前言
大家好,我是秋意零。
上一篇中介绍了,Pod 的服务对象,从而对 Pod 有了更深的理解;
今天的主题是 Pod 健康检查和恢复机制,我们将结束 Pod 的内容。
最近搞了一个扣扣群,旨在技术交流、博客互助,希望各位大佬多多支持!在我主页推广区域,如图:
文章底部推广区域,如图:

👿 简介
- 🏠 个人主页: 秋意零
- 🧑 个人介绍:在校期间参与众多云计算相关比赛,如:🌟 “省赛”、“国赛”,并斩获多项奖项荣誉证书
- 🎉 目前状况:24 届毕业生,拿到一家私有云(IAAS)公司 offer,暑假开始实习
- 🔥 账号:各个平台, 秋意零 账号创作者、 云社区 创建者
- 💕欢迎大家:欢迎大家一起学习云计算,走向年薪 30 万

系列文章目录
【云原生|探索 Kubernetes-1】容器的本质是进程
【云原生|探索 Kubernetes-2】容器 Linux Cgroups 限制
【云原生|探索 Kubernetes 系列 3】深入理解容器进程的文件系统
【云原生|探索 Kubernetes 系列 4】现代云原生时代的引擎
【云原生|探索 Kubernetes 系列 5】简化 Kubernetes 的部署,深入解析其工作流程
文章目录
- 前言
- 系列文章目录
- 一、健康检查
- Exec 方式
- HTTP 方式
- TCP 方式
- 二、就绪检测
- 三、恢复机制
- 总结
正文开始:
- 快速上船,马上开始掌舵了(Kubernetes),距离开船还有 3s,2s,1s…

一、健康检查
在 Kubernetes 中,Pod 的状态决定不了服务的状态,如:Pod 的状态是 running,而一个 Web 服务 Down 掉了,那么 Pod 对它是无感知的。本来我们理想是,这种服务 Down 掉之后,随之影响 Pod 的状态。所以我就需要==采用 Pod 的健康检查 “探针”(Probe),这样,kubelet 就会根据这个 Probe 的返回值决定这个容器的状态,而不是直接以容器镜像是否运行(来自 Docker 返回的信息)作为依据。是生产环境中保证应用健康存活的重要手段。
健康检查 “探针”(Probe)属于 Pod 生命周期范畴。
在 【探索 Kubernetes|作业管理篇 系列 8】探究 Pod 的 API 对象属性级别与重要字段用法,这篇中就介绍过 Pod 生命周期,遗忘了可以回头看看。
Kubernetes 中的 Pod 探针可以使用以下三种方式进行健康检查:
- Exec 探针(Exec Probe):通过在容器内执行命令来检查容器的健康状态。Kubernetes 将定期执行指定的命令,并根据命令的退出状态码来判断容器是否健康。
- HTTP 探针(HTTP Probe):通过向容器内指定的 HTTP 端点发送 HTTP 请求来检查容器的健康状态。Kubernetes 将检查请求的响应状态码,只有在响应码在指定的成功范围内时才认为容器是健康的。
- TCP 探针(TCP Probe):通过尝试建立到容器内指定端口的 TCP 连接来检查容器的健康状态。如果连接成功建立,则认为容器是健康的;否则,认为容器是不健康的。
Exec 方式
举个栗子:
apiVersion: v1
kind: Pod
metadata:labels:test: livenessname: test-liveness-exec
spec:containers:- name: livenessimage: nginximagePullPolicy: IfNotPresentargs:- /bin/sh- -c- touche /usr/share/nginx/html/test.html; sleep 15; rm -rf /usr/share/nginx/html/test.htmllivenessProbe:exec:command:- cat- /usr/share/nginx/html/test.htmlinitialDelaySeconds: 5periodSeconds: 5这个 Pod 中,最开始会创建 一个 /usr/share/nginx/html/test.html 文件,过 15 s 之后会删除这个 /usr/share/nginx/html/test.html 文件。
同时,定义了一个 livenessProbe(健康检查探针),它的动作是 exec 进去容器执行 cat /usr/share/nginx/html/test.html 查看文件内容,如果命令成功执行那么返回值会是 0,否则就不是 0,返回为 0 就代表当前服务是健康的。
注意:这个健康检查,在容器启动 5 s 后开始执行(initialDelaySeconds: 5),每 5 s 执行一次(periodSeconds: 5)。所以,可以将 initialDelaySeconds 和 periodSeconds 看作是用来控制健康检查动作的属性。
首先,创建这个 Pod:
[root@master01 yaml]# kubectl apply -f liveness.yaml
pod/test-liveness-exec created
然后,查看这个 Pod 的状态,使用 -w 监控状态:
[root@master01 yaml]# kubectl get -f liveness.yaml -w
NAME READY STATUS RESTARTS AGE
test-liveness-exec 1/1 Running 0 7stest-liveness-exec 0/1 Completed 0 16s
test-liveness-exec 1/1 Running 1 (1s ago) 17s
test-liveness-exec 0/1 Completed 1 (16s ago) 32s
上述中,可以看到 16s 时,Pod 的状态就不在是 Running 而是 Completed,这时我们查看 Events 事件:
- 看到我们,使用健康检查的来检测文件不存在,说明此时 Pod 的状态是不健康的。
- 而现在 Pod 的状态是 Completed 这就和 Pod 的重启策略有关了。
kubectl describe -f liveness.yaml
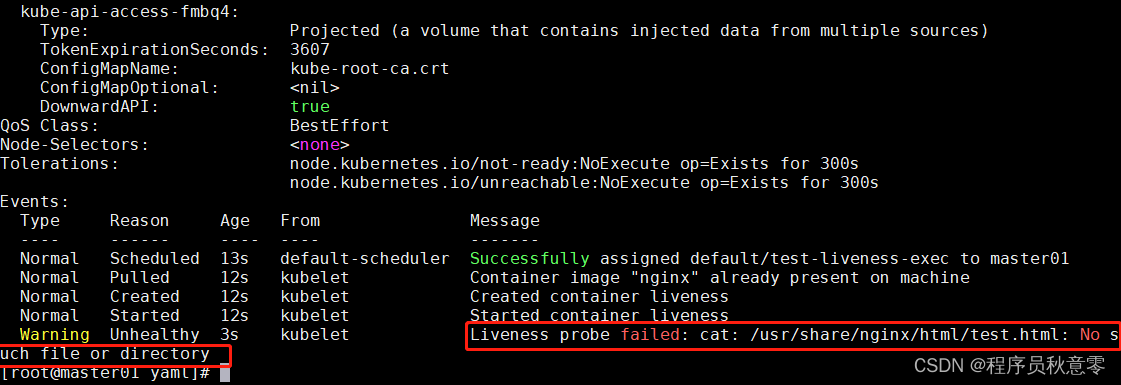
我们查看 17 s 之后,Pod 的状态变为了 Runing,说明了 Pod 以及重新启动过一次了,RESTARTS 字段可以看出重新启动的次数,如下:
[root@master01 yaml]# kubectl get -f liveness.yaml -w
NAME READY STATUS RESTARTS AGE
test-liveness-exec 1/1 Running 0 7stest-liveness-exec 0/1 Completed 0 17s
test-liveness-exec 1/1 Running 1 (2s ago) 18s
test-liveness-exec 1/1 Running 2 (1s ago) 33s
这时就有个疑问,最开始 Pod 没有进入 Failed 状态,而是进入 Completed 再保持 Running 状态。这是为什么呢?这就是 Pod 的重启策略(restartPolicy),也就是 Pod 的恢复机制。
HTTP 方式
cat > liveness-http.yaml << EOF
apiVersion: v1
kind: Pod
metadata:name: my-pod
spec:containers:- name: web-appimage: nginximagePullPolicy: IfNotPresentports:- containerPort: 80livenessProbe:httpGet:path: /port: 80initialDelaySeconds: 15periodSeconds: 10
EOF
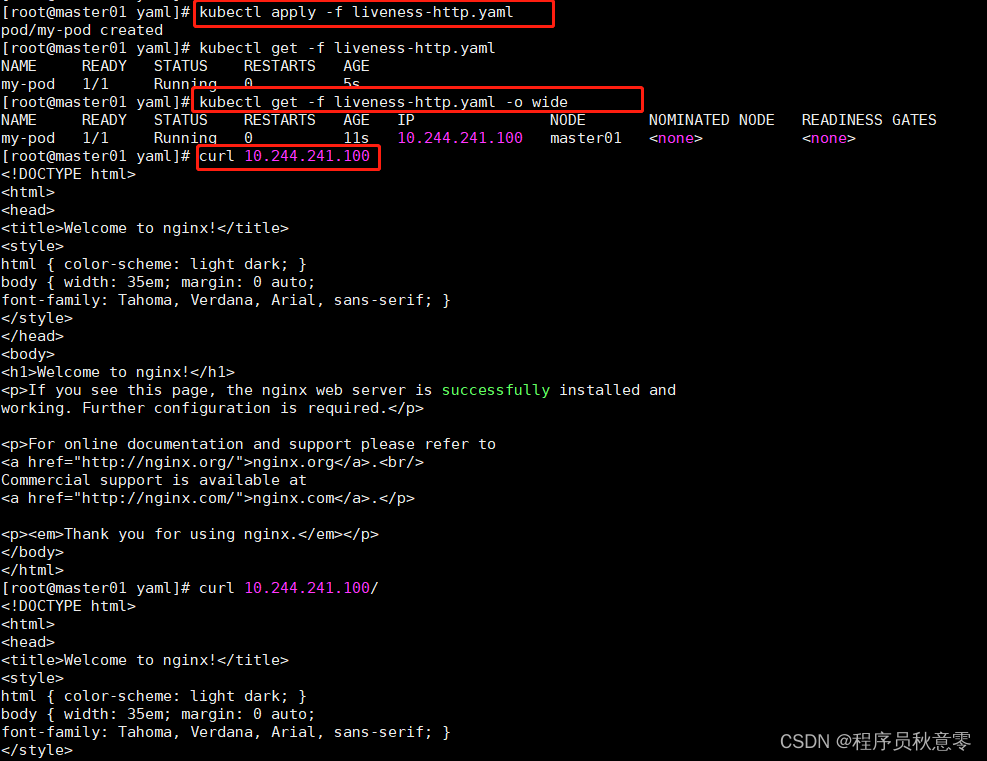
可以看到,我们 liveness-http 方式的 Pod,一直在运行(健康),并没有重启。
[root@master01 yaml]# kubectl get -f liveness-http.yaml
NAME READY STATUS RESTARTS AGE
my-pod 1/1 Running 0 3m57s
TCP 方式
apiVersion: v1
kind: Pod
metadata:name: my-pod
spec:containers:- name: my-containerimage: nginximagePullPolicy: IfNotPresentports:- containerPort: 80livenessProbe:tcpSocket:port: 80initialDelaySeconds: 15periodSeconds: 10
二、就绪检测
就绪检测(Readiness Probe)是 Kubernetes 中的一项功能,用于确定 Pod 是否已准备好接收流量和处理请求。就绪检测主要用于控制 Pod 在启动后何时被添加到服务负载均衡器中,以确保只有处于就绪状态的 Pod 才能接收到流量。
这部分内容,会在讲解 Service 时重点介绍。
三、恢复机制
restartPolicy。它是 Pod 的 Spec 部分的一个标准字段(pod.spec.restartPolicy),默认值是 Always,即:任何时候这个容器发生了异常,它一定会被重新创建。
*需要强调的是:
- Pod 的恢复过程,永远都是发生在当前节点上,而不会跑到别的节点上去。
- 事实上,一旦一个 Pod 与一个节点(Node)绑定,除非这个绑定发生了变化(pod.spec.node 字段被修改),否则它永远都不会离开这个节点。
- 这也就意味着,如果这个宿主机宕机了,这个 Pod 也不会主动迁移到其他节点上去。
而如果你想让 Pod 出现在其他的可用节点上,就必须使用 Deployment 这样的 “控制器” 来管理 Pod,哪怕只需要一个 Pod 副本。
Pod 和 Deployment 的区别:如果 Pod 所在 Node 异常,那么该 Pod 不会被迁移到其他节点;而 Deployment 会由 Kubernetes 负责调度保障业务正常运行,会重新调度新 Node 节点运行。
可以通过设置 restartPolicy,改变 Pod 的恢复策略,取值如下:
- Always:在任何情况下,只要容器不在运行状态,就自动重启容器;
- OnFailure: 只在容器 异常时才自动重启容器;
- Never: 从来不重启容器。
在实际使用时,我们需要根据应用运行的特性,合理设置这三种恢复策略。
比如,一个 Pod,它只计算 1+1=2,计算完成输出结果后退出,变成 Succeeded 状态。这时,你如果再用 restartPolicy=Always 重启这个 Pod 的容器,就没有任何意义了,所以这种情况使用 OnFailure 策略。
而如果你要关心这个容器退出后的上下文环境,比如容器退出后的日志、文件和目录,就需要将 restartPolicy 设置为 Never。因为一旦容器被自动重新创建,这些内容就有可能丢失掉了(被垃圾回收了)。
Kubernetes 官方文档中,总结了一堆的情况。实践上,只需要记住下面两个基本的设计原理即可:
- 只要 Pod 的 restartPolicy 指定的策略允许重启异常的容器(Always、OnFailure),那么这个 Pod 就会保持 Running 状态。否则,Pod 就会进入 Failed 状态 。
- 对于包含多个容器的 Pod,只有它里面所有的容器都进入异常状态后,Pod 才会进入 Failed 状态。在此之前,Pod 都是 Running 状态。
总结
主要讲解了,Pod 的健康检查的基本概率,以及 Exec、HTTP、TCP 三种使用方式;
接着讲解了 Pod 的恢复机制,我们知道了,实际上 Pod 的恢复机制就是 Pod 的三种重启策略。
至此 Pod 的内容也基本介绍完了,目前剩下就绪检查的概率,这个后续会说明。
下一章将是控制器部分的内容。
最后:技术交流、博客互助,点击下方或主页推广加入哦!!