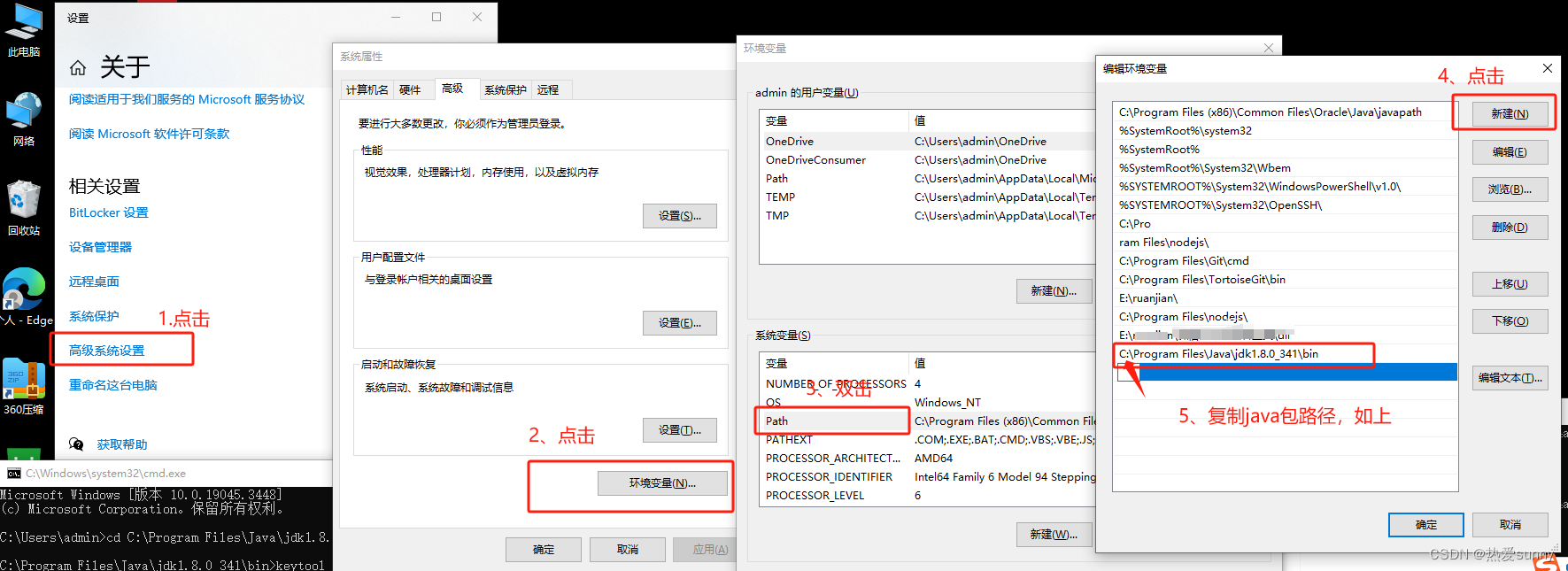
对于多项式回归,可以同样使用前面线性回归中定义的LinearRegression算子、训练函数train、均方误差函数mean_squared_error,生成数据集create_toy_data,这里就不多做赘述咯~
拟合的函数为
def sin(x):y = torch.sin(2 * math.pi * x)return y
1.数据集的建立
func = sin
interval = (0,1)
train_num = 15
test_num = 10
noise = 0.5
X_train, y_train = create_toy_data(func=func, interval=interval, sample_num=train_num, noise = noise)
X_test, y_test = create_toy_data(func=func, interval=interval, sample_num=test_num, noise = noise)X_underlying = torch.linspace(interval[0], interval[1], 100)
y_underlying = sin(X_underlying)# 绘制图像
plt.rcParams['figure.figsize'] = (8.0, 6.0)
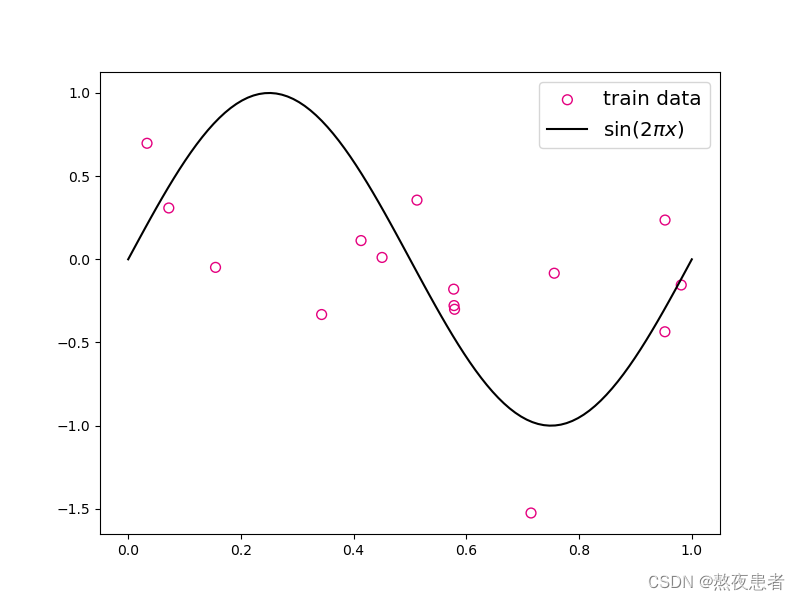
plt.scatter(X_train, y_train, facecolor="none", edgecolor='#e4007f', s=50, label="train data")
#plt.scatter(X_test, y_test, facecolor="none", edgecolor="r", s=50, label="test data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")
plt.legend(fontsize='x-large')
plt.savefig('ml-vis2.pdf')
plt.show()生成结果:
2.模型构建
# 多项式转换
def polynomial_basis_function(x, degree=2):"""输入:- x: tensor, 输入的数据,shape=[N,1]- degree: int, 多项式的阶数example Input: [[2], [3], [4]], degree=2example Output: [[2^1, 2^2], [3^1, 3^2], [4^1, 4^2]]注意:本案例中,在degree>=1时不生成全为1的一列数据;degree为0时生成形状与输入相同,全1的Tensor输出:- x_result: tensor"""if degree == 0:return torch.ones(x.size(), dtype=torch.float32)x_tmp = xx_result = x_tmpfor i in range(2, degree + 1):x_tmp = torch.multiply(x_tmp, x) # 逐元素相乘x_result = torch.concat((x_result, x_tmp), dim=-1)return x_result
我的理解多项式回归的模型的建立更像是将原来的一个x变成x x^2 x^3 ... x^degree这个过程
3.模型训练
plt.rcParams['figure.figsize'] = (12.0, 8.0)for i, degree in enumerate([0, 1, 3, 8]): # []中为多项式的阶数model = Linear(degree)X_train_transformed = polynomial_basis_function(X_train.reshape([-1, 1]), degree)X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1, 1]), degree)model = optimizer_lsm(model, X_train_transformed, y_train.reshape([-1, 1])) # 拟合得到参数y_underlying_pred = model(X_underlying_transformed).squeeze()print(model.params)# 绘制图像plt.subplot(2, 2, i + 1)plt.scatter(X_train, y_train, facecolor="none", edgecolor='#e4007f', s=50, label="train data")plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")plt.plot(X_underlying, y_underlying_pred, c='#f19ec2', label="predicted function")plt.ylim(-2, 1.5)plt.annotate("M={}".format(degree), xy=(0.95, -1.4))# plt.legend(bbox_to_anchor=(1.05, 0.64), loc=2, borderaxespad=0.)
plt.legend(loc='lower left', fontsize='x-large')
plt.savefig('ml-vis3.pdf')
plt.show()
训练结果:
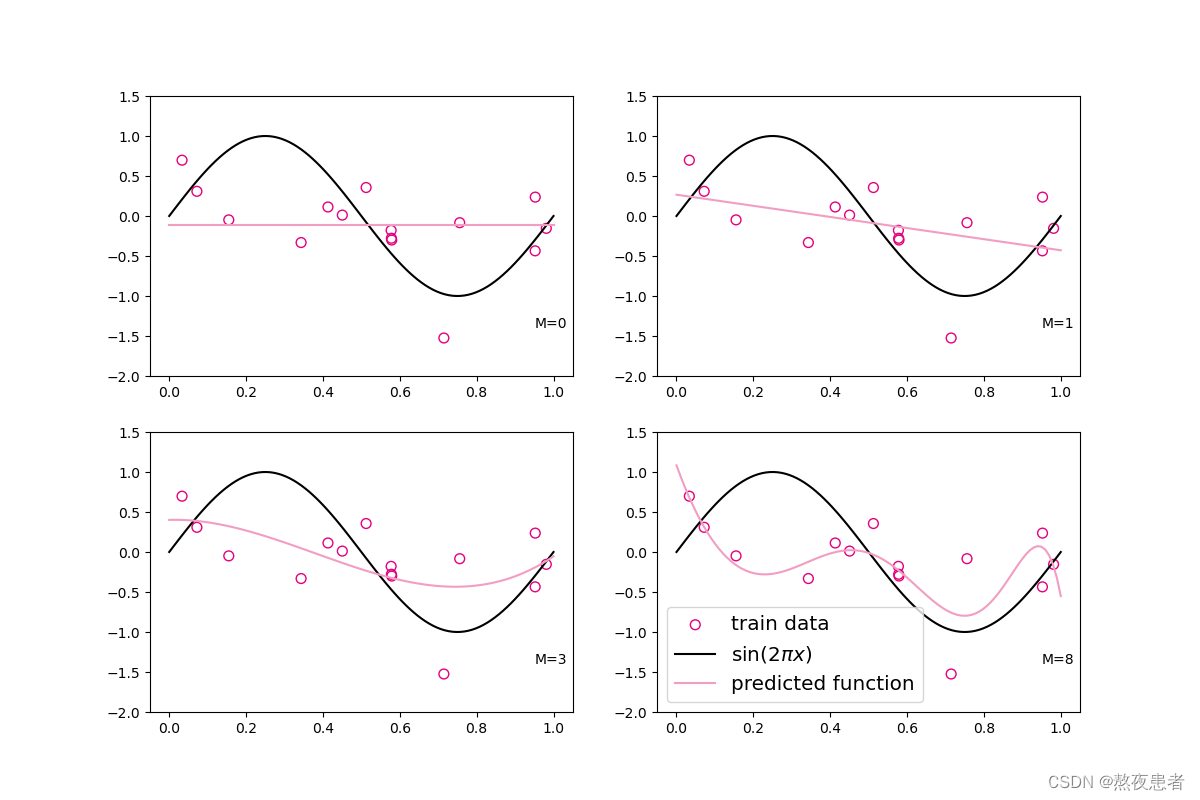
观察可视化结果,红色的曲线表示不同阶多项式分布拟合数据的结果:
* 当 或
时,拟合曲线较简单,模型欠拟合;
* 当 时,拟合曲线较复杂,模型过拟合;
* 当 时,模型拟合最为合理。
4.模型评估
下面通过均方误差来衡量训练误差、测试误差以及在没有噪音的加入下sin函数值与多项式回归值之间的误差,更加真实地反映拟合结果。多项式分布阶数从0到8进行遍历。
# 训练误差和测试误差
training_errors = []
test_errors = []
distribution_errors = []# 遍历多项式阶数
for i in range(9):model = Linear(i)X_train_transformed = polynomial_basis_function(X_train.reshape([-1, 1]), i)X_test_transformed = polynomial_basis_function(X_test.reshape([-1, 1]), i)X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1, 1]), i)optimizer_lsm(model, X_train_transformed, y_train.reshape([-1, 1]))y_train_pred = model(X_train_transformed).squeeze()y_test_pred = model(X_test_transformed).squeeze()y_underlying_pred = model(X_underlying_transformed).squeeze()train_mse = mean_squared_error(y_true=y_train, y_pred=y_train_pred).item()training_errors.append(train_mse)test_mse = mean_squared_error(y_true=y_test, y_pred=y_test_pred).item()test_errors.append(test_mse)# distribution_mse = mean_squared_error(y_true=y_underlying, y_pred=y_underlying_pred).item()# distribution_errors.append(distribution_mse)print("train errors: \n", training_errors)
print("test errors: \n", test_errors)
# print ("distribution errors: \n", distribution_errors)# 绘制图片
plt.rcParams['figure.figsize'] = (8.0, 6.0)
plt.plot(training_errors, '-.', mfc="none", mec='#e4007f', ms=10, c='#e4007f', label="Training")
plt.plot(test_errors, '--', mfc="none", mec='#f19ec2', ms=10, c='#f19ec2', label="Test")
# plt.plot(distribution_errors, '-', mfc="none", mec="#3D3D3F", ms=10, c="#3D3D3F", label="Distribution")
plt.legend(fontsize='x-large')
plt.xlabel("degree")
plt.ylabel("MSE")
plt.savefig('ml-mse-error.pdf')
plt.show()可视化结果如下:
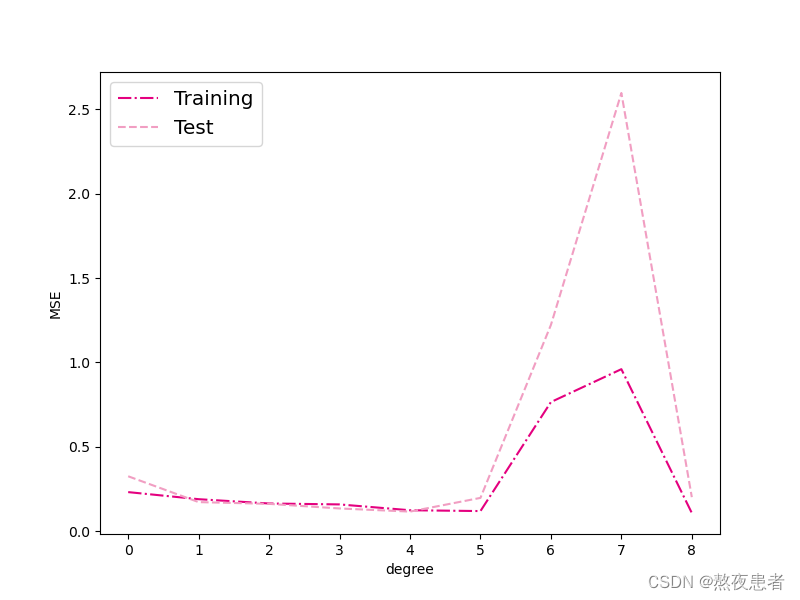
由可视化结果可得:
- 当阶数较低的时候,模型的表示能力有限,训练误差和测试误差都很高,代表模型欠拟合;
- 当阶数较高的时候,模型表示能力强,但将训练数据中的噪声也作为特征进行学习,一般情况下训练误差继续降低而测试误差显著升高,代表模型过拟合。
对于模型过拟合的情况,可以引入正则化方法,通过向误差函数中添加一个惩罚项来避免系数倾向于较大的取值。
degree = 8 # 多项式阶数
reg_lambda = 0.0001 # 正则化系数X_train_transformed = polynomial_basis_function(X_train.reshape([-1,1]), degree)
X_test_transformed = polynomial_basis_function(X_test.reshape([-1,1]), degree)
X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1,1]), degree)model = Linear(degree) optimizer_lsm(model,X_train_transformed,y_train.reshape([-1,1]))y_test_pred=model(X_test_transformed).squeeze()
y_underlying_pred=model(X_underlying_transformed).squeeze()model_reg = Linear(degree) optimizer_lsm(model_reg,X_train_transformed,y_train.reshape([-1,1]),reg_lambda=reg_lambda)y_test_pred_reg=model_reg(X_test_transformed).squeeze()
y_underlying_pred_reg=model_reg(X_underlying_transformed).squeeze()mse = mean_squared_error(y_true = y_test, y_pred = y_test_pred).item()
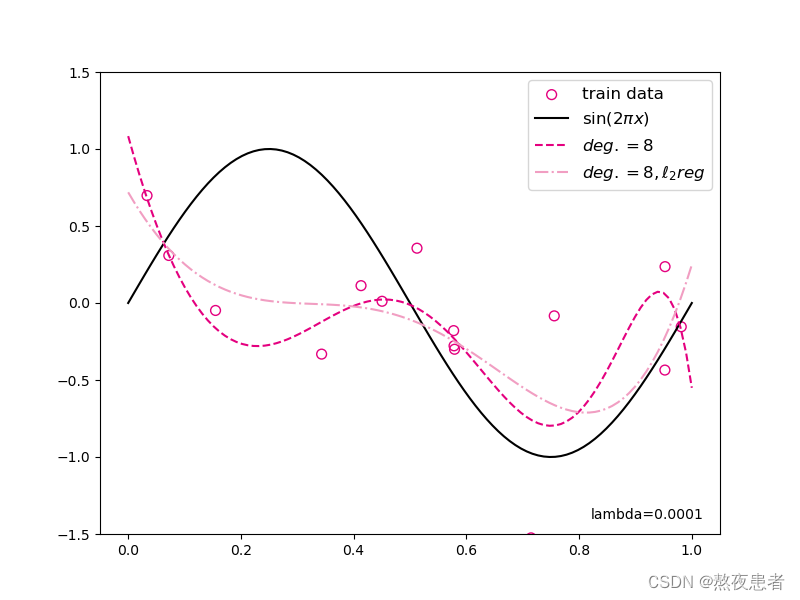
print("mse:",mse)
mes_reg = mean_squared_error(y_true = y_test, y_pred = y_test_pred_reg).item()
print("mse_with_l2_reg:",mes_reg)# 绘制图像
plt.scatter(X_train, y_train, facecolor="none", edgecolor="#e4007f", s=50, label="train data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")
plt.plot(X_underlying, y_underlying_pred, c='#e4007f', linestyle="--", label="$deg. = 8$")
plt.plot(X_underlying, y_underlying_pred_reg, c='#f19ec2', linestyle="-.", label="$deg. = 8, \ell_2 reg$")
plt.ylim(-1.5, 1.5)
plt.annotate("lambda={}".format(reg_lambda), xy=(0.82, -1.4))
plt.legend(fontsize='large')
plt.savefig('ml-vis4.pdf')
plt.show()可视化结果为:
多项式回归的难点就是是否真正理解了线性回归中的算子,均方误差等函数的目的和用法,其他的就是简单的函数调用问题啦~不懂的话还是建议多看看线性函数,先把线性函数的看明白最好~