input输入表头
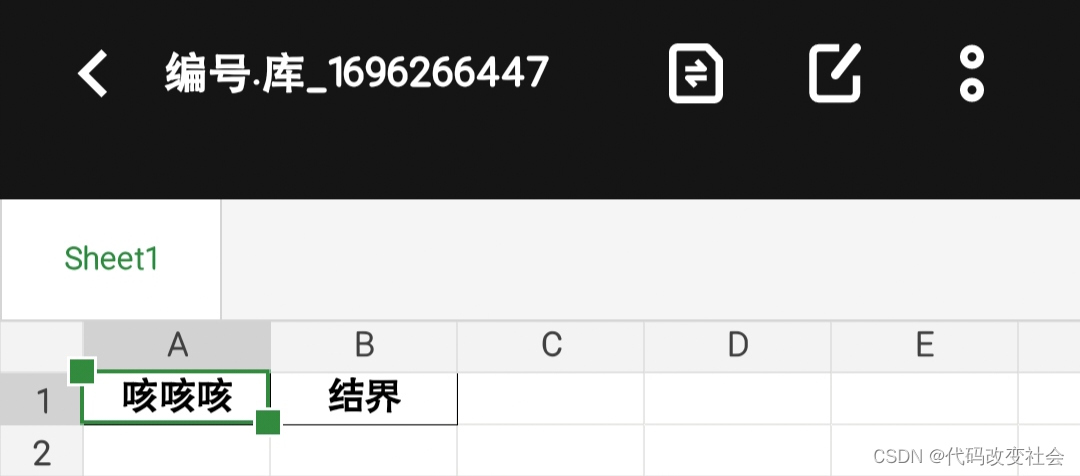
input输入表头
(input内除了/,空格 回车 标点符号等
全部作为单元格分隔符)保存/storage/emulated/0/代码文件/
没有就创建文件名命名方法:编号. 库 时间戳
嗨!听说你有个需求,想根据用户输入的内容创建一个Excel表格,并按照指定的命名方法来保存这个文件。哈哈!下面就给你看一个示例代码,让你瞧瞧是怎么做到的:
import pandas as pd
import os
import re
import time# 获取用户输入
header = input("请输入表头内容:")# 使用正则表达式替换除了斜杠、空格、回车和标点符号之外的字符为空格
header = re.sub(r'[^\w\s/]', ' ', header)# 使用空格作为分隔符,将表头拆分成列表
header_list = header.split()# 创建空的DataFrame
df = pd.DataFrame()# 在DataFrame中添加表头
df.columns = header_list# 创建保存目录
directory = '/storage/emulated/0/代码文件/'
if not os.path.exists(directory):os.makedirs(directory)# 生成文件名
file_name = '{}.{}_{}.xlsx'.format('编号', '库', int(time.time()))# 保存Excel文件
excel_file = os.path.join(directory, file_name)
df.to_excel(excel_file, index=False)
首先,我们要获取用户输入的表头内容。嗯,我会不厌其烦地把这个内容转换成Excel表格能接受的样子,去掉一些有点奇怪的符号。
然后,我们把处理好的表头放进一个全新而空白的Excel表格中,让它在那里等着,耐心地等着。
接下来,我们要创建一个特别的目录,为了保存这个特别的Excel文件。如果这个目录已经存在,就别管它了;如果不存在,我会亲自帮你建立起来。
让我们看看这段代码在“生成Excel文件”这个过程中进行了哪些操作:
开始
├─ 获取用户输入表头内容
│ └─ 干掉不需要的字符
├─ 拆分表头为列表
├─ 创建空的DataFrame
├─ 将表头添加到DataFrame中
├─ 创建保存目录
│ ├─ 如果目录不存在,创建该目录
│ └─ 如果目录已经存在,直接进入下一步
├─ 生成文件名
│ ├─ 包括一个编号
│ ├─ 一个库
│ └─ 当前时间的整数形式
├─ 保存Excel文件
│ ├─ 将DataFrame保存为Excel格式
│ ├─ 不要在Excel中显示行号
│ └─ 保存文件到指定目录下
└─ 结束
现在是时候给你的Excel文件起个独一无二的名字了!名字里包含一个编号,还有一个库,最后再加上当前的时间,这样才够酷对吧!
最后一步,就是把这个充满了期待的Excel文件保存起来了。我会小心翼翼地将这个表格以Excel格式保存好,并告诉它不要在Excel中显示行号。然后,我会把它放到我们刚刚特地创建的目录里,好让你一眼就能找到。
哈哈,到此为止!任务完成了,我们成功地根据用户需求创建了一个带有特别命名的Excel文件。感觉很有成就感对吧!但是我们输入出错了

这是为什么?❓
出现错误的原因是在创建空的DataFrame后,没有正确地设置表头。在设置表头时,长度不匹配导致了ValueError。
问题出在这一行代码:
df.columns = header_list
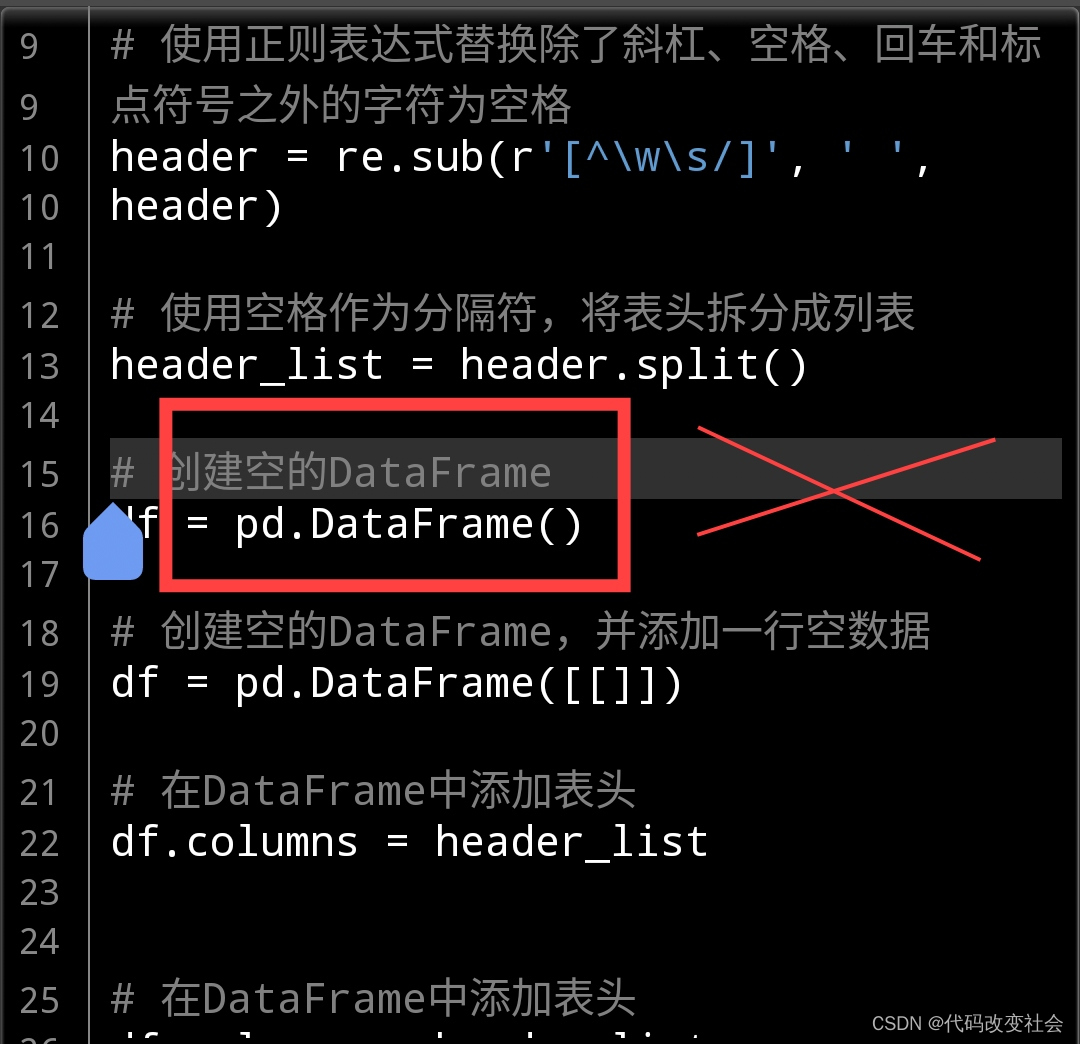
为了解决这个问题,你需要先手动为DataFrame添加一行空数据,然后再设置表头。修改的代码如下:
# 创建空的DataFrame,并添加一行空数据
df = pd.DataFrame([[]])# 在DataFrame中添加表头
df.columns = header_list
这样修改后,你应该能够看到新的错误❌答案
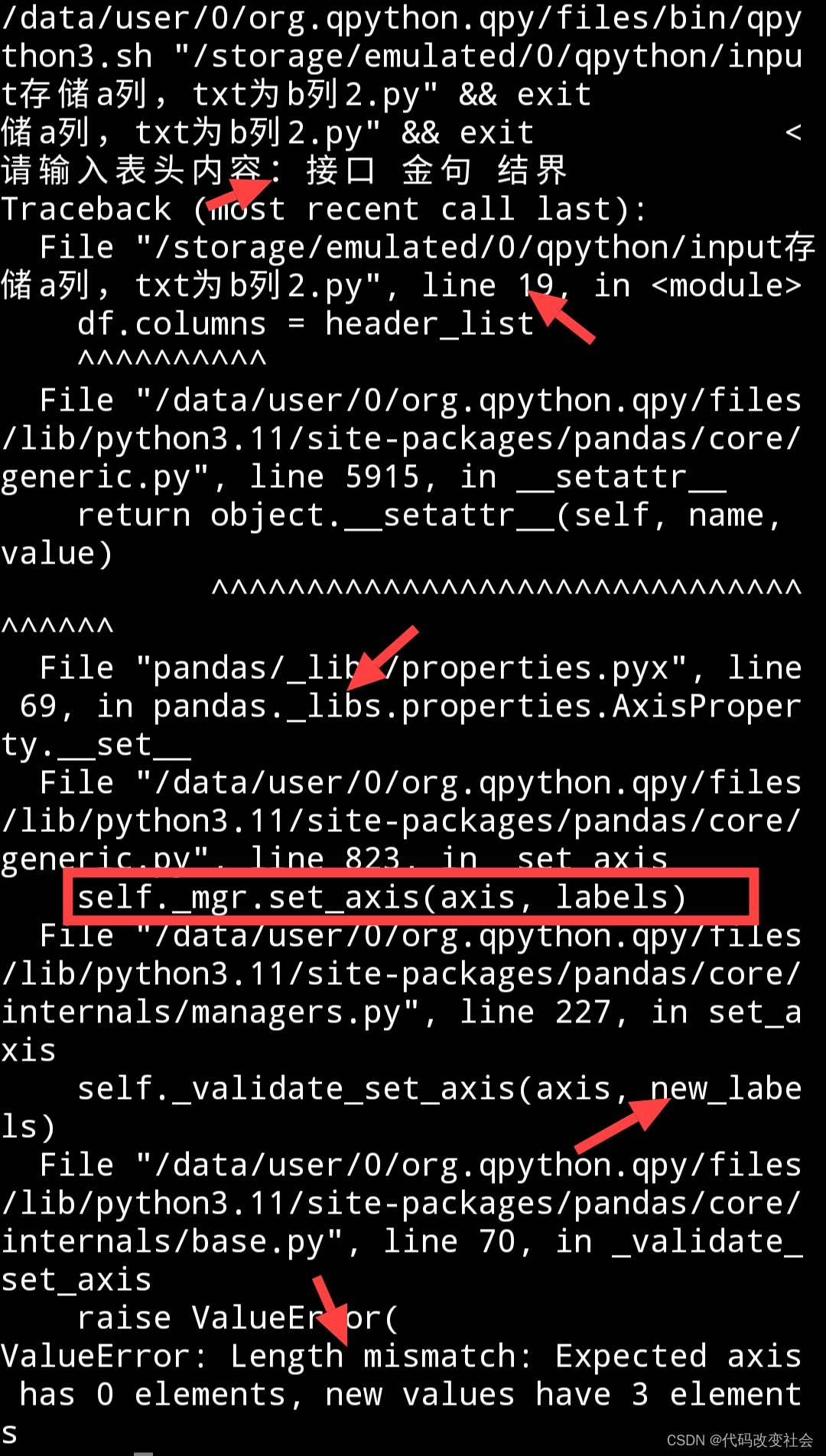
根据你提供的错误信息,问题仍然是由于长度不匹配导致的ValueError。根据错误信息,预期的轴(Expected axis)应该有0个元素,但新值(new values)却有3个元素。
这说明你的header_list列表长度为3,但是空的DataFrame并没有指定任何轴。
为了解决这个问题,请按照以下步骤修改代码:
- 创建一个空的DataFrame,并指定一个行(axis=0)。
- 在DataFrame中添加表头,确保表头与header_list的长度相匹配。
修改的代码如下:
# 创建空的DataFrame,并添加一行空数据
df = pd.DataFrame(columns=header_list)# 保存Excel文件
excel_file = os.path.join(directory, file_name)
df.to_excel(excel_file, index=False)
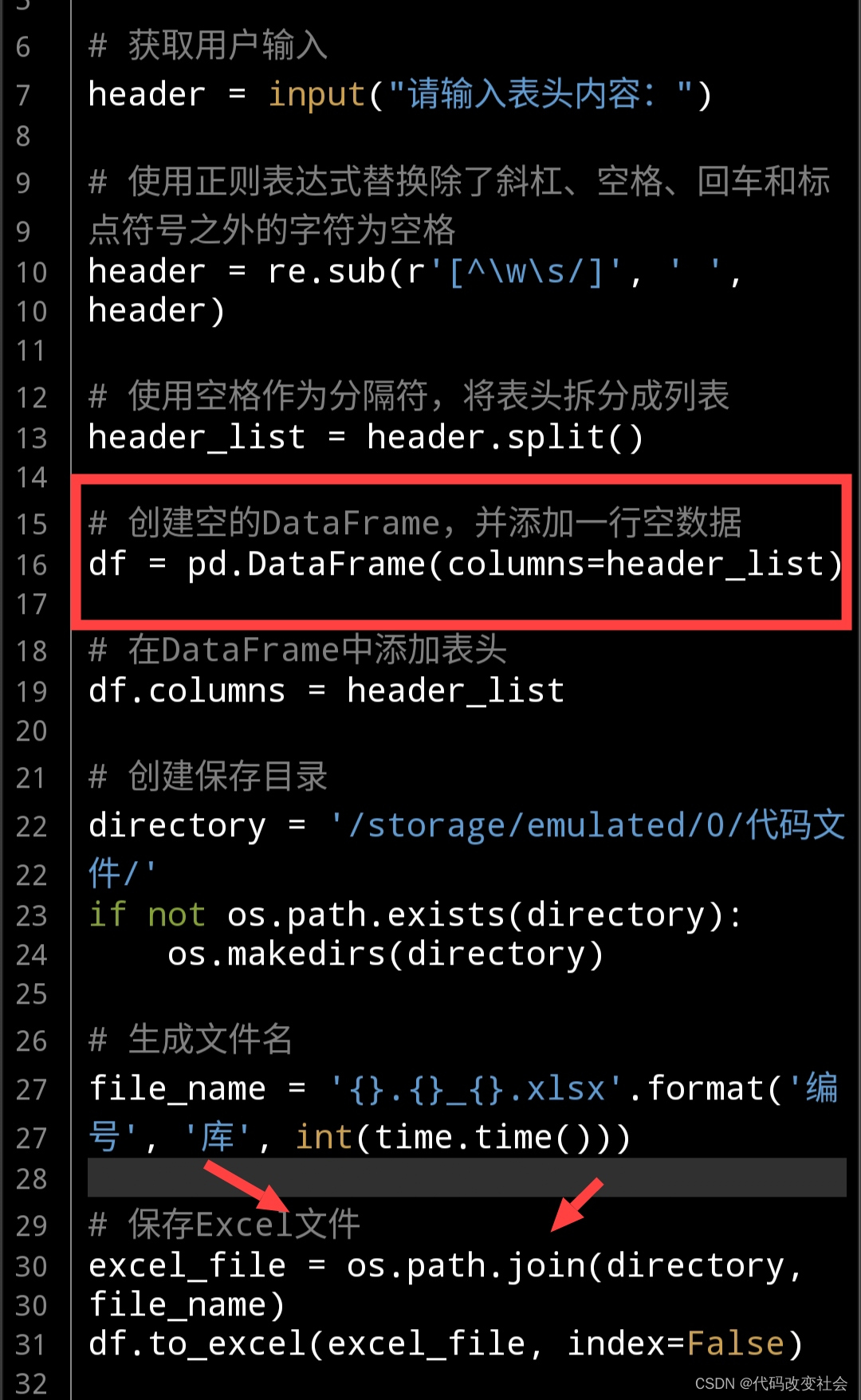
这样修改后,可以看到我们终于不再报错了。

你应该能够成功设置表头并继续执行后续的操作。
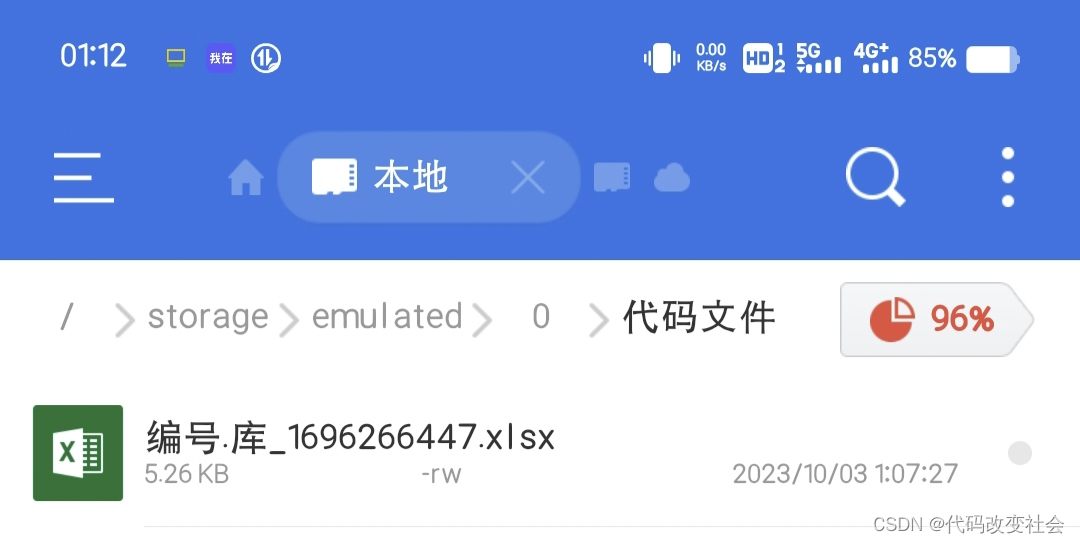
我们胜利了
修改后的代码为
import pandas as pd # 导入pandas库,用来玩转数据
import os # 导入os模块,和电脑文件玩耍
import re # 导入re模块,用来和字符们搞点小花样
import time # 导入time模块,和时间交个朋友# 获取用户输入
header = input("请输入表头内容:") # 用户大佬,请告诉我表头是啥子# 使用正则表达式替换除了斜杠、空格、回车和标点符号之外的字符为空格
header = re.sub(r'[^\w\s/]', ' ', header) # 通过施展魔法,把不属于字母数字、斜杠、空格、回车和标点符号的字符都变为空格# 使用空格作为分隔符,将表头拆分成列表
header_list = header.split() # 把表头按照空格进行裁剪,装进一个列表# 创建空的DataFrame,并添加一行空数据
df = pd.DataFrame(columns=header_list) # 准备一个空荡荡的表格,列名就是刚才小伙伴们给的表头# 在DataFrame中添加表头
df.columns = header_list # 让这个表格的列名变成刚才想好的表头们# 创建保存目录
directory = '/storage/emulated/0/代码文件/' # 准备好一个地方,专门用来保存代码文件# 看看这个地方存不存在,不存在就创建一个
if not os.path.exists(directory): # 如果这个地方不存在的话os.makedirs(directory) # 那咱们老老实实地创建一个目录吧# 生成文件名
file_name = '{}.{}_{}.xlsx'.format('编号', '库', int(time.time())) # 按照规矩来,给这个文件宝贝安排一个名字# 保存Excel文件
excel_file = os.path.join(directory, file_name) # 告诉电脑宝贝,这个文件要保存在哪里
df.to_excel(excel_file, index=False) # 把上面那个空荡荡的表格给保存到Excel文件里面去,别忘了把索引列也去掉哦~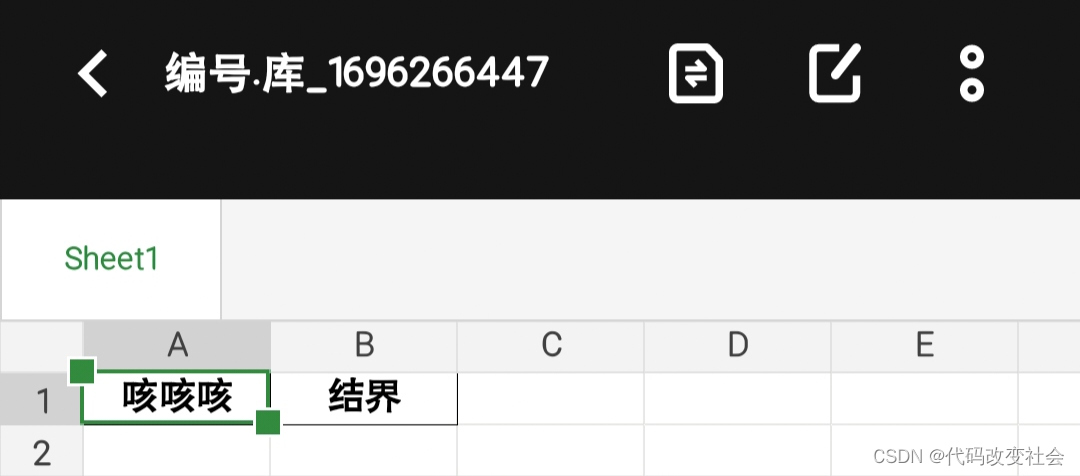


![[架构之路-228]:计算机硬件与体系结构 - 硬盘存储结构原理:如何表征0和1,即如何存储0和1,如何读数据,如何写数据(修改数据)](https://img-blog.csdnimg.cn/img_convert/ec8a420edd3c717b8212414255d52239.png)