Python3中类的高级语法及实战
Python3(基础|高级)语法实战(|多线程|多进程|线程池|进程池技术)|多线程安全问题解决方案
Python3数据科学包系列(一):数据分析实战
Python3数据科学包系列(二):数据分析实战
Python3数据科学包系列(三):数据分析实战
Win11查看安装的Python路径及安装的库
Python PEP8 代码规范常见问题及解决方案
Python3操作MySQL8.XX创建表|CRUD基本操作
Python3操作SQLite3创建表主键自增长|CRUD基本操作
anaconda3最新版安装|使用详情|Error: Please select a valid Python interpreter
Python函数绘图与高等代数互融实例(一):正弦函数与余弦函数
Python函数绘图与高等代数互融实例(二):闪点函数
Python函数绘图与高等代数互融实例(三):设置X|Y轴|网格线
Python函数绘图与高等代数互融实例(四):设置X|Y轴参考线|参考区域
Python函数绘图与高等代数互融实例(五): 则线图综合案例
Python3操作MongoDb7最新版创建文档及CRUD基本操作
Python3操作Redis官方详细文档
Java OR Mapping Redis文档:
Adding Redis OM Spring Java对象到Redis对象关系映射高级应用
对象关系映射Maven三角坐标
Python操作Redis高级方式: 异步操作Redis|管道|事务等操作
找准文档,对症下药,精准匹配,求人不如求文档,码农小菜鸟
精准扶贫|保姆服务
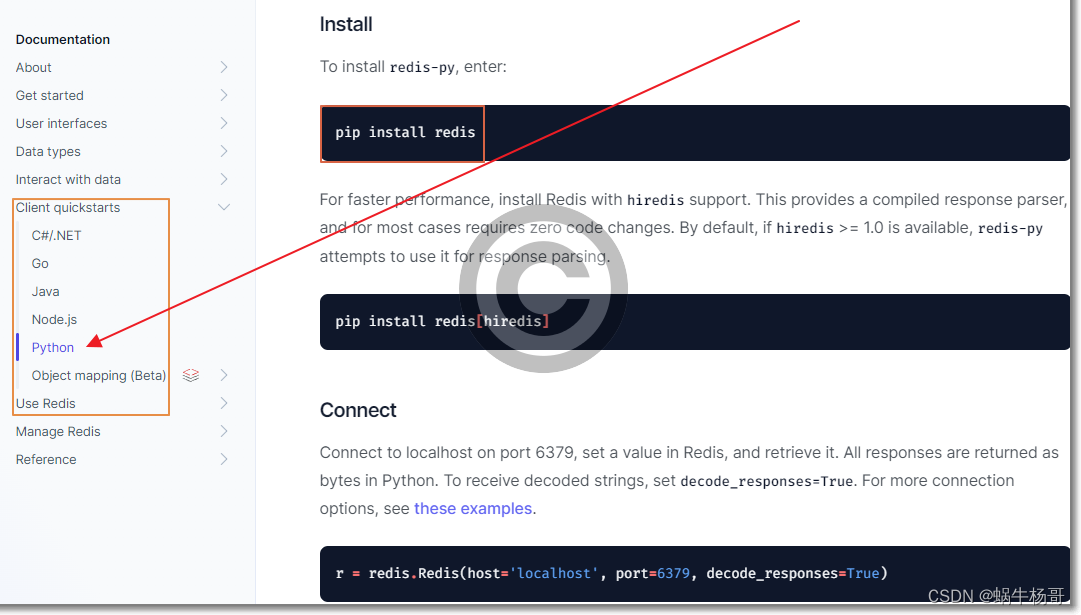
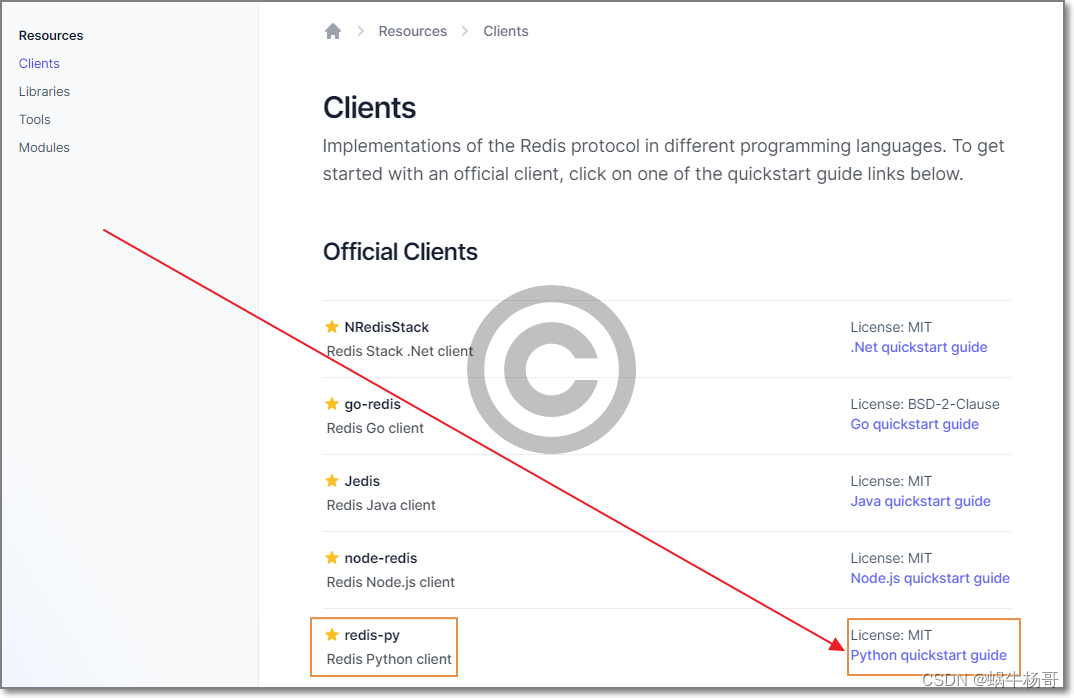
一: Redis连接
认知升维
Python3连接Redis操作 StrictRedis跟Redis的区别在于,StrictRedis用于实现大部分官方命令,并使用官方的语法和命令,Redis是StrictRedis的子类,兼容一些老版本。 Redis连接实例是线程安全的,可以直接将redis连接实例设置为一个全局变量,直接使用。
import redis"""Python3连接Redis操作StrictRedis跟Redis的区别在于,StrictRedis用于实现大部分官方命令,并使用官方的语法和命令,Redis是StrictRedis的子类,兼容一些老版本。Redis连接实例是线程安全的,可以直接将redis连接实例设置为一个全局变量,直接使用。 """ print("当前python引入的Redis版本", redis.__version__) linkRedis = None try:linkRedis = redis.StrictRedis(host='192.168.1.111', port=6379, db=0) # 指定IP地址、端口、指定存放数据库# 如果指定一些其他参数,可以看源码,将需要的参数进行指定。print(linkRedis.dbsize()) except Exception as err:print("redis连接异常: ", err) finally:if linkRedis is not None:print("释放连接资源")linkRedis.close()print("""连接池:redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。每个redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。 """)pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True) redisLink = None try:redisLink = redis.Redis(connection_pool=pool) except Exception as err:print("redis连接异常: ", err) finally:if linkRedis is not None:print("redis连接还给连接池")redisLink.close()
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorLinkcreate.py
当前python引入的Redis版本 5.0.1
0
释放连接资源连接池:
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。每个redis实例都会维护一个自己的连接池。
可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。redis连接还给连接池
Process finished with exit code 0
二: Python操作Redis插入数据
import timeimport redis"""Python3连接Redis插入数据 """ pool = None redisLink = None try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool)result = redisLink.set('key', '你好,欢迎来到Python3操作(Redis7.2.0)Redis应用') # key 代表是键 value:hello redis 代表是值print(""" 字符串操作,redis中的String再内存中按照一个name对应一个value来存储。 set(name, value, ex=None, px=None, nx=False, xx=False) 再Redis中设置值,不存在则创建、存在即修改 参数:ex:过期时间(秒)px:过期时间(毫秒)nx:如果为True,当name不存在时,当前set操作会执行xx:如果为True,当name存在时,当前set操作会执行""")print(result) # 打印结果:True 说明设置成功print("获取Key对应的值: ", redisLink.get('key'))# ex: 设置过期时间(单位:秒) name为Key '老杨' 为valueredisLink.set("name", "老杨", ex=3)time.sleep(1)resultValue = redisLink.get('name')print("请叫我:%s" % resultValue)time.sleep(3)print("3秒后请叫我无名小卒")print('name = %s' % (redisLink.get('name')))except Exception as err:print("redis连接异常: ", err) finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorInsert.py
字符串操作,redis中的String再内存中按照一个name对应一个value来存储。
set(name, value, ex=None, px=None, nx=False, xx=False)
再Redis中设置值,不存在则创建、存在即修改
参数:
ex:过期时间(秒)
px:过期时间(毫秒)
nx:如果为True,当name不存在时,当前set操作会执行
xx:如果为True,当name存在时,当前set操作会执行
True
获取Key对应的值: 你好,欢迎来到Python3操作(Redis7.2.0)Redis应用
请叫我:老杨
3秒后请叫我无名小卒
name = None释放资源,连接还给连接池
Process finished with exit code 0
三: Python3操作Redis查询数据
import time import redis"""Python3连接Redis查询数据 """ pool = None redisLink = None try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool, encoding='UTF-8')print("""getrange(key, start, end):获取子序列(根据字节获取,非字符)一个汉字3个字节 1个字母一个字节 每个字节8bit参数:name:redis的namestart:起始位置(字节)end:结束位置(字节)""")redisLink.set('detail', '详情信息')# 取索引号是0-2 前3位字节print(redisLink.getrange('detail', 0, 2))# 取所有的信息print(redisLink.getrange('detail', 0, -1))# 输出结果:详情信息redisLink.set('title', 'good')print(redisLink.getrange('title', 0, 2))# 输出结果:gooprint(redisLink.getrange('title', 0, -1))# 输出结果:goodprint()print("""incr(name, amount=1):自增name对应的值,当name不存在时,创建name=amount,存在则自增参数:name:redis的nameamount:自增数(必须是整数)""")print()# 自增name='incr' 每次自增 +1redisLink.incr('incr', amount=1)print(redisLink.get('incr'))# 输出结果:+1# 应用场景:记录页面的点击次数。print()print("""incrbyfloat(name, amount=1.0):自增name对应得值,当name不存在时,创建name=amount,存在则自增参数:name:redis的nameamount:自然数(浮点数)""")# 设置name='num'redisLink.set('num', '0.00')print(redisLink.get('num'))# 输出结果:0.00# 自增浮点数redisLink.incrbyfloat('num', amount=1.0)print(redisLink.get('num'))print("""decr(name, amout=1):自减name对应的值,当name不存在时,创建name=amount,存在则自增参数:name:redis的nameamount:自减数(整数)""")# 先查询name='num' 是否存在, 若存在 将对应的value 自减 1 ,不存在创建redisLink.decr('num', amount=1)print(redisLink.get('num'))# 输出结果: -1print()print("""append(key, value):再redis name对应的值后面追加内容参数:key:redis的namevalue:追加的字符串""")# 原name='name' 对应的value='老杨'redisLink.append('name', 'laogao')print('拼接后的字符串为: ', redisLink.mget('name'))# 输出结果:['老杨laogao'] 将value 拼接再一起print("操作列表")print()print("""lpush(name, values):从左边新增加,不存在就新建""")# 往name='list' 中从左添加value=[11, 22, 33]redisLink.lpush('list', 11, 22, 33)print(redisLink.lrange('list', 0, -1))# 输出结果:['33', '22', '11'] 保存顺序为 33,22,11print("""rpush(name, values):从右边新增加,不存在就新建""")# name='list1' 中从右添加value=[66, 55, 44]redisLink.rpush('list1', 66, 55, 44)print(redisLink.lrange('list1', 0, -1))# 输出结果:['66', '55', '44']print("""llen(name):获取列表长度""")# 获取name='list1' 列表中的长度 value=[66, 55, 44]print(redisLink.llen('list1'))# 输出结果: 3print("""lpushx(name, value):往已经有的name的列表的左边添加元素,没有的话无法创建""")# 首先redis数据库中没有name='list2'redisLink.lpushx('list2', 10)print(redisLink.lrange('list2', 0, -1))# 输出结果: []print("""rpushx(name, value):往已经有的name的列表的右边添加元素,没有的话无法创建""")# 首先redis数据库中没有name='list2'redisLink.rpushx('list2', '10')print(redisLink.lrange('list2', 0, -1))# 输出结果: []print("""linsert(name, where, refvalue, value):在name对应的列表的某一个值前或后插入一个新值参数:name:redis的namewhere:BEFORE或AFTERrefvalue:标杆值 (以它为基础, 前后插入新值)value:要插入的数据""")# 往列表中左边第一个出现的元素"66"前插入元素"77", 若name不存在, 不会新创建, 会返回[]redisLink.linsert('list1', 'before', '66', '77') # 目前数据库list1=[66, 55, 44]print(redisLink.lrange('list1', 0, -1))# 输出结果: ['77', '66', '55', '44']print("""lset(name, index, value):对name对应的list中的某一个索引位置重新赋值参数:name:redis的nameindex:list的索引位置value:要设置的新值""")# 将list1中索引为3, 替换成'33', list1=['77', '66', '55', '44']redisLink.lset('list1', 3, '33')print(redisLink.lrange('list1', 0, -1))# 输出结果: ['77', '66', '55', '33']print("""lrem(name, value, num):name对应的list中删除指定的值参数:name:redis的namevalue:要删除得值num:num=0,删除列表中所有的值num=2,从前向后,删除2个;num=-2, 从后向前,删除2个;""")# list1=['77', '66', '55', '33']# 从左向右, 找到value='66' 删除一个redisLink.lrem("list1", 1, "66")print(redisLink.lrange('list1', 0, -1))# 输出结果:['77', '55', '33']# list1=['77', '55', '33']# 从右向左, 找到value='55', 删除一个redisLink.lrem('list1', -1, '55')print(redisLink.lrange('list1', 0, -1))# 输出结果:['77', '33']# list1=['77', '77', '33']# 删除name='list1'中 value='77'的所有值redisLink.lrem('list1', 0, '77')print(redisLink.lrange('list1', 0, -1))# 输出结果:print("""lpop(name) 、rpop(name):在name对应的列表的左侧/右侧获取第一个元素并在列表中移除,返回值则是第一个元素""")# list1 = ['77', '66', '55']result = redisLink.lpop('list1')print(result) # 输出结果:77print(redisLink.lrange('list1', 0, -1)) # 输出结果:['66', '55']# list1 = ['66', '55']result = redisLink.rpop('list1')print(result) # 输出结果:55print(redisLink.lrange('list1', 0, -1)) # 输出结果:['66']print("""ltrim(name, start, end):name对应的列表中移除没有在start-end索引之间的值参数:name:redis的namestart:索引的起始位置end:索引的结束位置""")# list1=['77', '66', '55', '44', '33']# 删除name='list1'中, 不包含索引0-2的valueredisLink.ltrim('list1', 0, 2)print(redisLink.lrange('list1', 0, -1))# 输出结果:['77', '66', '55']print()print("""lindex(name, index):在name对应的列表中根据索引获取列表元素""")# list1=['77', '66', '55']# 取出name='list1'中索引为1的值print(redisLink.lindex('list1', 1)) # 输出结果:66print()print("""brpoplpush(src, dst, timeout=0):从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧参数:src:取出并要移除元素的列表对应的namedst:要插入元素的列表对应的nametimeout:当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞""")# list = ['33', '22', '11']# list1 = ['77', '66', '55']# 将name='list1' 中的Value 全部插入到name='list'中redisLink.brpoplpush('list1', 'list', timeout=2)print(redisLink.lrange('list', 0, -1))# 输出结果:['77', '66', '55', '33', '22', '11']except Exception as err:print("redis连接异常: ", err) finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorQuery.py
getrange(key, start, end):
获取子序列(根据字节获取,非字符)
一个汉字3个字节 1个字母一个字节 每个字节8bit
参数:
name:redis的name
start:起始位置(字节)
end:结束位置(字节)
详
详情信息
goo
good
incr(name, amount=1):
自增name对应的值,当name不存在时,创建name=amount,存在则自增
参数:
name:redis的name
amount:自增数(必须是整数)
26
incrbyfloat(name, amount=1.0):
自增name对应得值,当name不存在时,创建name=amount,存在则自增
参数:
name:redis的name
amount:自然数(浮点数)
0.00
1decr(name, amout=1):
自减name对应的值,当name不存在时,创建name=amount,存在则自增
参数:
name:redis的name
amount:自减数(整数)
0
append(key, value):
再redis name对应的值后面追加内容
参数:
key:redis的name
value:追加的字符串
拼接后的字符串为: ['老杨laogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogao']
操作列表
lpush(name, values):
从左边新增加,不存在就新建
['33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11']rpush(name, values):
从右边新增加,不存在就新建
['33', '44', '33', '44', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '55', '44']llen(name):
获取列表长度
36lpushx(name, value):
往已经有的name的列表的左边添加元素,没有的话无法创建
[]rpushx(name, value):
往已经有的name的列表的右边添加元素,没有的话无法创建
[]linsert(name, where, refvalue, value):
在name对应的列表的某一个值前或后插入一个新值
参数:
name:redis的name
where:BEFORE或AFTER
refvalue:标杆值 (以它为基础, 前后插入新值)
value:要插入的数据
['33', '44', '33', '44', '55', '44', '77', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '55', '44']lset(name, index, value):
对name对应的list中的某一个索引位置重新赋值
参数:
name:redis的name
index:list的索引位置
value:要设置的新值
['33', '44', '33', '33', '55', '44', '77', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '55', '44']lrem(name, value, num):
name对应的list中删除指定的值
参数:
name:redis的name
value:要删除得值
num:num=0,删除列表中所有的值
num=2,从前向后,删除2个;
num=-2, 从后向前,删除2个;
['33', '44', '33', '33', '55', '44', '77', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '55', '44']
['33', '44', '33', '33', '55', '44', '77', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '44']
['33', '44', '33', '33', '55', '44', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '44']lpop(name) 、rpop(name):
在name对应的列表的左侧/右侧获取第一个元素并在列表中移除,返回值则是第一个元素
33
['44', '33', '33', '55', '44', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '44']
44
['44', '33', '33', '55', '44', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66']ltrim(name, start, end):
name对应的列表中移除没有在start-end索引之间的值
参数:
name:redis的name
start:索引的起始位置
end:索引的结束位置
['44', '33', '33']
lindex(name, index):
在name对应的列表中根据索引获取列表元素
33
brpoplpush(src, dst, timeout=0):
从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:
src:取出并要移除元素的列表对应的name
dst:要插入元素的列表对应的name
timeout:当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
['33', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11']释放资源,连接还给连接池
Process finished with exit code 0
四: Python3操作Redis删除数据
import time import redis"""Python3连接Redis删除数据 """ pool = None redisLink = None try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool, encoding='UTF-8')print("""delete(*names) :根据删除redis中的任意数据类型(string、hash、list、set、有序set)""")result = redisLink.delete('hash1') # 删除key为hash1的键值对print(result)result = redisLink.delete('name') # 删除key为name的值对print(result)result = redisLink.delete('list1') # 删除key为list1的值对print(result) except Exception as err:print("redis连接异常: ", err) finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()
运行效果
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorDelete.py
delete(*names) :
根据删除redis中的任意数据类型(string、hash、list、set、有序set)
0
1
1释放资源,连接还给连接池
Process finished with exit code 0
五: Python3操作Redis常规操作
import redis"""Python3常规操作数据 """ pool = None redisLink = None try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool, encoding='UTF-8')print("""exists(name):检测redis的name是否存在,存在就是True,False 不存在""")print(redisLink.exists('hash1')) # 输出结果:False 说明key 不存在print(redisLink.exists('set1')) # 输出结果:True 说明key存在print(redisLink.exists('list1')) # 输出结果:True 说明key存在print(redisLink.exists('name')) # 输出结果:True 说明key存在print()print("""expire(name ,time) :为某个redis的某个name设置超时时间""")redisLink.lpush('list5', 11, 22)redisLink.expire('list5', time=3)print(redisLink.lrange('list5', 0, -1))# 输出结果:['22', '11']import timetime.sleep(3)print(redisLink.lrange('list5', 0, -1))# 输出结果:[]print()print("""rename(src, dst) :对redis的name重命名""")redisLink.lpush('list5', 11, 22)print(redisLink.rename('list5', 'list-5'))# 输出结果: True 说明重命名成功print("""type(name) :获取name对应值的类型""")print("""查看所有元素""")print(redisLink.hscan("hash"))print(redisLink.sscan("set"))print(redisLink.zscan("zset"))print(redisLink.getrange("string", 0, -1))print(redisLink.lrange("list", 0, -1))print(redisLink.smembers("set3"))print(redisLink.zrange("zset3", 0, -1))print(redisLink.hgetall("hash1")) except Exception as err:print("redis连接异常: ", err) finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorUpdate.py
exists(name):
检测redis的name是否存在,存在就是True,False 不存在
0
0
0
1
expire(name ,time) :
为某个redis的某个name设置超时时间
['22', '11']
[]
rename(src, dst) :
对redis的name重命名
Truetype(name) :
获取name对应值的类型
查看所有元素
(0, {})
(0, [])
(0, [])['33', '33', '22', '11', '33', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11']
set()
[]
{}释放资源,连接还给连接池
Process finished with exit code 0
六: Python3操作Redis对Set集合操作
import time import redis"""Python3连接Redis集合Set数据操作 """ pool = None redisLink = None try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool, encoding='UTF-8')print("""sadd(name, values):name对应的集合中添加元素""")# 往集合中添加元素 name='set1'redisLink.sadd('set1', 1, 2, 3, 4, 5, 6)print(redisLink.smembers('set1'))# 输出结果:set(['1', '3', '2', '5', '4', '6'])print("""scard(name):name对应集合中元素个数""")# 'set1' = set(['1', '3', '2', '5', '4', '6'])print(redisLink.scard('set1'))# 输出结果: 6print("""smembers(name):name对应的集合所有成员""")# 获取name='set1' 中的所有values值print(redisLink.smembers('set1'))# 输出结果: set(['1', '3', '2', '5', '4', '6'])print("""sscan(name, cursor=0, match=None, count=None):name对应集合所有成员(元组形式)""")print(redisLink.sscan('set1'))# 输出结果:(0L, ['1', '2', '3', '4', '5', '6'])print("""sscan_iter(name, match=None, count=None):name对应集合所有成员(迭代器的方式)""")for item in redisLink.sscan_iter('set1'):print(item)print("""sdiff(key, *args):求集合中的差集""")# name是set1、set2中values的值# set1 = set(['1', '3', '2', '5', '4', '6'])# set2 = set(['8', '5', '7', '6'])# 在集合set1中但是不在集合set2中的values值print(redisLink.sdiff('set1', 'set2'))# 输出结果:set(['1', '3', '2', '4'])# 在集合set2中但是不在集合set1中的values值print(redisLink.sdiff('set2', 'set1'))# 输出结果:set(['8', '7'])print("""sdiffstore(dest, keys, *args):将两个集合中的差集,存储到第三个集合中""")# 在集合set1但是不再集合set3中的values值, 存储到set3集合中redisLink.sdiffstore('set3', 'set1', 'set2')print(redisLink.smembers('set3'))# 输出结果:set(['1', '3', '2', '4'])print("""sinter(keys,*args):获取两个集合中的交集""")# 求集合set1与set2的交集print(redisLink.sinter('set1', 'set2'))print("""sunion(keys, *args):获取多个name对应的集合并集""")# 获取set1与set2集合中的并集print(redisLink.sunion('set1', 'set2'))# 输出结果:set(['1', '3', '2', '5', '4', '7', '6', '8'])print("""sunionstore(dest, keys, *args):将两个集合中的并集,存储到第三个集合中""")# 将set1与set2集合中的并集, 存储到set3中print(redisLink.sunionstore('set3', 'set1', 'set2'))print(redisLink.smembers('set3'))# 输出结果:set(['1', '3', '2', '5', '4', '7', '6', '8'])print("""sismember(name, value):判断是否是集合的成员""")# 校验value=3 是否在name=set1集合中print(redisLink.sismember('set1', 3))# 输出结果:True表示在集合中print(redisLink.sismember('set1', 33))# 输出结果: False表示不在集合中print("""smove(src, dst, value):将某个成员从一个集合中移动到另外一个集合""")# 目前集合set1、set2中的元素# set1=set(['1', '3', '2', '5', '4', '6'])# set2=set(['8', '5', '7', '6'])# 将set1中的value=4的元素, 移动到set2集合中redisLink.smove('set1', 'set2', 4)print(redisLink.smembers('set1'))# 输出结果:set(['1', '3', '2', '5', '6'])print(redisLink.smembers('set2'))# 输出结果:set(['8', '5', '4', '7', '6'])print("""spop(name):从集合移除一个成员, 并将其返回(集合是无序的,所有移除也是随机的)""")# 目前set1集合中元素 set1=set(['1', '3', '2', '5', '6'])# 随机删除'set1'中的Value值print(redisLink.spop('set1'))# 输出结果:1 说明删除的个数print(redisLink.smembers('set1'))# 输出结果:set(['3', '2', '5', '6'])print("""srem(name, values):在name对应的集合中删除某些值""")# 目前set1=set(['3', '2', '5', '6'])print(redisLink.srem('set1', 2))# 输出结果:1print(redisLink.smembers('set1'))# 输出结果:set(['3', '5', '6'])except Exception as err:print("redis连接异常: ", err) finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorSet.py
sadd(name, values):
name对应的集合中添加元素
{'1', '4', '6', '2', '5', '3'}scard(name):
name对应集合中元素个数
6smembers(name):
name对应的集合所有成员
{'1', '4', '6', '2', '5', '3'}sscan(name, cursor=0, match=None, count=None):
name对应集合所有成员(元组形式)
(0, ['1', '2', '3', '4', '5', '6'])sscan_iter(name, match=None, count=None):
name对应集合所有成员(迭代器的方式)
1
2
3
4
5
6sdiff(key, *args):
求集合中的差集
{'1', '6', '2', '5', '3'}
set()sdiffstore(dest, keys, *args):
将两个集合中的差集,存储到第三个集合中
{'1', '6', '2', '5', '3'}sinter(keys,*args):
获取两个集合中的交集
{'4'}sunion(keys, *args):
获取多个name对应的集合并集
{'1', '4', '6', '2', '5', '3'}sunionstore(dest, keys, *args):
将两个集合中的并集,存储到第三个集合中
6
{'1', '4', '6', '2', '5', '3'}sismember(name, value):
判断是否是集合的成员
1
0smove(src, dst, value):
将某个成员从一个集合中移动到另外一个集合
{'1', '6', '2', '5', '3'}
{'4'}spop(name):
从集合移除一个成员, 并将其返回(集合是无序的,所有移除也是随机的)
1
{'5', '3', '2', '6'}srem(name, values):
在name对应的集合中删除某些值
1
{'5', '3', '6'}释放资源,连接还给连接池
Process finished with exit code 0
忙着去耍帅, 后期有时间补充完整......................