RIFormer简介
Token Mixer是ViT骨干非常重要的组成成分,它用于对不同空域位置信息进行自适应聚合,但常规的自注意力往往存在高计算复杂度与高延迟问题。而直接移除Token Mixer又会导致不完备的结构先验,进而导致严重的性能下降。
原文地址:RIFormer: Keep Your Vision Backbone Effective But Removing Token Mixer
基于此,本文基于重参数机制提出了RepIdentityFormer方案以研究无Token Mixer的架构体系。紧接着,作者改进了学习架构以打破无Token Mixer架构的局限性并总结了5条指导方针。搭配上所提优化策略后,本文构建了一种极致简单且具有优异性能的视觉骨干,此外它还具有高推理效率优势。
实验结果表明:通过合适的优化策略,网络结构的归纳偏置可以被集成进简单架构体系中。本文为后续优化驱动的高效网络设计提供了新的起点和思路。
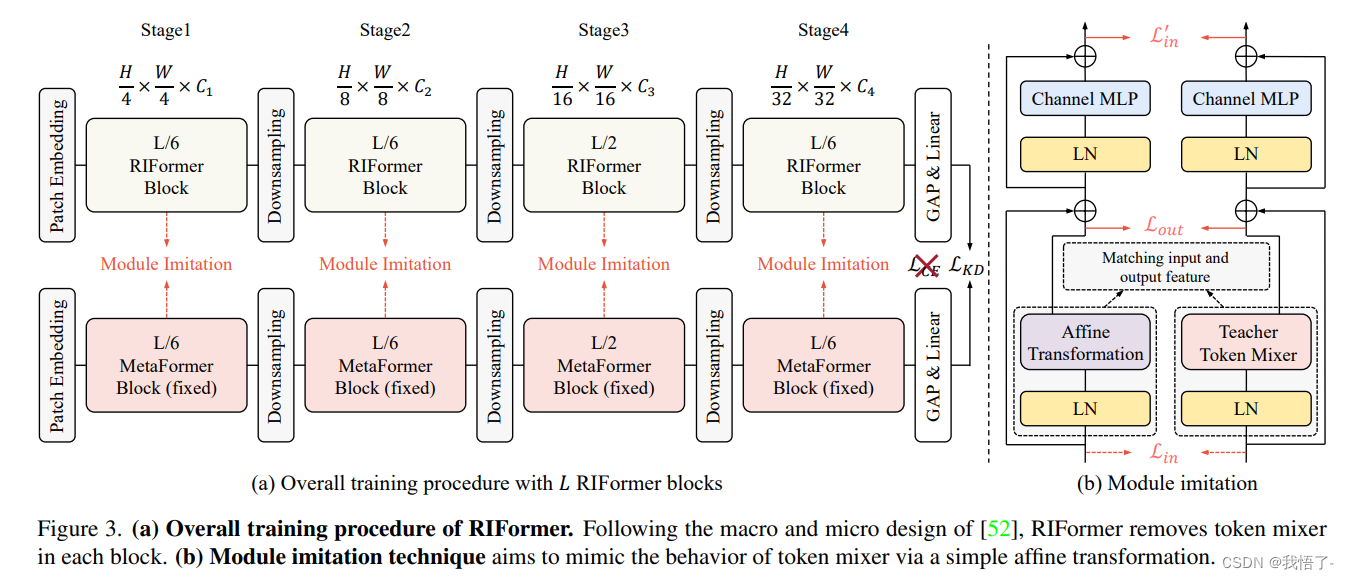
RIFormer代码实现
# Copyright (c) OpenMMLab. All rights reserved.
from typing import Sequence
import torch
import torch.nn as nn
import numpy as np
from mmcv.cnn.bricks import DropPath, build_activation_layer, build_norm_layer
from mmengine.model import BaseModule__all__ = ['RIFormer']class Mlp(nn.Module):"""Mlp implemented by with 1*1 convolutions.Input: Tensor with shape [B, C, H, W].Output: Tensor with shape [B, C, H, W].Args:in_features (int): Dimension of input features.hidden_features (int): Dimension of hidden features.out_features (int): Dimension of output features.act_cfg (dict): The config dict for activation between pointwiseconvolution. Defaults to ``dict(type='GELU')``.drop (float): Dropout rate. Defaults to 0.0."""def __init__(self,in_features,hidden_features=None,out_features=None,act_cfg=dict(type='GELU'),drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Conv2d(in_features, hidden_features, 1)self.act = build_activation_layer(act_cfg)self.fc2 = nn.Conv2d(hidden_features, out_features, 1)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass PatchEmbed(nn.Module):"""Patch Embedding module implemented by a layer of convolution.Input: tensor in shape [B, C, H, W]Output: tensor in shape [B, C, H/stride, W/stride]Args:patch_size (int): Patch size of the patch embedding. Defaults to 16.stride (int): Stride of the patch embedding. Defaults to 16.padding (int): Padding of the patch embedding. Defaults to 0.in_chans (int): Input channels. Defaults to 3.embed_dim (int): Output dimension of the patch embedding.Defaults to 768.norm_layer (module): Normalization module. Defaults to None (not use)."""def __init__(self,patch_size=16,stride=16,padding=0,in_chans=3,embed_dim=768,norm_layer=None):super().__init__()self.proj = nn.Conv2d(in_chans,embed_dim,kernel_size=patch_size,stride=stride,padding=padding)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):x = self.proj(x)x = self.norm(x)return xclass Affine(nn.Module):"""Affine Transformation module.Args:in_features (int): Input dimension."""def __init__(self, in_features):super().__init__()self.affine = nn.Conv2d(in_features,in_features,kernel_size=1,stride=1,padding=0,groups=in_features,bias=True)def forward(self, x):return self.affine(x) - xclass RIFormerBlock(BaseModule):"""RIFormer Block.Args:dim (int): Embedding dim.mlp_ratio (float): Mlp expansion ratio. Defaults to 4.norm_cfg (dict): The config dict for norm layers.Defaults to ``dict(type='GN', num_groups=1)``.act_cfg (dict): The config dict for activation between pointwiseconvolution. Defaults to ``dict(type='GELU')``.drop (float): Dropout rate. Defaults to 0.drop_path (float): Stochastic depth rate. Defaults to 0.layer_scale_init_value (float): Init value for Layer Scale.Defaults to 1e-5.deploy (bool): Whether to switch the model structure todeployment mode. Default: False."""def __init__(self,dim,mlp_ratio=4.,norm_cfg=dict(type='GN', num_groups=1),act_cfg=dict(type='GELU'),drop=0.,drop_path=0.,layer_scale_init_value=1e-5,deploy=False):super().__init__()if deploy:self.norm_reparam = build_norm_layer(norm_cfg, dim)[1]else:self.norm1 = build_norm_layer(norm_cfg, dim)[1]self.token_mixer = Affine(in_features=dim)self.norm2 = build_norm_layer(norm_cfg, dim)[1]mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim,hidden_features=mlp_hidden_dim,act_cfg=act_cfg,drop=drop)# The following two techniques are useful to train deep RIFormers.self.drop_path = DropPath(drop_path) if drop_path > 0. \else nn.Identity()self.layer_scale_1 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)self.norm_cfg = norm_cfgself.dim = dimself.deploy = deploydef forward(self, x):if hasattr(self, 'norm_reparam'):x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) *self.norm_reparam(x))x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) *self.mlp(self.norm2(x)))else:x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) *self.token_mixer(self.norm1(x)))x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) *self.mlp(self.norm2(x)))return xdef fuse_affine(self, norm, token_mixer):gamma_affn = token_mixer.affine.weight.reshape(-1)gamma_affn = gamma_affn - torch.ones_like(gamma_affn)beta_affn = token_mixer.affine.biasgamma_ln = norm.weightbeta_ln = norm.biasreturn (gamma_ln * gamma_affn), (beta_ln * gamma_affn + beta_affn)def get_equivalent_scale_bias(self):eq_s, eq_b = self.fuse_affine(self.norm1, self.token_mixer)return eq_s, eq_bdef switch_to_deploy(self):if self.deploy:returneq_s, eq_b = self.get_equivalent_scale_bias()self.norm_reparam = build_norm_layer(self.norm_cfg, self.dim)[1]self.norm_reparam.weight.data = eq_sself.norm_reparam.bias.data = eq_bself.__delattr__('norm1')if hasattr(self, 'token_mixer'):self.__delattr__('token_mixer')self.deploy = Truedef basic_blocks(dim,index,layers,mlp_ratio=4.,norm_cfg=dict(type='GN', num_groups=1),act_cfg=dict(type='GELU'),drop_rate=.0,drop_path_rate=0.,layer_scale_init_value=1e-5,deploy=False):"""generate RIFormer blocks for a stage."""blocks = []for block_idx in range(layers[index]):block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)blocks.append(RIFormerBlock(dim,mlp_ratio=mlp_ratio,norm_cfg=norm_cfg,act_cfg=act_cfg,drop=drop_rate,drop_path=block_dpr,layer_scale_init_value=layer_scale_init_value,deploy=deploy,))blocks = nn.Sequential(*blocks)return blocksdef update_weight(model_dict, weight_dict):idx, temp_dict = 0, {}for k, v in weight_dict.items():k = k[9:]if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):temp_dict[k] = vidx += 1model_dict.update(temp_dict)print(f'loading weights... {idx}/{len(model_dict)} items')return model_dictclass RIFormer(nn.Module):"""RIFormer.A PyTorch implementation of RIFormer introduced by:`RIFormer: Keep Your Vision Backbone Effective But Removing Token Mixer <https://arxiv.org/abs/xxxx.xxxxx>`_Args:arch (str | dict): The model's architecture. If string, it should beone of architecture in ``RIFormer.arch_settings``. And if dict, itshould include the following two keys:- layers (list[int]): Number of blocks at each stage.- embed_dims (list[int]): The number of channels at each stage.- mlp_ratios (list[int]): Expansion ratio of MLPs.- layer_scale_init_value (float): Init value for Layer Scale.Defaults to 'S12'.norm_cfg (dict): The config dict for norm layers.Defaults to ``dict(type='LN2d', eps=1e-6)``.act_cfg (dict): The config dict for activation between pointwiseconvolution. Defaults to ``dict(type='GELU')``.in_patch_size (int): The patch size of/? input image patch embedding.Defaults to 7.in_stride (int): The stride of input image patch embedding.Defaults to 4.in_pad (int): The padding of input image patch embedding.Defaults to 2.down_patch_size (int): The patch size of downsampling patch embedding.Defaults to 3.down_stride (int): The stride of downsampling patch embedding.Defaults to 2.down_pad (int): The padding of downsampling patch embedding.Defaults to 1.drop_rate (float): Dropout rate. Defaults to 0.drop_path_rate (float): Stochastic depth rate. Defaults to 0.out_indices (Sequence | int): Output from which network position.Index 0-6 respectively corresponds to[stage1, downsampling, stage2, downsampling, stage3, downsampling, stage4]Defaults to -1, means the last stage.frozen_stages (int): Stages to be frozen (all param fixed).Defaults to -1, which means not freezing any parameters.deploy (bool): Whether to switch the model structure todeployment mode. Default: False.init_cfg (dict, optional): Initialization config dict""" # noqa: E501# --layers: [x,x,x,x], numbers of layers for the four stages# --embed_dims, --mlp_ratios:# embedding dims and mlp ratios for the four stages# --downsamples: flags to apply downsampling or not in four blocksarch_settings = {'s12': {'layers': [2, 2, 6, 2],'embed_dims': [64, 128, 320, 512],'mlp_ratios': [4, 4, 4, 4],'layer_scale_init_value': 1e-5,},'s24': {'layers': [4, 4, 12, 4],'embed_dims': [64, 128, 320, 512],'mlp_ratios': [4, 4, 4, 4],'layer_scale_init_value': 1e-5,},'s36': {'layers': [6, 6, 18, 6],'embed_dims': [64, 128, 320, 512],'mlp_ratios': [4, 4, 4, 4],'layer_scale_init_value': 1e-6,},'m36': {'layers': [6, 6, 18, 6],'embed_dims': [96, 192, 384, 768],'mlp_ratios': [4, 4, 4, 4],'layer_scale_init_value': 1e-6,},'m48': {'layers': [8, 8, 24, 8],'embed_dims': [96, 192, 384, 768],'mlp_ratios': [4, 4, 4, 4],'layer_scale_init_value': 1e-6,},}def __init__(self,arch='s12',weights = '',in_channels=3,norm_cfg=dict(type='GN', num_groups=1),act_cfg=dict(type='GELU'),in_patch_size=7,in_stride=4,in_pad=2,down_patch_size=3,down_stride=2,down_pad=1,drop_rate=0.,drop_path_rate=0.,out_indices=[0, 2, 4, 6],deploy=False):super().__init__()if isinstance(arch, str):assert arch in self.arch_settings, \f'Unavailable arch, please choose from ' \f'({set(self.arch_settings)}) or pass a dict.'arch = self.arch_settings[arch]elif isinstance(arch, dict):assert 'layers' in arch and 'embed_dims' in arch, \f'The arch dict must have "layers" and "embed_dims", ' \f'but got {list(arch.keys())}.'layers = arch['layers']embed_dims = arch['embed_dims']mlp_ratios = arch['mlp_ratios'] \if 'mlp_ratios' in arch else [4, 4, 4, 4]layer_scale_init_value = arch['layer_scale_init_value'] \if 'layer_scale_init_value' in arch else 1e-5self.patch_embed = PatchEmbed(patch_size=in_patch_size,stride=in_stride,padding=in_pad,in_chans=in_channels,embed_dim=embed_dims[0])# set the main block in networknetwork = []for i in range(len(layers)):stage = basic_blocks(embed_dims[i],i,layers,mlp_ratio=mlp_ratios[i],norm_cfg=norm_cfg,act_cfg=act_cfg,drop_rate=drop_rate,drop_path_rate=drop_path_rate,layer_scale_init_value=layer_scale_init_value,deploy=deploy)network.append(stage)if i >= len(layers) - 1:breakif embed_dims[i] != embed_dims[i + 1]:# downsampling between two stagesnetwork.append(PatchEmbed(patch_size=down_patch_size,stride=down_stride,padding=down_pad,in_chans=embed_dims[i],embed_dim=embed_dims[i + 1]))self.network = nn.ModuleList(network)if isinstance(out_indices, int):out_indices = [out_indices]assert isinstance(out_indices, Sequence), \f'"out_indices" must by a sequence or int, ' \f'get {type(out_indices)} instead.'for i, index in enumerate(out_indices):if index < 0:out_indices[i] = 7 + indexassert out_indices[i] >= 0, f'Invalid out_indices {index}'self.out_indices = out_indicesif self.out_indices:for i_layer in self.out_indices:layer = build_norm_layer(norm_cfg,embed_dims[(i_layer + 1) // 2])[1]layer_name = f'norm{i_layer}'self.add_module(layer_name, layer)self.deploy = deployif weights:self.load_state_dict(update_weight(self.state_dict(), torch.load(weights)['state_dict']))self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def forward_embeddings(self, x):x = self.patch_embed(x)return xdef forward_tokens(self, x):outs = []for idx, block in enumerate(self.network):x = block(x)if idx in self.out_indices:norm_layer = getattr(self, f'norm{idx}')x_out = norm_layer(x)outs.append(x_out)return outsdef forward(self, x):# input embeddingx = self.forward_embeddings(x)# through backbonex = self.forward_tokens(x)return xif __name__ == '__main__':model = RIFormer('s12', 'riformer-s12_32xb128_in1k-384px_20230406-145eda4c.pth')inputs = torch.randn((1, 3, 640, 640))for i in model(inputs):print(i.size())
Backbone替换
yolo.py修改
def parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)# Parse a YOLOv5 model.yaml dictionaryLOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()LOGGER.info(f"{colorstr('activation:')} {act}") # printna = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)is_backbone = Falselayers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argstry:t = mm = eval(m) if isinstance(m, str) else m # eval stringsexcept:passfor j, a in enumerate(args):with contextlib.suppress(NameError):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept:args[j] = an = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, 8)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2elif isinstance(m, str):t = mm = timm.create_model(m, pretrained=args[0], features_only=True)c2 = m.feature_info.channels()elif m in {RIFormer}: #添加Backbonem = m(*args)c2 = m.channelelse:c2 = ch[f]if isinstance(c2, list):is_backbone = Truem_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)for _ in range(5 - len(ch)):ch.insert(0, 0)else:ch.append(c2)return nn.Sequential(*layers), sorted(save)
def _forward_once函数
def _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)for _ in range(5 - len(x)):x.insert(0, None)for i_idx, i in enumerate(x):if i_idx in self.save:y.append(i)else:y.append(None)x = x[-1]else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x
创建.yaml配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, RIFormer, [False]], # 4[-1, 1, SPPF, [1024, 5]], # 5]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], # 6[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7[[-1, 3], 1, Concat, [1]], # cat backbone P4 8[-1, 3, C3, [512, False]], # 9[-1, 1, Conv, [256, 1, 1]], # 10[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11[[-1, 2], 1, Concat, [1]], # cat backbone P3 12[-1, 3, C3, [256, False]], # 13 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], # 14[[-1, 10], 1, Concat, [1]], # cat head P4 15[-1, 3, C3, [512, False]], # 16 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], # 17[[-1, 5], 1, Concat, [1]], # cat head P5 18[-1, 3, C3, [1024, False]], # 19 (P5/32-large)[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]










![buuctf-[GXYCTF2019]禁止套娃 git泄露,无参数rce](https://img-blog.csdnimg.cn/99adbfe03e804e4399282a047f043873.png)