ S = ∂ D ( ⋅ ) ∂ ∇ θ L ( ⋅ ) ∂ ∇ θ L ( ⋅ ) ∂ A ( ⋅ ) ∂ A ( ⋅ ) ∂ S \frac{\partial D(\cdot)}{\partial \mathcal{S}}=\frac{\partial D(\cdot)}{\partial \nabla_{\boldsymbol{\theta}} \mathcal{L}(\cdot)} \frac{\partial \nabla_{\boldsymbol{\theta}} \mathcal{L}(\cdot)}{\partial \mathcal{A}(\cdot)} \frac{\partial \mathcal{A}(\cdot)}{\partial \mathcal{S}} ∂S∂D(⋅)=∂∇θL(⋅)∂D(⋅)∂A(⋅)∂∇θL(⋅)∂S∂A(⋅)

Traditionally transformations used for data augmentation are not implemented in a differentiable way, as optimizing input images is not their focus. Note that all the standard data augmentation methods for images are differentiable and can be implemented as differentiable layers.
这里是不是有点自相矛盾,传统数据增强变换实现不是可微的,但是图像上的标准数据增强方法是可微的?
2.3 训练过程

和DC基本一致,最外层训练K负责训练不同的模型初始化以增强浓缩数据集适用性,内层不断更新模型,训练T-1步,最内层是对每一个标签进行训练更新数据集。
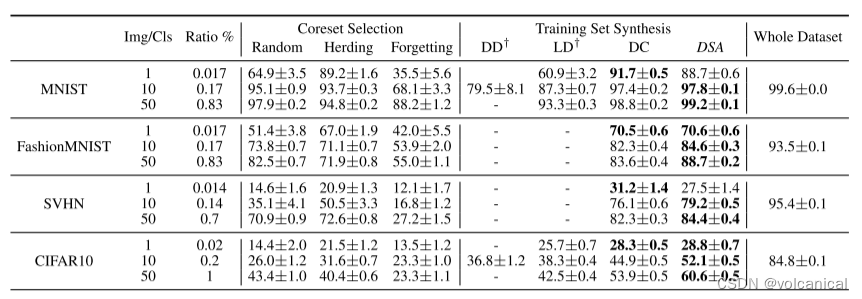
3. 实验结果
![[H5动画制作系列]单字母播放技术汇总-基础能力训练](https://img-blog.csdnimg.cn/bec7b42081b343c0b672477c69c4c814.png)