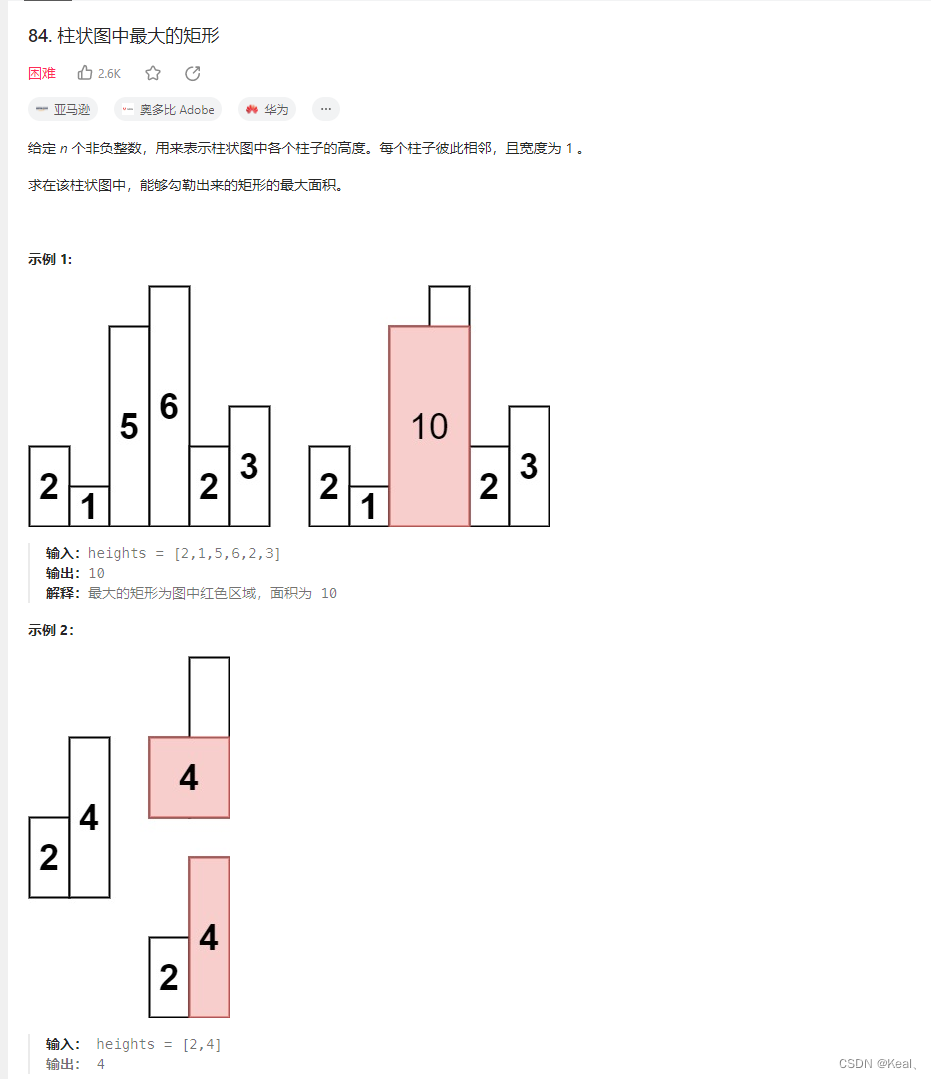
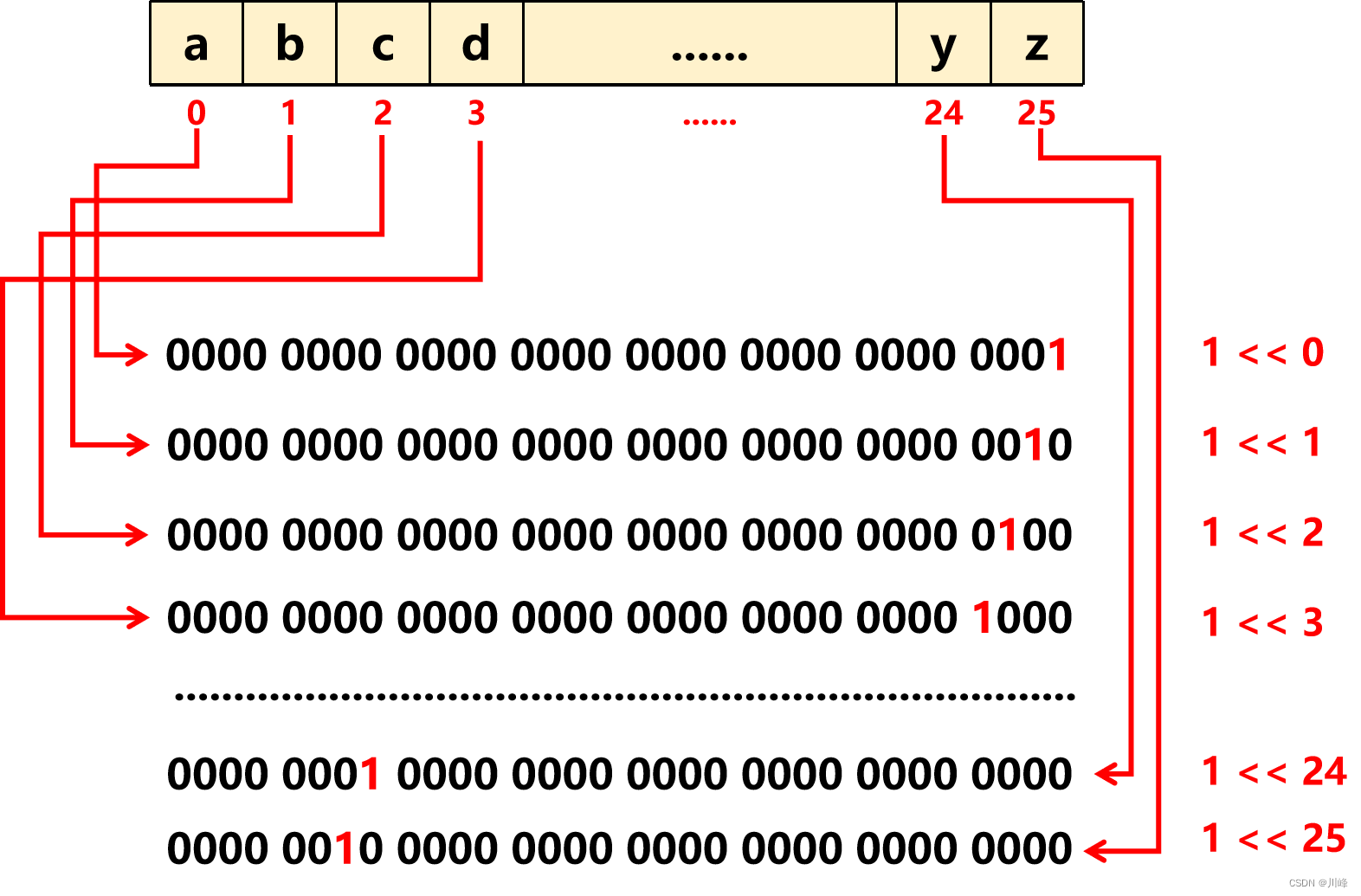
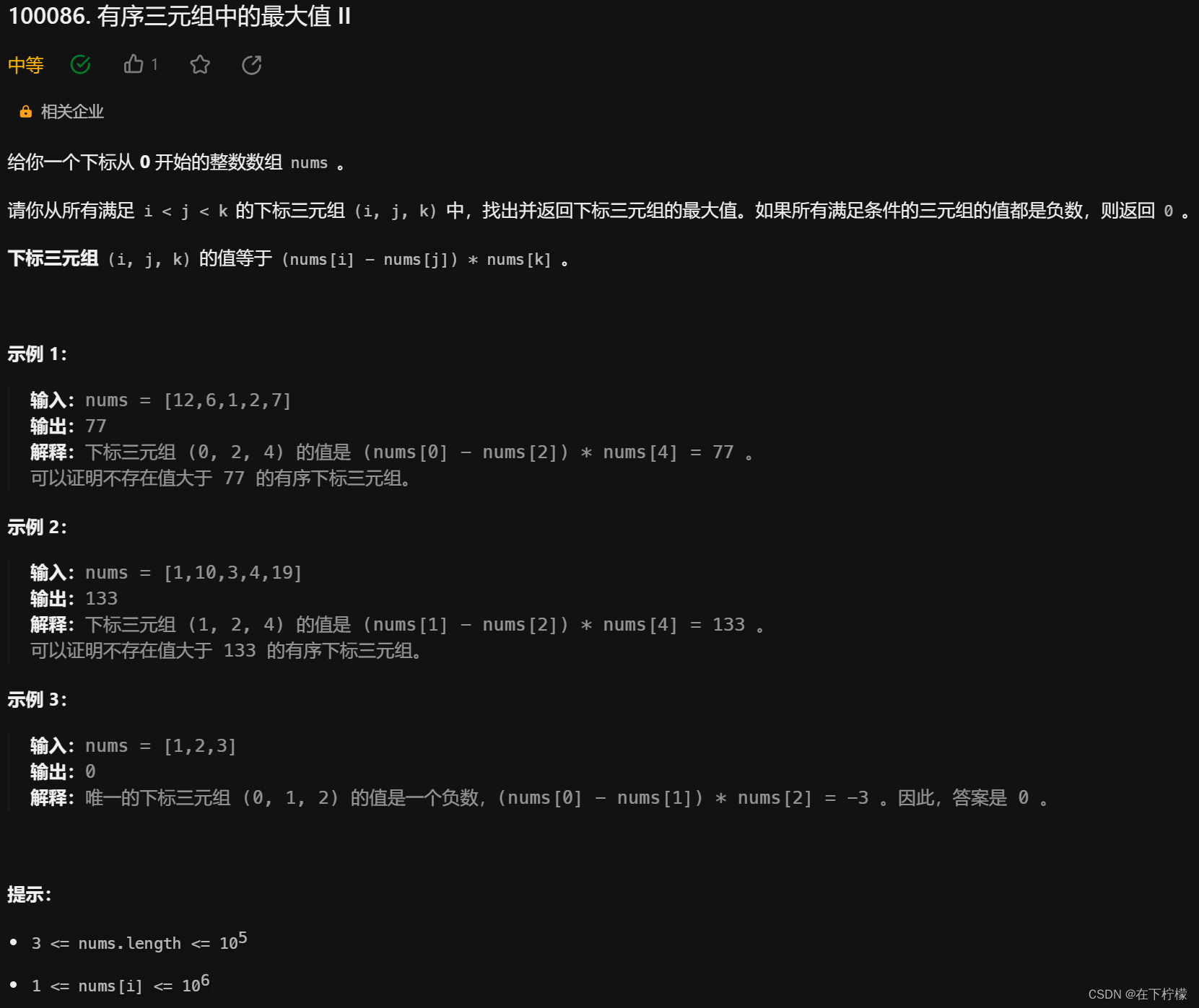
分类
神经网络可以分为多种不同的类型,下面列举一些常见的神经网络类型:
前馈神经网络(Feedforward Neural Network):前馈神经网络是最基本的神经网络类型,也是深度学习中最常见的神经网络类型。它由若干个神经元按照一定的层次结构组成,每个神经元接收上一层的输出,产生本层的输出,从而实现信息的传递和处理。
卷积神经网络(Convolutional Neural Network):卷积神经网络是一种专门用于图像处理和计算机视觉任务的神经网络类型。它通过卷积和池化等操作,可以提取图像中的特征,从而实现图像分类、目标检测、图像分割等任务。
循环神经网络(Recurrent Neural Network):循环神经网络是一种能够处理序列数据的神经网络类型。它通过记忆单元和门控机制等方式,可以处理任意长度的序列数据,从而实现自然语言处理、语音识别等任务。
自编码器(Autoencoder):自编码器是一种无监督学习的神经网络类型,它的目标是将输入数据进行压缩和解压缩,从而实现特征提取和降维等任务。
深度置信网络(Deep Belief Network):深度置信网络是一种由多个受限玻尔兹曼机组成的神经网络类型。它可以通过逐层贪心预训练和微调等方式,实现高效的特征学习和分类任务。
多层感知器(MLP)
MLP神经网络属于前馈神经网络(Feedforward Neural Network)的一种。在网络训练过程中,需要通过反向传播算法计算梯度,将误差从输出层反向传播回输入层,用于更新网络参数。这个过程中需要使用反向传播算法来计算梯度,并且在某些类型的神经网络中,例如循环神经网络(RNN),也存在反馈回路。除了MLP,其他常见的前馈神经网络包括卷积神经网络(CNN)和循环神经网络(RNN)等。
网络结构图
从输入层到隐藏层
连接输入层和隐藏层的是W1和b1。由X计算得到H十分简单,就是矩阵运算:
H = w ∗ x + b
如果你学过线性代数,对这个式子一定不陌生,可以理解为w是一个权重(权重越高,这个特征也就越重要),b是一个偏置,如果有多个特征那么就有个w,还记得w T ∗ x
如上图中所示,在设定隐藏层为50维(也可以理解成50个神经元)之后,矩阵H的大小为(4*50)的矩阵。

也就是说50个神经元就是一个矩阵50个特征,每一行就是他的w值,这里输入层总共两个维度,所有只有w1和w2,b值这里就不说了,假设为0
从隐藏层到输出层
连接隐藏层和输出层的是W2和b2,输入就是隐藏层输入的H值。同样是通过矩阵运算进行的:
Y = w 2 ∗ H + b 2
最终输出层,最终是4个象限
H是450的矩阵,输出层的w2矩阵就是个504,最终得到一个4*4的矩阵
1. H是4*50的矩阵其实是一个列是神经元50个,行是4个数据集的经过第一轮计算的输出值H,隐藏层的目的就是计算出一个H值。
2. 输出层的 w矩阵是50*4,目的是为了将50个神经元压缩到4个输出特征,也就是每一个数据集在4个象限的概率。所以最终输出是4*4
激活层

- 阶跃函数:当输入小于等于0时,输出0;当输入大于0时,输出1。
- Sigmoid:当输入趋近于正无穷/负无穷时,输出无限接近于1/0。
- ReLU:当输入小于0时,输出0;当输入大于0时,输出等于输入。
需要注意的是,每个隐藏层计算(矩阵线性运算)之后,都需要加一层激活层,要不然该层线性计算是没有意义的。
反向传播与参数优化
上面的过程其实就是神经网络的正向传播过程 ,一句话复习一下:神经网络的传播都是形如Y=WX+b的矩阵运算;为了给矩阵运算加入非线性,需要在隐藏层中加入激活层;输出层结果需要经过Softmax层处理为概率值,并通过交叉熵损失来量化当前网络的优劣。
算出交叉熵损失后,就要开始反向传播了。其实反向传播就是一个参数优化的过程,优化对象就是网络中的所有W和b(因为其他所有参数都是确定的)。
神经网络需要反复迭代。如上述例子中,第一次计算得到的概率是90%,交叉熵损失值是0.046;将该损失值反向传播,使W1,b1,W2,b2做相应微调;再做第二次运算,此时的概率可能就会提高到92%,相应地,损失值也会下降,然后再反向传播损失值,微调参数W1,b1,W2,b2。依次类推,损失值越来越小,直到我们满意为止。
此时我们就得到了理想的W1,b1,W2,b2
过拟合
过拟合是指模型在训练数据上表现很好,但在测试数据上表现不佳的现象。这通常是由于模型过于复杂,而训练数据又过少或过于噪声导致的。通过使用Dropout技术,我们可以减少模型的复杂度,并使其更加适应不同的训练数据。这样,我们就可以更好地泛化模型,从而在测试数据上获得更好的表现。
Dropout是一种在神经网络中用于防止过拟合的技术。它是通过在训练期间随机将一些节点的输出设置为0来实现的。具体来说,每个节点有一定的概率被“关闭”,即其输出被设置为0。这样,节点之间的连接就会被随机断开,从而迫使网络学习更加鲁棒的特征,而不是依赖特定的节点或连接。这种随机性可以被看作是一种正则化技术,可以有效地防止过拟合。

每个神经元由两部分组成,第一部分(e)是输入值和权重系数乘积的和,第二部分(f(e))是一个激活函数(非线性函数)的输出, y=f(e)即为某个神经元的输出,如下:

前向传播
第一层神经网络传播



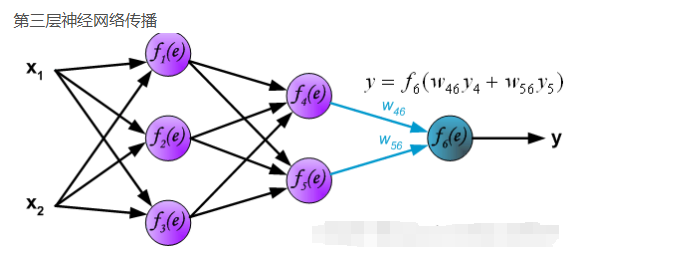
反向传播
到这里为止,神经网络的前向传播已经完成,最后输出的y就是本次前向传播神经网络计算出来的结果(预测结果),但这个预测结果不一定是正确的,要和真实的标签(z)相比较,计算预测结果和真实标签的误差δ ,具体的图解过程,这里就不在赘述。